|
|
|
6:07 |
|
|
transcript
|
1:02 |
Hey, welcome to the course. You want to keep up on cutting edge python, may be see what 3.11 has to offer and decide whether or not it's worth upgrading from 3.9 or 3.10 to 3.11 to get those features. Often times there's a few new features in python on the yearly release when we went to 3.9 or 3.10. But I gotta tell you with 3.11, there are a handful of really, really compelling reasons to upgrade. We're gonna go through them in this course. Now. Maybe you've already seen a rundown of some of those features and advantages that 3.11 has. But what's different here is this is gonna be a guided tour in code. So many of those other videos and articles talking about 3.11 only talk about the features, they don't really show you how it works. So I hope you're looking forward to writing some code in playing with actual live code for this course because we're gonna dive in and see how it works and actually put it through its pieces.
|
|
|
transcript
|
1:03 |
Python 3.11 was released on october 24th, 2022. Often when software like this released, there's a bunch of work done in the background, you're not aware of it, you have no visibility into it and then all of a sudden there's a blog post or there's some kind of social media announcement. But for 3 11, the folks behind the release there, they made it very public, not just the fact that it was released, but how it was released and they live streamed the process of doing all the release channels, pushing out to the different locations. For example, the version that comes with the Microsoft Windows store as well as the stuff you download off of python.org, updating the website and documentation, reflect those changes. So if you really want to see how the sausage is made, if you want to see some small presentations from the people behind some of the core features as well. During the downtime, say, while a 10 minute build is running or something, check it over here on YouTube. It's a lot of fun.
|
|
|
transcript
|
1:46 |
I mentioned at the opening of this course that Python 3.11 is a huge release. Let's put that in perspective, huge to one person. Could be. There's some changes for the other. If you go over to docs.python.org. And you pull up the change log, you can see the URL. Here. If you pull this up it gives you you can see like 1 to 2 sentences per thing change. So the first thing is a security release fixing, multiplying a list by an integer. There's some kind of overflow Now. This list goes on and on. In fact, there are 1,75,000 words in this list. If you scroll I mean it scrolls forever. In preparation for this course, I read this entire thing skimmed it. Honestly, it's massive. How about some comparisons. Your typical novel is 80,000 words. Your typical nonfiction book is 80-120,000 words. That just the release notes, a couple of sentences per thing. That has changed is 175,000 words. So my oh my is there a lot to cover now? Many of these things are important, slightly interesting, but mostly not relevant to you. So, I've gone through this list and pulled out what I believe are the major highlights that almost everyone is going to care about and gonna be interested in. And at the very end I pulled maybe some lesser important things out of this list and we'll just do like a quick quick hit of, you know, 20 or 30, 40 of these extra pieces in here that are still important, but not enough for their own topic. If you really want to know though, go check it out. The real point here, though is not necessarily encourage you to read the change log but just to show Yeah, it's actually really huge.
|
|
|
transcript
|
0:28 |
If we're going to explore Python 3.11 and its new features with code, you would expect that we would give you that code. Right? Well, here it is. Here's the Github repo. So I encourage you to pause this video and go over here right now and star. And maybe even fork this repo, if you want to play with it, that way, you're sure to have a copy and you can follow along and experiment with us. That, of course, is the best way to learn to code or to understand a new framework or feature
|
|
|
transcript
|
1:08 |
Usually when you take one of my courses, I'll say something like, well, you need a modern ish version of python. Do you have 3.9 or 3.10? That's probably fine. You can just use that. We're not using super cutting edge features, but for this one obviously we are only focused on the features of Python 3.11. So you're gonna need Python 3.11 to take this course. If you don't have 3.11, get it installed, maybe you already know how to do that and that's no big deal. If you're unsure what your options are to get it set up on your computer or if you even have 3.11, I put together this really great doc here training.talkpython.fm/installing-python. It lists out for each operating system how to check whether you have python what version of python do you have your options for upgrading the tradeoffs and benefits of each of those paths To get that done. So if you don't have 3.11, remember if you want to play along, you're going to have to have 3.11. So check out how to install it onto your machine. Or if you're familiar with Docker, you could run a Docker 3.11, image something like that, please make sure you get 3.11 setup.
|
|
|
transcript
|
0:40 |
Finally, let me just give you a little bit of background. If you're new to me, see that's me over there. A static picture, not a moving one. I'm over on mastodon. You can find me @mkennedy on fosstodon.org. So if you want to have a conversation about this course or python things in general, find me over there. I'm the host and creator of the Talk python to me podcast, co host and creator of the Python bytes podcast and one of the main authors and founders of this place right here, Talk Python Training. So I've been doing python for a long time, super passionate about it and I'm very excited to share these 3.11 features with you.
|
|
|
|
25:30 |
|
|
transcript
|
0:46 |
When we think about Python 3.11, there are two major major features, each of which individually may well be enough to make you say yes, I'm upgrading to this. It's worth it for me or it's worth it for our team or for our project The first one which we're gonna talk about right now is better error messages and error handling. So they've done a lot of work. The core developers have done a lot of work on python. So when there is an error, it not only tells you, hey, there's an error or what line it's on, but down to the character or down to a more specific error message, what has gone wrong? So we're going to explore that and other things to do with errors in Python 3.11
|
|
|
transcript
|
1:02 |
The most important upgrade for error reporting in Python 3.11 comes to us via PEP 657. It's got a non obvious or not. Super clear name include fine grained error locations in trace back. This one turns out to be incredibly helpful. As we'll see in prior versions of python, basically all you got was a line by line your information somewhere on this potentially really complicated line of code, something went wrong and now we'll get down to the individual keyword or the individual function call or symbol on that line of code that caused the problem. It's really, really helpful. Pretty much everyone who comes across this is like, yes, amazing. Wait, why wasn't this here before? It's so helpful. So There's actually some of the work done by the faster CPython team that built the foundations that made this easy impossible. So thats why it is in 3.11
|
|
|
transcript
|
2:59 |
Let's see the problem they're trying to solve here with this Pep. And this new feature. We've got this function a little bit contrived but not entirely unreasonable called Func 1, it takes five arguments. We could use python type ends to make a little clear what the point of these are. But the first one is a dictionary. The next four are keys that we want to use to navigate some kind of hierarchy of data within that dictionary. So we go to a the dictionary we say get b why b is the key. And then we say from that 'b' inside. That's part of the dictionary. We should have something called C. From that. We should have something called D and then something called E And then that's gonna be a string. And so we want to remove all the extra white space and make it uppercase. No problem. Right. Should work when we run this code write a function like this we'll say V1 V2 V3, V4 V5. These are the different variables that we're passing in. Let's say this works most of the time. But sometimes rarely in production doesn't work. And we're gonna log what happens. Well, we're gonna get a trace back and it'll say something like this. Well, there's a problem on this line. The one line of that function a.get(b). get(c) and so on. What is the error errors? None type object has no attribute yet. Oh boy. Well there's a lot of things that could be going wrong here. Let's think about this. It could be that A. Was none. In which case when we tried to call get 'b' on it. We got this error but let's suppose A. Is fine or maybe the return value of get(b) itself is none. And then when we tried to call get(c). On it we got this error. Same thing for the return value of get(c) remember this is a dictionary when you call get if you the key does not exist it's just gonna return none. If we had square brackets it would be a key here but here it's gonna return none. So maybe that's what happened for when we tried to call get(d). Or get(e). It's not the strip. So the return value of get(e) is fine or never made it that far. And similarly for strip and upper. So it's one of the first four but we don't know which one now do we? This is python 3.10 or earlier. However if we write exactly the same code literally take the same source and just run it in Python 3.11 notice the little carrots or the hat symbols here they go from the beginning all the way up to get(d) What does that tell us? Well it tells us right there that call to get(d). Crashed. That's what caused this exception. So that means the return value of get(c). Must have been none. Such that when we called get(d). On it it crashed awesome. We know right away, there's a whole bunch of these types of improvements from this pep. We gonna explore them now.
|
|
|
transcript
|
1:39 |
Let's get going and write some code. Now, since this is the very first time we're opening any of the code from this course, I'm gonna take you through a couple of steps of setting it up afterwards. We'll just jump right in. Okay. Over here you can see I've get cloned this repo that I shared with you before and I'm gonna drop it over on the PyCharm on MacOS. You can drop the folders on Linux and windows, you have to say file, open directory. So here we have the starter version. Of course this will be more filled out as we get going. If you look down here in the right, you can see that PyCharm has made a bad choice for us. Remember this has to be Python 3.11 or newer for this to work. Right? And it's decided, you know what? We're going to be totally good with 3.9, I've got 3.9, 10 and 11 installed. So let's go and add a local interpreter. I'm gonna pick a new virtual environment and again it guessed wrong, but it got slightly better guess 3.10 that time. So we're gonna say 3.11 here is what I want to base this on, Go ahead and update that as well. Okay, now you can see we've got 3 11 this virtual environment set up here. So just make sure whether using PyCharm or you're using Visual Studio Code when it auto detects the virtual environment, that is the right one. Or if there's not a virtual environment at all and it's going to create one, make sure you get the version 3.11.
