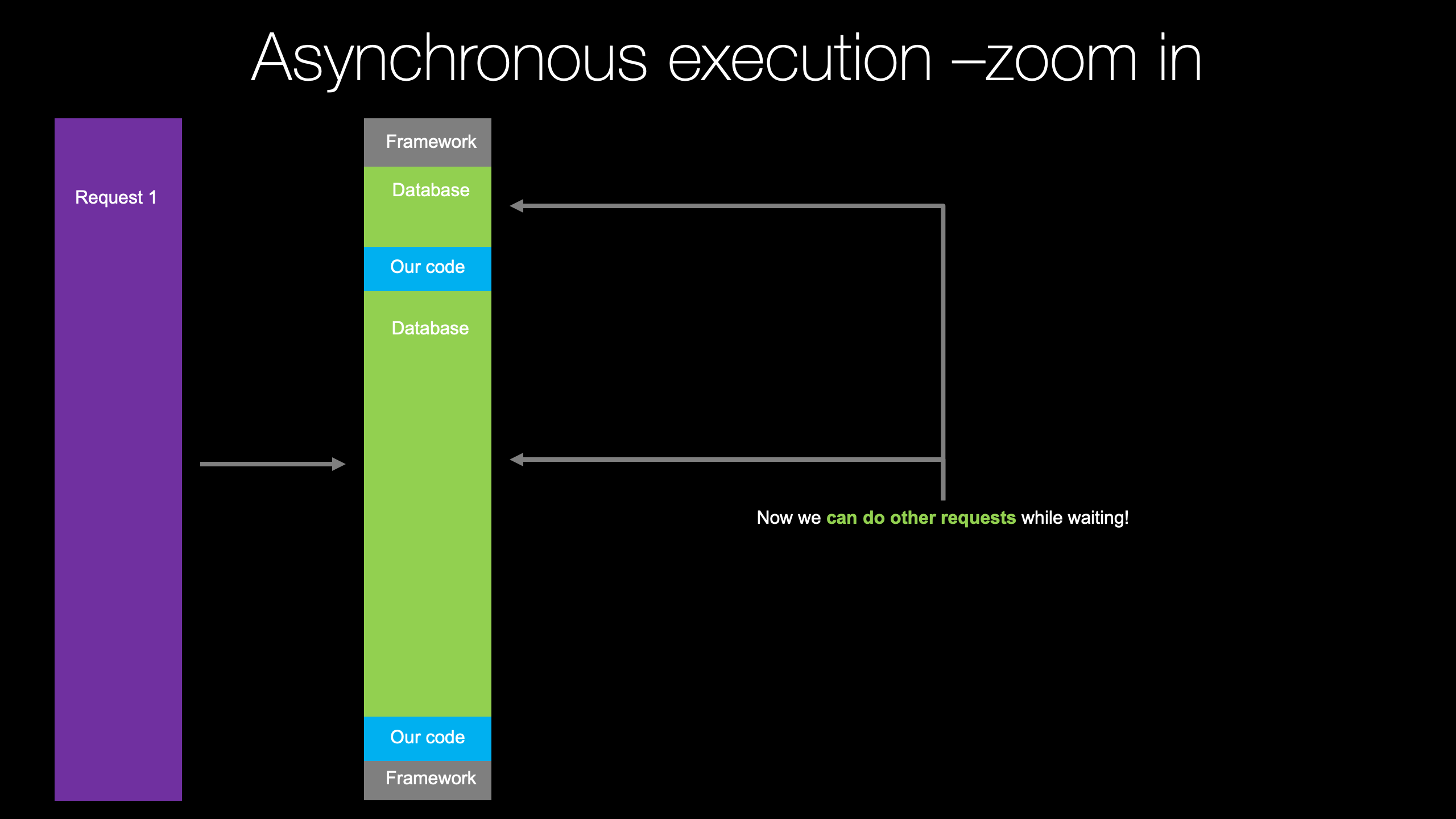
|
|
|
12:47 |
|
|
transcript
|
3:01 |
Hello and welcome to Full Web Applications with FastAPI. Applications, that's the key word about what we're gonna build in this course. FastAPI well, it has API right in the name, it's really, really good at building web APIs. But, as you will learn during this course, it's also really, really good at building web applications. Many of the cool, modern features of FastAPI can, with a very small amount of effort, be applied equally to web applications, those that generate HTML for browsers and humans, as it does for JSON, which is intended for computers and computer software to exchange data with each other. So let's start with this really important question here. Should you be focused on building an API or a web app? In the API, we're going to build applications that exchange JSON, they deeply leverage the HTTP verbs like GET PUT POST DELETE and so on and they exchange data that is generally unseen. Just a little progress bar spinning in you're app and then data appears, or do we want to build some kind of web application? Somewhere on the Internet users go and type and they show up on your page and they've got really cool dynamic HTML. They can go over, maybe create an account. They log in, they interact through their web browser. Now, this is a challenge that basically everyone has to deal with if they're building a rich application, say a mobile app, and they're going to build a website that corresponds to it. So often this is presented as APIs versus web apps. I maybe want to build some API or use an API framework like FastAPI, so that I have this great way to build APIs And then we'll go find another way to build that web app or we've already got our web app. How do we add an API to it? Do we have to completely start over? Good news, what you're going to see in this class is that it's not "or" or "vs" or anything like that. No, it's "together". I will show you how to build APIs in FastAPI and then mostly we will focus on building fantastic web applications. We have another course that focuses purely on building the APIs, but the interesting point here is how do I take this really powerful and modern API framework and allow it to also serve web applications, web UIs out of the exact same data models, out of the exact same code base? So you don't have two things to deploy, two things to manage, two things to run. It's not like, well, let's use FastAPI for the APIs an then completely start over and use Django for your web app. No, it's FastAPI through and through, And you're gonna be able to blend them together within the same application with the same versioning, the same deployment, everything. It's going to come out with one of the best web frameworks, not just API, but web frameworks that you can use for modern Python web applications. You're gonna see how to unlock that power in this course.
|
|
|
transcript
|
3:01 |
Now let's compare FastAPI to some of the other popular Python options that you might choose. Here's FastApi's home page, it's documentation and so on. The documentation is really thorough and really good. So what else might you use instead of FastAPI? Well, there's what I think of as the big two: Django and Flask. These two combined represent about 80 to 82% of the current Python web application framework mindshare, deployments and so on, especially looking at stuff that's been built recently. Between them they are the two ways that people often think about web applications and Python. Django has all these somewhat larger building blocks that you click together to build your app whereas Flask is all about it's micro framework lifestyle. You get to pick every little thing and there's zero help for you. You want a database? Okay, go get a database. You want to talk to it. OK, go figure that out. Right? Do you decide on SQLAlchemy Do you decide on MongoDB? Do you? What do you do? So it's all about picking the little pieces and putting them together however you like in Flask. We also have Pyramid and Tornado. I'm a fan of Pyramid, I like that framework quite a bit. It's very fast, and Tornado is one of the very first asynchronous style of frameworks. It doesn't necessarily use the, at least in the early days the async and await style of programming that's popular today because it actually existed before that style of programming but these air two good options. And if you're looking at just your API, there's frameworks like Hug or Django REST framework, or so on that you might consider. So which side are you leaning? More APIs and also need a little web or more web, and maybe we'll need an API. So if we compare these, you might say, well, how does this compare to FastAPI? One way to think about it is popularity. We're gonna talk about the features that make FastAPI awesome as well. But one is popularity. If you look Django and Flask, they're quite popular. 54k and 53k stars on GitHub. This represents their very nearly equal split in the mindshare. We have pyramid at 3k. Tornado at 20k, Hug at 6k. What's FastAPI at? 26k. Now wait. Maybe it's not as good as Flask or Django. Here's the thing. Django is like 10, 15 years old. At this point, FastAPI is less than two years old. So in the, you know, Django's had all this time to build up people like following and being part of it and FastAPI is really, really coming on strong. As far as I can tell, it is the most popular, relatively new framework, and being relatively new is an advantage. It means that supports async and await right out of the box without jumping through a bunch of hoops. It does really powerful things with type annotations. It works with Pydantic data models that do automatic conversion and validation and on and on and on. So because it's new, it's awesome. It has all the modern Python features you would hope for, but you can see it's nearly as popular as some of these older ones, the most popular, too, amongst the Python web landscape.
|
|
|
transcript
|
3:17 |
Briefly, let's just dive into a couple of ideas, The big ideas that we're going to cover in this course you get a sense of what you're gonna learn throughout the whole adventure that we're about to embark upon. We're going to start by building our first FastAPI site and at this level it's just gonna actually be an API that exchanges JSON with some data that we compute in our API endpoint. So we'll see what it takes to build from scratch from, you know, empty Python file till we get something running on the Internet, at least running on our local server that theoretically could be on the Internet that we can interact with. So we're gonna start out and see what is the essence. What are the few moving parts that we must have for a FastAPI site and then we're going to move on to the goal of this course serving HTML. Take this cool API now, how do we also let it handle the HTML, the web application the user interactive browser side of what you also need to build? Sure, you could build some APIs and those are great. But in addition to that, how do you also build your web application? So that's what this next section is gonna be all about. We're going to see how we can return first of all, basic HTML and then how we can use a template language like Jinja or Chameleon to create these dynamic templates that actually generate the HTML. We're going to talk about this idea of view models. If you're familiar with FastAPI, You may have heard of Pydantic this are really cool ways to exchange and validate data at the API level. They're great, and I absolutely adore that technology, but it doesn't make sense for working with HTML. As you'll see, when I talk about why that's the case. But it turns out that a similar but not exactly the same design pattern is what's gonna make the most sense here. So I wanna see about using that to correctly factor HTML and the validation and data exchange and then the actual doing the logic part of our web app. We're going to work with the database, of course. So we're gonna use SQLAlchemy to map Python classes to the database and we're gonna do this in two passes. First, we're going to use the traditional SQLAlchemy, API, which does not support async and await. But there's a new API. That's coming, starting in 1.4 and then heading towards version 2 of SQLAlchemy. That absolutely supports async and await, which is going to be a really important aspect of working with FastAPI and making it fast. So we don't do that in two passes, start out with the synchronous version that you're probably familiar with and then upgrade it to this new async version. And once we have an async database in place, we can now convert our entire web application to run fully asynchronously. This means many, many, many times more scalability for the same hardware. We don't have to write as complicated software with different tiers and caching and all these different things. Our application is gonna be super fast right out of the gate, and finally, once we get this cool app built and running, we're going to put it out on the Internet. We're gonna actually go out, create an ubuntu server and deploy this to the Internet where we'll publish it, people can interact with the browser, even talk to it over SSL. These are the major ideas that we're going to cover in this course. And when we get through all of them, were gonna have a fantastic web application that you can use as an example for whatever it is you want to build.
|
|
|
transcript
|
0:58 |
What do you need to know To be successful as a student in this course?. What do we assume that you know and we don't go into while we're going through it? Well, we assume that you pretty much know Python. You don't have to know all the advanced features of Python. You don't have to be able to create weird, dynamic meta classes or anything like that. But basic things like variables, functions, loops, classes, that's the kind of stuff we expect you to know, we also expect that you have a little bit of familiarity with the web and HTTP and HTML, but we work with some HTML, some CSS and some dynamic templates in this course. So we don't go through and teach you what this part of HTML means or talk about how CSS actually works. We just use the CSS and use the HTML. If you're somewhat shaky on it, probably OK, you can pick it up along the way, but it's not a focus to this course. So we do assume that you at least can pick it up on the way or you know it already. So with those two things in place, you're ready to take this course
|
|
|
transcript
|
1:14 |
So what application are we gonna build during this course? If we go over two PyPI, we could find that we search around. There's all sorts of different projects and maybe we could build one of those, but no, in fact, what we're gonna build is pypi.org itself. That's right. We're gonna create a clone of pypi.org. This entire site. Well, much of the site anyway, we're going to build a UI That looks like this, would have data coming back from the database like that. We're gonna have featured packages that are in here like that, who have the ability to log in, to register, have accounts, all that kind of stuff. So that's the application, the web application that we're gonna build. We're going to create a clone of pypi.org. It's a great example because it talks to a database, it has a decent number of multiple pages, it has HTML forums, it has validation, has accounts. Many, many of the things that almost any web application that is meaningfully large or meaningfully real will have. You wanna build a bookstore, it'll be similar. You wanna build a forum site, it will be similar. So I think this is gonna be a great example. We're all pretty familiar with it from our experience with Python. It's not too complicated, but it's not too simplistic at the same time. And we're gonna build an awesome asynchronous version of it with FastAPI
|
|
|
transcript
|
0:39 |
you might be wondering, who is this disembodied voice talking to you? Well, here I am, Michael. My name is Michael Kennedy, @mkennedy over on Twitter. Thanks for being to my course. I'm really excited to teach it to you. You might know me from the Talk Python To Me podcast where I founded it, and I'm the host. I'm also a, founder and co-host of Python Bytes, which I co-founded with Brian Okken. Maybe even more relevant for this particular situation is I'm also the founder and principal author at Talk Python Training. I've got a lot of different exposure to different types of Python and I'm going to try to bring all that experience to this course and share it with you
|
|
|
transcript
|
0:37 |
Now, if you really diving into FastAPI, you might want to take an hour when you're doing the dishes or you're out for a walk or something and listen to one of my Talk Python To Me episodes. In particular, Episode 284 where I interviewed Sebastian Ramirez. He is the founder and creator and maintainer of FastAPI. So he and I gotta have an awesome chat about why he created it, some of the design choices, where some of the inspiration came in and how to use it. If you want to go a little bit deeper, feel free to check out this episode where I interviewed the creator of FastAPI about his creation on that show.
|
|
|
|
6:54 |
|
|
transcript
|
3:09 |
Before we start writing code and just jump right into our editor, let's make sure that you have your machine set up and you can follow along, and you can build these applications with the course. It's really important that you follow along. So when we do stuff in the course at the end of a chapter, stop and go back and add that to either the same application that you're building along with me or create a parallel but very similar application and add the functionality over there So in this super short chapter, what we're going to do is just go through and make sure that your machine has all the requirements and tools that you need. The first question is, do you have Python? And importantly, is it the right version? FastAPI has a minimum requirement of Python 3.6, and we're also using features like f-strings in our code that require Python 3.6 or later. So you need 3.6 we're actually gonna be using, a higher version. But make sure you have at least Python 3.6. You wanna know, do I have Python? It's a little bit complicated to tell, but here's a couple things we can do. If you're on Mac or Linux, Yu can go and type Python3 -V and you'll get some kind of answer. Either Python 3 doesn't exist, in which case you need to go get Python or make sure it's in your path. Or it might be higher version lower version, whatever. You need to make sure that this runs and that you get 3.6 or above, we're gonna be using 3.9.1 Actually, during this course. On Windows, it's a little bit less obvious. There's a few things that make this challenging if you're not totally sure. So on Windows, what you type usually is Python, not Python3, even though you want Python 3. So you say Python -V. And if you get an output like this Python 3.9, 3.9.1 or whatever as longs that's above 3.6, you're good to go, but here's where it gets tricky if your path is set up to find, say Python 2. But you actually have Python 3 in your system it's just later in the path definition. You're going to need to adjust your path or be a little more explicit how you reference that executable. And here is the super tricky part. Python on Windows 10 is not included. But there is this Shim application whose job is to take you to the windows store and help you get Python. If you don't have it yet, it will respond to Python -V but it will respond by having no output. It won't tell you that Python is not actually installed that you need to go to the store and get it. It will just do nothing. So if you type Python -V and nothing happens, that means you don't actually have Python. You just have the shim that if you took away the V, would open the Windows store for you to get it and so on. So just make sure you get an actual output when you say Python -V or, you know, follow the instructions coming up on how to get it. Speaking of getting Python, if you need it, go visit realPython.com/installing-Python/. They've got a big range of options for all the different operating systems, the trade offs, how to install it for your operating system. And they're keeping this up to date. So just drop over there, get it installed in your machine and come back to the course, ready to roll.
|
|
|
transcript
|
2:31 |
what editor are we gonna be using for this course? Well, my absolute favorite is PyCharm. I think PyCharm is by far the best editor for Python applications, and the larger and more diverse they are like web applications are set to be, the better off that PyCharm is. Now, you don't have to use PyCharm, but if you want to follow along exactly, I recommend you get PyCharm. And for this course you're most likely, going to need the professional version for some of the features, you could get away with a community free version. But a lot of the functionality, the auto complete in the HTML and CSS side won't work. You'll have to have the PyCharm Pro Edition, and I'll give you some other options if you don't want to get that. But you can get it as a student if you work with any university or high school or whatever, you can get it completely for free, even the Pro Edition, and there's also a trial, so those are some options. I recommend it. I think it's absolutely worth it. Get visited over here at jetbrains.com/pycharm/ Now, the way I would put it on my machine as I would get, or I do get the JetBrains toolbox. This auto updates it for you. It lets you jump easily between different versions, that lets you know when there's new versions I think that's really the best way to manage JetBrains tools and products on your OS. So if you do go with PyCharm, get it this way. Now for some reason, if you don't want to use PyCharm, the other really good editor that I would recommend is VS Code. I don't know that I'd like VS Code. In fact, I'm pretty sure I don't like it as much as PyCharm. But I do like it. I think it's good. It has a lot of great features. It supports the HTML and the CSS and all the different languages that we're going to be touching during this course So that's cool. You go download it for free. And if you have an M1 one Mac, there's even a way to get the M1 version, native version over here, which is cool also for PyCharm by the way. If you do get it, You're going to need to install a couple of things. You want to make sure that you install the Python extension or it won't have all the Python smarts. You also, on top of that, want to install Pylance, which gives it better auto complete and better understanding still of your code. In order to get this dialogue to come up, you press that little box icon thing there and then you get the marketplace. Python should be right near the top. It's by far the most popular extension for VS Code. So this is a really good choice if you don't want to use PyCharm. Either way, get one of these two and or pick your favorite editor that you think will work well for this course and we'll be ready to work on the code together
|
|
|
transcript
|
1:14 |
Last, but definitely not least you want to make sure you have the source code for this project. Now, we are going to come and just create a new folder and create a new file and start writing code from scratch. But there are a couple of things that you're going to need if you want to follow along, for example, see where it says data/pypi-top-100 Once we get to the database section, we're gonna load up the database with a whole bunch of data that's in JSON format that is going to represent the actual live data on pypi.org. In order to get that, you got to get to the GitHub repository or if you want to just jump into, say, chapter five and start working from there, we'll have the code that we started with and finished for chapter five. So make sure you get this repo. You're going to clone it for sure. If you're not a friend of git, you can just click on that green button where it says code and download it as a zip file, but if you do have a GitHub account and you use git frequently. Be sure to star and fork this so you have permanent access to it. Once you get this downloaded and cloned or unzipped, you'll be ready to follow along with the course. That's it. If you have Python, you've got a decent Python editor and you've got the source code repo, you're ready to take this course. Let's get going.
|
|
|
|
13:36 |
|
|
transcript
|
1:43 |
Hey there. Now that we've got all that positioning and motivation out of the way. It's time to start building. We're going to begin by building our first FastAPI site. In fact, what we're gonna do is going to take the site and build it up and build it up and build it up over time. First, it'll be just a really simple site then it'll start having things like dynamic HTML in templates and static files. And we're gonna add a database and all sorts of cool layers to make it realer and realer until we end up with something that is very similar to what you might consider a full professional web application. And the question is, well, what are we gonna build? We're gonna build something that I'm pretty sure you're familiar with already. We're gonna build a clone of pypi.org for those of you don't know pypi.org is where you go to find Python packages and libraries that you can install with pip, anything you can install with pip, as long as you used the standard mechanism, not some URL or something like that. It's going to be coming through this central package index here. So what we're gonna do is we're gonna build an application that looks like this. It's gonna have similar elements on the page. You'll be able to log in and register and get help and do other things as well. You'll be able to go to a package and see the details. Many of the things you would do with pypi.org you're gonna be able to do with our application, and we're gonna build this with basic FastAPI functionality and a few cool libraries we're gonna add on to make it working with HTML even better in FastAPI. So I hope you're excited. We're going to start small in this chapter and build and build and build until we have something that looks very similar both visually and functionally to what we have here at pypi.org
|
|
|
transcript
|
4:09 |
it's time to start writing some Python code and creating our FastAPI not API, but web application. Our Python project for a web application. Here we are in our GitHub repository and you can see we have a bunch of empty chapters of what I think the structure is going to be. And we're going to start by creating our project here, evolve it. And then when we're ready to move on to templates for chapter four make a copy from what we did here, over to here. That way you could always just jump in at any given section throughout the course in case you didn't follow along exactly, or you just want to quickly jump into a section and see what it was like there. We want to go over here, and we're going to create that project. Now we're gonna open this in PyCharm, but also show you how to get started before, just in a terminal. So I have this cool little extension called Go2Shell. That'll let us jump in here. But you could obviously open a terminal or command prompt and just cd over into this directory. So if we look here, there's just this placeholder text so GitHub would create the or git would create the project structure. Now what we would need to do there's a couple of things that make up a FastAPI project. We're going to start by just having a main. So what we're gonna do is We're going to create a main.py, file. We're also going to need some requirements. And the easiest, most common way to do that is to use a requirements.txt. Yeah, we could use poetry or pipenv or whatever, but I'm still a fan of just the requirements. We're going to create that as well, and we'll put in things like we require FastAPI, and we require uvicorn to run it and so on. And then I wanna have a virtual environment. So I'm gonna come over here and say Python, you may need to type Python3, depending which version you got. -m venv, venv. We're not gonna do this from scratch for everyone. I'm just gonna walk you through it once and now we have our virtual environment. But if we ask which Python. It's still we ask which Python3 It's still the system global one. On Windows, which is not a command, but where is a command that will tell you basically the same thing. So we need to make sure we activated. So on macOS or Linux we say dot or source. venv/bin/activate like that and notice our prompt changes. If this was Windows, we would just venv/scripts/activate.bat like so you could drop the bat that would still run. But over here, I got to say this. Now, if we ask which Python it's this one here all right? Any time you work with virtual environment, it's almost always got an out of date pip. So let's fix that real quick. pip install. Sorry. -u for upgrade pip and setuptools. Now we do a pip list. You see, we've got the latest version. Now that we have our virtual environment up and running, let's go ahead and open this in PyCharm, we're no longer going to need this on macOS you can drag the folder onto PyCharm and it'll open. On the other operating systems, you have to go file open directory. Same basic idea. You can see PyCharm's found our virtual environment. Surprisingly, this sometimes works, sometimes doesn't. So you can always go add interpreter and pick the existing one that usually finds it or if you have to, you can browse to it as well, but it looks like we're good over here. This are red because in GitHub, they're not yet staged. So our project is over here. And let's just do a quick print hello, web world just to make sure that we can run everything and right click, say run. Perfect. It looks like everything is running over here just fine So we've got our project created. Obviously, it's not a FastAPI project just yet, but this is the process that we're gonna go through for each one. I won't walk you through it again. Well, I'm just gonna do this and say, Hey, I did this set up to get our project running and start with the existing code at each chapter
|
|
|
transcript
|
5:13 |
Now that we've got our Python project set up in Pycharm, let's make it a FastAPI project. The first thing we need to do is go to our requirements here and have our requirements stated. So to get started, we need just two, and we'll keep adding onto this list as we start to bring in things like an ORM with SQLAlchemy, as we bring in static files support with aiofiles and so on. But we can start with FastAPI, and we can also start with you Uvicorn. So Uvicorn is the web server, FastAPI is the web framework. PyCharm thinks this is misspelled. It is not. So we can go over here and hit Alt + Enter and say Do not tell me this is misspelled. They're actually working on a feature, to understand these packages and not say that they're out of date or whatever, but there we go. Now we need to install these. So we're gonna go to our terminal, make sure your virtual environment is active here. I want to say pip install -r requirements.txt right. Looks like everything installed just fine. I'm not a fan of the red. Let's go ahead and commit these to GitHub here and notice over here, we've got our source control thing. We can do this to commit. It shows us Command+K on macOS is the hotkey. But I've also installed this tool called Presentation Assistant. When I click this, Note at the bottom we got this. But also, if I just hit Command+K, this would come up. So you'll see me do a lot of things with hot keys as I interact with PyCharm in general, in the code and so on. So if you're not sure what just happened, keep an eye on that thing in the bottom. Now, down here. We've got these two files. These call this starter code for our project. Here we go. Now things don't look broken with red everywhere. But how do we create a FastAPI project? Well, there's a really simple, what I would call the PyCon talk tutorial style where you just put everything into the main file and, hey, you have a whole app. Look how simple it is. And there's the realistic one where you break stuff into you know, isolating the views into their own parts, the ability to test the data exchange between the views and the templates. And you got the template folder and all that. We're going to start with the simple one, and we're gonna throughout this entire course move towards what? Maybe we should call the real world one where you actually organize a big, large, FastAPI web application. We're gonna start by saying import fastapi and we're also gonna need while I'm up here uvicorn to run it. Now, if you've ever worked with Flask, working with FastAPI, is very similar. It's not the same, but it is similar to what you would do with Flask. So we're gonna create an app. The way we do that, is we say fastapi.FastAPI And then we're gonna need to create a function that is called when a page is requested. So we're gonna gonna call that index. That's just like forward slash And what are we gonna do? Let's just return something really simple. "Hello, world". It might not do exactly what you're expecting, but we'll see. Okay, and then we need to decorate this function to say this is not a regular function, but a function on the web. We'll say app dot get. Notice all the common HTTP verbs here get put post delete so on. And then we specify the url. You can see there's an insane number of options. We only care about specifying the path, so this will be fine. Bring that up. And how is everything looking? It looks pretty good, but there's one more thing to do. We need to actually run our API. So we say uvicorn.run and we just give it the app and that's it. We've built a FastAPI web API so far as you'll see. Let's go ahead and run this. Here it is running down there like that. Hello, world. Wait a minute, Look carefully. What is all this JSON Raw data. Why does it say JSON? It says JSON, because FastAPI is most natively and API. It's here to build APIs that exchange data. So, for example, if we had said something different here like we had said The message is, Hello, world and we run it again and we look at the raw data, you can see it's returning JSON here. Okay, So one of the things that we need to do for this course is to tell FastAPI for certain parts, may be much of it, maybe just a little part. Whatever part that we want to be an HTML browser oriented web application, we need to tell it. Don't just, don't return JSON. No, no, no. Return HTML and ideally, use a nice structured template language like Chameleon or Jinja or something along those lines. But you can see we've got our little FastAPI app up and running here on locahost. All we have to do import fastapi, create an instance of it, use its HTTP verb decorators to indicate which methods are web methods and then run, that's it.