|
|
|
transcript
|
9:21 |
Let's get started by writing the code. We're gonna need a file to do that. Trying to break this up into a bunch of different files per topic for you. Of course. This one we're gonna call better messages for better error messages. Now, what I want to do is look at this these types of error messages that we explore just a little bit before in the presentation from a couple of different angles. So let me drop in some code here. We're gonna use this named tuple is a really simple class and it has a name and a weight and a speed that will let us interact with those fields to do interesting things. We also want to have that function we explored. So let me drop those in notice at the bottom. This green box is showing the hot keys that I hit. So for example under there. So if I hit cmd+Alt+l, wait for it to go away and see it fix that formatting. But also down here it tells you what I did. You also see that if I press the button it will show the command of the hot keys. So if you see anything happen on the screen you're like wait, how'd that happen? Just check out that box at the bottom. That's called Presentation Assistant, if you care, it's an extension or a plug in for a PyCharm. Okay, so we've got this function here. That is the one we explored with the dictionaries. We also have the three things from our thing class and we're working with trying to add up the weights and here we're just doing simple math or stream combination order list combining which is it? We don't know. We're gonna find out in order to call these. Especially the first one we're gonna need some interesting data. So let's just write a main method that creates a data dictionary that we're gonna use and some keys for what we want. So what we want is we would like to have this string right here in order to get that out of the dictionary. We go to the dictionary and we ask for the region and we asked for the country and we ask for the size and we ask for the units and we get that value ideally Or if we don't traverse it correctly we get a crash. Now this main method obviously doesn't run, you probably know we've got to do this dunder name equals dunder main convention. Alright so we can run it now. Nothing should happen. But it should be working now notice we're using our virtual environment python here to run this. So I'm gonna copy that because we also want to run this with python 3.10. Now you could set up multiple virtual environments and swap between them. I'll just run it in the terminal on 3.10. So let's go and try to print out maybe what we get if we call up here we call Func 1 passing all of those values and we string, we strip it and we upper The miles and if we do this right. What are we gonna get the func 1 data B C. D. And E. This should work. There should be no problem. Sure enough. We get to the units, get the miles out and we see the stripped uppercase miles as you would expect. What if we ask for something wrong? What if we asked a D Is bigness rather than size and we try to call this function again What's gonna happen? Well first of all let's run this in terminal and I'm pretty sure python will be Python 3.11 for me. But if I type 3.10 I can explicitly call that. Well it crashed and exactly like you saw in the slides right there. Return a.get(b).get(c).get(d).get(e).strip().upper. Somewhere along that line. In the chain of calling. Not get one of the things that was called on. Either it was or returned. None that's all we know. And again this is Python 3.10 as you can see. But if I run the exact same code over here in 311. There it is. Look at that. It's telling us that this return value. Get D. Was a none type. So when we tried to call get(e) on it. It crashed. What what key did we break? We broke the key D remember? Bigness is not in there obviously. So when this tried to access a key here that wasn't there. It returned none. Beautiful. Right. Really nice. That's what's gonna show up in our logs and it's something that we can use right away. This will save you time in the debugger or other types of analysis tools to try to look at the values and figure out what went wrong. We know right here where the error actually is. So it helps us to focus in a little bit more. Now let's look at another example when you look at that function two for function two, we're gonna need some values for are things we have bob, sarah and jake. And let's see. We'll get PyCharm to tell us what these are. This is their weight in kilograms. And then their speed and running I guess. I don't know. Well I guess there is a faster runner. Okay Maybe maybe she could run that fast. We'll see now if we just call func2 to see. It takes three things to T1, T2, T3. All this total weight. When you print out the total weight here we'll say the total weight is. And notice I want to use an F. String but I forgot to put the beginning. Never mind. PyCharm will help us. If I just type T. W. It'll select auto total weight here automatically and then if I select this it will complete it and put the F. At the beginning. There you go kilograms. we run this again. There should be no problem. This is perfectly fine. We have three things. They all have weight properties. We're gonna add them up except for him. We never made it that far did we? Let's comment this out. Here we go. The total weight is 207 kg. Fantastic. Again. What happens if we did this wrong? What if we set T2 to none? Check it out being one like this right here, we tried to de reference the weight field or property on thing 2. And guess what thing 2 is none. So instead of just saying, well something along this line here was none. This weight problem. So that's really, really nice. Let's look at the other one. The final one will say Func 3. Remember this is the addition one here, A plus B plus C plus D. So we say 1,2,3 and 4. Run that 10. Sure enough. But what if we had like this one was the string three. Now we could convert it to a number but directly this will be an error in Python. If we run this code over here, you can see something along there. Those four editions there was an unsupported combination of int and stir which one we don't know although is really explicit right here. Normally these would be variables and you wouldn't see their values. But in Python, 3,11. Hey, look at that. There was an error in this thing and it's that plus right there, see the little carrot that goes up and says that's the one that the end and the stir went bad on so I'm gonna copy that out so we can write one more on a code. Let's suppose we had Sarah is too, so we'll say Sarah equals T two, Mob Equals T one. Let's suppose I wanna work with bob and Sara for a minute. I want to print out something like the weight of bob and Sarah is, I'm gonna do a little F string here. It's bob.weight and Sarah.weight, but let's suppose. I thought Sarah was spelled like that. Oops, now PyCharm is helping me here but imagine it was a little more subtle. We weren't really sure this era wasn't caught name error. There is no Sara spelled like this, but here's the part. That's awesome. Did you mean Sarah with an H and it's right here we're using it right in that F string, awesome, awesome, awesome. So really cool, Better error handling features, better error reporting when something goes wrong for us using Python 3.11. So this is definitely one of the biggest features of 3.11. Just easier to write code and develop code when you're getting started on a project and then if something goes wrong in production you have so much more information captured if you save the exception details then if you just had 3.10 or something before. Ok, big thumbs up for me.
|
|
|
transcript
|
2:48 |
The previous feature we saw that when python fully crashes or you somehow gather up a trace back their ways. You can take an exception and extract the trace back and print it. For example you get better messages. But sometimes in the normal flow of your program you just want to catch an exception and see a message. Sometimes that message is helpful. Other times it's not enough information. So that brings us to PEP 678 enriching exceptions with notes done by Zac Hatfield Dodds, sponsored by Irit Katriel. This is a way to catch an exception. Potentially temporarily add some more context that you might have about this error and then let it be raised further up the call stack where it's meant to be handled. Or even when you're throwing the exception, you can add more details about what went wrong and why in this new notes list that is associated with all exceptions. Let's see an example here we have a function called setup app. We're going to call it and we get a database connection exception. It gives us a nice message. The connection string is malformed. Well that's not super helpful. What way is it malformed? Is there anything else you could tell me about it notice we're calling, we call set up app, it calls connect to db passing a connection string. A server in support. Well it must have come up with this connection string and somehow done it wrong. I don't know but here's the exception. Not terribly helpful. However, with this new feature we just introduced, we can call the same code and if setup app is a little helpful and it says, you know, in this situation here's what's actually going wrong. And then let's set exception keep going. We'll get something more like this. Same error. Connection strings malformed. But check out those notes. Note, you cannot specify the server. Report in both the connection string and explicitly. So here we're calling connected database by passing a server in support presumably. But maybe in the connection string it says something like Mongodb:// server colon ports/database. And then we're also passing the server and maybe those values are in conflict they're different or something like that. So we get this extra information. You cannot specify the server import in both the connection string and explicitly. That is helpful. And then we even get some more encouraging advice here, amend the connection string. Try again. So that's what this feature is about.
|
|
|
transcript
|
5:34 |
Alright let's explore these exception notes at any file, EX notes. And again I want to start with a somewhat reasonable, slightly realistic set of codes. So let me drop a bit of code in here for us. Now we've got a DB exception class that derives from exception and adds nothing special to it. The DB connection exception derives from that. Again, just taking whatever the base exception gives us. And here we've got our connect to DB and you can see our test if the server is in the connection string and the server specified. That's a problem. If the port is in the connection string and the ports specified, that's a problem. Otherwise port connect to the database again. Just a sample. But if there we give this conflicting information there's gonna be a problem down here. We've got this Mongo connection there that passes the user name, password and database is not a real MongoDB connection. Just roll with it for a second. We've got this more troublesome one that passes the ports, we have a different port here that we're gonna pass one call it. Okay so here's our setup app. This is the one that might be causing us trouble. So let's go ahead and run this code now this doesn't have any of those notes added yet. So we've run it and it says awesome. You connected to the database and you can see it's a men appended onto the connection string. The server and import but if we go back and say let's try to connect with this conflicting one bam error error. Starting application the database, there's been a database connection exception. The connection string is malformed. Why is it now malformed? What's wrong with it? Okay well this function presumably this is my working theory of this example. Is that this function knows when it gets that database connection error of that type. But that means the database connection string is messed up. No, I know it's weird because it's also creating the connection string. But let's just say that this is the section of the code that knows if we try and we say except DbConnection exception as dbe. Then we can go over here and we can say dbe.add note doesn't look like PyCharm thinks that's there. Does it stick with me for a second. I'll tell you what's going on. So first we're gonna say note you cannot specify the server or port in both the connection string and explicitly and we want to add that other one. Amend... note, Amend the connection string and try again. Now look down here, we're catching this exception here and we're printing out some error details like what type of error and what is the message? Let's run this app ready. Okay that doesn't seem great now does it because when we caught the exception here we ate it. So that's why I think it didn't crash. So we need to say raise raise like this. Let it keep going or stopping for a minute we're adding some details and we're letting it go right there. Try again. Did not start in the right way. DB connection exception connection string is malformed. Wait, we added the notes where the notes go. Well if this was a full on crash, you would actually see the notes. So let's try to run that outside of this. Try except block here. You can see those three details right there. Though we've got the DB connection exception this and then we have these notes, whether we want to actually explicitly call them notes, maybe we want to put them in like this. However, that string appears there that just gets echoed below the air message. Okay, no additional information. There's no clue that that is the notes in the error message. But we can also work with us if we catch it and we can see the notes for ourselves. So for example, we could come over and say for n in x.notes dunder notes Again, PyCharm says they're not there. Give me a minute and we'll make sense of that. We'll print the Sad note will say there's a note colon, whatever that note is now we run it and says, look, there's these extra notes or you could say something like we could say print, we could do something like this where we say, hey look, we found some notes. There are two notes associated with this exception and here's what they are. So you can do whatever type of reporting around it you like the key. Take away. The key idea is there's some part of your code that maybe can't handle the exception, right? We need to let the caller of setup app know this broke, something went bad. Here's the exception, but we also have more information about what went wrong and a little contrived. But we know that you can't specify both the server and port explicitly. If we see this exception, that's what happened. So we can upgrade the error message.
|
|
|
transcript
|
1:21 |
So what's going on with PyCharm saying that's an error. Clearly it's not the code ran well. If you go over to the youtrack.jetbrains.com/issues for PyCharm. And we look at these, noticed somebody named Michael Kennedy submitted a bug. PyCharm does not know three eleven's exception features. And look at that. That should look pretty familiar. And look, here's the warning that we get you. Hover over add note. It says unresolved attribute, add notes for class dB connection exception it, you know, it doesn't have that. But this was categorized as a major bug submitted by and reproduced by Andre. So You watch this error if you want. This is PY 58021 notice appear I'm running the 2022.3.1 Release candidate. So presumably in the next RC that comes out or the main version when they actually release it. This will already be fixed. So chances are by the time you get to this section of the course it's already been fixed. If using PyCharm. But if you haven't, here's what's going on. Just watch it over here. I'm sure they'll fix it. They're usually quite quick at fixing these types of things.
|
|
|
|
22:59 |
|
|
transcript
|
0:36 |
Python 3.11 brings a bunch of cool features and enhancements for Async IO. you know, that thing just below the async and await keywords or the async def when you're defining a function awesome part of python and it gets better in Python 3.11. In this chapter, we're going to focus on some of those new features and improvements. We'll see there's also a better error handling for async errors, but we're going to push that off to an error handling chapter that follows this one. So this is not the complete story in this chapter, but some important and useful additions.
|
|
|
transcript
|
1:01 |
If you're doing async work that involves more than one task and a lot of async work does imagine I want to log something to a file and put it into the cache or I want to get something from the database and call an API. At the same time. Well you're working with a group of tasks and Python 3.11 now has task groups specifically for that and this github issue as far as I can tell is the definitive source of this information I couldn't find a PEP for it. Maybe I just missed it. I always thought perhaps for what we needed to make changes to the language, but it looks like this github issue by none other than jGuido Van Rossum himself is the definitive source of this information. Nonetheless, it's a really cool feature that allows us to start a bunch of tasks, wait for them all to finish if there's an error or we want to stop part way through cancel the ones that have not run a bunch of great features like that.
|
|
|
transcript
|
8:25 |
Well let's get started over here. We'll write some code to explore these task groups. And let's give it the name groups for our file Again. We're gonna start with some existing code and tweak it with this concept because I want it to be something realistic So what's the deal with this code sample here? What we're gonna do is we're gonna search two different podcasts. We're gonna search talk python and we're going to search python bytes. Let's jump over there real quick. So for example, let's say talk python. Now, both the podcasts have great search features. So I could search for pydantic and odm we get a bunch of results here. So we get the interview I did with Sam Colvin Colvin on pydantic, the updated version 2 some stuff on Sql model, which is the new Sql Alchemy paired thing with FastAPI That's also based on pydantic. Right? So we're getting these results. But if you look carefully, there is a want to search with our API There we go and we can search the same thing over here. Alright, so it's taken us back. Hold on, you click this it'll show you give you some information the keyword you search for and then all these results and whether it's an episode or it is a transcript. So in this code sample, what we're gonna do is we're gonna use this search podcast function up here. So we've defined this search response which is a pydantic model that will allow us to parse that response. You just saw elapsed time keywords, the results which is a list of search items and broken out by just episodes, search items, list as well. We've got that code up here, that's totally fine. Notice we're using pydantic and HTTPX. We don't have those available to us yet. We'll have them shortly. This cleanup function is just unifies the two different search API's don't worry about that. Here's where the important stuff is. So we're gonna search the podcast and this is an async feature so we can use httpX to asynchronously open the socket, we'll close it and then we can await asynchronously getting the search results that Json we're gonna parse it using pydantic here and then return it as a list. We're going to do that for talk python and we're gonna do that for python bytes. What is the relationships between those two shows besides the fact that I happen to work host both of them or co host one of them host the other one. Nothing. There are separate servers. They're separate web apps. They're separate search engines so we should be able to search them both at the same time and combine those results A perfect use for starting a bunch of tasks that can all run independently bringing back the results when they're all done. Alright. So here we are, we're going to go create this task and we're gonna call search and we're gonna try to print out the results. How well is this going to go not to Well, first of all, because we don't have the dependencies. We don't know what httpX is. So let's first add a requirements for the entire project entire course here. So requirements probably thought I was gonna type txt No, no no. Let me show you something cool. This is way better. I'm gonna put a requirement.in. And what goes into this file here is just the base dependency. So we have httpx and we have pydantic. You want to put those two in here just like that? No versions or anything. And what I would like is a requirements.txt file that has all of the dependencies. Not just those two but its dependencies and their transitive closure of their dependencies all pinned with the latest compatible version. So what we're gonna do is we're going to come over here, I want to say pip, install pip pools, which is a really awesome library to manage exactly that. Then we're gonna say pip-compile give it this requirements in and say upgrade. It will require generate a requirements.txt. Let's see what we get look at this over here. Perfect. So we've got anyio why do we have that because of http core. Http core, why do we have that? We have that because of httpX, you can see they're all pinned versions. And if new dependencies come out we can run that command again and it'll upgrade the ones that got an upgrade. Even the dependencies of the dependencies. So highly recommend pip-tools and pip compile here. We still need to get the dependencies. So let's do that real quick. Alright. We should be good to go and this warning will go away in a sec. Alright, so this up here looks pretty good. Let's go try and run it again. It's still not gonna work. This is going to start the task but it's not going to go well what search do you want to look for now? It suggests that this is a search term you can use or set of keywords that will generate some results, but not an insanely large one. So let's go with that whack. asyncio feature is in an invalid state. The result is not set. Boy, if I were designing asyncio, it would be so different. So one of the things that's annoying, let's say about async Io is what I would like to see is like if this is running and you can't give me a result yet, just stop and wait for that to result to finish and then give me the results, basically turn that into a blocking call. That's not how it works. If you don't wait for this in some other way it's going to crash, and this gets worse. If this thing internally also generates other tasks like you kind of got to build this up as a hierarchy. So one way to do this is we can come over here and we can say results equals asyncio.gather and give it an arbitrary number of tasks. And this thing itself is in a task that we can await. So when this runs we should be able to pretty print out the results and let me just return real quick So we just see that. Try the same search again. Awesome. Look at that. So we get here's the results for talk python and here's the results for python bytes because the order in which we gathered them. Well, that's cool. But what if after that one started and this one hadn't quite got going yet? I decided I want to cancel everything or this one has an error. We don't need the other work to keep going because there's a problem. We just got to stop and deal with it. Well, none of that at all addressed here. Okay, so we have these two problems. One just running a block of tasks and waiting for all of them including their Children. And the other one is cancelation and error handling. And that brings us to task groups. They're super easy to use and their paradigm is very normal, very approachable for a python person basically. Do you know how to use a context manager? aka with block. So instead of with we say async with task group as tg. Instead of saying asyncio create task we say task group create task that associates it with this particular task group. And if that thing internally needed to make some tasks we could pass the tax group to it as well and it could change those on. Right Okay. So we took away the await. We're just gonna run the task group. When we go from line 57-58 we'll know that either there's an exception which case we're out of here or all those tasks have completed. Let's try it again. Back to searching for this beautiful search term. They like being a mongo dB orm go ah yeah look at that. So it ran it waited for them both to finish because guess what? There are a group of tasks working together and then down here both the task. None of this weird extra gathering to get the results and then working with the task results later. So very very nice. Again we're just touching the surface here. We're not using cancelation, we're not using error handling or anything like that. We're just using in a straightforward way but still really nice to be able to run these as a group and then wait just for them to finish.
|
|
|
transcript
|
0:41 |
Let's summarize task groups real quick here. So look how clean this code for our search turns out to be We just get the input text and we say async with task group and we use the task group to create these tasks. You do not await the task, you just create one and then the next and the next. If you will wait one and create another, then you're gonna just run them one at a time. This will run all the tasks in parallel, which is awesome. And then by the time we leave the task group will have all the tasks finished. So we can just work with the results. All results equals tp.result, which is a list. Combine that with the python bytes results list and now you have them both.
|
|
|
transcript
|
1:25 |
Here's a quick one. We'll just look at the docks. A time out context manager. So whenever you're talking to external systems that might time out, I'm waiting for the database to respond, I put something in the queue, I'm waiting for a response to be put into another queue after it's been processed. How long do you have to wait for that? Usually not too long. Sometimes a long time, potentially forever walking up your system, which is not ideal. So one of the additions we get is the asyncio.timeout context manager So in this case if we have some asynchronous task here represented by the long running task, async method And we want to run it for only 10 seconds and any longer than that becomes an error We just say async with asyncio time out 10. Put that into the context manager and either it's going to come out successfully or there's going to be an exception and it will be canceled. This will show up normally as a cancelation error or canceled error but the context manager will transform all canceled errors into time out errors, which you can handle as a special case. So there's a specific exception you're going to be able to handle that says the thing you try to do timed out through this async time out mechanism. Pretty cool. Check it out if that sounds useful. Here is the real easy way to do it in python 311.