|
|
|
transcript
|
2:31 |
Now, before we call our little basic structure here finished. I do want to show you one quick little thing. Notice I was able to go over here, right click and say run. And I can also press this button and everything looks golden. But the way that we actually run FastAPI in production is not to go and say Python run this file. What we're gonna do is we're gonna say set up Gunicorn, which is going to oversee a farm of Uvicorn worker processes, and each one of those is going to run this application. And that way, if something goes wrong with one, it can be restarted. You can do scale out. There's all sorts of cool advantages to that. And that's generally how Python web apps run in production anyway. And when we do it in that mode, the way we're gonna have basically implicitly behind the scenes do that chain. I talked about what's gonna happen is, we're going to say uvicorn main thing here. What is it that we're working with? And then what is the name of this thing here, which is app in our example. So we're gonna go to the main module and find the app instance and run it. Watch what happens if I try to run it here. It says whoa, whoa. You're somehow like double running it. I'm not really sure what's going on here. And that's because this is really just for testing, and we need a different way to run it in production. So we're just gonna quickly fix that and say:only if you try to run it here in dev, do we want to do that. So notice this, a live template is gonna expand out to if the name is main. This is the Python convention. Say this file is being run directly rather than imported and else I don't know. This is what we're gonna end up doing in production. There's actually some things will ultimately need to do here. But for now, there's just nothing else happening. If I run over here through this mode, you can see it's running fine. And if I go into the terminal now and I try to run it like this hey, look, it runs fine as well. Okay, so you'll see that as we get this little bit more complicated. Think more things going on, like setting up the database at start up and so on. There's gonna be some interesting balancing act that we have to do around this but I wanted to make sure that you I focused on this specifically because it's easy to just say uvicorn run, but then seems like it works and then it doesn't work in production. And that's why, right, this is fine when we press the run button but in production were running through a completely different chain of events that uses uvicorn module:variable_name. So I want to make sure we get this set up right from the start.
|
|
|
|
53:10 |
|
|
transcript
|
1:13 |
In our previous chapter, you saw we built a simple FastAPI, API more or less, returned JSON. And our goal now is actually to exchange HTML. We may also want to build APIs with FastAPI, I mean, that's one of its main purposes. But if we're gonna have web pages that talk to browsers, we need to return HTML. Now, the last thing we want to do is write static HTML in strings in Python and then return it. No, no, no. We want to use one of these dynamic templating languages like Jinja or Chameleon or even similar to what you have in the Django templates, where we write HTML and we put a little bit of scripting in the HTML and the scripting varies by templating language. But the general idea is we put some scripting or some conditional stuff into our HTML. In FastAPI we're going to create a dictionary and hand that off to this template and say: render all these items and here's the pieces of data that you're going to need to work with. So that's what we're gonna do in this chapter. We're going to start really simple and just see how to return HTML. Then we're gonna leverage, a cool library that allows us to basically do what I just described: create a dictionary and just hand it off in the simplest possible way to under one of this underlying templating languages
|
|
|
transcript
|
4:07 |
Here we are in chapter four and in our GitHub repo I just want to give you the lay of the land. We completed all of our code in chapter three, and now I made a copy of that into chapter four. So the way this is gonna work is the final code for chapter three is the starter code for four. The final code for four is the starter for five, and so on. I've already done all the set up. Like I said, we're not going to go through that again. So let's just jump into it over here. Now, you would be forgiven to think that FastAPI is really just for building APIs. And if you wanna have a proper web app that has HTML and bootstrap and CSS or Tailwind CSS, whatever you want, that you need another framework like Django or Flask or something. Because remember, when we run this, we look at it, what we get back is JSON. And if we look in the network stack what we get over here when you do a request, the response type on this one Its content-type is application/json. Of course, it seems like, well, what this does is it returns JSON and that's true. But what we can do is we can actually change how it works. Let me introduce you to the HTTP responses. So over here in FastAPI, we have a whole bunch of other things we can do than the default. The default, of course, is to return JSON. But if we create a response under FastAPI responses and you look, we have HTML response, a file response, a redirect, JSON. That's what we're getting now, plain text, streaming content and so on. What we're gonna do is going to create and HTML response, and we're just going to say the content is some local variable. Notice all the other defaults are fine, the header defaults are fine, the status code of 200 is fine and so on. I'm gonna come over here, and for the moment, just for a moment, I'm gonna do something bad and type some inline HTML. This is not the end goal. But in here let's say we want our page to look like this. Here's some HTML and here will say: "hello FastAPI Web App", and we'll have a <div> and then we wanna make sure we close our </div> and it's gonna be: "This is where our fake pypi app will live!" And instead of returning this dictionary, we're going to return the response, and the response is gonna tell FastAPI you know what this is actually not JSON, it's an entirely different thing, like a file or in this case, HTML. We can actually just inline this right there, like so. OK, let's run it again and see what we get. Look at that. "Hello FastAPI Web App This is where our app will live" And if we go to our network and we look again at our content-type down here somewhere, there it is: text/HTML. Like all friendly HTML pages, its text/HTML and utf-8. Pretty cool, right? And if we go to View Source this time, it's well, exactly what we wrote. Is it valid source? Not really. We didn't put a body and a head and all that kind of business in there, but this is enough to show you how we can return HTML at a FastAPI. That said, this is not how you should be returning HTML out of FastAPI. We're gonna do what all the other major frameworks do: That's we're gonna use dynamic web templates, gonna put those over there, and we're going to pass a dictionary like we did before, off to that template and the template engine will generate our HTML and our static content and our dynamic content, all those sorts of things. So we're not going to do this, but this is the underlying mechanism by which we're gonna make that happen. We're gonna use another library that's super cool, in my opinion, I really, really enjoy working with it, and it makes it super easy. We're just gonna put a decorator up here that says use a template, and magically, instead of being an API, it now becomes a web view method or web endpoint here. All right, so this is what we're gonna do for this chapter: we're going to start like this, but we're gonna build up into moving into those templates and serving static content and things along those lines.
|
|
|
transcript
|
1:30 |
With Python, we have a choice of different template languages. So what I'd like to do in this section is talk about three of the main possible choices that you might choose for this dynamic HTML templating that we're gonna do and see the trade offs, and then we have to pick one and go with it for the course. So we're going to do that, and I'll give you the motivation for doing so. But let's go through three popular ones. If you've ever done Flask, you've done Jinja. So, Jinja is really the one templating language that is deeply supported by Flask. There are many other frameworks that use Jinja as well. A lot of different, maybe smaller web frameworks that are not quite as popular, that also happen to leverage Jinja, so Jinja very well may be the most popular, most well known choice. Mako is another template language and looks quite similar to Jinja. I think I actually like Mako a little bit better, you'll see that there's a little bit less: open, close, open, close all of these things you have to keep writing; and it's, here's a template line and then you just write some Python. That's pretty nice. And then we're also going to talk about Chameleon. Chameleon is unique because it doesn't leverage directly writing Python as much, but it uses more of an attribute driven way of working with the HTML so you might pass some date over. There might be an attribute that says: if this condition is true, show or hide this element that has the attribute, whereas Jinja and Mako would actually have an if statement directly in their HTML, so there's drawbacks and benefits to each one of these as we will see.
|
|
|
transcript
|
6:22 |
I think the best way to get a feel for these three different template languages and which one might be the best to choose for our application, would be to compare them with a simple example. So what we're gonna do is, say, given a list of simple dictionaries or simple objects, each of which has a category in an image. We would like to show these in a simple, responsive grid. So this comes from a bike store and would look something like this: would have comfort bikes, speedy bikes, hybrid bikes, folding bikes and so on. And what we want to do is generate this HTML results, and we're going to do it with these three different template languages, given this data on the left here. So how would this look in Jinja? Well, the first thing we have to address is what if there's no data? So either the list is not there at all. It's None, or it's just an empty list. In that case, we want a simple <div> that says "No Categories". So that's the first block, and what you should notice here is you have curly percent. If statement close curly and then annoyingly curly percent endif curly percent, there's a lot of this open close. Like if this and if for that and for and so on. So you see a lot of that in Jinja. Alright, so we've got this categories up here and this is standard Python. If you can read Python, you can read this, right? Then, if there are categories we want to do a for in loop over them and repeat a <div> that has two things: it has a hyperlink that wraps an image and it has a hyperlink that wraps just the name. So we're going to do a four c in categories in this bracket percent thing and then in the for, we have the HTML and wherever we have a dynamic element from our loop, we have c and then we'll say go to the name lower case the name just in case because that's how our routing works, let's say. Over to image then we have just the name properly cased shown there. OK, so this is what it looks like in Jinja. It's not terrible. If you know Python, you know it pretty well. Here's what it looks like in Mako and the only real difference that you'll see here is that instead of having curly percent closed curly percent and closed percent curly, you just have percent on one line. And to me, honestly, this is not a very nearly as popular as Jinja but I think this is actually a pretty neat language because it's got the same functionality, but you just write your symbols, which I think is kind of the Pythonic way. One difference is the way you get strings from objects. So instead of saying curly bracket curly bracket variable, you say dollar curly, variable. So that's how it looks over here. One thing that's annoying, it's that dictionaries don't get dot style traversal. You have to say, you know, call the get on them and so on. Right. So this is Mako. Third one is Chameleon. Now again, we're gonna have these two conditions. The top condition is we want a <div> to be shown if there's no categories. The thing to take away from Chameleon, the Zen of Chameleon, really, is that it has this template attributes language t-a-l or tal. And the way you program it is to not write Python, but to write small, small expressions as attributes. So here, if we wanna have a <div>, that's only shown when there's no categories, we say <div> no categories, and then we put this attribute that says tal:condition. And here we put basic Python, not categories, you call functions, do all sorts of Python things in here. That's how we do that part. Then the next part, we're gonna have the opposite condition. So just tell tal:condition="categories" and then we want to do a loop like before So we say, <div tal:repeat="c categories"> and then it's gonna repeat that entire block, the <div> and the two hyperlinks, each time it sees an element in that category, then it's gonna write it out. Here we use dollar curly brace like we do in Mako, but it does get the dot traversal of even dictionaries. All three of these, they're pretty decent, right? It turns out, Chameleon is really by far my favorite language. There's two primary reasons I think this is a much, much better language, even if it's not as popular. I think it's much better than Jinja. One, you don't write symbols over and over and over again. You don't say curly percent test closed, percent closed curly, curly percent and if close percent curly and just that stuff all over. But the other drawback of writing code like that is what you get is not proper HTML like this. This is proper HTML, there might be attributes that don't make any sense to a standard web browser, but if I were to load this up in some kind of tool and I try to look at it or I hand it to a designer, they would be able to look at it straight away and go: yep, I know what this is. This is HTML. So I think the fact that it's basic HTML and you don't put a bunch of code in there, I think that makes it really quite nice. The other one is, and I think this one you could be split on is a lot of people see that they could, they cannot write arbitrary Python here, where, over in say Jinja, there's ways to write arbitrary Python code in your template. Some people might see that as a drawback, like I can't do all this cool stuff in my template. To me, it's a feature. It means I can't put logic, complicated Python logic into my HTML. Where does that belong? I don't know. Not here. It belongs somewhere else. We're gonna talk about where it belongs in our web application we'll build later. But limiting the amount of Python code that we can write over here, to me is a feature, because it means you have to have more professionally, more properly factored applications. You guys can decide to use whichever one you want for this one, we're going to use Chameleon because it's proper HTML and it doesn't let you write arbitrary HTML throughout it. It doesn't have all these symbols everywhere in terms of the open close and all the Python code that's interlaced and so on. I think this is a great language, we're gonna use it for our course. What I'm going to show you, there's a very, very, very small change to make Jinja do the same thing So if you prefer Jinja, you can use that, we're gonna use Chameleon for the reasons I just laid out here.
|
|
|
transcript
|
6:28 |
Well this was nice here, to render this, but that's not how we want to write our code, is it? We want to write our HTML in an HTML file and then write our Python in a Python file and then put those together. That's how all the common web frameworks work. So let's go and create one of these templates over here. We're gonna start by creating one. This is the whole HTML page, and then we'll work on some nice shared layout. I'm gonna create a folder directory called templates. And then in here, I'm going to HTML File called, what I like to do is, I like to name my files the same as the view methods. So if the view method is index, I'm gonna name the file index and this will be Fake PyPI like that and let's just put something similar, but not exactly the same. We have <h1> now we've got a nice editor for working with HTML, beautiful. Say, call it "Fake PyPI" for now and <div>, we'll just put, actually, let's put an unordered list of the popular packages so we'll have a <ul>, it's gonna have an <li> it's gonna have three popular ones. We could do this short, cool little expansion thing in PyCharm if you hit Tab. So let's say we wanna have fastapi, we have uvicorn and chameleon. And let's also add one other thing here, let's say we wanna have a <div>. Let's put the user name and this is gonna be something I'm gonna pass. A piece of dynamic data is gonna be passed. We'll just have user_name like this. And in Chameleon, the way you say output a string from a variable, Turn that variable into a string, you say: dollar curly braces. If you're familiar with Jinja than it would look like this. But in Chameleon, you do it like that. All right, so we want to render this. How are we going to do it? Well, turns out Chameleon is not built-in in FastAPI. You wanna work with Jinja? There's actually some built-in stuff, but I'll show you a better way I think anyway. So let's go look at an external package here. Let's go over here to GitHub. Here's a cool package I created, I don't like it because I created it, I like because I really wish that it exist and it didn't so I created it for FastAPI So the idea is, it's called fastapi-chameleon and what it is, is a decorator that you can put onto your view method that will take a dictionary plus a template and automatically turn that into HTML. What we got to, we've got to install it, right now It's not yet on PyPI. Check back here when you're watching this course, there's a good chance I'm going to publish it to PyPI, but for now, just install it this way. So the way it works is you've got a template directory and I like to actually name a little more structure here. We'll get to that in a minute, but got some template file. We're gonna set this overall path of where those live and then all we gotta do is just say, Here's a template and return a dictionary and we're good to go. If you return any form of response like an HTML response or redirect response, it just ignores the template idea and just says, return that response directly. So let's go and use that over here. We're gonna install it like this. And PyCharm says: Oh, you better install it like OK, super. It's installed. And then when I go over here and I'm just going to say @template and we need to import that from fastapi_chameleon. I like that up there. Now I'm gonna first type out the template file to be index.html and we don't need this and we don't need that. All we gotta do is return some piece of data. Maybe this comes from the database or something. Will say user_name is mkennedy or something like that. And and that's spelled ok. And we try to run this. It's not gonna love it, I don't think. So when I click on this, it gives us an error. That's unfortunate, what happened? It says you must call this initialization thing first. So what we've got to do before we start using it, and we're gonna organize this better in just a minute. Is we need to go to I guess we need to import this as well, directly. And we'll go to this and we'll say global_init() and we have to pass along the folder "templates", that's what we're calling it. And I think that should do it. If we have the working directory right. If the working directory is not in the same place, you probably need to pass a full path here. Let's try it again. Fingers crossed. Look at that. How awesome is this? So here's our HTML and this is the dynamic data that was generated and we passed this over. We could actually do something like this. We could say this has a user which is a string. OK, come over here and say it's going to be user if user else "anon", something like that, OK. And we try this again. Ah, yes, it needs a default value, I guess that's the way that works, I forgot, equals, just do it like this. "anon". There we go. So if there's nothing passed, it's anonymous. But if we say user=the_account, be whatever you want. So this part is totally dynamic, as our dynamic HTML is. And this is our static stuff that we can write so so cool, so super cool. This lets us come over here and just specify a dynamic template. A Chameleon template in this case, you render. If for some reason you don't want to use Chameleon and you prefer Jinja. Check this out over here, scroll down a little bit. This friendly guy over here, cloned this project and created a Jinja version. So all you gotta do to use it is go and put a decorator or your Jinja template on as well. So use one or the other, depending on the template language that you would like. But I really like this style of let's just put this here and return a dictionary and let the system itself put the pieces together and build the HTML.
|
|
|
transcript
|
11:16 |
Let's pause building our application for a minute and actually do a little bit of organization. What's going on here? We have got our one file where everything is in here and right now it's only 20 lines of code. It's no big deal. But as this grows, is going to get larger and larger and larger. We've got to read stuff from configuration files or secret files, for our passwords potentially like to our database connection. We've got to set up the database connection. We're already setting up the templates. Maybe we're setting up other things, like routing and so on, as you will see, and it's gonna be a real mess for a real application. So what I want to do is first sketch out what we might expect to build here. So we're gonna go over here. I want to say, @app.get there mostly gonna be, but not all, gets. I'm gonna go over here and have an about, let's just have these be empty for a moment. We're gonna have this about function and like these are the sort of the homepage overall type of things. But we're also gonna have, say, account management. So let's go over here and have a an index for the account. Although in this case, because it's in the same file, we'll maybe call it not index, but you'll see that we don't really want to. For the url it's gonna be "/account" And we're gonna have a way to register for the site. So this could be "/account/register". This will be register. We're actually gonna have one to accept a get and one to accept a post. Talk more about that later. Also gonna have a login and we're gonna have a logout and so on. As you can see, this has started to get really not so nice. And this is just scratching the surface. Also in our templates over here we have a big pile of dough. So what I want to do is just take a moment and talk about reorganizing these for a larger application that looks like this. What I'm gonna dio is I'm going to go and create a folder for all of our views and call it views. And then I'm gonna further organize this. Say well, over here we're gonna have the home views and over here we're going to have Let's say the views that go with account. We're also gonna have stuff about packages like package details, package list, search package and so on. So I'll call that packages like this and so on. And then what we're going to do is move some of these over. So, like these two right here, this should be about. That's it. Let's move those over into home. You're gonna need to import some stuff like that. Notice this is a problem. Will fix this in a second. We have our account things. So here's the three about account, like that. We're also gonna need that same template thing. So I'm gonna go ahead and just rob that from up here. So we got it. Put that at the top of account as well and packages we'll put some stuff in here eventually. OK, but this is a problem, isn't it? If I try to run this, I don't think it'll crash or anything. It's just gonna give me 404. That's weird. Why? well, remember the way it worked is we load up this main file and everything that was listed there. I left my logout. Everything that was listed here before we had run, got registered. Well, now we're not doing that anymore. So what we need to do is use something different and FastAPI has a really great way to deal with this. We need to import FastAPI and then what we do is: we create this thing called API router. So we say router = fastapi.APIRouter() like that. And what this lets us do is it lets us build up the various routes or roots for my British friends. Do basically whatever you would have done with app. You just do that here. So we've got our get, we've got our post and so on. And then later we say, well, router, everything you've gathered up, install that into the application. So we're gonna do that everywhere we were using app Perfect, those were all good. And let's go ahead and do this for packages as well. OK this are all done. If we run this. Nothing magical has happened. It's still going to be that same "404 Not Found" that we saw right there. Until we go over here and we say from views import home and account. Ypu can put this all in one line if you want. I kind of like to have it separate. We're gonna import this and then somewhere along the way, we need to go to the app and say include_router and the order here might matter. So make sure you do in the order you want. Do home, we do account, then we do packages, clean up on that. Not gonna need this template business over here anymore. Now, if I run it, it should be back to good. Let's try. Tada! perfect. We got our anonymous user sort of passed in. This we should we go back and we do user=abc. Now we get our abc user right there. Okay, So what this is gonna let us do is this unlocks the ability to build much, much larger applications. We can put all the stuff we need in the home here. We do all the complicated account stuff over here, and it doesn't all get jammed into the same file. Now, corresponding to this, let's go over and organize this a little bit. Because when you see index, well, is that the index of view for home? Or is that the index view for help? I don't know. So I'm gonna make subdirectories here, and what I'm gonna do is I'm gonna name them exactly the same as the view module. So home, account and packages. Perfect. And I'm gonna take this and I'm gonna put it in home. Now, PyCharm may have fixed this. Maybe not. No, it didn't. So what we need to do is go over here, say home/ like that, go templates and then whatever goes there, let's run this one more time and make sure everything's hanging together. Perfect, still works. So this gives us a lot more organization. Now for in the home views. We know exactly where all the dynamic HTML is going to live Let me do one quick change. Here, let me rename this to pt. I renamed in here and PyCharm found that and named it over there because the way we're naming this, we actually, our template has a convention template decorators, a convention that will look at the module name: home, and it will look at the method name: index. And it says, Where's the template folder? Well, let's go look for home/index if you don't specify anything here. So we can actually omit that in this case. And look, it still works. Cool, huh? So very, very nice that it will go and find that over there for us. One final thing to address over here is this. I don't really like the way this is working here. So what I like to do is make this a little bit more clear. Because, as I said, it's going to get more complex and more complex and so on. I want to define an overall function here. I'm gonna say define a function called main and main is going to run this. And I want to define a function called configure and actually configure, at the moment can just do all this and here we'll say configure. So the idea is: there's a bunch of different pieces that we're gonna be putting together here and it'll make a little more clear where to go find those pieces. Like, for example, in the Talk Python Training equivalent of this file the only does what. The kind of stuff you're seeing here. I think it's like two or 300 lines long. You want some organization, in the end. So one thing to be aware of, I told you about in production, what gets run is the else stage. This part. We wanna make sure that we still call configure over here. Otherwise, in production you have no routes. Nothing. It won't be good. The other thing is, I wanna have more partitioning here. So I wanna make that a function and that function. So we come over here and say, extract method, say configure_route and this one. I know right now, simple. But let's go ahead and make a method out of it configure_templates because, you know, maybe you've got to do a little more work to find this thing. And there's some path juggling and whatnot. This feels to me a lot cleaner. I could come in and say OK, well what do we do for the main? When you run the app, you say I'm gonna configure it. I'm gonna run it with uvicorn. We could even go and be more explicit. Say the host="127.0.0.1" I wish you could say "localhost". I don't think you can. And then I want to configure the template and configure the routes and then either run it directly or for running in production. Just set it up, but don't actually call "run". Let's just make sure everything still works. Should be unchanged with that refactoring. And it is everything is still working. OK, so this gives us a really nice convention for the way that main works and using the routers we're able to partition out the different pieces. You very well may have APIs as well. So you might have an API directory like this and then a views directory like that. That's what I typically do. But I don't think there's any reason for us to write an API in this example course because I'm keeping it focused just on the website. But in a real one, you probably have both. I think PyCharm has special support for templates and for some reason, I think it marked it up there. If we go and say unmark is just the name, it automatically grabbed that one. We can come over here and say mark directory as template folder and it says, hold on, hold on, hold on. For this project, we don't know if you want to use Jinja or if you want to use Chameleon or Django templates. So let's go set that. Now, what would be nice is if you said yes and it took you to where that's supposed to be. For some reason, it doesn't do that. So you got to go over here and type template language and wait a second. I noticed over here it says None, and it gives you all these different template languages. I'm gonna say we're doing Chameleon, so that will give us extra support for Chameleon syntax. But now, if I go over here, I can type things like tal: repeat, whatever, right? This is the syntax that will be working with for Chameleon. And now you can see we get support in the editor for it. To me, this is a much, much more professional looking application that's ready to build a real, complicated app that is easy to maintain over time
|
|
|
transcript
|
2:24 |
One really important thing you want to keep in mind when building web applications is how are you gonna have some shared look and feel, some common look for your application. Let's take the Talk Python To Me podcast website for example. Here's the home page you can see we have the navigation across the top. We have this Linode sponsorship bar and some general styles. There's, in fact, a bunch of other stuff going on, like CSS, like JavaScript like analytics and whatnot that you don't even see here as well. But obviously the calm look and feel, it's the same, right? Over here, go to the episode page, similar navigation along the top, similar style sheets and whatnot. Going to a particular episode, Surprise! Same banner, same navigation, same style sheets and so on, maybe some extra ones for this particular page. But in general, it's the same. So having this one look and feel for your site is really important, and what we want to do is we wanna make sure that we write a single HTML page, put that code into one place and use it throughout the entire site So when we make a change, let's say we want to change that banner or we want to add a new navigation element, we change it in one place and everything changes. So there's all sorts of benefits to having these layouts that are shared. It's not just the look and feel. That's the obvious thing. But you have much more consistent things, like a consistent title. Or if you've got meta description or meta other info in the head of your document, that will all be the same and shared, and if we want to make a change. You do it in one place. You have consistent CSS and JavaScript files not just having the same ones, but in exactly the same order all the time. Consistent analytics. So if you want to do something like have Google Analytics that tracks people on every page, I don't do that in my sites with Google Analytics. But if you want to have something like that, you could add that, say at the bottom of your shared layout and every single page is always gonna have the same analytics. This one's slightly less obvious, but it's really important. You have a structured way for every other page to bring in it's extra CSS. So imagine that that episode page had an extra CSS file, an extra JavaScript file I wanted to bring in. You could have certain little parts in that shared layout That's here's where that page can bring in its extra files. You can do that in a really consistent and structured way, so these are super useful and we'll see how to add them now.