|
|
|
transcript
|
7:11 |
we're going to look at another asyncio feature that might take a little bit of an example to get your mind around. I want to use a game as an example. So in games we often have this core set of operations that has to happen each frame that goes on the screen clearly you want to say take what the scene looks like and draw on the screen but there's more to it. Maybe there's a little bit of time has changed and you need to reevaluate the physics. Has this moving thing bumped into some other solid or moving object, in which case they have to have some change applied to their direction or it has to stop or it falls You might need to update the physics of the world. If the users are entering input on a control or on a keyboard, you need to take that they realize they push the button. What do you do in the button buttons pushed and you take some action there, maybe there's AI features running around and some of these things need to be done in a certain order. Some of it can be done up ahead. You gotta wait for steps and then more. So for example, drawing the screen, you might brought the screen to some invisible part of some sort of virtual, non visible screen and then as one final step, swap it. Otherwise you could see the screen drawing. You know, usually on a really fast game. That doesn't happen but you get flickering and tearing. Maybe you don't see the drawing exactly, but you still do get these artifacts that are not great. So we talk about this game loop, there's a bunch of different things. Part of them has to happen. We all get to this kind of the frame is done and then we do what happens for the rest of it. So here's a cool little example that talks about using py game down at the bottom. There's this section you can see to start the game and just create one and we just say game.loop over and over and over again. But how do we coordinate those different operations if we were to say, scale them out using async Io because maybe they're talking to external systems, like a database or we're using asyncio. On the file system or we're just using threads, however, we're coordinating them. How do we use these asyncio mechanisms to facilitate that? So let's go write some code here. We'll start with another new project kind of game. Like, I suppose I'll say in sync with barriers. So here we have our async method which is our game loop, and we're just going to say while true until someone exits the game and breaks out of this list. Well, we want to do a couple of things, we want to compute the physics, get the input and render the scene. Of course we could have more right. We could have the ai side we could have networking going on if we're doing multiplayer, all sorts of different steps here, but we basically want to group this into, here's the start of a frame, We're going to run them all together so check this out. We got our asyncio task group gonna run all the frame tasks when they're all done and we can consider the frame finished and start that loop over again over and over. Hopefully 60 120 frames a second, incredible how much computers can do when you really think about it, especially in the context of games here. However, right now we don't have a great way to organize it so look coordinate it. So we're here, we're going to do some work to print the screen and this is just simulating it 1.5 seconds and then we want to somehow wait for the other parts, like the physics and the networking and input all to happen and then we're going to do some cleanup work and carry on. Imagine that takes a little more time. Similarly, we're going to compute the physics, wait for the frame to render and then we could do another, you know, some other work to wrap that up. Same thing for input. Right, well let's run it, see how it works. It's going if we stop, what do we get here? Looks like the timing is good enough that they're not weirdly out of order or anything, but we do better. We say soon as maybe we don't need to do one of these sleeps with them. As soon as the work is done for one of them make sure we let it go. So that's where these barriers come in and here's how it works. We're going to create a barrier. It's going to be an asyncio .barrier three now again doesn't look like it exists does it? But guess what? It runs just fine. Why? because the same bug that PyCharm has with exceptions and 3.11 it also has with asyncio. I don't know what's up but don't worry about it. So down here we're gonna pass each one of these functions. A barrier and notice three here and three tasks. So the way the barrier is gonna work is if you try to go and interact with it you can say wait for the barrier to be all complete one task does it great. It's gonna wait a second task does it? It's gonna wait But as soon as the third one says I'm done and waiting all three of them together will be unlocked. All right so let's get in here and say that this takes B Which is an asyncio barrier And this one takes one and this one takes one how do we use them? See where it says pause here and wait for the other task we just see. b.wait now. That is an asynchronous task right we want to let other async work happen while this is waiting. So we await b.wait right now that's one trigger. It was just going to pause and do it again here. That's two waiting. But we said the barriers for three things so when two are waiting there still must be one going and then we say that here now that will be the third one when they all hit they all unlock this one will run that asynchronously. This will run that asynchronously and this one will run that asynchronously let them go see how they're all waiting done, waiting done instead of just popping out randomly at whatever time it is. You can see them coordinating the beginning runs, they all get finished and then all the cleanup runs, beginning all the cleanup, beginning all the cleanup. Very very nice. Now of course if this was a game you would hope this is an incredible slow motion because this would be you know seconds per frame not frames per second but of course it's going slow. So you get the idea all the work starts, they make some progress till they get to the point where they need to wait for the other sections to be done and then they're all released once every single one of them is done. Super cool. Huh? Not a real common thing that you have to do but if you're gonna fork off a bunch of work and you need to know how far they've gone and at some point like, okay, we're waiting here until the rest of it gets done, that we can do some more work on that same asyncio task. Well, here you go, barrier, it's for you.
|
|
|
transcript
|
3:40 |
Well, that was a lot of, asyncio there's a whole lot more in that great long change log that represents the changes to 3.11. I pulled out a couple more that I think are interesting but not really worth exploring with code itself. So let's see a few more first of all, github issue 97545 we have make semaphore run faster, so semaphore's are a little little like barriers, like I'm going to only let a certain number of things run, but they're kind of in reverse, like if you said to have a semaphore, five items, I want five or fewer to run, whereas the barrier says we have to have all five run than it goes. So it's a coordination mechanism much like that, that is very, very powerful and apparently faster in 3.11. Like many things, we also have a default number of workers for the thread pool, executor now and that is five times the number of cpu's a lot of guidance says, well the thread pool, the number of threads you should use optimally is exactly the number of processors in your CPU or number cores in your CPU not necessarily true one, you might have hyper threading, so you might want to double that two. If any of those threads are waiting on network stuff. So if a thread is talking to a database or an api or a file or many, many other things, it's not consuming the CPU, in which case you unlock more work looks like, that's what the python folks decided that five x is probably a good number. There was a loop parameter as an async iO event loop that was passed to a asyncio sub process and tasks function that's no longer needed awesome because it can just internally call, get the running event loop. There's a way to mock various things in python. There's that works on synchronous functions and classes but it doesn't work on async things. So we have async mock but apparently async mock didn't correctly patch static or class methods that were async Now it does hooray some more BPO-39349. We have a concurrent.futures.executor that we can run to coordinate different running tasks and you can call shut down on it. That now takes a parameter called canceled futures which will look at all the things that we're going to be run if there are any that are not yet started will be canceled previously. What happened is I said, well, you want me to shut down? Well, I gotta wait for all the work that's running fine. But also the work that's scheduled. So there's a possibility canceling the work now in 311 and this one caught me out when I upgraded really quickly to Python 3.11 and the Mongo dB motor. The async Mongo DB library was using this the asyncio.coroutine used to be the way that you would declare that a function is async by saying it's an at asyncio. coroutine of course. Now we just say async def. Such and such. This older way with decorators is gone. It said it was deprecate in 38 and is scheduled to be removed, was supposed to be removed in 310, but now it's really, really gone and I know because my code broke for a day until the Mongo DB folks fixed their library. All right, well that's asyncio in Python 3.11. I still have one more thing for you, but it falls a little more in the error handling than it does in the async side, but it could go either way. So maybe this is all the awesome stuff for asyncio. or maybe we got a little bit more coming. Nonetheless a bunch of great additions.
|
|
|
|
22:15 |
|
|
transcript
|
0:32 |
In this chapter, we're going to focus on two new features around error handling. The first, a new language feature that lets us capture or catch multiple exceptions in a single try except block Sounds crazy. We'll see why it makes a ton of sense. The other one has to do with performance and try except blocks, Python 311 has a whole bunch of speed ups for using. Try. Except these days, we're gonna explore both of those with some fun code samples. So lets get in to it.
|
|
|
transcript
|
2:06 |
We just saw task groups and how awesome they are. They let us kick off a bunch of tasks that are related to each other here. We're doing three things. Recording action to an external API. Or recording some action to the log file and we're recording it to the database. All three are independent. All three are working with external resources in some way and they of course all could crash. Normally when we write code and something goes wrong, there is one place where there is an error. Maybe when I called record action to the external api it crashed but if it didn't it succeeded, then we go into the next step that either passes or fails succeeds or fails and we go into the next one. But with async, especially with these task groups where we have the ability to launch them all at the same time. In fact, that's kind of the point of the task group. We could have multiple ones fail, The log could fail and the dB could fail. What do you want to know about that when there's an error? Do you want to know the first one? Do you want to know that the log failed before the DB did so you get that exception? Maybe you want the last one? What if you wanted all of them? So in Python 3.11 we have this exception group that allows us to group these multiple errors that it might have come into being as part of something like a task group. These are called exception groups and what you get is kind of a hierarchical set of exceptions. You get an exception group which itself has inner exceptions which themselves may have inter exceptions and you can dive down and see. But in that previous case we would get an exception group with two errors, one for the logging and one for the database. But there's also an extension to the language except Star that says I want to catch in a single except block. Wanna handle both errors in a single bit of standard -ish that you're willing to see the Stars. Standard, standard python, exception handling. Pretty cool. Lets dive in to that works.
|
|
|
transcript
|
9:17 |
So let's write some code that may or may not have multiple errors and you'll see what happens. We'll just play with it. So I'm gonna add a new file here. I'm gonna call this except star, again I want to start with some existing code and then play with it so you can see what's happening. So let's look at this code that I dropped in here. We've got Except star and we've got some async methods for logging and you'll see down here. That's external API log and database. Just like the example from the slides before and we have different types of exceptions. We have a DB exception and http exception of socket exception and others. So for example, this one can have an http exception. The dB can have a socket exception. For example, the database server is turned off. Right. So what we're gonna do is we want to record that action details not really specified what we want to record, but we're gonna use that as a task group to do these in parallel. Hey, we're in 3 11. Let's use the 3 11 features. Right, awesome. So we're gonna kick these off and I've written them to be specifically unreliable. Sometimes they will succeed. Sometimes will fail. Sometimes more than one will fail. Sometimes they all succeed. So what we want to do is we're, we know it's some sketchy code we're working with. So we're gonna run it in a try except block. Right now. We're just catching the exception and literally just calling Print X. That's it. No additional details. Like looping over the notes when we did that before. All right. So we're gonna run main it's gonna run this record. We'll do the task group to do sketchy things in parallel. There's an error. We're gonna print out what happens. Let's try the login. Api file file worked awesome. DB work. But we don't see the API. worked. What we got is a un-handled errors in a task group. Let's change this a little bit. So we print out two things, let's print out a type(x).dunder name and that all worked. No errors. Super. Okay. Look what we got is an exception group. Have a task group that started it. There were multiple exceptions. So we get, well an exception group this case there's one this message is 100% controlled by python. 3.11's exception group error. Okay. It's not something I did as you can see right there. So that's what it looks like. Let's try to run it outside of a try. Except, that one worked. There we go. Maybe that's more what you expected. So we try to run some code some things went wrong and then here's the exception group because two there are two sub exceptions. One of them is there's an HTTP exception. No can API. And there's a DB exception. No Can DB. Okay. So we get the trace backs for each of them and you could click over here and you would be able to see where that actually happened. Remember we called record action to external API. And record actually the database within the task group. So it's kind of a call stack relative to where the task group was. Okay so this is pretty cool. What do you do with this? So in a sense this makes it like a little bit less useful Comment that one out. If I want to capture an exception I just say well I'm gonna capture an exception group and then I've got to traverse this and dive into it and figure out all the errors. I just made my life harder. Didn't it? Not fun. Thanks asyncio thanks a lot. In fact let's replicate this. Alright so I'm gonna comment out this old one. Leave it here for you to have in its pure form And what we're gonna do is we're gonna catch the different exception types. So normally you would say except db exception as db accept http exception as 'HE'. For error. What are some other ones? We could do the file exception can't we? We would say catch that as FE. And let's just actually I'll just print the name real quick just so you can see are we hitting any of these do you think we'll see any of these. Right was any of these the top level exception that we ran into? Well let's find out. I'll run a bunch of times exception group. There are two exceptions. See if there's just one. There, there was just one. Which one? It was the database one. Well, we're catching up, we're catching the database exception right there. But no no no. What we were thrown is an exception group that internally, if you were to inspect it, it had one of these database exceptions in it. So check this out. We can use a different syntax, we can say except star dB exception. And let's right now, just the exception here like that, not the best formatting but it's going to work. This will be an accept star things that don't match. So watch what happens when we run it now there's a database on handled error and task group. Okay. And HTTP exception in unhandled error in task group but there were actually two errors in the task group Look at that 2 Except classes ran. That's what the except star does. It says find all of the http exceptions and things that are derived from that. And run run, send me a specific task group for those and the same for the database exception. So let's see what we can do to get a little more details here. So we're gonna go over here and say for e in db.exceptions. And I want to print dB exception will make this little f string here. We want to print the e There we go. We're gonna go through all those inner exceptions, there might just be one, but they're theoretically as far as python's concerned, there could be multiple dB exceptions that have happened. Let's try this again. So http just comes out like this. Let's find a database exception. There it is. Database exception. We got an error with dB. No Can db, if you care about the specific details, you can loop through it like this. Alternatively, we could just say something like this. There was an http exception. That's an error with API. File exception. There's an error with a file right again, notice now we're getting meaningful messages if we get multiple of these back in the database version, we get specific details about what that is and for the others we just say the type of error is enough information for us. Here's what went wrong now over here we ran it one more time. And one of these was some kind of exception that didn't fit into the HTTP. File or the dB exception. It was some other kind and it fell into this general except star exception here. So this might be another case down here where we want to print will say something like this. So we could say seven or three or whatever additional errors and then print out those details. So let's try that one more time. I'm gonna run it upon. Look, we hit all three except for the final catch all. Here we go. We have one additional error. No can db. I believe that's a socket exception. In addition, if we can't connect, we get the socket exception. If there's something internally wrong with the DB, we get the DB exception so potentially we wouldn't want to catch that up here in that section there. But check this out pretty wild. Huh? We can remove these unused variables here because we're not using them but we have this except star syntax that will capture one of these exception groups and partition it into basically by matching all those categories. Run multiple of these and it gives us one of these exception groups. We got to dive in deeper to figure out what's happening. So if you're doing a group of operations and more than one might fail. Here's a really cool way to catch those exceptions and but standard python, like error handling around what turns out to be a pretty tricky case of figuring out what's happened when you get multiple exceptions except star and exception groups.
|
|
|
transcript
|
1:49 |
Now the example that I gave you was exception groups and except star for async, you might be thinking I never do async stuff. So not my problem. I don't care the idea of these except stars and exception groups certainly could be expanded and may be expanded in certain libraries beyond that. So for example, obviously we have the concurrency story that we spoke about but you might also have the retry operations. Have you heard of the library package Tenacity? It comes with the decorator that you can put onto a function that says I'm gonna call this function and if it fails, try it again fails again, try it again up to five times and maybe slow down and call it more slowly. Like maybe the database server is being restarted and you need a 10sec window so try it. But if that fails, slow down, but if it ultimately tries five times and then does completely fail, you might want to know all five errors. So multiple failures when retraining operation, that would work really well with exception groups and except star. If you have multiple user callbacks fail, for example, you can register at exit and potentially multiple exits could fail. You might want to know what's going on here. There are multiple errors in some kind of complex calculation or in wrapper code, for example, the temp file temp directory context manager had a problem while processing exception, it couldn't clean up. So it raised its own exception. In addition to the exception exception that caused it to clean up, you might want to know about both of those. That's just some of the ideas of how you might use except Star and except exception groups. That is not just concurrency.
|
|
|
transcript
|
6:07 |
Here's another one of those features that is either for error handling or is for performance. You know what leans a little bit more towards the error handling. So we're going to talk about it now, but it just as well could fit into the chapter where we talk about performance and that is zero cost exception handling. Did you know that if you were to write proper python code with try except blocks, you paid a price for that? Not a huge price, but there was a performance cost even when it succeeded. Well, as part of the faster c python team, Mark Shannon and a bunch of other folks as you can see here worked on making exception handling basically free not have any overhead unless there's an error and in which case it becomes slightly more expensive but that's the exceptional. Not the standard case. So I think that's the right choice, let's play with that. So let's call this zero cost exceptions first. I just want to start by having a little bit of code to play with and just seeing how it works So let's drop this in here. We've got a troubling method. Was it troubling. Well, it may take a crash, it may take a header, so we pass in some kind of string and its job is to convert it to an integer and it just tries goes into of X. That better work. We might get a value error and says, Oh no, well that didn't work. In which case it returns -1. It might get some weird or like maybe the thing we passed in had this ability to be converted to an end but it through an exception, say it wasn't implemented or we just don't know what's wrong. Right? Something went wrong. It has all these print statements. Obviously that was probably not what you would do but no matter what case, either returns this value or this. So we call it with a good number like this, Let's do our name convention here and try again. We get 77 So 77 is great, we do it 901. We can even call it with I know 2 as an integer and it should work But you know the typing says don't do that but we're gonna do it anyway. Right? What if we pass this number 9 900 will that work? Let's try. Oh no, it couldn't be converted because of values invalid, literal intent with a base 10 900 we got negative one. Alright, well that didn't work. Standard python code, I mean it's a little contrived but this is kind of how you're supposed to do it right? You try to do the thing, you catch the exceptions, you handle them, deal with it. So it turns out that to write this part, even if everything succeeds in previous versions of python, there was a price to be paid. So let's see try from dis import this Now this is a thing, we can call on a function that will or class or different things that will show us the python byte code commands. So basically the assembly language, the lowest level building blocks of what python actually does because a lot of times you'll see one line like this, like oh, that's one or two lines, that's a bunch of things happening. The python has to actually do to make that work. For example, pointing out that it's entering an exception block. Okay, so in addition to this, let's just do dis of troubling method, take away that run it and there we have Oh, a bunch of stuff. All right, now, this is only somewhat interesting on its own. Let's actually take this, let's go out and run this two ways here, Way on the left will say Python 3 11, this and we'll say Python 3.10 this what I want to do is compare the byte code that comes out from each of them and show you the actual byte code that python uses, what actually happens in the python run time is different now than it used to be. So there's this one, there's that one notice, first of all, there's an exception table. That's kind of interesting. Well, let's go to the top where we right there to resume. The first, the first line there. This one starts at eight, but that's fine. We get the top resume kind of nothing. No up is kind of nothing. Then we load fast the X, the value of X and then we do a pre call and I call this is I believe an optimization from a specialized interpreter. We'll get to that later in the course and then we return the value. So notice those five those five statements there, there's nothing about exception handling. But if you get past that you don't do the return value, then you push the exception information, you load up the value error or you load up the not implemented. So you do this extra work right here and then you go into the exception handling. That's 3.11. That's the new, the new goodness over here. What's the very first thing set up? The finally the final thing that you're doing and then we're gonna run down here, do the stuff that we already did, that's this. And then we're gonna pop things worked. It looks like we're gonna pop the exception block and return the value. Otherwise we get into the exception handling. So notice 3.11, If things go right, we don't see anything about exceptions or finally or working with the exception blocks. It's only when there is an error that we pay the price. So pretty cool. Other than that though, it should have run exactly the same. We should have 77 901 1 null, it couldn't convert and we do, behaves the same its just a matter of performance
|
|
|
transcript
|
2:24 |
Let's actually test the timing. All of those things were fun. Right? We can run this once here as well. That was fun. But let's actually see how long this is going to take. Let's try to run this code and see if it makes any difference whatsoever. So what we want to do is we want to call that function troubling method 10 million times and see how long it takes. But that number over there will say for. We're gonna go loop over that this many times and I'm gonna say the elapsed time, it's gonna be done in some number of milliseconds with two decimal points and digit grouping. Let's run and see what happens. We go 922.26 ms I suppose we don't need the decimal points, but they don't hurt us there. Do they run it a few more times. There's a decent amount of variation. I gotta tell you, screen recording over webcams and the screen puts a bit of a hurt on the computer. But let's give it a shot. Now, you saw it over here in 3.11. A few times. Just to get some numbers. Okay, a little faster. Here we go. I'm gonna say eight. Let's pick the lowest number. We got 8 40. That was decent. Let's try the exact same code. Just running python 3.10 Still over 1000. What are we getting? What's Our best So 1,035, Divided by 840. Well, that's 23% faster or slower for a python, python 3.10 3.11. Not going further back than that. Right? Not looking at 3.8 or 3.7, but the very recent most recent version. Right, So this looks like you got about 20% faster. Because guess what? We're not paying the price to set up the try block, even when it succeeds. And remember most of the time, if you're writing good code and working with somewhat reasonable data, it's going to succeed. So why pay the price for the odd exception case when using 3.11? You dont.