|
|
|
transcript
|
6:14 |
So we just talked about how important it is to have a shared common layout for the entire site. You wanna add a CSS file to the parent site, put it in the layout. You want to change the title? change it in one place. You want to add some JavaScript? What's, includes over there. So that's really, really important for having navigation for common look and feel as well as those other things. So let's go and do that here. So what I'm gonna do, I'm gonna start out first by creating a real simple version that we can see. And I'm gonna drop in the actual version that we're gonna work with. So I'm gonna create a place called "shared" over here. And in here I'm gonna create a file, an HTML file called "_layout.pt" My convention is: an underscore means you're never really supposed to use this directly, but it's supposed to be used as part of building up something larger. Then I'll call this "PyPI site", and then we wanna have some content here. This could also have a footer. "Thanks for visiting". Now in here, let's have some content in our site. This is just a CSS class that lets us maybe style it or add padding or something like that, because we could also have, like, a <nav> section or whatever. And in here, I would like to say: other pages, you can stick your content right here. Everything else will stay the same. But you control what goes in here. So the way that we do that in Chameleon is we do what's called defining a slot. So let me just change this names. They have nothing really to do with each other, other than, like, conceptually, you're styling this thing. We've got our main content CSS and we're gonna call it content from the other pages. And if they don't put anything here, it's just going to say no content. All right, But if they do this whole <div>, it's gonna be replaced with whatever that page wants to do. So let's go and change our home over here. Not do all of this stuff up there, not worry about this, not worry about that. It's just going to do this one thing here. So what, we're gonna do is gonna have a <div> and put that stuff into there. That's the way Chameleon likes to work. Always likes to be valid HTML. Now, in order for us to use this, what we need to do is we need to go over here and use this template language. Notice here there's "metal", we've got tal and then metal, the metal one is about these templates and so on tal is a temporary attribute language. So what we gonna do is we're gonna say "use-macro" and the easiest way to do this is say load:, and we give it the relative path from this file over to shared over to "_layout.pt". What do you get named pt.html? Let's rename that. There we go. layout.pt, could be HTML, could be pt, "pt.html" is kind of weird. OK, so there and then we need to go over here and say, there's a section that has this content and it's gonna be metal:fill-slot="content" and we don't want this tag to be part of this. Will say tal:omit-tag="True". So just this content is going to go into that hole. You want to tighten this up a little bit. All right, that should have no real change. Our code should still run. What's gonna find this index.pt when it starts to render through Chameleon, Chameleon will read this, go well, we've got to go get the overall look and feel from here and just to make it, I don't know, feel like it's got something going on, let's put a little style in here. body background. Let's make it a really light green. We do that by something like that, just so you can see some sort of common look and feel being specified here. We run it. We should get this new view. Must have made some kind of mistake, and I have not. Awesome! We've got our PyPI site and we've got our footer and then this comes from that particular page. Let's go. And not you, View Page Source, let's view the whole source. There we go. That was cached or something. So this comes from the overall layout page. This comes from the overall out page layout page, and this is what our index had to contribute. Well, with that in place, let's do a real quick navigation thing. Actually, here, let's just do a <div> that has two hyperlinks. One is going to be slash home and one is going to be about. We'll do better navigation in a minute, and let's go and add one of these for about so these are views. It's down here. We're gonna add another template. And if we call this in the home folder about.pt, it'll automatically find it which we will. Now the way I find the easiest to create new pages is just find a simple one of these and copy and paste it because the top part is always the same she'll say about and this will just be about PyPI something like that. If we run this again. Now, we should be able to jump around. If we go to home, we're here. If you go to about, about PyPI. You can tell the formatting is totally wonky. We need spacing and whatnot, but check that out. We've got our common look and feel We've got our styles coming across. We got our footer very, very cool, right? So this is how we're going to create this common look and feel over here in our FastAPI web app. Well, really, we're just leaning on Chameleon. OK, this overall common look and feel here. And then within one of these, we just say, here's the overall layout and then we're gonna fill various slots. You can have multiple ones of these, like we could set the title and so on. But we don't really need to go into that right now. This should give you more than enough to know what to work with here. So I think this is a really, really good idea for building maintainable apps because you define your layout once, and then you're good to go.
|
|
|
transcript
|
3:53 |
You might be thinking: hey, this belongs in a CSS file so that you could maintain it separately, just like we did with our HTML and Python. Maybe you wanna I don't know, have an image that you show on your website or use JavaScript. Well, those would be files in a static folder that gets served directly, not through some sort of processing that FastAPI might be doing. And some frameworks come with this built-in or defaulted like Flask automatically you can go to /static and just serve stuff out of there. FastAPI doesn't work like that. You've got to explicitly enable static files in two steps or three. So what we're gonna do is gonna create a folder, directory called static. And in here, let's just create something simple. We'll do a "site.css". In our site, let's go and move this over. <style> here. And let's change the color just slightly. So you get a sense of, you know, here's something different. Let's make it like a light blue, maybe purple. Anything different is all we need. And then let's go over here and try to include it. So we have a style sheet and check this out. If I select, type /static, I'm already getting some completion here. You get even better completion if you go over here and mark directory as a resource route. But it seemed like that worked pretty well for us. And if I run this, let's go and see what happens. Well, where did our green go? Green is gone because I took it out of the page. But why isn't it purple? Well, because this is not working. If I try to click, this is cached again. But a quick click this, not found, can't serve that. So the fix is easy, but not obvious. Let's go over here, told you we're doing more and more things in these various stages, which is why I broke it out. I want to go to the app, and I need to mount the static folder. And then what I need to do is pass along this thing called StaticFiles, and that comes out of Starlette. Not FastAPI, FastAPI is an API framework built upon Starlette, so a lot of times you'll see things like request, response things or this actually being driven by Starlette. We'll go in here, we're going to give the name of this as well. "static" like that. I think we gotta explicitly do it. These are all keyword arguments. And then, if that wasn't enough static, we're also going to say name="static" like that. All right, You would think this might do it, and it will get us part of the way there. Check this out. It says if you're going to use static files, we would like to be able to serve them asynchronously as fast as possible without blocking the rest of the requests. A really cool way to do async await file access is with this package called aiofiles. So, in order to use this feature, we have to install this extra library to work with it. So we're gonna come over here and say we're gonna use aiofiles. We would have basically done the same for Chameleon, but this package already depends upon Chameleon, so it solves that. So there's a bunch of things like this in FastAPI that are not used by default. But if you want to use them, you're gonna need to install additional dependencies. So yeah, and that's not misspelled. Let's try one more time. That should be all the hoops we got to jump through, create the static folder, mount the static directory with static files, and add and install the aiofiles package. Wuju! look at that, purple! Doesn't seem like a big deal. But that is our CSS file that we're now able to serve right out of here and for some reason, that keeps getting cashed, the view source. But there it is. There's our CSS file that we created, and we're serving out as a static file, so it doesn't look like much, but this means we can serve images, we can serve CSS, we can serve JavaScript. All the things that major websites have to do.
|
|
|
transcript
|
4:00 |
Now, let's just take stock of where we're going, what we're trying to build. Remember, this is our application we're building during this course, and here we have it running locally in a finished version. What you'll have at the end. But we're not there yet, are we? So this looks a lot like pypi.org. See,it's got some data in the database. We can go and see details about these packages. We can log in, we can log out. We can come over here and say /about to go the about page. So what I'd like to do is to bring in some of this design. This is not a web design course. This is just to teach you how to take the concepts of web development, including design and harness them with FastAPI and use that very powerful framework as the foundation instead of something like Flask or Django or Pyramid. So what I wanna do is, I want to copy this overall shared layout feel into our web application. Now, in our static folder we have site.css, which has the one silly thing there. We're gonna remove that and we're going to add in a completely different set of files here. So over here in our static, it's empty. But what we want to do is paste styles from somewhere else. I've got those copied from something I've already written. And over here, you could now see we've got a whole bunch of stuff. Look, we've got, say, our site CSS, which has a bunch of web design, our navigational design and so on. And we've got external CSS files like Bootstrap and jQuery and so on. jQuery is just JavaScript. We've also got some images. So that's just gonna be the general layout. You could go and study that if you want to mimic it. But the point is to show just how to use this and build a really cool application, right? So that is step one. The second step, in order to use that is to put our, go into this shared lay out here. Right now it's incredibly simple with just one CSS file that we actually deleted, but there's really not a lot going on here, so I'm gonna copy over the proper one, and let's take a look at what we have now over here. So we've got more style sheets, we've got Bootstrap, we've got the site, we've got the navigation. We have a few more slots to fill in if we want to add additional CSS, we may end up doing that. Over here, we've got a toolbar, a navigation bar that comes from bootstrap with things that look like the main PyPI site like "Donate" and "Help" and "login" and "register". Here's our main content as we talked about and then it's got a footer and some Javascript to make things go. Other than that, we've only dropped in the CSS. and the images, which change nothing. There might be something that's dependent upon what we pass over, but I don't think so. Let's give it a shot. See if this will work. Look at that! Now, that might not seem that impressive, right? But here's our content and here we go to our about. Here's our about, there's our home page. Notice we've got our common look and feel. Just like over here, you can see we've got our common look and feel, our navigation. Down the bottom We've got our footer. So just like that our site is ready to go and there's really nothing fancy besides I brought in just some CSS and some basic HTML and our goal is going to be to start writing the code that fills out these pieces as our login. This one's empty for the moment. Remember we didn't turn, do anything with what we're returning from there. We've got our register. But you see, those were actually, those links are starting to work. So very, very cool. We've got our overall look and feel, in the real web design, put together. Let's see how we did. Here's the real pypi.org. Roll that up, now we can scroll it up. It's just stuck there but look, pretty, pretty good, pretty good I think in terms of, you know, the navigation and such. So we got a ways to go, but we're making really good progress here.
|
|
|
transcript
|
5:43 |
So we saw that we were able to get a really solid looking overall layout. We have our navigation, we have our footer, all those kinds of things. And yet, when we look at this here, it still has this big fake section in the middle. Remember what we're aiming for. It's supposed to look like this, this cool search section, this info box here with three pieces of information, a list of packages. But what we're gonna do here is copy over the HTML and then write a little bit of code for first passing over fake data. And then when we get to the SQLAlchemy data-driven section, we're gonna have real data. So let's, just like before, go over here and drop in the real HTML. I'll talk you real quickly through it. There's not much to it. It uses the layout, the same, the same shared content section and so on. It has this little "hero" section that has that big header with the search text. We have the styles and the CSS we already included. We have that stats bar, that gray bar here and it has the package count. Instead of just showing it as like this, we're formatting the string to do digit grouping. So if it's 120,000, it's a 120 comma 000. We need to have a package_count, release_count and user_count. And then, we're gonna go over here and we're gonna do a loop through a list of recent packages. And for each package, we're gonna have the "id" and the "summary". So we've got to write a little bit of code for that to work because if we try to view this now, we'll just get some weirdo server error. So here we get this crash. So you saw we're getting an error over here, and the error is, and in Chameleon it's unfortunately super hard to track down the errors. You get all this junk here. Look at all this. In the middle, you could see that's the real problem. NameError package_count. Jinja, if you don't provide some kind of variable, it'll just come through as None and then whatever happens then. Chameleon makes sure everything is hanging together, it's good in that regard, but it's also a little annoying that you have to be exactly there. So let's go to our home and remember what we have to pass over. So let's just for now, add some fake data. And then, like I said, we're gonna be getting this from the database. You will be data-driven and we won't be writing this code here, but we do need a package count. Let's say there's 274,000 packages and there's a couple others right in there. We're gonna need a release_count, which will be two million ish like that and the user_count is gonna be, let's say there's 73,000 people who have created accounts here. We're gonna need a packages which is actually gonna be a list, and into each one of these, we're gonna need a little dictionary that has an id. So let's just say one. I think it's a "summary", it's what it is. We'll look at it in a sec. There's three things we need, I believe. And here we need the "summary" and the id. The id is like the actual package name. So this would be, let's say FastAPI, a great web framework. That uvicorn, favorite ASGI server. And httpx, alright. I think those three should do it. This is not misspelled, right? One more time. We have enough data. Is it gonna crash? No, it's not gonna crash. Oh my goodness, that looks fantastic! So here's our hero section. Here's those counts. Here is the number of projects, the number of releases. Notice the digit grouping? yes! Number of users, and here's hot off, the releases. Out three most recent projects or packages are FastAPI, a great web framework. Uvicorn your favorite ASGI server. And httpx, requests but for async world. Now these have links that if we click, don't go anywhere yet. We're still working on that section, but very cool, right? And maybe one thing we haven't really talked about and it's not necessarily super obvious the first time that you see it, would be, how do you do loops? Right, in Jinja, you create the percent you say "for thing in that", then you end the loop and so on. It's more implicit here. So this is the thing that's looping. Basically, this is, that will stop helping, it, this is "for p in packages", repeat that whole <div> section, including the part that has the "repeat" on it. So we're just cloning that <div> over and over, and each time through, we have this "p" variable that is one of the packages. So that's how we got that repeated list of projects right in the home page. Super cool, huh? So we've come a long ways from returning a string that comes out as JSON, converting that to an HTML response that just has embedded HTML. To now using a shared layout that brings in all the important pieces, including the navigation, a common look and feel, and then leveraging that overall CSS and designs theme brought in to bust out a cool little homepage that looks like this. We've used our template decorator. Go ahead and find the starting template, a Chameleon template, which then finds the shared layout through the template engine and so on. So I think we've come and built a really nice way to layer on proper web development on top of FastAPI. Of course, there's lots more to build. There's some cool data layers that we've got to talk about and things like that. Already, hopefully, you can see the potential for what we're building here.
|
|
|
|
38:37 |
|
|
transcript
|
1:44 |
Our web application has come really far. If you look at the design, it looks a lot like the PyPI that we're looking to build. We don't have our real data coming from the database yet. We're getting there soon, but if we had that in place, it would be quite close. However, there's a few things that I would like to touch on before we get there, that are going to help tremendously as our web application grows. So there's two core design patterns or concepts that we're going to go through and integrate into our PyPI clone during this chapter. One is called "View Models". Now "View Models" are curious when we're working with FastAPI They make perfect sense with Flask or Pyramid where there's no natural exchange mechanism between the HTML data and the view processing and sending that data back and forth between that template. But in FastAPI, we have Pydantic. So we're gonna talk about how "View Models" and Pydantic should coexist, when to use one, when do you use the other. Because you might think you can just use Pydantic models and to a degree, you can, but they're not nearly as advantageous as what we will get with working with view models, as we'll see. Also, we're gonna talk about services. These are not web services or APIs but just things that provide group functionality to our application. So there'll be a "package service" that lets us do all the database queries and processing and answer questions around packages. Similarly for users, if this was a real app, maybe we would have something that worked with email and it would figure out how do we resend a reset email? Or how do we load up templates and then pass that up and things like that. So the are two patterns we're gonna talk about: "View Models" and "Services". And we're also going to compare that with Pydantic as well. And you're going to see, we're gonna be in a really good place with our web app after this chapter.
|
|
|
transcript
|
3:41 |
Before we start writing code around this view model pattern, let's just take a high level conceptual look at where it fits in the whole web application process. So on the left we have what I imagine, some kind of HTML form where data is being exchanged with a browser. So the form represents like, say, the Chameleon or Jinja template. And it's got all the data that the users typing in and is going to be submitting back to the application. The application may also need to provide some data to that form. Like, for example, if there's a drop down of countries that you wanna pick Well, you've got to send over those countries to that form. Most likely you don't want to hard code that into the HTML. This view model, its job is going to be to manage that exchange. So on the left, we've got a browser with an HTML form that is driven by a template. On the right, we've got a big action method because, what happens here? when they submit this form for in this case, registering for our site, they're gonna put in their first name, their last name, their email address. Maybe they've gotta checkoff a re-captcha type of thing to make sure that they're not some kind of bot, and so on. Our website, our action method over here, our view method is going to actually need to look at that and say, well, did they supply a first name? Yes or no? Did they provide a last name? Yes or no? If they don't provide the last name, tell them they have to provide the last name. If they provided an email, make sure that it's actually a proper valid email, not just some random text. Did they provide a password? Is it secure enough? Like all of those things have to happen. And then we go and create the user. And at each step, if something goes wrong, we need to send back a message like, hey, this didn't work. And very importantly, we need to round trip that same data, if they typed in first name and last name and email. But email wasn't right, we want to reload that form with the same first name, the same last name and the same email and just say, here's what you typed, but please correct it. That is a really important part here as well. So the job of this view model is instead of writing all of that just in this one view method, this action method, which makes testing hard, which makes editing the code or adding features really hard. We're gonna break this action method into another part, using this view model. So it will have a small little action method. And the view model will be a class whose job is to understand all the data that the page needs, all the data that the user is supplying, how to round trip it and how to validate and report errors on it, as I just described. And then this action method is just going to say, hey, they submitted the form, please load it up and tell me if it's good. If it is, I'll create the user. If it's not good, we'll just send back that same data you have along with the error message. That's the idea of these view models. And like I said, it sounds like Pydantic would be a really nice choice here. But there's a couple of problems. Pydantic, when it runs into errors, it doesn't hang on to the data anyway and then let you send it back. It just crashes and says, hey, we tried to accept this data. It wasn't right. Sorry. And while that's super perfect for what you need in an API, it's not what you want for a web page. We'll see some concrete examples of this later when we actually write the registration method in the next chapter. But for now, let's just put it to the side that Pydantic models are perfect and such a cool library and way to work with data exchange with FastAPI for the API side. But they don't make as much sense when you're trying to make a web application with HTML templates. We'll come back to this in more detail, and we'll see exactly why that is, later. Here's what the view model pattern looks like and how we're going to use it to isolate the data exchange between the HTML template and some of our code and not mix that in all over the place. Make it easier to test that data exchange validation, and it will keep our view methods nice, clean and simple
|
|
|
transcript
|
8:44 |
Welcome to chapter five. Let's get started working on these two patterns view models and services So, as you can see here, I've made a copy of what we completed in chapter four and that's what we're starting with in chapter five. Let's go ahead and open it up and over here we're gonna focus on this view right here. Let's just run it and remind ourselves what it looks like. So it's this page here that shows a couple of things, and we're gonna add something else that's gonna be interesting that we weren't able to do easily before. Here, we've got the number of projects, the number of releases, the number of users and then the most recent projects. So what we're gonna do is we're gonna create a view model that provides this page, this template, that data. Now we're gonna start simple here because we're not exchanging data. We're not accepting data yet. Later, we're going to write a login and a register bit of functionality. This is gonna let us do many things, work with HTML forms and validation and all that. That's when you'll see these concepts of view models really shine. But I wanna, you know, make progress down that road until we can get to the user section in the coming chapters. What we're gonna do is we're gonna create a view model that just provides data to this page, and we're gonna have some services that work with projects and users. Let's go and create a "service"s folder. And like I said, we're probably gonna have to. I'll go ahead and just write it here, package_service. Again, this is not web service in the traditional sense of the API. This is a thing that bundles functionality and think of it as a layer between your actual data layer and the rest of your application. It knows how to do all the queries to SQLAlchemy. It knows how to interact with external APIs that you might need for, say, sendgrid or mailchimp or something like that, using either of those services. While the user service, here, the user service might know how to verify passwords with cryptography. In addition, it's not just data access layer, that's no what. It's why I'm not calling it that. OK, so we're gonna need a couple of things in order to do that, to make these useful. But let's go ahead and do our view models, now recall that we have some really cool naming conventions that allow me to say, well, I'm looking at this. Let's say I'm looking at this function, this view method. I want to know where's the template. I don't have to guess what it's called or like track it down. I go. OK, so it's home index. So it's home index. We're gonna follow exactly the same pattern for view models. That way, if you're in the view model, you know where the function is. That is the view function. You know where where the template is. It's really nice and organized. So I'm gonna go, create a directory called viewmodels. And in there we're gonna make a directory called home, and at home, we're really just gonna probably need one view model. We're also gonna need to have a common base class. I'm gonna create something called shared, and I'll put, I'm gonna calle it viewmodel_base in here. Maybe just a few models. Here we go, and we'll have a class. Now, it might seem silly like, why do I need this base class? What is its job to be? There's a couple of things that we want to make sure every single page has all the time. For example, when we do user management stuff, we wanna have it be the job of these view models to tell you what user is logged in and potentially provide you with that user and so on. If you're in a form, they always are gonna be able to provide an error message if something goes wrong with the form. So there's a couple of things like that that are gonna be part of this base model. The other one is, we need ways to easily provide the fields of the class as a dictionary. So those are the two rules here. So a ViewModelBase, let's call it. And down here its gonna have a couple of things so we'll have an error, which is an Optional, we're gonna need some typing here, string, which is None. And let's have ah user_id, which is an Optional integer, which is also None. So those were the two core shared pieces of data. We're probably gonna pass around some more. It's often helpful to have access to the request that comes in as you'll see for, like, cookie management and stuff like that. So let's go and add that in here as well, and PyCharm will gladly add that. Now wouldn't it be cool if it typed that for me? OK, so it'll have this stuff and then, in order to pass these things back we're just gonna take advantage of the fact that when you do this, what it's really doing is putting an entry in the class dictionary. So we'll say def to_dict, gonna return a dictionary. And what's gonna be in here, we're gonna do is just return self.__dict__. So this is looking good. This is gonna be something common to all of our view models. We're probably never going to touch it again. And then, now let's go. Remember, we are in the index, and in the home I'll say, indexviewmodel. Add a class IndexViewModel like that. I'ts donna derive from our base class, which we import. Thank you, PyCharm. And it's going to need, yes, it'll need a constructor. Alright And PyCharm says there's one that requires something passed in so well let PyCharm write all that code for us. Thank you, thank you. Super cool. So let's go back. Now that we've got our structure in place, Let's go back up here to our home view and say, What were we doing before? we were coming up with all these elements, this dictionary that has a package_count, a release_count, user_count and a list of packages. I'm gonna copy this over. And this will give us a hint on what we're going to need in our indexviewmodel. Over here tells you that we're probably gonna need a self.package_count, which is an integer, and I'm just gonna put None, I'll put zero for a minute. We're gonna come up with a better answer in a moment, and we need a release, release_count and a user_count. And then it is the order here we're gonna need packages. Which is gonna be a list of something. We don't know what goes in the list yet because we don't have a class for it, we will in a minute. And we'll just say like that. OK, so let me go and comment this out and see if we can now swap this out to be our view model. And I'll just put 1, 2 and 3. So we have some little big data, it's just so you can tell actually, something is flowing from one place to the other. So instead of this. What we're gonna do is we're gonna say vm for view model. It's one of these. We've gotta, of course, import that as above. And then we have to pass in the request. PyCharm'll help us get that close. close. We've gotta type that in. FastAPI uses the type hint here to know that what you want to pass in is the request. So this is all we have to do, and then it'll start passing it over. And then again, if we don't pass anything, watch what happens. We get a crash and the crash is NameError somewhere. The NameError is right here. package_count. You're supposed to give me a package_count, and you didn't. So let's provide the data from here, which will be to_dict. It was basically like before. It's gonna build up that dictionary like we saw. Not as much data, but close. Yes! Look at that 3, 1, 2. Maybe we could've changed the order to go 1, 2, 3 but still cool, right? So it's provided this information. It's gonna get it from somewhere else in a minute, but it's provided this information, and it's given us an empty list of new releases. We're gonna need to get them from somewhere again. Pretty awesome, right? So this is how we're going to pass data over to our template. Now let's go back and look real quick. Suppose that we want to make sure that the request is not None. We want to make sure that you know some data that we're pulling back is valid here or if we pass in more things like we're passing a form that the form contains the elements that we expect. It's really, really easy to write a unit test against that class right there and do that validation without doing any web test infrastructure, which is always kind of a pain around unit testing web applications. So it allows you to really carefully test the exchange between the template and this thing You could even actually use the template engine to directly try to render a test instance of one of these things. So that's pretty cool. It's also going to keep this method extremely simple. For real ones, it's gonna be slightly more complicated than that but not a lot.
|
|
|
transcript
|
3:41 |
Well, we had our little random fake data here, but let's move over to using our services to provide data here. So what I wanna do is, I want to go to the package_service. And I wanna have it answer a couple questions. And I can hit Ctrl + space two times and PyCharm will automatically import it up there. Awesome, and I wanna have just a couple of functions that'll tell me how many releases for packages are there and how many packages are there. So we'll say release_count something like that and we'll do right there package_count. Let's spell that right: package_count. Now, those don't exist yet, as you can see and we'll have user_service. Again double Ctrl + space puts it at the top, and what we want to do is say, user_count. And down here, let's say package_service.latest_releases() and let's pass in limit=5. We don't want to get all 200,000, we just want the five latest releases. This is what we want our services so far to look like, to provide data over here. We can have PyCharm, write it for us, and we can say this returns an int, which is great. We're gonna need that again. So I'll just copy it. And down here user_count and create that function there, returns an int. And this one is going to return an int, this is where we're going to write our SQLAlchemy queries in a minute, when we get to there. But for now, eventually it's gonna be a list of package classes but we don't have those yet. This is gonna be an int, and the default will be five. Now, here's where we would go and do a count against a query for the release table. We do a count against query for package table or we do an order by and then a limit over on. I said latest_releases. We want that to be latest_packages. Sorry about that. We'll do a some kind of query that orders by the release dates and then does some kind of limit on that. That's where we're going, when we get to the SQLAlchemy section. For now, let's just go and put these numbers back in there. So, which one was that? That was package_count. So when you get package count, we're returning that number. When we get to the release_count, it's that two million. Again, this is just fake for now, just to get the layers in place. I wanna keep going from there, right? So user_count is going to be over there, clean this whole thing up. Perfect. And lastly, here's what we're gonna pass back for the packages and let's go and use that limit. Obviously, we're gonna go against the database, but because slicing is so easy, we can say go from the first up to however many they pass in. That way, if we say two or whatever, we'll be good, let's go and run this one more time and make sure our app is hanging together. Starts, that's a good sign. There you go. Look, now we're back to what we started with. Great refactoring, huh? So here we've got our projects, our releases, our users and here are our latest packages again. The difference, though, is this time, around the view method. Again, this one's pretty simple but when we do like registration stuff, there's still gonna be a decent amount of things happening here. So this lets us isolate that data exchange, This class has one job. Its job is to know what this one temple needs. It needs package_count release_count, user_count and so on. Its job is to go get that data and then provide it to it. And if it were some kind of form, accept that data back, validate it, convert it, and so on. Cool. So now we've got our app converted over to use view models.
|
|
|
transcript
|
3:08 |
We saw our one complex page so far, our index view, with the page that has the counts of the packages and the latest ones and so on got converted to being, to using view models. But the others, there's something that we could also do as well, and we'll see why. Maybe I'll write the view model here for this one, but we're gonna leave it off for just a second. In fact, we could just use the base one on that one. But if we look over our account view, which is right here, notice that there's a bunch of stuff going on and we're not actually using them yet So just to, while we're on the topic, let's just go ahead and put some placeholders in place here. So I'll take you through the process again. We're in the account view module. So what we need to do is go over here and create a directory called account, and we have an index, we have a register, we have a login and so on. Let's go knock those out real quick. So, IndexViewModel. I mean, we call it just AccountViewModel because it's slash account. You can decide what you want to call it. I guess we'll go and call it that. So this'll be a class. I don't like the name. Hold on. We'll fix that, let's go over here and rename it. What I would prefer is having account, maybe like this, it'll make it easy to read viewmodel. OK, pass is fine. We're just gonna leave these alone for a minute. Easiest way to create more is to just copy paste. So let's have a register_viewmodel. Make sure we change the name. And we're gonna have a login_viewmodel as well. We don't really need a logout_viewmodel because that's just gonna make a change and send them somewhere else. So LoginViewModel, and then we can just start using those here and say vm equals this AccountViewModel, that. It's going to need the request. Which we want to have it at the perimeter. Thank you, like this. And then again, here what we do is just say, return the dictionary of this thing. I'll just copy that because it's really similar, register and login. It's this view model here that you're going to see that actually is where a lot of the magic of these view models come from. So we got that in place and then I think that's pretty much it, you'll see over here that we could do this, just equals ViewModelBase like this and pass over the request like that. But I'm going to leave this out for just a second. Because I wanna show you one of the benefits that we're gonna get from using view models and sort of run into an issue here. And then we'll come back and just say, well, look, if we add this view model, everything works great. All right, so that was just a little bit of housekeeping to get everything set so we can start writing the rest of our application.
|
|
|
transcript
|
1:08 |
Let's see how far we've come with our website here. So we go over, we got our login and register. Those don't actually have the right return value yet, but that's OK. We'll come back to that in a second. But over here we've got these packages and we've got lists linked to them, right? So we go /project/fastapi, /project/uvicorn I personally would probably choose like /package or /packages/ that. But if you go to the real pypi.org this is the url structure they use, so we're just gonna stick with that to be as close to what they are creating as well. Now, if you were to go to the real PyPI and let's just look at FastAPI real quick, and go in here and you scroll down you notice there's quite a bit of stuff. There's this sort of main banner section with these different installs. What the release was, whether or not it's the latest version, stuff about the history and the versions and the forks and the authors, then a big description here in the middle and even if you go to the release history, go back to a different line, you can see it shows you different install statements, information about whether or not it's the latest version and so on. That is what we're going to build.
|
|
|
transcript
|
3:44 |
Now I'm going to start again from existing HTML because, like I said, this is not a web design course, this is how do I do websites in FastAPI. So we're gonna just look at some Chameleon and then go from there. This is what it's gonna look like, we've got our content details. Again we're using our shared layout, as we will with basically everything. Here's our little hero section pip install such and such. And if it's not the latest version, we're gonna do an equal equal the release version that's selected. Stuff like that. Here's the summaries, the stuff along the side, and when you download etcetera, etcetera. So there's a lot of things that we're going to need. For example, we need a package, which has a license, a package which has a description. We're gonna need whether or not it's the latest release. Let's see over here. So what we're gonna do is we're just gonna go through and try to get this to run. We're gonna miss a few things I'm sure. We'll then go back and update that as well. I'll just copy this for a second, that will give us the simplest path to do that. Got a couple of things to import Starlette's Request, fastapi_chameleon's template. And here let's just call this details, DetailsViewModel and let's call this details. Remember, the URL is going to be slash project, wish it was packages and then it's some value that goes here. It was a package name. So the way we do that in FastAPI is like this, we put it in here and we give it a type. This one is just a simple string. OK, so that means this is a required element in the URL. There's no defaults and it's going to be a string. And because of the somewhat unusual naming structure here, we need to set the template file explicitly. We can't just go with the standard convention. So what is it? It's packages/details.pt Here we go. Now we don't have this DetailsViewModel. Again it's gonna have the same structure. So in the viewmodels like before, the easiest thing to do is probably make a copy, make a new directory called packages, and in there we're gonna make a new Python file called details_viewmodel. Go do it yourself, copy this one over. So this is gonna be DetailsViewModel, and it's not gonna have any of this. A little placeholder. OK, so this is going to be our basic structure and import that. We also need to pass over the package_name, right. So this is part of the URL. In order to get it, we're gonna pass it on, so I'll copy this and put it right there. Perfect. We want to make sure they passed over a valid package name, and that is not empty. The routing will probably do that for us. But what we can do is we actually want to make sure that not only is this a valid name, but if we do a query against the database, we get an actual package back. What we're gonna do is gonna say self.package is going to be package_service. And I'm gonna do a query, let's say get_package_by_id() And package_name is what we're using here. Then, if we don't have any value for the package, we're gonna want to make sure that we return some kind of 404 and so on. So we'll say, somewhere we'll say something like this, not that, return. OK, so we've got to write this function, and right now this is gonna be a string.
|
|
|
transcript
|
7:57 |
I think it's probably about time to create a class for our package. Eventually, this is gonna to come out of the database using SQLAlchemy. But for the moment, let's just get sort of started down. Cause you saw when you looked over here and we reviewed this. There's a lot of stuff, like a package has an id, and it has a summary and there's one more thing down in a home page and so on. So what we want to do is take all those things and put them into a class that ultimately we're gonna map into the database. So let's make a new folder. I'll call this data, something like that. Alright, ultimately this. Like I said, it's gonna be a SQLAlchemy model, along with many other things. But for now, it's just gonna be a simple class. For now, when we create it, we want to just pass over this name. Here we go, we won't add any validation or anything like that. We just need enough going on here so that this works. So I need to pass over the package name, which also turns out to be the id, gonna use that in the database for the id. And this now, we can say is going to return an Optional[Package]. OK, so we're gonna just return an empty one for now. Just return None, were gonna get this working in a second, but let's go and finish filling this out so that it will work with our details. Let's just go through and see what we need. We need an id, we need a summary. Here's the id again for just the URL, home_page. And I need a license like, is it MIT, BSD or whatever. author_name, here's a bunch of maintainers. So it's going to need maintainers. I'll just make that an empty list, license, I think we've got that already, yes license again. Description and that's gonna be it I think, perfect. The short description and a long description. OK, so let's say we also need to pass over a couple more things here I need a summary, description. I'll just knock these out and we'll assign them. All right, we've got our package created. Now, there's one other thing we're gonna need to do to make this page work. Looking here, a little bit simpler, but we do have more information. We have a latest_release, which has a created_date. I think that that might be all that the release has. But for the same reason, let's go and create a class here, call it release. We'll add this latest_release over here. This is a datetime.datetime, perfect. And it's gonna have other things as well. Let's go ahead and say it has a version, it's a string like "1.0.0" or so on. Great, so that will be what we can add over there as well. Now back to our view model. And let's just make sure that we're passing enough details over. Again, there's a lot going on here so we'll have self, and we have the latest_release. I will just call this. Actually, this was created_date, I believe. The variable was called latest_release. Perfect. It's gonna be a release. We'll just make up some fake data for a minute. What do we need? let's say "1.2.0" and this will be datetime.datetime.now and for our get_latest_package_by_id, let's put it in here and just have it create package, and put some info into it. So what we're gonna need? we're gonna need package_name, that's what we're passing over. Summary will be "This is the summary", "Full details here!". And for the home page let's just put, passing over FastAPI, obviously this is hard coding it, but we got a whole bunch of data coming along soon. The author will be Sebastian. Here we go. Sebastian Ramirez, and the maintainers can be empty. All right, that's gonna be our package, and we'll just return that. Again, this is gonna come from the database, but for now, we're just gonna return some fake data. And while we're doing this, let's also, one more thing, let's have this package_service.get_latest_release_for_package and let PyCharm add that final function, which is going to get a string and it's gonna return this. It's an Optional[Release]. Maybe they're asking for the release of a package that doesn't exist or the package doesn't have a release yet. Something like that. Here we go. I think we might be good. Let's go and run this and see what happens. There's still gonna be one or two little pieces. We need to put in. The moment of truth. What happens if I click this? Crash! I'm sure there's a NameError somewhere. Let's go find it. And latest_version. So latest_version we'll be. There's a few little things like this that we gotta figure out, let's just go "0.0.0" and if there is a package and there's a release, then we'll have to leave. But if there is one, latest_version, latest_release.version, I'm gonna say that. For the moment, let's just say self.is_latest is True. We're going to come back and we'll be able to check what release they've asked for and whether or not that is the latest. Down below, Yes! we've done it. We've definitely done it. OK, so there's a couple of things we're gonna need to do to make this work a little bit better, but we're quite close. So here, like if we go to the project's Homepage. Notice, it takes us to FastAPI. Here's the description, here's FastAPI for the name. The license is MIT, the author is Sebastian Ramirez. Here's a little summary. One thing that's missing though, is there's an extra CSS file for this page. Come over here to static and you see this package? We need to use this. Well, where does it go? Remember our layouts and our shared look, we had this define-slot additional-css that goes right there. This is that structured way. This is the location where additional CSS goes. Not before site, after site, for example. So we're just gonna go down to our details, and if we're doing any of those things, we're not. Let's close this up, a little easier to read. So what we do is we just put a <div> and we say fill-slot and we can omit the tag. And then what do we want to put here? We just put a link to /static/css/package.css. Format it a little bit, run it again. And tada! There we go, We have all the final designs brought in. If we do a View Page Source, notice the indentation. There's not much we can do about, but right in the location we expected, there is now a package.css included. I love that, and layout that we got working here. So this is really, really nice. Now we're using fake data. Again, we're about to get to the database, but this is really nice. What we've got going on here. We've got our home page, so let's go back home, we got our list here. Click on uvicorn, and of course, it's not using any of that data other than just that little bit right there. Still, pretty cool, right? About close to a functioning website.
|
|
|
transcript
|
4:50 |
Let's go look at our views one more time. We're just about there. We've got our account stuff going on here. Account views with their various view models, and we've got the home view with it set up. And the package view going on here. These are all good, but if we look here, there's this one we left this TODO. Remember that? Let's see one more thing to do with these view models that is really, really valuable. So one of the things that you often want to do is provide some feature, some functionality, to every single part of your application. Every template. It's just gonna be common across there. So let's look at a really straightforward example that's over here in shared. I've got this login and register. Well, guess what? What if I'm logged in? Do I still want to see login and register? No, I want to see a link that says your account and a button that says logout. Wouldn't that be nice? So how do we do that? Well, it's really super simple. Over here in Chameleon, you just say tal:condition, and then what? Like, is there a user_id? Let's say that that's gonna be something we can get really cheaply because it's gonna come from the cookies, which is just a dictionary, not from the database, which maybe would be more work. So instead of testing for a user, we're just gonna test for the user_id. Maybe a better way would be, say is_logged_in, are logged in or has_account or something like that, right? Make it a little more abstract. That would be nice to have. We'll say that we don't want. It's gonna, It's not the case. And if it is the case, then we want to say, change these around a little bit. So if you are logged in, we wanted it to go to just /account, and this is gonna say "Account" and this is gonna be/account/logout and down here it'll say Logout. That's great, right? Let's go and run it. Mmm, not as great as I was hoping. Probably not as great as you were hoping either. What is the problem? without looking. It's NameError: is_logged_in not found. Right there. It doesn't know what the heck that is. So what we do is, we go to our base view model and it always pulls this and sets this. I'll say self.is_logged_in = False. And then maybe a comment, right. We'll set that from a cookie. And it'll be really straightforward. So what's gonna happen is, the view model, anything that is either this or derives from this is going to have that information. So every single view now should have that info there. And what is our problem? Oh, I said case, didn't mean case. I meant condition. Somehow I got that, condition. Sorry about that. I'm sure you noticed that and you were like: what is going on here? Condition, I said condition, but autocomplete gave me case. There we go. Again, perfect. Now, right now, we said there's nobody logged in and notice if I go to any page on the site. Always working, go over here to our ViewModelBase and just say True. And obviously you wouldn't just hack that and say, of course, you're always logged in. What you would do is get that from user. But check it out. Now we have Account and Logout. Have it over on the home page, we have it on this page and so on. But if we don't use the view models everywhere, remember our about page? Crash! Again, all of a sudden, what is going on with our site? Well, here's that NameError that I was telling you about. In this particular view, that information our shared layout needed, didn't get what it was expecting. So it crashed, right? So these view models provide a really nice way to send that information to everything as long as everywhere you use it. And if you don't need any details, we can just say return the to_dict() or just the base, right? We didn't have to go create, like, an AboutViewModel here, but by using it everywhere. This is working great. There's other ways to do this, the view models provide a really nice mechanism. And if you're using them in most places, just use them everywhere and you'll be good. So back here that works, this one works, everything works. Great, just one nice chance to show how this ViewModelBase provides common data and common functionality for the entire template engine. Well that's it for view models. I hope you found this way of partitioning our logic and data exchange into view models and services really nice way to keep things like our actual view methods really clean. Create some testable little classes that we can test in isolation and provide common functionality to the entire template engine.
|
|
|
|
39:47 |
|
|
transcript
|
0:49 |
We've added some different links, depending on whether or not a user was theoretically logged into our website. It's time to actually greet users, let them log in, let them register, using HTML forms for our site. There's two main takeaways from this chapter. One, how do we deal with having users, who need to have accounts that are stored securely in our database? And, how do we do HTML forms we can get and post back for FastAPI with templates. We're gonna combine these things by creating the login and the registration features for our users in this chapter. We're gonna learn a lot about how to work with these forms and we're gonna use view models as the way to do some of that exchange. I think you're gonna see this works really, really well with FastAPI with it's native understanding and embracing of HTTP verbs.
|
|
|
transcript
|
1:46 |
Let's start off this whole chapter by creating a basic user class. And then we can use that for our form, our validation, our logging in. All that kind of stuff. So you can notice again that I have created a copy of what we finished for chapter five. Now that's where we're starting for chapter six. Over here in our data section, we have package, we have release. Let's add one more class, for the user. And let's call it class User, and it's gonna have a couple of things. It's gonna have a name. So, it has name, it'll be a string. It's gonna have an email. It's tempting to say it has a password. You never, ever wanna store the password. You wanna store a hash of the password and we're gonna use a really cool library for this. Another thing that's nice to know when people sign up is: when did they create their account? So let's go over here and say a created_date, and I'll just put that as None for the moment. There's two more things, we're gonna have a profile_image_url, which is gonna just be some kind of string that we pass over, and we'll have last_login, which is a datetime, perfect. So this is our basic user class that we're gonna work with. And this is optional, but we'll come and make it work when we really do our actual thing with it. Let's give it a few pieces of information. Let's say we're gonna pass over the name, the email and the hashed_password. Those will do it for us for now. Perfect. So we're gonna go and create this, add couple of users with our form. Let them login through our user service, things like that. Here's our basic User class. Remember, what we're going to do is convert this to a SQLAlchemy ORM model with basically these columns. But until we get to the database in the next chapter, we're just gonna work with it in memory.
|
|
|
transcript
|
3:02 |
Before we go about writing our login form or a register form or any HTML form. Let's talk about a pattern that is super common on web applications, and we're gonna use it here in FastAPI. It's the GET > POST > Redirect pattern, and for sites that are designed well and you've had good experiences with, I'm sure they're using this pattern over and over again. Let's talk about it. So we've got our server, our server stores it's data in a database, and we've got you sitting on your laptop working with your web browser. Let's suppose you want to go to the site that's hosted on the server, you want to create an account, you want to register for the site. How do you do that? You visit a page and it shows you an empty HTML form. The way you do that is you do an HTTP GET request against /account/register and an empty form comes and says, great you'd like to register? what's your name? what's your email? what's your password? They always make you confirm your password, or sometimes even your email both of those are annoying to me. I don't really like it that they do it. But, you know, that's how these things go, right? You have one of these, these types of forms that gets shown here. Then, you edit it locally and you want to say I filled it out, save it on the server. What you're going to do is an HTTP POST, often back to the exact same URL. That's gonna take the form, post it back to the server. Server's gonna look at that and say, well, now you're submitting the form instead of wanting to just see it because it's a POST and not a GET and it has data, it's not empty. If it's good, you get to carry on. If there's a mistake, the form, that POST will just reload the page and say there's some kind of mistake, you know, like that account already exists, you can't use that email address or whatever. But let's assume that it worked out well. What it's gonna do is save some data to the database, and then it's going to send a 302 redirect like you submitted the form but now we want you to go over to /account. The last thing you want is to just stay on that registration page and say OK, now go find somewhere to go. No, you take them where you want to go. So in this case, they've created an account, let's take them to their account, or maybe to their onboarding for whatever this website is, they'll GET > POST > Redirect. Super, super common pattern on many, many websites. And that's how we're gonna construct, how we're gonna put together our user login as well as our user registration. So we're gonna have one view that handles the GET to register, the one that just shows the form. The other one is gonna handle the POST which actually validates the data and creates the accounts. Now, if you look around, you'll see that this is not a pattern that I just made up. It's also something that gets used in a lot of places. Over on Wikipedia, they call it the Post/Redirect/Get To me, and I don't think so, I think of it as GET > POST > Redirect. You start with an empty form, you submit it, you go somewhere else when you're done. Here, it kind of starts like halfway through that process. Like I guess you're posting something you magically acquired, right? So anyway, they call it Post/Redirect/Get. You'll see it under several names, choose the one that you think that makes the most sense. So common pattern. Anytime you're working with server side HTML forms, which we are, and we're gonna do that for our account management.