|
|
|
|
18:55 |
|
|
transcript
|
1:15 |
We've come to the headline feature, the headline advantage of Python 3.11 and that's performance. I said at the beginning that these better error messages for one of two major things. Well, here is the second and for me, this is actually the biggest and most important change, Python 3.11 is maybe 40% faster than even python 3.10. And for something that's been around and been maintained and improved for over 30 years to make that big of a jump in just one year. It's incredible Guido Van Rossum, Mark Shannon and a bunch of other folks over at Microsoft as well as other core developers. But there's a special team at Microsoft specifically focused on making CPython faster, you know what they're called, the faster CPython team and their goal is to continue making these improvements, these big jumps over the next couple of versions. This is really the first one that gets a big boost from that work. So it's just the beginning, but it's really, really exciting in this chapter. We're going to see some of the features that make this possible, but not all of them, there's a bunch of small changes in a few really big ones.
|
|
|
transcript
|
3:25 |
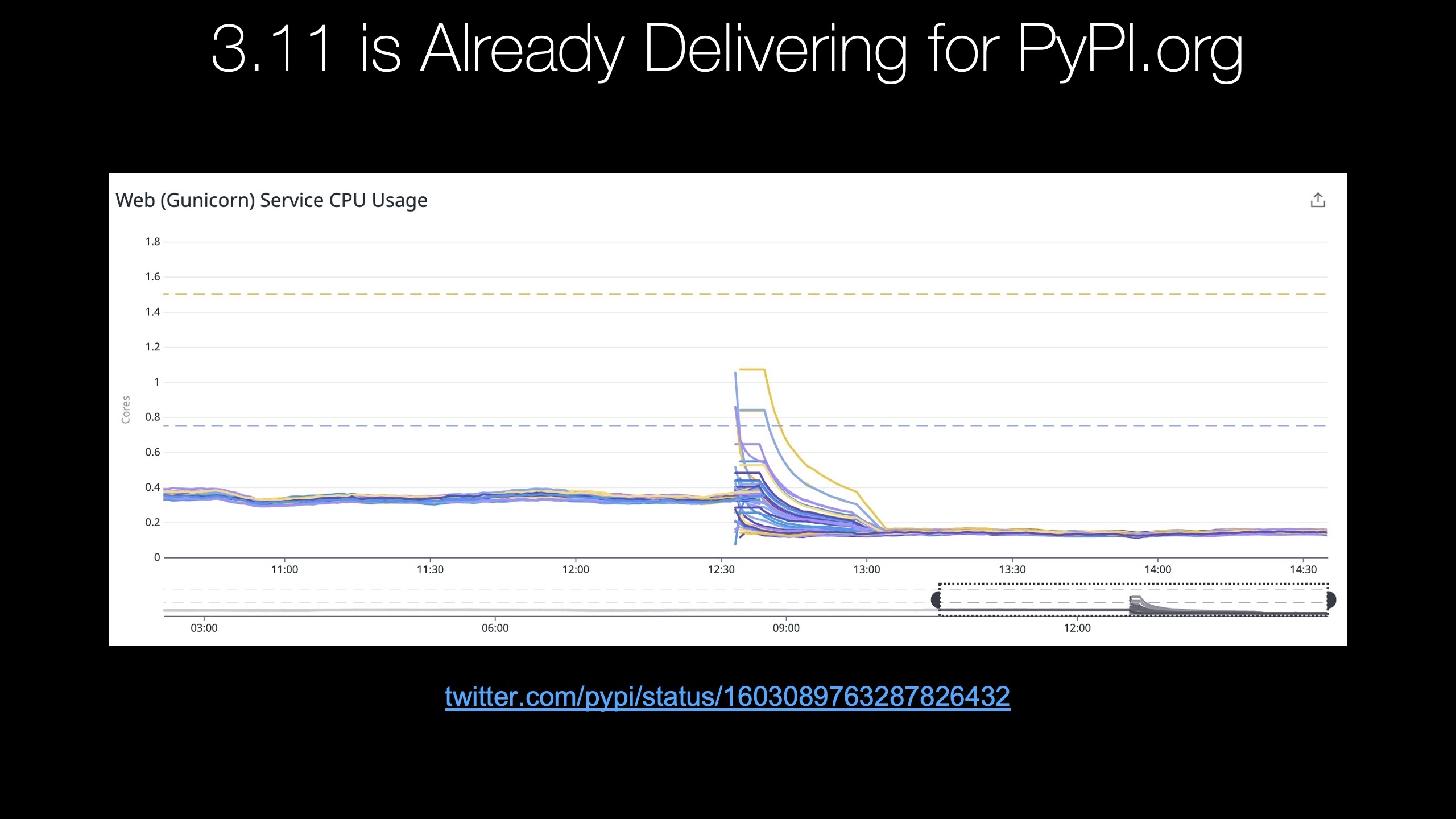
I want to dive into this performance, signed a Python 3.11. There's a couple of cool places to look over here on this website, there's a post with a whole bunch of benchmarks and graphs, you know, pages and pages of them with different graphs showing Python 3.11 versus the three prior versions, 10, 9 and 8. And the title of this post is Python 3.11 performance benchmarks are looking fantastic and oh yes. Oh yes, they are. What's notable here is this is actually published in june so this is just the beta version. This isn't even the final, most polished, most optimized version of python. And here you can see 3.11 beta is almost 50% faster than 3.9 and 3.8 and 40%. I'm just eyeballing it here faster than 3.10 on this particular benchmark we saw with the no cost or zero cost exceptions, that part of python got maybe 20% faster. So really, really nice to see all these improvements if you want to dive in, you can look here. The faster CPython team says sometimes there's no improvement. Sometimes there's 10%. Sometimes there's a 2x improvement, you know, 100% better. So your mileage will vary depending on what you're doing. But this is really great. There are many people who suggested. Well pythons too slow, you've got to go to some faster language that's less true now. Also, I don't think it's that true in the first place for many, many use cases. But if it was true, it's a little bit less true now, this is, this is fantastic. Let's take another example here. If you look at PyPI.org, that's the python package index. They keep very detailed analytics of the CPU usage of their web app, Their G unicorn service powering many, many requests on PyPI.org. It's kind of unimaginable. How much traffic, how many terabytes of traffic this website does but check this out this is from when they switch from running on 3.10 to 3.11. You can see it's running around again. I've also at 0.7% or so, of usage before and then it drops down to half 0.35, something like that. It's not entirely obvious here. If you zoom out. Well, look at this graph here. Okay. The graph on the left before the big spike is 3.10 The graph to the right when it's all smooth as steady state warmed up. 3.11. That weird crazy spike in the middle is where they had to shut down everything flush out all the caches and the system had to build back up. Things like it's cache and whatnot. So there was a little bit of spike as the system was restarted. Had to warm everything up again. But once it got going, look at this really, really a massive difference. I mean that's, you could probably have half as many servers. That is no joke. And that's just going from 3.10 to 3.11. not like from 3.6 to 3.11. Right. This is a very, very small jump inversions and yet a huge jump in performance. So Python 3.11 is definitely delivering for PyPI.org.
|
|
|
transcript
|
3:24 |
So how exactly is Python 3.11 40% faster than just the previous version? Well, it starts with something that was called the Shannon plan, as in Mark Shannon had this plan to make python five times faster over five years along those lines. The idea was every year to make an improvement. Kind of like the one we saw here. And if you compound that over four or five releases, then you end up with python being actually five times faster. It's really exciting the progress they've already made, so five times faster than a couple of years possible. You want to hear more about the plan, a lot of the details of what they've been doing again, there's a bunch of small things that we're not going to focus on and code here, but there's a few big ones that we will. So if you want to hear about how they plan and are making python this much faster. I did a nice interview with Mark Shannon and Guido van Rossum. you can check out the link here at the bottom, This is talk python to me, episode 339. So this was before the 3.11 release. This is kind of the beginning of when 3.11 started development I think. So, really, really cool to see what they're doing here and if you want to learn more about the overall performance story, check this out. One of the important, one of the most important pieces about making Python 3.11 faster is this specializing adaptive interpreter? The idea is that normally we saw this with when we disassembled our python code previously we have these byte code operations and usually what they do is they assume more or less nothing about the type information or the specific operations available on an object. So if I'm adding some things you might have to go figure out well what types are these and then what operations do we actually call to add them all? These are floats and integers. I see. So here are the steps but if you knew in advance that you were adding to floating point numbers, you could do that way faster. And similarly if you knew you're adding two lists together, that's a totally different operation. Theoretically you could do that a lot faster. And so this specializing adaptive interpreter starts out in this general way of just a traditional way python has worked and then if it sees certain things that it knows about and it knows it can make faster, it will replace those with adapted specialized bike code instructions that say don't just call the add operation but in fact add to floating point numbers, which as I said would be a lot faster. So you can see this code highlighted here on the screen. This is a project called specialist by Brandt Bucher here. He is on the screen next to me again, I interviewed him about this on talk python 381 you can check that out. We're going to be playing with his project specialist which will let us look at some existing code, see how the adaptive interpreter is treating it and seeing if we can make it any faster by taking some advice and specializing or helping the specializer make special instructions where otherwise it couldn't. So we're going to play with this in code next.