|
|
|
transcript
|
5:36 |
So far, our login and register haven't done anything. Remember, if we look over in the views, they just return empty stuff and they were actually crashing because they didn't know a template that went with them. So we're gonna address that in just a second. But let me go and copy over some HTML, just like before. I'm just gonna use some standard HTML that's already here. So, for example, when you just go to your account it says "Welcome to your account", whatever your user is dot name and when you go register it's gonna provide you a form that had, lets you type in your name your email, your password and if there's an error, it'll show you what that is. OK, so this is a standard HTML form that we're gonna use, and we're just going to go here and we'll do. an @template(), let's see, we've got account index, got account index. I think we could just throw the template on like that and like that. OK, so this is almost ready to work. But if you go and actually look at, say the index, it has a user which has a name and if we go to our view model, it's not going to provide that data. So what we're gonna get is that there's going to be a NameError, so let's go quickly provide a user. So this user will probably come from the cookie that we get, we'll get an id. And if we have an id out of the cookies, then we'll be able to pull them out of the database. But for now, we're just gonna say the user is going to be a new user, which we're gonna hack together in here. And it takes the name, so I'll just put Michael and michael@talkpython.fm, and the hashed password is, whatever it is. And we also need to call the base, like that. OK, so this, let's double check that our user has a dot name. They do, so this should work. All right, now, let's go and give it a try. We need a way to log into here and indicate whether or not we're logged in But it looks like that is working in terms of the HTML. That's cool. And let's go see about doing something similar for register. If we look at register, we're gonna have to provide some information over to it name, email, password. We go to our view model and do the same thing. def __init__, add the super() call like that. And we're just gonna have a couple of strings. So we'll have email, the string, an optional string because maybe somehow it didn't get submitted. Gonna start out None, and as a minute, at a minimum, we have name, email, password, and then the error is gonna come from the base class. So there's nothing special we have to do there, And let's see if we have everything we need. Name, email, password, error. I think we do. Notice that we're also pulling in some extra CSS to make this look good. We go back and try to register. Tada! Look at that. We also have age in years, we don't really need to use that. But it was there, just for some, we're gonna use it just to show some of the client side validation in just a little bit. All right. So we've got our name, we've got our email address and we got a password. What happens if I fill this out? I really love the password "a" So that's nice. I'm gonna go with that. And my age in years is 18. Click register, "Method Not Allowed". What is that? Well, this is our POST, remember when we went to it like this, that's doing the GET. But when we pressed that button, it's submitting the form, which is a POST. Now if we go back and look at PyCharm here, at the view. What do we say? well we say, well we can handle an HTTP GET right here to this URL. But where are we handling the HTML, the HTTP POST? we're not. Remember the GET > POST > Redirect pattern. So that's what we need, to add here. When we do a GET, we're just gonna pass along the empty email, empty name and so on. And then when we submit it, we want to do something different. So we're gonna have a totally different function if you're doing something like this. Like if request dot method is GET do something, else do, If it's POST, do something else. No, that's doing it wrong. You want separate functions because their job is entirely different. One is to create the form. Another is to create the user and then send them on their way. So this one is going to be our POST. Now let's just do a print really quick. We'll say print "GET REGISTER", and "POST REGISTER" just to see that these are happening because you won't really be able to tell until we do a little more work. So let's just make sure. Here we've got that form. We're doing our GET register. I'm gonna fill it out. Register. Reloaded the form because we haven't changed anything about where it goes, but notice that's the POST. So that's the GET > POST > Redirect pattern. And what we're gonna do is we're gonna need to do a little bit of work This is where it's gonna get interesting. A little bit of work to grab the data from FastAPI, to pass it over to the view model, to validate it, to make sure everything is looking the way it should be. And then, if everything is good, we're gonna actually send them over to their, /account details view up here. If it doesn't work, we want to just tell them it didn't work, here's why. Please try again. But a lot of work to do here, but we've implemented to GET, POST almost Redirect pattern. We're going to do the Redirect later, but here's how we handle the GET and POST submission of the form.
|
|
|
transcript
|
7:09 |
So we've got the GET > POST part of our GET > POST > Redirect pattern in place, and we no longer need those little prints to see it in action. Now, there is another thing that we need to do here. We need to work with the data that's being passed back into this form here. So what's happening in this part is we're creating the blank data to pass along to just create the empty field. But we need to accept the data that's being passed over to it from this template through FastAPI. So give it something, say load from this form. In fact, we don't have to even pass this over, we're gonna be able to get this from the request itself. So let's go ahead and add this function. Now, why is there this separate thing? Why is this extra one? Because if we just grab the form right here and and check, it's going to be empty for the name in the GET version, but it's not gonna be empty in the POST version. It needs to be empty in the GET, it cannot be empty in the POST, right? So we wanna have different behavior and this, this allows us to say, like, OK, here's the kind of get it loaded up, GET version. And here's what we do in the POST. So this is gonna be interesting. What we need to do is going to say the form which is gonna effectively be like a dictionary is gonna go to the request, and we just say form() like this. Seems good, right? But if we say form dot notice the stuff that PyCharm is showing us coroutine, coroutine, coroutine, coroutine, awaitable, awaitable object. So what this is, when we do this form read here, there's a couple of things that are happening, and one is that this is an asynchronous read. It could be some kind of blocking thing, like maybe it requires that it's submitting like an image as part of the form POST, a multipart form POST or something. It's, it's reading the stream, so we want to make sure we don't block during that. So in order to do that, we're going to get to one of the very exciting features, our first chance to touch it, and we're going to dive deep into this on the database side, it's we're gonna use async and await. So to convert this task, this potential result to an actual thing, but allow other work to happen at the same time. We have to say, await that. And now if we go to form, you can see we have a multi dict form data type of object with keys and items and dictionary stuff. But in order to use await, we have to have an asynchronous function up here, and in order to do anything useful with our asynchronous function. Maybe if I left it like this, what you would see, you would see that there's a there would be something like, this was not awaited, or something like that at the end of your code. If you see an error like that, that means you forgot an "await" somewhere, and we need it there. And again, in order to call this here, we need to make this in an async function. And here's where it gets awesome, FastAPI automatically supports both synchronous and asynchronous view methods. So this is no problem. We don't have to do anything else. We don't have to choose a different server or a different way to run FastAPI. There's one reason, Uvicorn, as the primary server for it, all of this stuff just automatically adapts. But once we're down here and we start down this path, we've got to cascade the asyncs back up. OK, so we've got that done. Let's go ahead and get these things, the password and the email. The other thing we need to do here, though, is we need to check, we need to check that these values are set properly, so we'll say, if not self.name. Now we could put validation, and we will put validation in the form that says the name is required, but there's nothing that forces the browser to follow it. If you're using it normally, of course, Chrome or Firefox will say this form field is required. But if, what if you just grab something like requests and do a POST against this to see what's gonna happen? Well, none of that validation is gonna happen, so we have to make sure we re do that here. So if name, there's no name or not self.name.strip() like a space or tab won't do it. I'm gonna say self.error equals the name, your name. And we're going to do something like very, very similar to this for the others. That did not work out as smooth as I hope it did. There we go. elif email, your email is required. And then we could do password. Let's change this a little bit, say, or the length of the password is too short. Fewer than five characters say: "Your password is required and must be at least 5 characters" I think we might be ready. This is the processing and validation side of our form, and we could do could, we could grab that age and say we want to convert that to a integer, and if it's not an integer, it has to be an integer. We'll see some other stuff that we could do around that as well. But I'm just gonna leave it like this for now. So now the next question is, did that work? We'll say, if, how do we know? Well, one way is that there is now an error contained in the view model We could also have this return, you know, return False right if we want. But I'll just check whether or not there's an error. So if there is an error, we want to do exactly this right here. Otherwise I'll just do a print really quick. "TODO: Redirect" because this is, it takes a little bit of juggling here. So we're gonna do that in the next video, and I'll just print this out, like so. Just return it back again one more time and we'll change this last line. So what we're gonna do is, it's gonna come in, submit the data. We're gonna load it up, grab the form asynchronously read it, validate it, store the data. If things are not good, instead of just returning, we want to return the data they submitted back to them to reload that form with what they've typed. So if you say your email is wrong, we'll leave the one they typed wrongly there so they can make adjustments to it rather than make them fill out the form from scratch. Give this a shot, see what we get. So if we come over here and we click on register and if I just submit nothing, I'm gonna put something there really quick. Submit nothing. Oh, something has gone wrong here. What has happened? Yes, I meant to mention this earlier. When you work with forms, just like when you work with templates or you work with static files, there's other dependencies you need. And when we work with forms, this Python-multipart package is required. Well, let's go install that. Then I think our form will actually be ready to go. Install this, there we go. Give it one more try, resubmit it. Look at that, "Your name is required". How awesome is that? So now if I put my name and I try to submit it, "Your email is required". OK, put my email, password, now great, let's put the letter "a". Nope, must be 5, 5 "a". 1, 2, 3, 4, 5. All right, here we go. It worked, the only one way we know that worked is one, we saw the "TODO: Redirect" here. The other is the error message went away. Super cool, right? So if we didn't resubmit that dictionary right here, every time the form would empty itself. But we're reloading the form every time with whatever they passed in. So in case this was missing, it's going to say, it keeps the Michael and the password and it just says, just put your pass, your email back. Really, really sweet way to do this. GET > POST, almost redirect pattern. Virtual redirect. Here, looks like we got it working.
|
|
|
transcript
|
3:39 |
Well, we've got our form taking the data and validating it, but it just stays right here. So there's a couple of things we still need to do to make this work. One is we need to go over here and say TODO:, Create the account, and let's go and write some code to do it and then we'll make this actually happen when we get to the database. This is gonna be the user_service, and we'll say create_account() and we need to pass all that information over. So view model is going to have the name, the email and the password. That's going to create an account and we probably also want to say TODO: Login user, which we still got to get to in a moment, do that. And then we want to do the redirect, right? We're still kind of focused on this GET > POST > Redirect and this the last step in that. Let's go ahead and write that function real quick so it doesn't crash, it's just gonna be strings and it's gonna return one of those users, one of these classes, and we'll just have it return the user like this for a minute name, email, "abc". We've gotta hash the password, not for the moment, but we'll get back to that. OK, So we're gonna log in our user and then we want to redirect. Now, remember we talked briefly about FastAPI responses, responses there. There's a bunch of great stuff, we started out by saying, oh, there's this regular response and the JSON response, and let's use an HTML response for a minute. You can see these actually come out of Starlette, not FastAPI directly. So we've got a perfect candidate for our redirect. We're gonna return a RedirectResponse, and what could we put in there? the url, the url is going to be equal to /account. Let's give this a shot and see what happens. All right, come over here. We're going to submit this form, it's gonna fake out creating that account, and then it's gonna redirect to /account. But it's not gonna work the way you're expecting. You probably think we'll just see the account page shown here. But let's see what happens. Method not allowed. Wait a minute, what just happened? what just happened? Look at this, it did an HTTP POST when we did the redirect from /register it redirected as a POST. Most frameworks automatically convert redirects to GET, FastAPI and Starlette do not. So no problem, what we can do is, we can go over here and we can actually import status. We can set the status_code equal to status, and this is going to come out of Starlette. And here we have all the HTTP statuses and the one we want is 302 Found, and that means redirect with a GET. Right, one more time. Go back here, try to submit my form. Should see it, redirect, and off it goes. Tada! there we go. And we've got the correct redirect instead of one of those 307 or whatever it was there. 302 Found when I did the POST to register and then it did the GET to the account. So GET > POST > Redirect. Perfect, so now we've got this working and you can imagine something very, very similar for login, right? We're gonna create a GET version, a POST version. The view model is gonna load the data out of the form, validate it, do some stuff like log in the user, make sure their account exists, log them in and then do a redirect, probably over to the same place as well. So this pattern will serve us for most of the HTML forms that we wanna work with.
|
|
|
transcript
|
3:56 |
Let's talk a little tiny bit more about validation. We saw that we're getting lots of validation in this section here on the server side, but a better experience for the user would just to be have the form as they type, give them a little feedback. Like hey, you know what? Your password has to be five characters before you hit submit, your email field has to be an email, not just some random text, those kinds of things. So in order to let you see the server side validation, I turned off the client side validation. You might have noticed it was here actually before, but what we're gonna do is we're gonna do a couple of things just in HTML to make this a little bit better. So let's just check, for example, if we go register. I try to register, it's posting back, and if I go Michael and it's really quick, so it's not a horrible experience, but if I go and type this, oh it's required. How about that? No. Still no. And it would be nice if it would give us information like if I just type this, it would say: oh, you know, that's not a real email, you gotta do better than that. So let's make just a couple of little changes. I already pointed out that you can't rely on this to validate all your data. Somebody could entirely skip this and just use Requests or something like that to jam data straight at your server. So you gotta have service side validation, always. But you can make the experience nicer. Like I can come over here and say, in this section here, that this is required, right? So all these fields that are required, we just say they're required and all we've gotta do is put an empty attribute They don't have a "values" or anything like that. And then, we try again. We refresh, without a POST. We just try to submit it, notice all the things are in red, it says this one is required, put stuff in there and you see the red goes away as I work with it. Really nice experience, right? OK, so that's great. Let's put in the letter "a", gotta put a number into this one now, password's required. Now we went back to the server, but we can do more. Let's have another look, what else could we do? Well, did it let me type in junk for the email? It did. That's because we said is this is the "text" type, but it also, there's many other types, like email, months, numbers and so on. So if we say that this is an email, and this age. You know, the age is already number so that's good. So it'll make sure it is a number. We'll be in better shape here. Actually, that's not. Submit it again. So if I say my name is Michael and I just put Michael here and the password is "a", notice, it's trying to, trying to suggest something. What is the problem here? Yeah, I don't know if I can get it to show you but it says this must be an email. So if I put some, oh there we go! Perfect, finally got it to come out. So if we go and put that in there, it'll now the red goes away. This must be a number, so I'll say that. And this one, it tried to submit it back. We can do more. Still with this one, we could say at the client side, this must be five characters. Over in the password we can say minlength has to be five. That's good. And then also, while we're at it, let's say that you have to be 18, at least to register. So what we can go over here and say that the minimum for this is 18 and let's go and set a max so it's a reasonable age, 120 or something like that. All right, let's go look at this again. All right, gotta fill out our name. Sure, we can do that. With the letter "m", "a". Nope, it's gotta be an email address, email address. Okay, it is. The password, my favorite, the letter "a". You're currently using one character. OK, That's right. It's five a's and then down here, it says your age has to be a number. but watch if I hit up arrow. Remember? It did 1, now does 18. If I hold it down, he goes up to 120 and if I say 121, no, no, it's too big. Let's go 40 or something reasonable. Now we can register. We got a chance. That's the first pass of all this validation right on the client side, users get a little better feedback as they're working on it. And then off it goes. We've registered, redirected over to the account, tada! we've got our form working really, really well.
|
|
|
transcript
|
5:50 |
Got a little bit more work to do here, and I guess we could take away the TODO on this one. But now we're gonna need to log in the user. How are we gonna do that? Let's go and create a special class that manages putting the user information into cookies and getting it back out of cookies, checking what is there and so on. Because we'll see there's a naive way we could do pretty quickly inline here and a more complex way, that works a lot better. So let's go create a new category of code called infrastructure. This is like stuff that helps out the rest of the site. Little utilities like converting integers or pulling out cookies or stuff like that. And I'm gonna call this thing, we're creating cookie_auth. What we're gonna do is we're gonna take two passes at this. I'm gonna show you a simple version that has a problem and then a more interesting version that we're just gonna drop in here and review that's like this, but better. So we're gonna have to functions here. One I'm gonna call set_auth and it's gonna take a user_id and all it's gonna do, it also needs a response, which is a Response from Starlette, and this is gonna be an integer. Then we have another one called get user id from cookie, from auth cookie. And I think this is gonna need a request. Same one that we've been working with the whole time, from Starlette. And we don't pass in the user_id because we don't know, we don't have it yet. That's what we're doing here. It's gonna be Optional integer from typing, perfect. So let's go over here and use this cookie_auth, so cookie_auth and I need to pass it this before we send it along. So there's a response. Here's our redirect. And then we need to say set this cookie here before we send it along. So the response is gonna go there, and the user_id, we'll say account.id, doesn't have an id yet, but we will go and update our class to have one. So do that real quick. Let's say it's always 1, until we get to the database where it'll autoincrement. Alright, so I'm gonna pass that along and then it's gonna be really simple. All we gotta do is go to the response and say, and our first pass is gonna be simple. At least set_cookie, the key, let's make sure we always use the same key. So, like the name of the value in the cookie dictionary, this will be auth_key. It's gonna be, let's say, 'pypi_account' like that. So the name is gonna be that, the value that we wanna pass in is the string of the user_id, the max_age. Ah, we don't need to set the max_age, there are a couple of settings we do wanna set though, we want to set secure, and we're not going to set it here, I'm gonna say False. But in your real web app, when you're running in production, you wanna set this to be True so that if somebody types your domain without using HTTPS, it won't still exchange the cookies over HTTP, where people could eventually watch it. But I'm gonna say False in development because we don't have SSL set up in development. And then httponly, this means that JavaScript code cannot read the cookie. It'll exchange it, but it can't read it. So I'm gonna say True and samesite being "lax", that's good. All right, I think we're in good shape with this. And then over here, we wanna read it back. We wanna take our request. I'll say, if auth_cookie not in request.cookies, then we'll return None, there's no value here. And let's, for now, just say we're gonna directly store this as a string, so we'll say user_id equals, notice it's dictionary-like so the way we access it is auth_key like this. Then we need to convert this to an integer like so and return it. Right, so what we're gonna do up here, we're gonna call this, which we are. And then let's go and actually make our view model Do the magic that it was supposed to do all along. Remember we said you're logged in, yes or no. Let's go like this, Let's say cookie_auth, get user_id from cookie self.request so the request is passed in. All right, and if that comes back with something, well, we should be logged in. If it doesn't come back with anything, we won't be logged in. Let's go ahead and give this a test and see how well we've done. But first of all, notice we're not logged in, so this "Login" and "Register" are set, that's a good idea, a good sign. Let's go over here and register with all the info that I put in. Oh, yeah. I need my five a's and let's just put anything there. So this works, it should set a cookie. Let's go over here and see if we can get it to show us while we're at it. It should set a cookie, then redirect us to the account page. The account page, all the pages, will look and see if there is a login cookie and should switch this to "Account" and "Logout". If it doesn't do that, we got something wrong. Let's see how this works. Off it goes, yes, perfect. So check this out, "Account" and "Logout" are now set over here. And here we go. We've got our account information there, if we go and look at this you can see set-cookie pypi_account, is id equals 1, HttpOnly, Path is what it is, SameSite is "lax", like we described. Then when we did a GET over here, the response had over here in the cookies, had that pypi_account is one. I think we've got this working. We've got our cookie set up. At least in this naive way, we just have that stored in a cookie. And if it's set, then we're logged in. We pull back that user_id, if it's not set, hey, we must not be logged in.
|
|
|
transcript
|
3:26 |
Let's have a look at our cookie_auth one more time. So this looked great, right? We saw that we're storing our account id in the cookie. And if we submit that cookie, then everything's golden. What happens if we were to try to play with that? What if we were to go find the cookie on our disk? Or we were to do some sort of POST where we set a cookie? We noticed well, if it was 1, what if it were 2? what if it were 100? Could we be other users? How about that? That'd be cool. In general, more broadly, the problem is, what if people tamper with the cookie? What if they make changes to the cookie? How do we know? we wouldn't know. I mean, as long as it was valid data, it's a valid user, it'll look like that user logged in. So what I'm gonna do is drop something in there that takes the data and then creates a hash of the data. When we get it back, we'll be able to say, here's what they gave us. Here's what it should look like if we were to scramble it up, do they match? Right, so we're going to store both, the value and the scrambled version, which they won't know how to recreate because of the way we've generated it. And that'll give us a tamper proof digest type of thing. So I'm going to just drop that in here, and now we've got a slightly more complicated version. So let me just walk you through. It's basically the same thing. So when we get a user_id passed over, instead of just sticking the user_id directly, we're going to hash this user_id in a certain way that's hard to recreate and put the user_id here. So if somebody gets hold of the cookie, they see the number one and some giant scrambled thing. That way they'll not be able to look at it and say, Oh, I can just tweak this because if they tweak it, they'll have to adjust the hash, the match to be the same. So we're gonna create a sort of a combo here, and then when we get the cookie, we're gonna pull it apart and we're gonna check two things, give us the value and the hash value, and do those match as we would expect? They don't, we get nope, there's no user here. Otherwise we're gonna convert it to an integer. OK, To hash it, what we're gonna do is a simple sha512, but we're also going to apply some salt at the beginning and the end. So instead of just hashing the number two, we're gonna hash "salty__", two underscore, "__text". Looking at the value, you would never know that that's what you need to hash. So it provides a small level of safety, not huge, but it does help us here. OK, So what we're gonna do is we're gonna try this again. I'll that "pypi_account". All right. So make sure I named everything correctly. No, I didn't. Let's see, get_user_via_auth_cookie, there we go. That's what I dropped in there had the name of and then over in account. Looks like this is working, so let's run it. We should not be logged in when we first get there. We're not, go register. Takes five a's and an up arrow and we should be able to register. Off it goes, perfect. Now we're logged in, and let's look at the thing we exchanged this time around Network, HTTP, go anywhere and we should be able to see our cookies getting sent back. Here we go, now check that out. We got the "1:" and then that huge blob of stuff, Right? That is the verification that if we were to try to change that, which guess what? Go ahead and make changes to it. If we want, we're not gonna be able to change it, right? If we put a 2 there, we would have to know what that huge thing on the end that corresponds to the new hash. So it'll make it much more tamper proof. And that way people won't be able to go randomly, change stuff around and cause problems with our site.
|
|
|
transcript
|
1:23 |
Let's take this whole experience full circle and add the ability to log out. So we're able to register, then we're logged in. How do we thought being logged in? How do we do this logout? Well, it turns out it's incredibly simple. So when we logged in, what we did is we created this response and then we set some cookie. So here, when when you do a GET, it's just going to do the opposite of that. So we're gonna come along and grab this. It's quite similar. And instead of sending them to their account, which doesn't make sense because they're not logged in, let's just send them back to the home page. And we're gonna again use the 302 so we don't do a POST, we do a GET. And over here, this actually has a logout where you just pass in the response. If you look at that, it's incredibly simple. It just goes to response, delete cookie, the name of whatever we called the cookie. Let's go ahead and try to rerun this, see if we can now log out. We click here, we're still logged in, we still have the cookie, we go to uvicorn, we're still logged in got to account. But now, if I hit log out, it should delete that cookie and send us home. Let's see if we got it right. Boom! Cookies deleted, logged in info is gone. And now we're back home where we're meant to be. Right? That's it. So we've got our GET > POST > Redirect pattern. Think in the form, submitting it, once we're registered, and validated, we create the account, we set the cookie, hangs around for a while until we log out and then it's gone.
|
|
|
transcript
|
3:11 |
Because login and register are so super similar but require a lot of juggling of little pieces, I'm just going to drop this little bit of code in here and let's review it and add the final pieces. So just like register, we're going to have a GET version and we're gonna have a POST version and then do a redirect. In the GET version, We're gonna have our LoginViewModel, and then it's just gonna return the empty form. Let's look at that really quick. It's gonna have an email and a password, as you can imagine, along with the base error message that might be sent over, like you couldn't log in or wrong password or something. And we're gonna do a load in our POST back to get that from the form, just like we did before. Over here, we create it, and this time we await a load, which means it has to be async up here. This one doesn't actually have to be async, I guess, because we're not doing async stuff. And we check for errors. If there are, we reload the form with the same data, show the error. We're going to need to write a login_user, given the email and plain text password they submitted. If it didn't work, then sorry we couldn't get that account. Either it didn't exist or the password doesn't work, match or something. You want to do a redirect with 302, set the auth cookie just like we did before, and send that response back. One thing we could do real quick here is we can create this function, it's going to return an Optional of User like so, like that. Now, the test we're gonna do this first time around is really, really simple. So remember, we passed in an email and the password, which is 'abc', that we stored? So let's just check against that. When we get to the database section we're gonna actually store the hashed password in a really cool way. But let's just go and add a simple test. We'll say if password equal equal, let's say "abc", then we'll return some basic user like this. The email's what they passed in and the name will be "test_user" or maybe that, more friendly name like that. Otherwise, what we're gonna do is return None, because that didn't match, right? Either we didn't find it out of the database or they typed it in wrong. Let's go just run through this experience real quick to make sure our login works in a simple way. So here we are, we're not logged in currently. We're gonna log in, the password, the password is gonna be "ab", which is not "abc". So this should not let us in. "The account does not exist or the password is wrong." Oh, let me try that password again. That's right, it was "abc". Now it should set that cookie log us in, redirect us to our account page, and the navigation up here should say "Account" and "Logout". Boom! just like that, it does. Really, really similar to the registration stuff, but we try to find the account instead of trying to create the account. Go log out and we're back logged out. So we have all of our account management stuff besides actually saving the users in the database, which is the next chapter. But we've got all the general HTML view, view, model flow and validation of account management and HTML forms completely dialed
|
|
|
|
1:01:13 |
|
|
transcript
|
2:14 |
It is high time that we start working with a proper database. There's been way too many times that I've had to say: "And we'll actually create users and save them when we have a database, we'll actually pull real package information, when we have a database." So that's what this chapter is about. Were gonna put that database and that data access layer together with SQLAlchemy. Now, notice it's not just databases with SQLAlchemy, this is "Databases with SQLAlchemy Sync Edition" as in synchronous, not asynchronous. We're gonna talk about SQLAlchemy in two passes. First, what I believe to be the familiar and common way of working with SQLAlchemy. And then we're gonna come back and work with a new A P I that they're working with in a beta mode, it's not even fully released yet. Why are we doing this? We're doing this because the traditional way of working with SQLAlchemy in no way supports asynchronous programming. And one of the massive, massive benefits of FastAPI is it's natural and easy use of async and await. If you want your application to scale massively, you need to make sure your data access layer allows you to write asynchronous code. So every single time that you're waiting on the database, your web server's processing more requests instead of just blocking. So in order to make that happen, we need to use the asynchronous version. But that's in beta mode, and I don't think a lot of people have really any experience with this new and not compatible way of writing. This is why I pushed the database section further back in the course, because we have this sort of complication of like we're working with two APIs, one of them is under beta. It's not a big deal, but I didn't wanna throw all that complexity, as it doesn't really have that much to do with FastAPI directly, at you before you've seen most of what we're doing with the web framework. So that said, we're gonna in this chapter build out the traditional synchronous version and then we're gonna convert that to the new asynchronous API. The reason I'm doing it that way is cause I think most people are familiar with this style of SQLAlchemy and the new style of SQLAlchemy will be uncommon, unfamiliar with people. So I want to give you a first past where you're like "Oh yeah, I see what's happening, I know what's going on" and then we can come to terms with the slightly different async style of working. Let's get to it.