|
|
|
transcript
|
1:06 |
Well, let's write some code and explore this specializing adaptive interpreter. We're going to use brandt butcher specialist tool here to do so. So what we're going to need to do is we're just going to pip install this now. We're not actually going to use pip, we're going to use pip X specialist is like black or to some degree like pytest or these other tools that are not actually used as part of the runtime of your app but it's just something you run against your code. And so it's more of a like a global utility than it is part of your application dependencies. And so for that reason, we're going to use pipx, pip x lets us, install and manage and update global python command line tools. So let's do that. You have to of course have pip X installed, see the website for details. We'll just pipx install specialist. Now we have a new command specialist. So let's go over to our code and check that out.
|
|
|
transcript
|
5:47 |
Let's start with the code that is really similar to what you would find on the Git hub specialist page as the example. So real simple, what we have is a function that takes Fahrenheit degrees and converts them to Celsius. Of course that's subtract the 32 to get it to the zero point and then multiply by 5/9 to convert from the step size of Fahrenheit to Celsius. And of course you can do that in reverse the other way. There's a bunch of test values that you might want to test and see how they get converted here We have this function called test conversions and what it does is it loops over and it just checks to make sure that if we go from given a number a degree from Fahrenheit to Celsius and then Celsius back to Fahrenheit that those are the same as well as reverse Celsius. Fahrenheit then Fahrenheit, Celsius is the same and just prints out some simple things there. Alright let's go ahead and run this I suppose. See what we get here. You can see looks like it's working Zero Fahrenheit is negative 18 ish Celsius and 32 is of course zero Celsius. There's some other ones as well but you know you can see these test values putting out reasonable numbers it looks like the code works. This is not about making the code work, it's about understanding what the specializing adaptive interpreter can do with it. So for example, up here notice we have a floating point being with an integer subtracted from it. It turns out the way the specializing interpreter works, how it adapts for the moment is it looks for the same type. So do I have a float in a float? Well in that case we can speed those types of operations up. It'll help us look through this code and see if there's a way we can give a little nudge to the specializing adaptive interpreter to make it work better. So let's go over here to the terminal and here we are in this specialist start. I have a start and I'm gonna have a final because we're going to change this in a moment. In fact, let's go ahead and give us the final because we're going to make changes to it right now. It's the same. Right? So look at this, let's run special list in the final like that. What it's going to do is it's gonna parse the file, understand what's happening and then it will generate an html report for us. So here we have that report for our code. This stuff down here just ignored. It doesn't matter. This is not something we can optimize. Like we don't care about assert or strings. Similarly for looping over our test values, it's just those two functions that we might consider performance critical, doing our Math and we want to pay attention to them. Notice two things here, there's green. Green is optimized, we can do all sorts of cool stuff with that, although not much yet. Yellow is a little bit of an optimization but not massive. And then pink is we couldn't do anything with that. So Pink is not good. Yellow, not great. Alright, let's look at this. Why is this one not optimized again, a float and an end. It seems like well, maybe the system could do that for whatever reason it doesn't at the moment. So if I just put a 32.0, well all of a sudden that's a float on float operation and it makes no change right. The result of this is going to be a floating point number anyway. So if I go ahead and get ahead of the game and make that a float, it's not going to hurt it. So let's go and run that specialist again. Move this over so it doesn't get hidden by the presentation assistant. Look at that. This line is now going to be fully adapted to work in a higher performance. More specific version of python byte code that knows about floating point numbers, not arbitrary edition because if you add strings, you get something different. If you add lists, you get something different than if you add floats. So it doesn't have to be general like that. It's like, nope, these are numbers, let's do that similarly. Let's look at this one here, we have a float times an end. This is the order of operations. And then divided by an int we can make a super minor change here like this. We can put parentheses here and just basically change the order. This is going to become a constant that gets evaluated at parse time by python into a float. What do we get if we run this now? Check it out, cycling back and forth. You can see now that float to Celsius thing is fully optimized. And let's go ahead and apply that for the Celsius 1 as well. We can force that constant to be computed before and we can go ahead and turn that into the float that it's going to be anyway. There it is. And forget about the stuff below these are the two functions we care about. Let's see that they still run and give the same numbers, you know? Sure enough. Here's the boiling point tests. Here's the zero point tests. Different directions, same still works the same obviously. But we've given it a little bit of help and unified the types involved here and that's going to make the specialize adaptive interpreter work a little bit better.
|
|
|
transcript
|
3:58 |
Notice we have this function called round trip that does basically the same thing here without the print statements and the asserts, if we time how that function runs, we should be able to see if there's any sort of improvement. Right? Let's write one more function here. We'll put it maybe by the test conversions, we'll say a def test speed. And let's go in here and say we want to run this a million times but we've got all these test values, We want to use eight or nine or something, so we're going to divide that back so that when we loop over it and then loop over those values, the ultimate result is around a million operations. Okay, So what we're gonna do is instead of doing this other one down here, we're gonna say test speed. Now I need to put this into both because we want to see it before and after. Right. All right, now let's go ahead and run the this one 149 milliseconds. We'll run it a few more times. Go, it's around 100 and 140 145 150. Let's run this one. This is the one we've helped the specializer do more. 113 115 1 18. Oh yeah, 107. awesome. So we went from around 145. 150 to 108. What is that? 35%, improvement roughly awesome. That is really cool. And now remember what we're doing is not running this under an old version of python and then the newest version of python and saying, look, the new version is faster. Both of these were running under Python 3.11. It's just a matter of did we use the information that we got to write our code slightly differently so that the specialized in adaptive interpreter can run with it or do we just leave it the most naive way that we might have written this code and then hope that it ran fast. Now. This is not something I would go crazy all over my program and just make sure I'm doing this everywhere. I wouldn't worry about that. But if you're profiling your code and then you find a spot like this part is doing a little bit of math and it's run a lot of times. So it really matters that this little bit, this little portion of the math in my program matters. You know, maybe a couple of parentheses conversion, pre conversion to a floating point number, something like that would help you a ton Now. The folks over on the faster C python team Brandt Bucher and folks said look, the intent of this tool is not really to help you rewrite your code. So it's faster it's to help them understand the adaptive interpreter on different code so they can continue to make it faster and that's great. That'll just make existing code go faster and faster But you know, this is pretty compelling 35% faster by putting a couple of parentheses in floating point dot 0.0 on there. That's a really easy way to make your code go faster. And if it really does, I don't see why you wouldn't want to do this again in a limited few places where there's really hot loops, really important calculations that run over and over. So that's the specializing adaptive interpreter in Python 3.11. Mostly it's automatic, but you can see that you can write your code be more in line with what it can help you with or kind of out of line where it's decides it can help you. So go play with your code again only where it matters. Dont over complicate it.
|
|
|
|
12:49 |
|
|
transcript
|
0:52 |
Way back in 2014 and Pep 484, Python introduced type hints or type annotations and it goes by both names These are great little additions to the language. They don't have really much effect or any effect depending on which framework you're using on how your code runs, but it lets your editors be smarter. It lets linting tools like mypy look at where you're calling a function with a certain variable type and what you declare. It's supposed to take and check and make sure everything's hanging together. Much like a static language like C# or java, but not with all the restrictions of a true static language For me it is a great middle ground in Python 11 Bring some cool new features. Let's go see what's new for types in Python 3.11.
|
|
|
transcript
|
3:11 |
Here's an example of python typehints and action. We have this function user by id. That gets us a user given its user id. And possibly returns its user. You can see the blue typehints, it says that the user id. Must be an integer. it can't be none. It can't be a string, has to be an integer. And the return value is one of two things. It's either a user that was located by finding it from that Id. Or possibly you could have asked for a user Id. Whether is none. Maybe we have 100 users. And you asked for a user? One million. Well we got no answer for you there. So you're going to get none. So optional of user or you could write user pipe None, if you prefer, tells us that it's either going to be a user or it's going to be nothing And that's super helpful when we consume this function, we can know exactly what to do with it. So these typehints, as I said in the opening are really, really great. Sometimes though they're not as great as they could be. Due to the way that python creates classes and functions and all those things. It doesn't use a compiler where it pulls out the types and then compiles it and then sort of re evaluates things like some compiled languages does know it just goes from top to bottom and says I'm gonna execute this code The execute class colon user means will begin finding a class called user. It's not done until you get all the way through that, but it's going to start it and we'll hit the def init. Well, now we're going to define a function init. The internals. We can get that later. But right now we're going to define a method that goes with that user. Then we get to this next one here def. Same gonna take the self that's current object in another user. That other user is supposed to be also the user class we want to use Typehints to say that here, look, this other user colon user. But I haven't read something's wrong, isn't it? Red is not good. Not in this case. What's the problem? Well, we can't say the user class because we're in the middle of defining it. But this step that we're trying to propose with type ins is actually saying we need to use this type that presumably exists to say what types here. It's like, well, we don't have that yet. We're still building it. Hang tight. I do think python should be upgraded to just say, look, we're going to put a little placeholder here and come back and fill that out. But that's not how it works. No, this is how it works. It says crash. Crash. Crash. Name, error user not defined what gives. I mean, look, I did exactly the same thing in that function. Get user by id and it runs just fine. I said there's an optional user, but here, when you're inside of a class, you cannot use that class, the name of that class. You get this crash. Well, python 3.10 and before had one fix, python types in 3.11 and above have a better fix. So, lets go and explore in code.