|
|
|
transcript
|
2:05 |
When I introduced this chapter, I said, you're familiar with this SQLAlchemy API and we're going to start that way. Well, what if you aren't familiar with it? What if you need to learn SQLAlchemy? Maybe you're brand new to databases. Well, there's a couple of things you can do. One, you can just sit back and let it wash over you and kind of get an appreciation and some initial exposure to what we're doing. Or if you want to make sure you dive in, you wanna do a little extra work, I'm going to actually put an appendix that you can go study first, before we jump in to actually writing the code. If you look over on the Talk Python Training site, we have a class called "Building Data-Driven Web Apps with Flask and SQLAlchemy". In this course, we built PyPI from scratch but way, way deeper into the web design, the web development foundations across everything. Remember, this is about teaching you how to do that kind of stuff with FastAPI, not how to teach you how to do it from absolute no understanding, which is kind of what this course does. And if you look down here, you can see we've got chapter 9 and 10, "Modeling data with SQLAlchemy classes" and then doing basically queries, inserts and updates with SQLAlchemy as chapter 10. It's almost two hours of content, I'm going to take those two chapters and put them into appendices at the end of the course. If you're really wanting to go slow and take everything in and SQLAlchemy this is your first exposure to it. Then go ahead and watch those two appendices, those two chapters. Not only will they teach you SQLAlchemy in the context of web development, they will teach you SQLAlchemy building PyPI. So, in fact, the data model is identical. So in this course we built pypi.org from scratch, using much of the same constructs. And over here, when we talk about SQLAlchemy, we're talking about the same thing users, packages, releases and so on. So you'll get a really good foundation for what we're gonna do with SQLAlchemy over here if you'd like to spend an extra couple hours digging into the foundations. If you're familiar with it, you probably don't need to do this, but if your brand new, your time is probably well spent over here going through the two appendices before we go further.
|
|
|
transcript
|
4:06 |
Before we start writing code. Let's just take a really quick look at some of the differences of the current SQLAlchemy and where we're going and you'll see how we're gonna write code now and then in the next chapter, we're gonna write it against the new API in just a little bit of detail. Here we are at SQLAlchemy. There's currently a 1.4.0b1 released about two months ago, and this is the culmination of about 18 months of work. And the main goal of this is to bring a new API, which will be introduced maybe exclusively in SQLAlchemy 2.0. So when we get to 2.0, we'll have to switch to this new API. Let's just really quickly look at the announcements here. So it says this is the first beta release of the SQLAlchemy 1.4 series. It's the culmination of 18 months of effort to envision and create a modernized, newly modernized and capable SQLAlchemy. The first step along the way to SQLAlchemy 2.0, and includes a gradual introduction to the simplified way of working with, most importantly, the ORM So if you just look at some of the changes, there's a simple and more consistent way to work with transactions. There's this select() construct that gets used now heavily in the ORM where it used to be you would just go create a query and I believe the select stuff was more in the "core", if you wanted to do direct queries some caching, which sounds amazing. Here's why we're having this conversation, why this is valuable. This is the first version of SQLAlchemy to provide support for a asyncio, meaning async and await and direct integration with FastAPI. So that's gonna be super, super awesome, that we can use the ORM with async and await to get massively scalable applications all the way down to the database. OK, so that's what the goal here is. We're gonna go through and create everything in a familiar way, and then we're gonna make just some changes, really only to the queries that we write, it won't be that big of a deal, but you know there it is. Let me just show you what some of those differences look like. So if you go back here to the home page, real quick, just to give you guys some guidance here, there's this releases. Oh, look, there's migration notes and there's a big, long document about it. But if you look, there's another migrating to SQLAlchemy, which is not those migration notes. It's a totally different one. You can see the URL appear at the top. Anyway if you, it's really if you look at the scroll bar, it's quite a large document. If you go down, now what is that? About 70% of the way down. It talks about the biggest change in SQLAlchemy 2.0 will be the use of Session.execute(). Instead of using query, you're going to create select statements and then execute them. What's nice is down here we have a couple of examples that we could use. So traditionally, you would write something like, I want to get all the users, session.query(User).all(), now you write this, you execute a select statement on the user where you get the scalars and then you call all(). Down here you wanna do a filter. So give me the users, so session.query(User) where the name equals "some user", give me the first one. Now you'd write, you would execute the statement, select user, filter by name, scalar_one(), ok? You notice that this one applies to the query, whereas here, your select and your query is one thing and then you execute it against the result of the execution. So there's a little bit of difference going on here. So you can just scroll through this and see that these APIs are not even close to similar. Maybe there's some parts that are similar, but to me, they feel fairly different. Like all() is now scalars().all(). When you do a join, you have to do a unique() on it. So there's just a lot of stuff that is really not directly transferrable. You know, it's not necessarily obvious that that's the adjusted thing. So what we're gonna do is we're gonna create this, this version that I believe most people who work with the ORM of SQLAlchemy totally have down pat. And then we're going to rewrite the queries in this, not the classes, just the queries, and make those asynchronous which is gonna be so worth it. And we're gonna do that in these two chapters. Here's the documents that you might wanna look at. So we've got, you know, https://docs.sqlalchemy.org/en/14/changelog/migration_20.html. All right, and there you can find this comparison doc. It's about time to write some code, don't you think?
|
|
|
transcript
|
9:19 |
Welcome to chapter seven databases. Copy over the final result from Chapter 6 to 7, set it up as a new project and open it here so you'll have what we finished with in 6 as well as what we're doing. Here we go. Let's open it up and get going. First thing we need to do when we work with SQLAlchemy is create this thing that will create what are called sessions or units of work. In order to do that, we've got to create an engine which binds to a database connection string. There's all that kind of initial set up. We want to create the table structure based on the classes, and that's done through common couple of lines of code that always gets done once, and exactly once, only once at startup for the application. You've probably seen SQLAlchemy before or you've watched the appendix series that we talked about that, that does this. So let's go over here. I'm gonna create a class. Really, I'm gonna create a module, excuse me, db and call it db_session and in here I already have some code. I want to just walk you through because it's really not super valuable for us to take the time to go through all the details here. And if you're familiar with SQLAlchemy, you'll know it. We don't have SQLAlchemy set up as a dependency yet. PyCharm will actually do that for us. It says, you want to install that? Yes, please do. And then, once that's installed, it will say, you know, you really should add that to the requirements. And I'm gonna say give me a compatible version. What I've done so far with, I'm going to say, give me the exact version, actually. What I've done so far is just left the dependencies and versions open. That's usually the best, you'll get the latest. But with this 1.0 - 2.0 difference, I'm gonna be really careful. So what we're gonna do is, I'm gonna pin it to this exact version. You can put it on, whatever the latest version that works when you get a hold of it. But for now, I want to make sure if you check it out and run it, it's gonna work now. And what we're gonna need to do is put 1.4.* something, 1.4.* something, or higher when we get to the next section to enable the async and await features as well. So, here we are. We've got that specified and saved, so it's easy to get this back. All right, so there's one other thing that we're gonna need in order to work with the ORM, and it's we're gonna need to define a class called whatever you want. But I'm gonna call mine SqlAlchemyBase and we're gonna put it into a module called modelbase. Let's do that first and we'll talk through this file here. So I'll call it this, and we'll say import sqlalchemy.ext.declarative and we'll come down here and I will say this is gonna be just call declarative_base() and that's it. That's all we gotta do. We just need this dynamically created base class to exist. And actually, you can create multiple ones and associate different connection strings and databases with every class that derives from this. So now we've got that in place. Let's talk through this. So what we need to do is at the beginning, we're gonna use SQLite and SQLite takes basically just a file as a connection string. If you had PostgreSQL or Microsoft SQL Server or whatever else you want to use, they have their own way of writing a connection string. For us, we're gonna use SQLite, so we're gonna specify just a file. We're gonna check that If we've already done the set up, not gonna run a second time, it'll make sure that there is a file, it doesn't have to exist. SQlAlchemy and SQLite will actually create the file if it doesn't exist. But one thing that we do want to make sure is the folder structure where you specify it does. So down here you can see mkdir, I'm using this pathlib thing say create the parents and it's fine if it exists. Going to say "sqlite:///", file name. That's the SQLAlchemy connection String for SQLite. Then just shoot out a quick note about what's happening here. Then, we're gonna, we're gonna go and create an engine with that connection string. If you want to see every command that goes to the database, set that to True, it's super chatty, but it does give you a good sense of what's happening and then SQLite has, sometimes complaints about threading, but it's also thread safe, so we can just tell it not to complain to us. And then what we're gonna do is create this thing called a factory and that job is to create these units of work or this sessions, as you can see down here, it's we just call this function, creates one of these by calling it, this is a handy little thing that makes working with fields after you've saved them easier and then we're gonna return it. OK, The last thing to do is we need to make sure that SQLAlchemy, the base class has seen everything that derives from it. And the way that we're gonna do that is, we're gonna go over here and create a file like this, and there we'll say from data.package import Package and data.user import User and release as well. These are not SQLAlchemy classes yet, but you know what? They're gonna be really soon. So let's get this in place. Now, PyCharm is usually super, super helpful here, it says, look, you're not using that. If you wanna go over here, you could Alt, Alt + Enter and it would go away because you're not using it. But in fact, we do wanna have this exist for this particular file only because the whole point is just to do an import. And that's enough to trigger what we need for this base class to see that it derives from those various other classes, as it will shortly. And then finally, we call create_all on the engine, and it's gonna go create the database for all the tables that don't yet exist but have classes. It will create those, it won't make updates to them, so be aware of that. But it'll create all the tables in this db_file that we're going to have here. All we gotta do now is make sure that we call this and it should get our database all set up and ready to go. Remember, this gets called once and only once. Hence the global_init not all_the_time_init. Let's go down here and add another thing to our config. See these start to grow, those will be configure_db and what we need to do here is we need to come up with a file name or for the SQLAlchemy db_file. So what I want it to look like is I want it to be in the working directory, then db then pypi.sqlite like that, and an easy way to get a hold of that is we can go to the main file, Path, we'll import that from pathlib and we say it's the current file, so that's the full path to main. And then from here we can say, parent, that will give us this directory and then we can say "/". It's kind of funny, they override the divide operator to look like path concatenation, but it works. Then we can say pypi.sqlite like so. And then all we've got to say is file equals that, and that should be what we get, what we want here. And we also want to have the absolute path. I guess we could, do I need to do it like this? I'm not sure, whether I'd rather do it in a second line or do it like this, but that'll give us the absolute path. And let's just print file for a second. OK, make sure we call over here configure_db(dev_mode). We don't really need to use the dev_mode here, but let's go and make it available. We could do things like turn on the SQL tracing or turn it off. Let's go and run this and just see we've got the file working. And here's the path that it found. So here you see we have courses/fastapi/fastapi-apps/code/ch7... and I got the full user name there, chapter seven, then db,/pypi.sqlite, perfect. That is what we wanted. So instead of printing out, let's go ahead and call it. We'll say db_session and let PyCharm import that and then just say global_init(file). And over here, in a moment, we should be able to see a db folder created. If I got everything right, let's find out. Look at that. I always forget this when I'm working with this Posix pathlib objects. When we called this, we got a path object, when we called this, we got a path object. When we did this division combination thing, we got a path of object and so on. All the way to this file, it's still not a string, it's a pathlib object. So to actually get it as a string, there's two things we could do. We could say str() of it like that or we could come over and say as_posix() and that will print out, that'll give us just the string representation. The problem was global_init tried to call strip. If there is white space, maybe we read it from a config file, there's like white space at the end, or some weird thing like that, wants to guard against that. But it can't do that to a PosixPath, It can only do it to a string. So let's try it one more time. Oh it worked. OK, that's good. And look what we printed out: connecting to the database with. Here's our scheme that we need to use for SQLAlchemy. I noticed it looks like there's one too many slashes there, but there's not. The thing that we're passing here is just the full absolute path. So triple slash and then the path just happens to be that also has a forward slash. So it looks like we've got this set up correctly. If we go over here, we say reload from disk. We now have a db folder with a little SQLite database in it. It does not yet have any tables because the classes we've created are not actually SQLAlchemy classes yet. Once we create them, then that whole process will actually create additional tables. Right now, it's just an empty database, but still, that's pretty cool.
|
|
|
transcript
|
7:19 |
Now the next thing that we need to do is start creating some of these classes and we kind of went down this path a little bit already. Remember, I said, it's really tricky to pass the right data with the right, you know, properties and cascading properties and whatnot that we need to the package page and so on without just creating some classes. You know, all the time knowing that we're kind of headed towards the SQLAlchemy path, which is done with the ORM and classes anyway. So let's go and upgrade this class to be something that gets automatically queried and serialized out of the database rather than just an in memory class. So we're gonna use our SqlAlchemyBase. We'll just do it here like this, SqlAlchemyBase double Ctrl, double Ctrl + Space and we get all that magic happening. Now It's a SQLAlchemy table. Well, sort of. It doesn't have any columns yet. This is not quite the way you do that there. So let's do one thing before you forget. I want to set the __tablename__, something that bugs me about these things. Tables contain more than one thing, so calling it user to me seems weird. Should be "users", and capital, I don't dig that. So let's call this "users", lower case. I'll tell Pycharm. Now this is cool, you can have tablename all day long. It's not misspelled. Then let's add these fields, which are going to be columns. We're gonna have an id, which is a SQLAlchemy column. And one of the nice ways you can do this is, you can so, import sqlalchemy as sa. You can have a little bit shorter, something to write here, sa.column, whoops, capital Column. And then we have to specify the type, and this is gonna be an sa.Integer. Now, not just any integer, but this is gonna be the primary key, and it's gonna automatically update itself, increment itself on the database so we'll set two things primary_key is True, and autoincrement is True. So this should also create an index for us, we shouldn't have to have an index explicitly here cause it's a primary key. Next we've got name, which is an SQLAlchemy column of type sa.String. Let's just put the type information in here for now and we'll have an email, which is the same. We'll have a hashed_password, which is the same. We'll have a created_date and that is not a string that is a sa.DateTime. We'll have a profile_image_url, which is now back to the sa.String. Now all these done. And we've got our last_login, which is gonna be one of this, last_login. OK, super. Now, let's make this a little bit nicer to work with. A couple of things, how often do we want to be able to query a user by email? Well, when they log in with their email, very, very often. So let's go over here and say index=True. Also, if they log in and they say forget their password, we wanna let them press a button and reset their password. So we need their email to also be unique. So we come down here and say this must be unique=True. We can't have different accounts with the same email, that would just be weird, password, no index or anything like that. create_date, this one, when you create the user, we would like SQLAlchemy to automatically just set it to right now. So let's say the default, gotta be really careful here, is gonna be a datetime.datetime.now. That's what I wanna type, if I hit Enter, the parentheses go on there. And that is not what I wanna type. What I want to do is provide the function now, that SQLAlchemy will call. Not now() when the class gets parsed. So for the whole lifetime of the app, it's just when the app started. No, no, no. We do it like this. We can do the same here, the last_login, the very first time is right when they create their account. And then we're gonna have to set this the next time and the next time and the next time. profile_url_image, we don't really need anything on that either. Maybe we want to do queries like, show me the users who were created today. You know, show me all the new users order by descending on created_date or something. For that reason, we're gonna make this much faster if we have an index on those two things. I think that's it. I think that's it. Now, one thing you wanna be careful about is if I run this code, it's gonna create the users table. Once it does that, SQLAlchemy will never make a change to it again. It's like, that exists, we're not gonna break anything. So you want to make sure it's right, or you have to either throw away the database or directly edit it or do a migration or something. So, you know, double check the work. That look good, looks good to me. So let's go and run this and then we'll go inspect the database. Right, It didn't crash. That's a really, really good sign, because it did go through that global_init process. And importantly, it called this right, right here. SqlALchemyBase.metadata.create_all with the engine. And that'll create all the class, it'll take all the classes that derive from SqlAlchemyBase and create their corresponding tables and relationships and foreign keys and so on. We should be able to go look at our SQLite database over here. Let me reload from disk and see if anything changes. Yes, notice the icon changed now that it has an actual structure in it. It knows it's a database, that's super cool. What's not super cool is, I don't think that I can load it up here. Normally in PyCharm I could just drag and drop this over here. But notice there's issues. It's having issues. The reason it's having issues, I believe, is this is actually one of the Apple Silicon M1 Macs that I'm recording on, which is great, super fast, and this is the M1 version of PyCharm as well, the native Apple version. Everything sounds great, except for the SQLAlchemy database drivers don't work with it. So let me go and show you something else that's cool. If you wanna use that way, that's great. That's normally how I would do it in PyCharm. But if for some reason that doesn't work or you don't have PyCharm Pro, let me show you this. So we've got this really cool, nice looking database UI tool called Beekeeper Studio, and Beekeeper Studio is really quite a nice UI. Talks to all these different databases, lets you create different connection strings and basically do autocomplete queries and have a history of them, a history of the queries, explore the schema and so on. So what I'm gonna do is I'm gonna go open up this thing here. I can go SQLite, browse over to it. But you know what? I've already done this so I can just click right here. Click connect and check it out, we've got our users table. We've got an id, which is an integer, and our name and our hash_password, our created_date and so on. Now there's nothing in here, you can see if we go to a query, it's just empty, right? We could come over here and we could say "select * from users where..." You know, what have we got? a name, id, name. Really nice, right? We don't have any users yet, but you can see that it did find the structure of it and let us open that and explore it, which is pretty awesome. So this will be really handy for us to make sure we're getting the right databases created when we work with SQLAlchemy
|
|
|
transcript
|
5:29 |
So we've got our users created and we went real carefully through setting up the indexes and the primary keys and all that kind of stuff. Let's just quickly drop in an existing package and release and talk through it. There's really not a huge value in us spending tons of time working on the data model. So I'm just gonna drop in two files and we're gonna talk through them. All right. And this one is called "release" and this is called "releases". So let's delete that and then call this one "release" just so we get that right and consistent. OK, so releases first, it's a little simpler. Packages, there's one package, and there's many potential releases for each package and the idea is that it's gonna have an id, just like before. And the release is gonna have a major, minor and build version, which is an integer; and each of these air indexed because we might wanna query by, you know, give me this certain version or all the versions above this version. Again, when was the release created. There's a comment on the release, a URL for the release, a size in bytes of the release. And then, it gets interesting because we have a relationship, we have a package_id, which actually represents a foreign key back to "packages.id". So when you create these relationships, you've gotta be really careful. I find myself always just constantly getting tripped up by this. When you say this line, you talk about the package_id and it's relationship, it's key. You speak database terms. The database thing that is related is the lower case, plural, "packages". That's the table name that has a thing id. But then we can also use this relationship to get an object that's lazy loaded through the ORM. When you speak in that thing, you speak in terms of the object that happens to match that table. So here it's capital "P", singular "Package" class. Here it's lower case "p", "packages", the table. Now once you get this down, no problem. But there it is. We're gonna create this foreign key, one-to-many relationship. If you look at package, it's similar but slightly more complicated, id, created_date, last_updated, summary, description, home_page, docs, package_url. All the stuff that we happen to have shown in the package details page, author_name, author_email, the ur..., the license, excuse me, like MIT or whatever. And then, we have this relationship that is really quite an interesting ORM thing right here. So the, this is the one-to-many. One package has many releases. Then we're gonna create a relationship over to the "Release" class and it back populates "package", which is that thing right there. So if I get one, I don't have to do another query to get the other, the reverse relationship. What's interesting is you can do an order by, not just an order by, but an order by composite key. So show me the largest version by first, order by the major version and then the highest minor version and then the highest build version among those. So I think that's pretty unique, you don't see that too often, but really helpful. It'll let us easily get the latest to the oldest releases automatically just by touching this relationship, we don't have to do anything. All right. Moment of truth. Let's see if I put everything together right here and if so, our Beekeeper Studio, when we connect will not just have users, but it'll also have a package and a release. It looks like it might, let's go connect again. Look at that. We have packages, again empty, but we'll fill it up a minute. There's all the interesting elements and the releases right there. Super cool. You can't really see the relationships. I don't know that there's like a visualizer diagram type thing. Maybe there is, I don't know where it is in Beekeeper Studio, there is in PyCharm but sadly, it doesn't work in the version that I have. We've got our database all set up. It just has no data. Wouldn't it be cool if it had some data? Well, we'll get to that in just a moment, but these three classes are now SQLAlchemy classes. Let's just review real quick, ideas. They have to derive from SqlAlchemyBase, the elements get specified as columns and notice one other thing I hadn't, didn't comment on before. Let's just do it for the users. Some editors are smart enough to know. Yes, you said this is a column, but really, really, it says, it's an integer type column, so let's treat it as an integer. And let's treat this one like a string and this one like a datetime. Now, not all the editors are smart enough to do that. So let's go ahead and specify some type information here. We'll say, that's an int and that's a string and so on. That's a string, that's a string. These are datetime.datetime's. So if I come down here and I say "u" equals "User" and I say u.created_date, look at all the datetime stuff, perfect. It knows, right? If I go to "email.", look at all the string stuff, it knows, perfect. So this just takes it up a little bit of a notch to say when you're working with the class in memory, treat it like the native Python types that they ultimately will get out of the database We've created a class, derive from SqlAlchemyBase, specified the columns and their features like indexes and uniqueness, and then importantly, we put them into this so that they got imported. They got seen by the SqlAlchemyBase over here, on this line, right before we called create_all. So it's that thing that looks at all the classes and then creates the corresponding tables. And that's why our Beekeeper Studio, nice and cool, like it does over here with the tables.
|
|
|
transcript
|
4:49 |
We've seen we created the tables, but we haven't put any data in there, and where are we going to get the data? Anyway, wouldn't it be nice to have somewhat realistic data? The data we used before was super fake. We just generated some integers and said there's this many things. We put like, this is the summary, instead of actual summary information. Well, you're in luck because I've given, I've gotten and given to you the actual data from PyPI. So you're familiar with this section, the code all over here. But now, let's have a look over here. When I grabbed all this data, I got the top 100 packages and all of their information, and I saved them to a bunch of JSON files, so check this out. We go in here, we've got ampq, we've got boto, we've got beautifulsoup, we've got the awscli and so on. And if I quick-view these, you can see they've got an author and emails and classifiers like their licenses and notice, they're not simple. Like I want to say this is a BSD license but I've got to go to the info, to the classifier to get the license and split it into pieces and find the BSD part. Say, oh, it has a BSD got it, right. So there's gonna be some work to read this data, but it's no problem. Here is the home page, here's the license written on a better way, here's the summary and so on. So what I want to do is read all of this data into the database. So I'm gonna go over here and create a folder called bin and This is where I put all these little utilities that like, load up the database or run little migrations or maintenance scripts and so on. I'm going to drop into here something called load_data because it is not at all worthwhile for you to watch me pulling this all together, OK? So we're gonna use a couple of libraries we haven't talked about yet. This really cool library called progressbar2 that does a progress bar while stuff is happening in the terminal. That's great, unfortunately, it named itself progressbar, and the package is called progressbar2. Not, not great in that regard but we've gotta put progressbar2 there and we install that requirement. And over here, this will go away in a second, perfect. Similarly annoying, we wanna work with thing that's fantastic called dateutil.parser, but it comes from Python-dateutil so the names don't give you a lot of guidance on, you know, what the underlying package to install is. But I'm walking you through it. It's all good. Some of these we're not actually using here. And this is release and user, OK. so what we're gonna do is we're gonna go through, I'll just clean this up so it runs fine and all that, you don't have to watch. What we're gonna do is load up all of those files, those JSON files, and we're gonna parse through them to find out all the users that are mentioned within those and then we're gonna create corresponding users to the ones we discovered. And then we're gonna go create the packages and then associate the users with their package, who created what. We're gonna do language imports. And we're gonna do some license imports and we'll just print out what happened. So we're gonna run that real quick, and then we'll have data in our database. All right, that thing I dropped in here actually was importing a little more data that we needed, so we're not gonna worry about it like the language and maintainers, we didn't create the classes in SQLAlchemy before, so there's nowhere for them to go. So what I'm gonna do is I'm gonna run this, it'll initialize that connection, create one of these sessions, and it'll check, has data already been imported? If there's no data whatsoever, it's gonna go do the import, then print out a little summary. Let's run it. You'll see down to the bottom the little progress bar thing going across, which is cool. If I press, this, it's gonna run the website, which is not what we want. We wanna go here, right click, run. It goes, you can see a little progress bar zipping by at the bottom. Finally, we have 84 users, 96 packages and 5400 releases. I know said there was a hundred but I think for some reason, a couple couldn't be downloaded or something like that. All right, so now if we go back and we connect again over here, we click around. Look at that, all of our data is here. Super cool, right? So we've got our users. Here's Armin Ronacher from Flask, he doesn't have a password apparently. Kenneth Reitz, say from requests. You should know these names. Here's Ned Batchelder. Probably because of coverage.py and so on. Django Software Foundation apparently maintains Django, but these are all the really popular projects right here. Celery Project, right. That's expected from the top 100 packages off of PyPI, right? So here we go, look at this. We have data, we've got our releases and they go back to their packages, we can see that over here somewhere. Notice we're using the actual string name of the package as the id, which is pretty cool. argparse, asyncio and so on. We're in a good spot, we've got our database all put together, and we've got our collection set all ready to go and actually view these in the website. But remember, we still have to write the queries to do it. At least we have the data to write the queries for.
|
|
|
transcript
|
7:11 |
It's time to start using our real data. After all, we have a database, we have a database model, we have the database full of data from actual real live PyPI data. Let's start using that. In order to do that, we need to actually do queries against the database instead of having this fake data. Now the way I like to approach this is sort of a top down mode. Let's look at this homepage and see what queries we might need to rewrite in order to make that using this live data instead of this fake data. But just to remind you, Let's click here, this is the home page. And the most important things to see are how many projects are there, releases, users and then show me the latest releases to the projects that have recent releases Okay, so we want to go and basically do that. Let's just start here at this index method. We'll go to the IndexViewModel, hold down command or control on Windows, and you can use these hyperlinks, so I'll jump to that. Here we have our package_service, which has given us a release count and a package count and our user service, which has given us that. Let's do the three counts real quick. I'll jump over to the package_service release_count. That looks real, doesn't it? No, no, it doesn't. So we're going to need to create a unit of work, a session in SQLAlchemy's nomenclature. So I'm gonna do, from data import db_session. That is the thing that creates the units of work. And it's easiest if we do this kind of stuff within a try, finally. And then we close up the session, clean it up there at the end right away. So what we'll do, is we're gonna say session = db_session.create_session(). And remind yourself this returns a Session object. By calling the factory, turns off some of the, force you to reload it too frequently in my opinion, types of behaviors. So over here we're gonna have the session. And then instead of this, we're gonna write a query right here. Do this in line, it's really simple. So, say query, what do we want to query? We wanna query the release, to which you wanna go to the table, to the query and just run a count against all of it. And here we'll say session.close() like that. Let's see if we got this working, just before we go any further. Let's go ahead and run it. Now, we should have, what was it? 5,400. If we look over here without refreshing, there's some huge number of releases to simulate the real PyPI but our fake data is just a couple hundred. Here we go, look at that! Perfect, 5,400 out of the database, that's what it's gonna look super duper similar down here, only one word changes, we want to change that to package. That's it, we re run, we refresh. That should go to 96. It did, and then users. I think we had 83 users. Let's go down and write really similar code for the users, but that's over, work our way back. That's right here. They're having this fake thing, we'll do that. Gotta import this, and this is gonna be user, just like so. That should be the three count queries that we have for our little bar. Look at that, it's all live data. How incredibly easy was that? That's awesome. That's why we're using an ORM, because once we get it all set, it's incredibly easy to do. The last thing to do here is to get the latest releases. So we're gonna go over to our package service. This may be the most complicated query we're doing in the entire application. So what I wanna do is say releases, we're gonna start by getting the releases from the table, the releases, here. What I wanna do is come over here and say session= db_session.create_session() and then try this. And finally session.close(). So then we're gonna come to our session, and we'll do a query against the release table. Remember the releases know which package they're related back to. In order to do this query, we're going to have to, well because we're closing the session and we don't wanna have a bunch of slow, come back and do extra queries against the database. We wanna do just a one shot thing, we're gonna do a join. And the way we do that is we come over here and say options and into the options, we're gonna pass the ORM. Now, that's not imported yet, but it's going to be. We have a joinedload, and the way we do the joinedload is we specify the relationship on the thing that we're querying here. So we wanna that relationship, basically its part of the join, so every time you get a release, get it's related package as one query and let's wrap this around and then we also want to go and do an order by because we want the latest one. So we're gonna go over here and do an order_by and then what are we gonna put in this? It's going to be release.created_date.desc(), most recent ones first, and then finally, we only want a certain number here. Now this could cause a problem. But there's a way to say limit and then you pass how many items you want to go over. It just happens to be that word, just the same. And then finally, we wanna say, you wrap that around, and say .all(), wrap that around. Okay, so those are the releases, plural. And what we should be able to do is go to each release and get its package. So that's what we want back, it's not a list of Release, a list of Package. So finally, after that's all closed up, we can return. Just do a little list comprehension, say, for each release, we're gonna get its package for r in releases. All right, Is that gonna do it? We're gonna find out, aren't we? So let's run this and oh, look at that. It's working. So we've got 1, 2, 3, 4, 5 packages back. Let's go and change how many were passing over. Let's say limit equals seven. Okay, Lokk at that, we've got gevent and awscli. Now notice, I told you that this has a possibility of causing some kind of problem because of the way our data structured, if a package releases frequently, it could, and if we ask for too many of them, it could show up here, but we can go, maybe be a little bit safe, I guess. Let's try to do this. Let's go to package service. Say I wanna do a set comprehension here instead of a list and then we're gonna turn it into a list. What will that do? Hopefully it will make it a unique, sets always only hold one of any given item, it's, it's a matter of what counts as you, you know, the same item for these. I think this'll' work, we're gonna find out. Here we go. We should have 6. 1, 2, 3, 4, 5, 6 because one was duplicated. So in this case, maybe we query for twice as many as we need and then do this reduction and a limit. But it's just kind of messed up with the data that we have that it's, there's a chance of getting a duplicate. But nonetheless, let's just take a moment and appreciate what we've got here. This is real data coming out of our database that we populated with real data coming from PyPI. This whole section here is completely live.
|
|
|
transcript
|
2:53 |
Well we've got this page working really well out of the database. Let's click on this. Oh, well, maybe that one is not working yet. The project details. So what we've got to do is, we've got to go and actually get this thing to work. So let's just jump in here real quick and see what the problem is. It said, oh, you passed a bunch of arguments, that doesn't really work for SQLAlchemy anymore. So we could really quickly fix this by saying some of these values, just, if you specify the key names we'd be good to go. This is gonna be description, this'll be home_page url, we've got the license, and this'll be the author_name. All right, so that should make it run. I guess the same problem is true for releases, created_date, OK. Oh, yeah. We've also got to pull out the version here, so let's just do a little f-string. Really, I just don't want to write that same thing a lot. So let's just say f"{r.major_version}.{r.minor_version}.{r.build_version}", All right, so that's the same thing we're trying to get out there. Okay, so we've got it working, sort of, didn't we? This is live, this is live. All this stuff is fake. All of those things are fake. So actually, this may also be fake, right here. I'm not entirely sure, but definitely everything else is fake here. So what we need to do is write the queries to make this page go, don't we? So let's just go through like we did before. Go through the view model and say were we're getting the stuff. So the package name is being passed over, that's great. And it's get_package_by_id Yeah, this is the one we "fixed". We made it run, but this is certainly not what we're wanting to do. Let me just grab this real quick here because it's gonna give us a lot of what we need to work with. We're gonna go over here and do a query against a Package. I don't know why I grabbed the most complicated one. We'll do a query against the package, and what we've got to say is filter and, what do we want? the id is the package_name so we'll say Package.id == package_name, then first(). Just the one, we'll return package. Perfect, let's see what's gonna happen here. It's gonna work? Oh, yes. So let's just see. this is working. Check this out. So we've got this whole thing coming back and working. You ca see this is the latest version. The release was that, I guess, is probably when we inserted it. Let's go back over here, click on gevent, perfect. Got our gevent, all the details, were not actually converting the, cause that's Markdown, that's restructured text, were not rendering the restructured text as HTML, kind of a pain. If we did, then you know, would come out great, but see the license is MIT. If we click in the Homepage, it really takes us over to gevent, where they probably need an SSL certificate. But nonetheless, this thing is working great, right? So we've got our home page, and now we've got our details page working as well.
|
|
|
transcript
|
1:34 |
I almost overlooked something, really quickly before we move on from the Package Details Page. Notice we were just sending this fake release back. Let's actually rewrite this to return the real package release. Let's go down here, we'll say, create a session and we want to get the latest release, right? And I guess there's a couple ways we could do it, we could get the package and then we could get the releases. Or we could just do a query where the package name is something and order by release date, let's go with that one. So we'll go to the release and we'll say filter where Release.package_id is package_name. That should still be set as that foreign key that we're working with. And then we have the first, that's fine, but we're also going to have, come over here, and we want to say order_by(Release.created_date.desc()). So we want all the releases for this package order by, going the newest ones first and then just give us that. And that is going to be "release". It could be, there's a release or there might not be a release, it might be None, hence the Optional return value here. Let's try this one more time, make sure we're really using all the live data over there. If we go to botocore, oh yeah, look at that. It's got old snapshot data, but there it is, botocore updates all the time so it's a little out of date, but check that out. We've got the latest release. We come back to awscli, 05-31. Ah let's good, to kombu, 05-30 and so on. Pretty cool. Now we've got that last query written and working beautifully.
|
|
|
transcript
|
7:28 |
Package details is working, home page is working. There's one final section that has important stuff going on like register, that's not right anymore. But if I click on register, remember, we're just doing that fake data. We're setting the cookie, so it looks like something happened. But there's really no persistence or storage of the users. Similarly, when we try to log in, there's no checking that there's actually a user. So we need to write these two queries here. We've already got the user_count, let's do this create_account. So I'm gonna go ahead and nab this code cause it's real similar and what we need to do, that is just a little bit different, is instead of returning a query, we need to create an object, insert it in the database, commit those changes and then return that object. So but, do like this and say the user is a User, and then we'll just set some of its values, id we don't have to set, that's auto incremented email can be email. Over here, we're gonna set the name, it's gonna be their personal name or whatever, created_date has a default, will get set by SQLAlchemy, hashed_password is, just gonna set this to "TBD" because we're gonna do a little bit of work to do that right. last_login is set by an auto, by a default, created_date is set by a default, profile_image_url is just gonna be None. And that's all we gotta say. So the last thing to do is say session.add(user), session.commit() and then return our new user. Cool, huh? So we're gonna use this later, we're not using it yet. We're gonna come back for a second pass and store the password here. So this is our query, our create_user and then lets do, we really need something more like this. Let's go and do the query user as well and maybe I'll just put "# TODO, set proper password". And while we're here, let's go and do this one as well. Everyone having the password "abc", that's not the best. What we wanna do is come over here and say I would like to get a user. Now, a naive query would be give me the user where the email is this and the password is that but you never, never wanna do that because that means you'll be storing raw passwords. Don't wanna do that. What we wanna do instead is get the email and then check that the re encrypted version of the hashed password match, the plain text password matches what the hashed password is. So we'll do our filter where user.email is the email, I'll say first(), this will be user, here we go. We're gonna say, give me the user. If there's no user, gonna return whatever that nothing is, it's very, very, very likely None. And I'm gonna put just "# TODO: verify password". We're gonna leave that for a little bit later, not do that yet, and then we're gonna return the user, right? Assuming that the password, say if. So if for some reason the password is wrong or whatever, we're not gonna return that. Okay, so we'll return the user we got back from the database and let's see if we can do this round trip here. So we're gonna run, down to beekeeper, and I'm gonna go over the users table and let's go and order by created_date, doesn't matter, they're all created right then, but it will in a minute. We're gonna have something new in there. So what we wanna do is we want to go over and try to register. So to register, I'm gonna put my name this time, this is the password, put my fancy letters here, doesn't really matter, but I think it's required. All right, moment of truth. This should now go save it in the database, it did not. Something went wrong, right here. Ah, yes. Our AccountViewModel needs to be calling the database here. Yeah, so what we need to do is, if we look at the ViewModelBase, we've already got the is_logged_in and let's, let's go and set this like so. Let's set this here, The logged in is that is not None. All right, so if there is some kind of id set, then they're logged in. Okay, so we already have this user_id. And what we need to do is just go and write one more function, is user_service.get_user_by_id, and it would be self.user_id Didn't exist yet, let's go write that real quick. And this is an int in this case, and it's gonna return like before an Optional[User]. See, there's a lot of similarities going on here. Copy, copy. This one's simpler but quite similar in structure. So we try to get it and, this time where the id is the user_id and let say return that, but in fact, we could inline this and just return that result, doesn't really matter if we look at it. Sometimes I find having a variable is nice for debugging. You can say, well, what came back here? Alright, go and return that but this is gonna be straightforward. All right, I come over here, try and it thinks we're logged in, but let's go and log out. Let's go register, again. Say Michael, email address, five a's and some number, but let's just verify what's happening. The register actually worked, I believe. But then, we didn't get the right data back, right? The error was in the account page, not this, so hit register, and we still have an error, what's going on here. Ah we're not checking, apparently, we tried to register with the same email address. We already have this email, so let's go and add, looks like we're missing something in our registration view model. Yeah, and we didn't do the test, right? So another test we need to do, say elif user_service find user, user what do we get? It is get user by. Let's say get by email self.email. If you're gonna have a uniqueness constraint, you can only have one of them. Okay, so maybe you should log in. Alright, so let's try that real quick, and it's extremely similar to this. Except for that is email, and that is email. And that's a string. Okay, let's go try to submit that again. Now it comes back, it goes no, no, no you can't do that. That email is already taken. Oh, well, let's go and try to log in, we're just not checking the passwords so I'm gonna put only three a's this time, not five. Remember we're coming back to do that authentication stuff. Look at that, I've logged in, I'm logged into our account. Let's try one more time, I'll log out. I'm gonna log in. Beautiful. All right, awesome. So we've got our account set up. Let's just go finally, look in the database, we'll do a query select * from users where users.email is my email. We run it and check it out, there we go. Name is Michael Kennedy. password is not set yet, created_date is right now today, profile image not set, but we created our user and we're using it to log in and log out. Let's check one more thing. Let's try to log in using a non existing thing. Sorry, that account doesn't exist in our database. Super cool. So I would say we have these queries, all working. We just needed a little bit extra back here to make sure we didn't create the same user twice, which the database won't allow. That's it. We are 100% using our database and writing all the SQLAlchemy queries against our models to make this entire website run. Beautiful
|
|
|
transcript
|
6:46 |
The final thing to get our SQLAlchemy stuff really working 100% has to do with storing passwords. Now storing passwords is tricky. You wanna make sure you get it right and doing it yourself is probably not the right way. So over here, let's check out our TODO's that are pending, says set the proper password. What that really meant is take the plain text passwords and set the hashed password to a hashed version. If we just do an MD5 hash, there's these look up tables. This hash equals this word, this hash equals this word. We can't do it that way. Also, we wanna make it computationally expensive to guess if for some reason our database got stolen and somebody got ahold of those hashed passwords, we don't wanna just hash it once, because then you could just guess a bunch of things. So there's a lot of different things, like bringing salt that is arbitrary text into, mix it in with the word but also hash folding or password folding, where you hash it, and then you take that result and you hash it again, you take that result and hash it again a 100,000 times so that it's really computationally expensive to take a guess at a given word, much more so than a single hash. So what we're gonna do is we're gonna use this package that makes it much easier called Passlib. It does all those things with a variety of different cryptographic algorithms really, really easily. So what we're gonna do is we're just gonna go and add passlib and let it do all the hard work for us and get things right. So passlib another one to install and it's not misspelled. Now up here at the top, I need to import something from passlib. So I'll say from passlib, and I want to import it as a certain thing so if we change the algorithm, we can actually change the underlying algorithm, we don't have to change the code just because the name of the algorithm changes. So what I'm gonna write is from passlib.handlers.sha2_crypt and here on import sha512_crypt Not like that though, but as crypto. That way, if we decide to use bcrypt or a different algorithm, it'll still just be one of these providers, one of these handlers called crypto. Okay, so that allows us little flexibility. And down here, this is incredibly easy to use. All we have to do is go to crypto and say encrypt. We give it the password, and it also takes a bunch of arguments. See if it'll have documentation inside. Oh, it looks like it was renamed to hash. Okay, let's call hash, then. Fine. And the secret is password. Does it say what its keyword arguments are? I know which one I want, but I'm not sure, I was hoping for documentation. So what we could do is we could come over and we could say round equals let's say, 172,434. So I talked about that folding and do a hash, and you do the hash of the hash, the hash of the hash of the hash. This will do that iteratively 172,434 times making it computationally expensive. If you wanted to be, take longer, you make it higher. You wanna make it a little bit quicker, I'm guessing This is about 1/10 of a second, I'm not 100% sure. Let's go and do this and register a new user and see what gets into our database. So register, this'll be Sarah Jones. this'll be sj@gmail.com. She loves the password "abaaaa" and who knows how old she is. We hit this, we get our account and let's go to our database and have a quick look. She's at the bottom and now check this out. Copy this and I'll just put over this query page here so you can see it Look how giant, enormous that is for, like, four a's and a b. This is all sorts of craziness. So it tells you the algorithm that was used, the rounds here, ups don't move that around for me. The rounds that were used, the number of iterations and then a combination of the encrypted result, along with hash that was randomly created for the salt that was randomly created for it, and so on. So this is way more secure than storing plain text. Even better than just hashing it once, right? So it has randomized, per user salt, plus the iteration. Really, really nice and how hard was it? It literally couldn't be easier. crypto.hash(password). Now, what is not so easy is how do I verify that? How do I verify that that is actually the password. Well, what we're gonna do is I'm gonna come over here, we don't have to remember the rounds, it's stored in the result. But when we log in, we need to say we're gonna get the password that they provided and we wanna compare that. So we're gonna come over here and say crypto.verify. It doesn't say "decrypt" because you cannot decrypt the hash. But you can look at all the pieces and hash it again and say, Did the outcome match? So here what we're gonna pass over is we're gonna pass over the secret, which is the plain text password And then we're gonna pass over the hash, and that is what we stored on the user object, the hash_password. And if it's not verified, We're gonna say no, get out of here. Otherwise it will return the user. So look at that, to use passlib, literally that line and that line and we're covering so many good practices around storing passwords, incredible. Let's go try to create, let's go try to log in, as our other user. Hope I remember the password, right? It was sj@gmail.com, I think it was "abaaa" We'll find out if it doesn't work. No, password's wrong. Let's register a new account. There's no reset. Sarah Jones2 sj2@gmail.com and we'll set a decent password and register. Now let's log out and see if she can log in again. So come over here. Use that same email address. Boom, we're logged in. That's awesome. If I were to put in an invalid password, something else, nope, doesn't exist. It doesn't let us log in. So really, really fantastic. This passlib, how easy it makes storing passwords and doing user management correctly. FastAPI has other ways of authenticating users and doing authentication. We're not gonna go into it in this course, right? Use just this user name and password integration here. But if you wanted to do like Federated Identity or OAuth or stuff like that, the framework does support it, but it's sort of beyond the scope of what we're doing here to get deep into user management and different types of authentication. Pretty awesome. I'm super, super pleased the way this came out, that is the way to do things. And that's a really nice way to verify that they are logged in correctly. You saw in the database, go back to our users. Now we'll have a couple examples. You look at these two. The number is the same there, but then after that, it's just all randomness, and it's not anywhere near the same thing. Super super cool way to store this users in our database.
|
|
|
|
39:07 |
|
|
transcript
|
1:31 |
Welcome to the async SQLAlchemy chapter. I'm so excited to finally be presenting this part of the course to you. We've been building towards this for a long, long time, and I'm so excited because this is how we're going to take advantage of one of the most powerful features for creating truly high performance web applications with Python. Async and await, one of the reasons I love FastAPI so much is it makes it really, really simple and straightforward to create async web applications, you simply use the cool async and await keywords that come with Python, and it handles the rest at the infrastructure level. We can have async and non async code mixed together in different view methods or different API methods, and it just knows how to treat one as async and one as a regular web method, but in order to take advantage of that, we have to have async for all the external systems we're waiting on. If we're calling an API, we need to use some kind of client that understands how to do that asynchronously and importantly, one of the biggest things, the biggest systems we wait on in web applications is the database. In fact, many web applications, I would say, do more processing or computation, spend more of their time in the data base layer than they do in the actual web layer And with async and await we can take all that time we spend in the database and just completely free it up to do way more web processing. So this is really, really a key piece of the advantage of FastAPI and we're gonna dig into it now. It's gonna be awesome.
|
|
|
transcript
|
1:45 |
I need to put a warning right in front of the beginning of this chapter. We're using the async functionality of SQLAlchemy to unlock the database async behaviors in FastAPI. That's awesome, SQLAlchemy is by far the most popular ORM if you are excluding Django ORM, which is tied to Django, of course. So it makes sense to use SQLAlchemy. However, as we already saw when we started the previous chapter about the synchronous version, the async support is in flux, and we only have a beta version of the API to work with. Now beta, that's not alfa, that's not pre-release, that's somewhat stable, right? But at the same time, it's not final. It's, there's no guarantees, and it's only a step towards what they're calling the 2.0 version of SQLAlchemy. So for that reason, we're going to have to use the beta version of SQLAlchemy. There may be some changes along the way, so I wanted to point out that I've created this course revisions document just at the top level of the github repository called revisions.md and my goal is to put any changes like you need to make this small code change, or warning, we had to change this thing about the way we were working with any of the code in the course. But the one that I think we're gonna end up potentially making changes or having any issues around is gonna be this part of SQLAlchemy. Be sure to check this document. Right now, you can see it says initial commit no changes, and that's because it's just what we're recording. But over time, there might be some issues we run into. I'll update the code in the repository. Maybe you run into something. Create a github issue and let me know in the repository, and we'll keep this working will keep it fresh. But in order to do this now, instead of waiting months or maybe years in order for the support to be fully there we're gonna have to use the beta version. Who knows what's gonna happen in the future so just a heads up on that.