|
|
|
transcript
|
3:47 |
All right, here we are in Chapter six. Let's add type self. So we're gonna play with somehow referring to yourself within a class. Now let me take the code I had from that presentation in the slides there and here you have it Sure enough. PyCharm is warning us something is going wrong. Unresolved reference user. This has always been confusing to me because guess what? I'm literally within the user class. How can you not possibly understand what the user is? However, if I try to run it sure enough, name, user is not defined. Well that's unfortunate, Python 3.10 and before had this interesting way. If you put this in a string and you hover over this it's kind of gives you this weird color of the string. And if we say U1 equals user. U2 equals user. Let's give them some id's Two and one have to be we have U1.same And what goes in here notice it knows it's a user not a quote user but a real user User. Say U2. And I can even print out whether they are the same like that, are they the same? No because they have different ideas. But if for some reason we make their id's the same then yes. Yeah that's good enough for us. Sure enough, they're the same. And so this is how you've done this previously and it's a bit of a hack. Right? So we say it takes the user now notice again because and by the time line seven finishes running the user class is defined. We could have that other function I wrote. So here if we're going to get this let me just say user of user Id. Right? That's a bit of a hack. But let's say that's what we're gonna do notice here, we have our user right there and code runs. No problem at all. So it's only within the class here that this is a problem. So let me go and give this a slightly different name. We'll just change the name for the next one. Let me call this 311 because this is gonna be the new feature, not the old one with the quotes. So now what we can do instead of having the string hack, we can come up here and we can say from typing import self, this is a Python 3.11 thing. And within a class we can say, look, I don't know what you are, you're not finished being defined yet. But if you're up here, you called yourself user down here, you're going to call yourself user again. Alright. And by the way, let's come back to the old one. Let me just show you that if I asked U1.same as the number seven, it gives you a message and says no no no we expected seven. So we get expected a user and we got the number seven. The same thing will happen down here and way of self, If I say U1.same as seven, what's it gonna say, expected user matching generic type self now. And instead we got this end. So a little bit more theoretical way of explaining what's going on here because the generic as well, we're not seeing the type explicitly, it's inferred from the type that is spoken within in this case the user class, but you can still see that that would give you the same error, so same type of thing. But now you don't have to have this weird hack and for some reason you change the name, there's not this string that's hanging around that no longer makes sense. A little bit more hide into the type system. Cool,right.
|
|
|
transcript
|
2:03 |
There's a bunch of other features for python types in 3.11, 6 or seven that you might really want to pay attention to but they're not that commonly used this one though If you're doing anything with something like mypy where it's doing validation of the types really carefully or presumably editors like PyCharm will adopt this. Although we saw they're not really doing with the current feature so they're not doing with this one either is something called literal strings and we've all heard of SQL injection attacks and other types of injection attacks. Think of like the log for j log for shell problems as well. There's a bunch of them. So here we have a query that's entirely safe. It's a literal string. It's not made up from variables or combined at runtime. It's just static and it says select star from users where validated is true. Hey give me all the validated users easy, easy to do now. We might have some code that it's not as good. Like what is your child's name then we'll say select star from users where name is quote whatever they typed in they typed Jaimee, you're probably going to get the kid named Jamie. But if you're feeling a little mischievous, maybe type --semicolon drop table users semicolon--. What does that do? The first quote in the name closes out the opening quote in the name equals so it would say name equals nothing and then the semi colon ends at select statement says new sql statement drop table users in that statement --comment out whatever's after that so that it won't make the results invalid or crash. So for example, if there's a transaction so you want that to commit, this is not good. This is not good and this is not a literal string because it's made up of different variables at runtime. That's not fine. See xkcd exploits of a mom to find out exactly why.
|
|
|
transcript
|
2:56 |
In the type system in Python 3.11 we now have an explicit type for a literal string. This is not a new class or new thing that you create instead of a string with quotes in python it's just the type system. So here's an example. We have this function that's gonna execute sql commands. You know what we don't want to do take arbitrary strings combined from user input and run them against our database New, that's a bad idea. So what we can do now is we can say from typing import literal string and then the sql query itself is the literal string. Here's a literal string, select star from users where name is like some percent thing and then we can say for u in users execute this where the name is like Sarah and notice we're using the question mark. That means Sarah is being passed as a database parameter to the query where the query syntax itself is fixed. The database knows where that question mark is. That's where we put the value of Sarah and that can't be combined a short circuit. Some kind of sql statement or inject new ones. So this one is totally safe. This comes to us of course from Pep 675. On the other hand, if we tried our trick before select star from data where these ideas this we tried to execute it not at runtime but at mypy checking time we would get something like error. We expected a literal string but we got str again. Both of these are really classes instances of the string class. it's just a matter of were they created with input from parsing some kind of F string or string dot format or the actual literal strings? One final comment on this as well. This one's valid literal string here sql select star from users. We can combine it with addition, like plus or other types of things with other literal strings. So we could have an if statement that says if you want to sort sql plus equals order by name or order by date registered or something like that. That would still be a literal string because both the original and the thing being combined with it or literal. So you can do interesting things with these literal strings. They don't have to be purely static in this sense. They just can't be taken from variables and then have not formatted to generate the string where who knows what got into the string. Alright, that's the arbitrary literal string type and PEP 675. Pretty cool. Hopefully that leads to just a couple of less. XKCD jokes about sql injection, at least for us, python folks.
|
|
|
|
5:28 |
|
|
transcript
|
0:35 |
Well out of that huge change log and all of the changes for 311, we've covered the major features and the major changes. According to Michael. However, there was a bunch of others that I think are worth giving a quick shout out, get some quick awareness for. So that brings us to our final grab bag of assorted items. We're just gonna go through a quick list and point out some of the additional changes that might be relevant for you as you go forward and upgrade your projects from older versions of Python2 3.11 and beyond.
|
|
|
transcript
|
1:24 |
The first subtopic here is file formats and the big one here is TOML. So you're probably familiar with toml. Will you use it to do things with Docker? You use it for clearly the pyproject.html, which is becoming the new replacement for setup.py and packaging. Previously. Until now, if you wanted to work with toml, will you had to go find a separate library? Unlike Json? Right. There's a Json library right inside of python that just comes with it. But toml, even though we had pyproject.Toml and it was used for packaging, you had to get a third party library. Not totally weird for python. There are over 400,000 packages on PyPI. However, some things cause this maybe you don't want to have to depend upon external TOML libraries and with 3.11, you no longer have to, we have bpo-40059 and that's also PEP680. So, the Toml lib module now includes built in parson for Toml and mentioning Json if you're using the Json decoder, it now raises a different type of exception. A Json decode error instead of a value error. So, if you've got code that catches the value error out of the Json decoder might want to go have a look at that and update it.
|
|
|
transcript
|
2:10 |
We spent a lot of time talking about performance in this course. However, there's a few more I want to throw out that didn't really justify their own section. So we're gonna talk about that here inlining opcodes. So we have inlining upcode caching according to this issue here we have in line caching for load attr as well as store attr and we have it for load method as well. So some of those byte code caching operations are going to be much faster. Same thing for binary subscript and for the compare operation. So a lot of opcode caching which is fantastic. We also have better performance around strings. So if you're using find, rfind both of those have improved algorithms that are faster couple more here we have speed up of the iteration over bytes and bytearray by 30%. That's great. Very very welcome there. And this one is probably the most important. Maybe tied for the byte code one but certainly right up there is list.append and list comprehension are now faster. We use list of apennd and comprehension all the time. The way lists work is as you add a new item there's sort of a buffer even if it has zero items that might have some space to store that let's say 10. I don't know the exact numbers off the top of my head and then you add one and another and it knows there's two but there's really memory space for 10 pointers and then once it gets past 10 it's going to grow and not just grow by one more byte and one more byte. That would be really tricky to have to copy for every append. So it grows maybe by doubling, so it might go from 10 to 20 places and then add the 11th and the 12th. It's now surprisingly before it wasn't is now optimized for that case where you're adding an item and you have space already because of that doubling of the actual memory that it manages versus the number of pointers So most of the time it's just going to be putting pointers into existing memory and resize is required, it's now optimized for that,awesome.
|
|
|
transcript
|
1:19 |
The final subcategory is removing dead batteries. Well there's the saying that python comes with batteries included. Most of those batteries are awesome, some of them are seriously outdated or just don't make any sense. So here's a list of modules that were previously in the standard library and are no longer built in. So if you want to do something like an. NNTP You've got to find a proper replacement somewhere on PyPI. I'm sure it exists. So there's a bunch of things have been deprecate id, you can see PEP 594 to learn more about that actually did a whole episode with Brett cannon and Christian Heinze to talk about the plan, how they're doing that. You know this was quite a while ago they started thinking about removing some of these modules. There may be more to come. I can't remember the entire timing of the whole list. Some things were on the list then they were off the list. Anyway, if you want to dive into this removing dead batteries side of things, there's this great episode that we did together, you can have a jump over there and have a listen. Well alright, that's it for the grab bag again, just scratches the surface. But this is the stuff that stood out to me that didn't justify its own section.
|
|
|
|
0:57 |
|
|
transcript
|
0:57 |
Well, there it is. That's Python 3.11. What a huge release for just one year. Huh. I hope going through this course has been really helpful for you. I know when I saw those features, I was like, great, these look really neat, but they didn't really connect with me until I got to play with some code and see them in action and consider some of the trade offs. So that's what I wanted to bring to you through this course. And hopefully you found it really valuable. Remember to go check out the github repository to start and fork that repo So you have all the code to continue your exploration. Follow me over on mastodon where I'm @mkennedy at fosstodon.org and be sure to check out other courses here on talk python and our podcast as well, sincerely thank you for taking the time to take this course and supporting all of our work. Good luck with your Python learning.
|