|
|
|
transcript
|
4:52 |
Before we dive into writing code around async and await and moving that up into the FastAPI layer, I wanna just broadly cover what is the value and where does async and await play a role in scalability. Now scalability can mean a lot of different things to different people. But the idea of scalability is not to make one thing faster, it is to allow you to do more of the same thing without slowing down, right? So the goal here is if we have, say, five requests coming to our site, and then there's some kind of burst and we get 500 requests coming to the same website. We want it to be able to handle those 500 requests at about the same speed as it would handle the five. That's the goal. That's the scalability that we're looking for. We're gonna examine two views of a theoretical web server doing some processing, one that is a traditional Python WSGI, Web Service Gateway Interface application that does not support async view methods. Traditionally, this has been Django, Flask, Pyramid, all those different frameworks. Django is starting to add some async features, Flask is thinking about it. Maybe by the time you watch this recording, they've actually made some progress there. But many of the popular Web frameworks do not support this async scalability. So this first view that we're gonna look at, this is, this is, you know, traditional Flask. Let's say at least at the current time of the recording, and we'll see that we're going to, as we get more work sent to the server it's just going to take longer and longer because, well, it's not as scalable. So let's look at a synchronous execution here, and we're gonna get three requests. Come in really quickly. Now, these green bars are meant to represent how long it actually takes us to process from the request coming in to the response coming out for the page that Request 1 is pointing at, and the page that Request 2 is pointing out and see Request 3 down there at the bottom, even though it came in third, it's actually incredibly short, so it should come out really, really quickly if there was no other traffic. But what happens in this synchronous world? Well, Request 1 comes in and boom, we're gonna start processing it right away. How long does it take from a user's perspective from actually the request hitting the server until the response goes out? Exactly The same amount of time is as it would normally take, right? It's just that's how long it takes. But when the Request 2 comes in, it has to wait to begin processing. It cannot begin processing its response until response one is done, right? Because the server is synchronously working, it can't do more than one thing at a time, so it's going to wait to get started. And the big yellow bar is how long. It seems like the page takes to load to the user who made the request because they've gotta wait for this Request 1 they don't know about, plus the time it takes for theirs. Poor old Request 3 comes in just after Request 2 and it takes as long as that big yellow bar for it. It's gonna take a really long time for it to get the response. If it had been processed alone, it would be really rapid, just the size of the green Request 3 bar, but because it has to wait for 1 to finish and for 2, which is waiting a while for 1 and then itself. It doesn't actually get processed for a long time. So for the user, from the outside, it appears that this Request 3 takes the big long yellow bar time to get done, even though it would actually be really quick. What's going on here? Well, if you actually dig into one of these requests, let's say Request 2, for example or Request 1, doesn't really matter. One of the longer ones. It's not just processing, there's a bunch of systems working together in web applications, right? Maybe we're calling an external API through microservices, maybe we're talking to the database and so on. So let's expand this out. What does this processing actually mean? So here's Request 1 coming in, you could think of it as just we're processing the request, but if we break it down into its component pieces, it's a little more interesting. We have the framework that we're doing some database work and then a little bit of our code runs, which issues another query, which takes a long time over to the database. Get a response back, we do a quick test on that, and then we send that off to a response in the framework. So how much work are we actually doing? Well, maybe the gray plus the blue, the gray plus the blue is all that really has to happen. This database work, this is a whole another computer, another program that we're just waiting on. So there's no way in a synchronous web request to allow us, our website, our web framework, our web application to do other things while we're waiting, we just call the query and it stops. That's not great. This is why there's such a blockade when Request 1, 2 and 3 are coming into the system because we're just waiting on something else when in fact we're only doing a small amount of work. Maybe a 10 to 20% of this request is actually us doing the work where the server would be busy. Most of it is waiting and async and await in Python are almost entirely about finding places where you wait on something else and allowing other things to happen while you're waiting. So there's a huge opportunity to do something better right here.
|
|
|
transcript
|
1:42 |
If we live in an asynchronous world like FastAPI allows us to do incredible easily. This picture looks much, much better. So here we have three requests coming in. Look at this picture now. So Request 1 is gonna come in and guess what it's gonna take as long as it takes to compute that. And then we'll get a response back halfway through. Remember, what we were doing, maybe a third of the way through in Request 1 is we were waiting on the database. Well, anytime we're waiting, if we're using async and await, we're allowed to just completely go do other work during that time with almost zero overhead in fact. When this request comes in, we can start on it right away, and we pretty much do a couple database queries and just wait. So now we have Request 1 and Request 2 in flight, but they're both just awaiting a database response. Request 3 comes in and boom, we can get the answer right back to them. How much better experience is this for the user? Yes, it still takes the same amount of time to that database period while we're waiting for say, Request 1 or Request 2 or even Request 3. There's no speed up of waiting on that database. Our initial request is the same speed. But as the traffic builds, it doesn't slow down the site because most the time we're waiting, we can just keep on doing other stuff, serving Request 3 while we're waiting on 1 and 2, for example. It's beautiful and we're gonna see how to do this with FastAPI and SQLAlchemy in this chapter. If we zoom in, again, where we had our framework and our database and then our code, all this stuff that's green, we can now go process other request because we're just waiting on the external database to get back to us. Really, really nice with just simply converting those queries from a regular query to an async query we're good to go.
|
|
|
transcript
|
3:43 |
Here we are in chapter eight now. You can see I've copied the code, the final code from chapter seven over as per usual, now it's the starter code for chapter eight. In order for us to work with the new version of SQLAlchemy, the first thing we gotta do is actually we've gotta go over here and adjust this to say, this is a certain version and funny the way this is coming together, we're creating a fake PyPI, we're going to need to go to the real PyPI and find SQLAlchemy, go to its releases, and here's the beta version that we want. And we can just copy that bit right there. And so what we wanna put over is this. That'll allow us to use the async features that are not in the 1.3 edition. Let that reinstall here. All right, that looks like that worked. Now the API is different for working with SQLAlchemy. We don't create just a session and use the query the same, what we do is we create an async session. The first thing that we have to make changes to is to our db session class because we need to do the async stuff. The other difference in the API here, in the traditional one, we created a factory that creates the session. But what we're going to need to actually store and notice if we go down to where we put this together, We've got a connection string, we create an engine, the engine is passed the factory, and then the factory is used later. In the a async model, what we do is we have to hang on to the engine and then each time, use that to create kind of a context block type thing with the engine. So we go over here and we're going to create an __async_engine that's just this internal thing, It's gonna be an async engine, which we can import from sqlalchemy.ext.asyncio and we'll make that Optional of that because we want to set it to be None in the beginning, and the way that we create it is pretty similar. So here we have this create_engine and we're gonna do something like that. But instead of calling this, we're gonna say, create_async_engine like so, the parameters that go to it are the same but this set here, this async create is what we need. And it's telling us that this needs to be registered as a global for us to make a change instead of just overriding a local. Okay, so that's working. And then this create_session thing is gonna use that over here. So we'll say def create_async_session. Let's call it that. This is gonna return an AsyncSession like so. We'll say we're gonna use this global __async_engine here. And let's just do a quick test, it was like this where we said, you know, you've not set this up before, so for some reason, if our __async_engine is not called, then we know that they didn't call the right set up, and this is gonna be a big problem for us, perfect. And then this is pretty straightforward. We're gonna create the session, which is an a AsyncSession. Instead of just calling the factory, we're just going to allocate it and pass the async engine along like this. And from here on, it's pretty similar to what we have before. Pretty similar, not the same. Now notice this expire doesn't, expire_on_commit doesn't exist. So this is the async session but there's within it async session for which we can set the expire_on_commit. All right, so that's pretty much the changes that we're going to have to make in order to have our async engine stored and then the ability to create these async sessions. We're gonna go and use this function instead of this one to go through and do these async queries against SQLAlchemy. Let's just run it to make sure when it runs this whole startup code, everything's hanging together. Perfect, it looks like it is. So our foundation to create these sessions we need to rewrite the queries is all in place, looks good.
|
|
|
transcript
|
7:46 |
Now that we have our db session with async capabilities, it's time to go use that for some queries. And here's where we're gonna get into the new query syntax for SQLAlchemy So we don't need db_session anymore, we're just gonna use it and let's go work on the user_service for now. There's a couple of queries that we want to go and rewrite. For example, let's work on the count. Recall, this is the one that's shown right on the home page when, it's got the little gray bar that says, how many packages, releases and users there are. So we're gonna do something similar to this, but not exactly the same. So let me comment this out and leave it here to guide us. We'll say. You'd like to say db_session = db_session.create_async_session() but things are a little bit different, as I've indicated here with this async API. What we're gonna do is we're actually gonna do an asynchronous context block, a with block, but one that's async, that's a little bit funky syntax in Python, but that's how it goes. So we'd like to say something like this with that as such and such, and then we're gonna use it. And I, for one, am really happy to see the session being able to be used in a context block, that means it'll clean itself up like you saw where you're kind of simulating that with try, finally. Well, now, in this new API you can just put it right here. So this is cool, but because this is asynchronous, what we need to do is do an async with block here, and then we're gonna do a query. Now, the queries look a little bit different in this new API. Instead of saying session.query, what we do is we actually create a select statement and then we execute it. So we'll say, select, I'm gonna import that likely from sqlalchemy.future, and in here, we're going to put some kind of statement. Now, normally, it's pretty straightforward, like user, and we do like a filter and and so on. But for count, it's a little bit funky. So what we're gonna do is, we're gonna say, I'm gonna import this thing called "func", which comes from sqlalchemy, and then there's a way to say count(User.id). So we're gonna pass a function that's counting the user id over to the select. Now we're gonna go get the results, because this is just a query that has yet to be executed. So here's where the session comes into play. We'll say execute and we give it the query. This is where we go talk to the database, and when we talk to the database, this is our chance to do other work while we're waiting, right? If I were to, look at this and then print out the type here, let's just do a, a really quick print type of result and then I'll, let's return 12, how about 42. That's a good number of users. So when we run it, you'll see something happen, and then this, and should probably see a warning as well. So let's run this and okay, so we've gotta do one thing first. In order to use async or await within a function, we do have to make it async here. Alright, and in order to actually call it when we're calling an async function, we need to sort of go up the stack and await that as well. So let's go and do that. We'll go see where this is used, which is going to be in our home IndexViewModel and notice, already right here PyCharm is saying there's a problem. What is the problem? Well, the problem is that we got a coroutine and we wanted an integer Oh, this is an non executed, but could be computed, could be executed asynchronous function. And in order for us to actually interact with it, what we have to do is we have to await it. We'd have to type this await here. That's cool, except for there's a small challenge here. Constructors cannot be asynchronous, so that means we're gonna need to split this apart into two pieces. Let me do it like this def load or something like that. And here, we're going to just make this all equal to zero at the start and then we'll set them to something meaningful. I'll just use an empty list for now. Okay, so over here because this is also async, right? This kind of propagates up the stack, like I said, this is now going to be an async function that we can then call. Once this one's async we're gonna need to call it so let's go further up the stack here. Typically, how this goes. And over here, we didn't previously had to call vm.load() but now we do. And if I try to run this, you'll see some weird stuff happening. When I request it. It worked but there is no data. And if you go down here, you can see warning, warning, Index, scroll over, load was never awaited. Okay, so this actually never really started, it never did anything. So we can await this, that's the warning I was looking to show you. We just gotta work our way out far enough to get it to actually run, so you can see it. Now, when we do this in order for us to have that keyword there, this has to be an async function. And here is where FastAPI is awesome. What do we have to change in the way we're running the program, like the web server were using, the way we might deploy it, the way that we specify a route or any of those things? Nothing, nothing changes. It's all exactly the same, FastAPI just knows that this is an async function and it'll automatically execute it correctly. So let's run this again. And now if we go and request that page, you can see we now have our 42 right there. And somewhere down, there's another warning that there's another coroutine that was not awaited, this execute. Took me a while to get to be able to show you that, but there it is. We go down here, this is actually an asynchronous function. So when we're talking to the database here, we need to tell Python we're about to wait on something external, You can go do other things until this finishes and then please pick up here on. Okay, So if you look at that print somewhere back here, you can see that this is a coroutine just like we already saw. But now if we await it, this is actually going to be just a result. But let's go print it out one more time. There's, there's something different as well here, result, and let's put the type of result as well. We'll do a quick refresh, we have an iterator result and also just says that thing. So if we put, let's put this into a list so you can actually see what comes out of it, not the same shape as it was in the previous API. So look what we got, we got 87. That's good, that's the number of users. But what is this? That is a tuple. We got a tuple here. So the way this works, in the new query syntax in SQLAlchemy, what you get back, our table rows are the value or the object that you tried to query and then maybe other things. I'm not sure exactly all the different things that might be returning there, but you get a tuple of results. So in order to actually get the result that we're looking for is we need to go and say, return the scalar, I thnink scalar will do it. If you go and request that, this should now turn that 42 to an 87 and it does. Okay, so remember when I said this is probably the API you know, and this is a little bit different. I'm sure that this looks quite a bit different. Both because it uses this select thing, you pass in additional functions, you await the execution. But also because the results you get back are these tuples where one of the elements is what you actually used to get back previously. Okay, so not really a big deal at all. It's quite easy. It's just like I said, not that similar. So let's go over here. The next one we gotta write is create_account and then login and then get this two users by id and by email, both are gonna be pretty similar to the one we just wrote.
|
|
|
transcript
|
4:24 |
Next up, let's rewrite these two, get_user_by_id and get_user_by_email here. So I'll comment this one out, and it's gonna be quite similar to what we just did, which I copied. So we're gonna create this async session, then I'm gonna create a query, but now the query, this one's a little bit more like what you would expect. I'm gonna say, gonna create a select of user where we filter, I wanna filter by user, what are we doing, id, this time equals user_id. Now previously what we did, as you can see right below is we did first(). So we're not gonna do that here. The, we can't do those types of queries directly on the select statement, we do it on the results. We gotta come in here and get our result, and then we're gonna say scalar_one_or_none. So give us the actual value, which in this case is gonna be a user object, the one that you got or return None. Don't crash if there's no results, like if they pass the wrong id or in the case below, we're checking to see if it exists, right? Or to say, give me this, Is there a user by this email? Yes or no? So we could also rewrite this one really quickly as well. In this case, it's just email and email for our comparison here. And that should do it. Maybe format it like this. Make it look a little better. All right, so this should do it. But in order for us to write this code, we have to make this async functions, right? And then where they're called, we have to convert those things to async, right? It propagates up the stack. In this case, we got our AccountViewModel, and it's gonna need one of these def load, which is an async function. Then here it says, warning, you have not defined a user class in the globals object yet, right at the startup. So we want to make sure we always do that. It's going to be an Optional[User], we don't know if there's one coming back or not. Initially, there won't be one. Now, PyCharm should be complaining to us here, but it's not so if we go look, this is an async function and where we're calling it, what we get back, as you saw is a coroutine. So we need to await this right there. Right, then up the stack. Where are we using this? Well, we're using that in our view for account in the index right here. So we'll await vm.load(), which means this has to be async. Now we're all the way to the top of the stack. Hand that off too FastAPI, and it'll go. Let's just see if this will work real quick. So let me first log in, There's a problem, not gonna work, is it? It does work, look at that. We haven't changed that function yet. So over here, we got Sarah Jones2, and we were able to log in. This is our slash account, which is running that code right, ups moved around, running that code right there. Perfect. The other one that we were working on is this one right here. So we need to see where we're calling this. We're just calling it in this one place where we're doing this check. And so this one is already async luckily, because we had to do that for the form. So we're just gonna need to make sure we're awaiting this. So we wouldn't have been able to register because it would have said coroutine is not none. So that means the email was taken, not actually true. Let's run this again and make sure we can register now. I log out, register and register a third Sarah Jones. See if she can register. First let's try to register with her old self. Nope, that email is taken. Oh, yeah, that's right. This is actually my email. Let's try that. Boom. Sarah Jones3 was able to register. All right, So hopefully you're seeing the pattern here, right? What we do is deep, deep down in the service layers, we switched to the async session objects, we await the database queries, that converts these methods to be async that just propagates up the chain. So If we're over here, in the view model, we have to make sure that the load, we have some function that we can make async where we're doing these calls. For example, this one already was. We had to make sure we added the await right there to actually get the email back, not just the coroutine
|
|
|
transcript
|
2:03 |
Next up is our create_account. This one is not asynchronous yet. So let's borrow this little bit here and make it asynchronous. So we're gonna do that, and that makes this method require async. We no longer need our try, finally, because we've got our context block already. And what else do we need to do? We could actually do this right here, ahead of times outside of this async behavior. So this will run right away, including this, which is computationally slightly expensive. So we can do ahead and run that. And then as soon as we've gotta talk to the database we'll go and await it. So we begin, basically begin a transaction, add this record to be committed. This commit here, this is asynchronous, this is where we're talking to the database. So we need to say await, you can go do other work while we're talking the database. When it gets back with the result, we'll send it on. We're gonna return, you could even do it like this, we could return our user. So everything looks good. That's pretty straightforward but remember, wherever this was being used, we now have to go and make that async. So that means this becomes await right there. This one was already async because we needed that for the parsing of the form, which is a async in and of itself. All right, we should be able to register again. But this time, using the async capabilities. Log out, what do you think? time for another Sarah Jones register? How about Sarah Jones4? And again, let's go ahead and just verify this works, the email is taken. But if it's 4, you can create the account. Here we go. It looks like we created the account so, perfect. This bit of code seems to be working great. We can now asynchronously, create users. Super simple, very similar to before actually, in this one even more. This is the most similar code you'll see from anything that we've done. We just, instead of creating the session, adding and calling commit, we created it with the context block and we await the commit. Easy.
|
|
|
transcript
|
3:42 |
The final user method that talks to the database that needs to be converted to this async API is login_user. Again, pretty straightforward. So I'll come over here, like this, and we want to get a hold of the user by email so I'll leave some of these tests in here. This is gonna be different, of course. We do a query, which is a select of User like this. And then the filter goes on, but not the first, that goes to another location. Then we say result equals session.execute(query). Now, remember, this is the async part right there. We're talking to the database, so we say await and then finally, we're gonna get the user. Not by saying first, but results.scalar_one_or_none, that's how we did it. We check, are they there? So we get the user back. If there's no user with that email, well obviously they're not logging in, are they? But if they do come back, we want to verify their hashed password against rehashing the password. But if for some reason the password's wrong, also return None. And then we return the user. As before we gotta asyncify this and then find where it's used and push that up the stack. This one awaits it. And because we're doing the form stuff, those are always async the way that they work. So that method was already good to go. Very cool. Let's go and try. to log this in here. Log out, close some other tabs. Let's go try to log in. Let's go log in as Sarah here. Perfect, we logged in as Sarah Jones2. Let's log out, and how about Sarah Jones4? Yep, we can log in to Sarah Jones4. And let's try one more, log in as other@gmail.com, "abc". Nope, there is no other. And also, let's make sure, even if we have the right email, but the password is wrong, still can't log in. Pretty awesome, in fact, because the way async and await works, we have the ability to do a little bit better here. In this login part, it is somewhat computational here, but you'll find once you get your site on the Internet, after a while, if it's popular, people are going to start hammering away on it for various reasons to just cause mayhem. Try to guess passwords, all kinds of stuff. The one thing we could actually do here is we could go and say something kind of like time.sleep(5) And so you know what? I'm not gonna get back to you for another five seconds to tell you whether or not that guess was right or wrong. However, if you do time.sleep(5), this is gonna be bad. It's going to literally lock up the server on this whole thread for everyone. Doesn't matter if you're using async and await or not. But if you go to asyncio, import that, there's a sleep right there and this one we can await. So this one, it's just gonna stash it off in the queue and then pick it back up to run in five seconds. It won't have much overhead at all. Let's go and try this one, that is a little more picky if you get the login wrong. So let's see, are we logged in? No, let's first see that it logs in super fast, if you get it right. Bam! Yes, it does. Log out, log in maybe one more time. Even quicker. Yeah, perfect. But if for some reason we get it wrong, put in junk for our password, for example 1 one thousand, 2 one thousand, 3 one thousand 4 on e thousand, 5. Yeah, there you go. No, that wasn't right. So if you want to slow people down, if they're doing things like trying to guess at coupon codes, access codes, other pages, accounts, its really easy to asynchronously just put them on the chills so they can't guess nearly as quickly which I think is kind of cool, actually.
|
|
|
transcript
|
7:39 |
Over here in the package service, those were the final queries that we needed to convert to async. And because it's exactly the same as what we've been doing, I decided to go ahead and do the conversion, and we'll just talk through it real quick. So for the release_count, just like we saw before, we're gonna do a select with a function count of Release.id and execute it, that's pretty straightforward, at least given what we saw for users. package_count, exactly the same. But Package instead of Release. This latest_packages, remember, this was our most complicated query that we had in our system. But from here to here, it was exactly the same as the old query. We just have to, instead of doing session.query, we just say "select" and then you can't do the all() anymore, what you do is just scalars() like that. Then we did this little set trick just like before to make sure we get only unique ones in case a package has had a release within a couple of times of some of the other ones, right? We had a little duplication, and that gets rid of it. get_package_by_id again super similar. You get a select, here your filter just like before, await executing it. And this first() is now scalar_one_or_none. Also converting the latest release for a package. Very, very straightforward. This was basically the same thing. Execute it, these are scalar_one_or_none, good to go. So that's it. Those are all the queries. But what I wanted to do together with you, it's just integrate these queries back into the rest of the application. So let's go find where this is being used and update it. It should be just that IndexViewModel right there and notice PyCharm is saying all of these, all of these are a problem. None of them are returning integers or lists, what in fact they're returning is coroutines. We gotta execute the coroutine and get its value out by awaiting it. And then this one, we now can say more concretely, this is a list of Package. That will give us a tiny bit more autocomplete. So release count, package count, we already just took care of. latest_packages, I believe this is also just used in that one location. Yes, it is and we're doing things, I'll get there. get_package_by_id, where is that being used? You'll find it, there you go. It's over in this DetailsViewModel. Now, this is one of those that's going to take some work. We now have to await this, and this one is also async, so we're gonna have to await that. That means we will need to do some sort of work. Let's reorder this a little bit, like this. We need to do some sort of work in order to allow us to await this. Like I said, constructors, the dunder init, cannot be asynchronous. That was already down there, so I guess that was just duplicate. So this part right here needs to run somewhere else. However, these things need to be defined as optional things of whatever they are, so this means Optional[Package], so we can write this code here, define it correctly, and then load it up. Come over here, same type of thing but for Release. Package release, the latest version, that's already set up there. Okay, good. So now all we gotta do is make an asynchronous function that we can call wherever we were using this before. Remember, it's called DetailsViewModel, and it's in packages. So that would mean it's in the package view detail function. There's only one, apparently, so that kind of solves that right? But the last thing to do is make this async and await vm.load() we should be good to go with that. We may have just done it. That might have been the last function. Let's see, where is this one being used? Yeah, it's already being awaited. That's cool. Oh, however, I just now noticed, you may have have already noticed that, we need a "self" over here to pass it along, perfect. All right, let's go click around the site and see if it works. Make sure there's no "you forgot to await something" warning. So here we have number of projects, releases, users. Those all look real. Notice I added two more by adding those Sarah Jones3 and 4 in, which is pretty cool. We have the awscli. The part that we just worked on is, what happens if I click this? Mmm, not something good. What has happened here? Multiple rows were returned, right here. Oh, yeah, we just want to say scalar I believe. It's, scalar_one_or_none is if I'm trying to get some kind of like user or something were it's supposed to be unique. Let's see about that. There we go. Because, of course, there's multiple releases. We just want one, which is the latest. Alright, perfect. This is working right here. Looks like everything's good. We could check out the home page, that awscli sure looks like it, so that, that's working. Let's click on one other, gevent, perfect. There's details about the gevent, the library, and this is all working. So homepage, package is good. Let's just one more time. Log in, log out. We log in, log out and finally do one more register. I'm sure this will work because I've done it so many times, but we'll do a test with the wrong one there, already exists. That's right, we wanted Sarah Jones5, and Sarah Jones5 is now registered. That's it. Let's double check, really quick here, make sure there's no "you forgot to await something". No, no warnings either. Looks like we got everything converted over to this new SQLAlchemy style of programming. Now I want you to just think back to that diagram where we saw the animations where we saw all the interactions, so over here. Here, where we saw those interactions when our request would come in to, like, slash project slash whatever. What are we doing here? We're going. And we're saying I want to start a little bit of work. So this whole section here is gonna run synchronously, which builds up the variables to work with. And then we're gonna await this load jumping back over here. This is where we're going to the database to do a query and say: you know, anything that's happening right now, if another request comes in while we're waiting for the database, cool, just go let that request do its thing, maybe start off another database call, when this database gets back to us, just put the answer right there. Oh, now we're gonna start another database call, and if anything happens during that, it's cool, just go process it. When this one's finished, drop the answer right there. And then a little tiny bit of work, like checking for None on two items and a string format. Most everything happening in this whole series right here is about waiting on the database, in those two database calls. Were doing that asynchronously, that means we're not blocking up the server, were not consuming hardly any resources while that's happening, on the web server. Obviously the database is working its heart out, trying to give us the answers, right? using its indexes and doing its thing. But as long as the database can handle the traffic, this particular part of our application is not gonna be the bottleneck, and that is super, super cool. It's possible because async and await, we were able to use async and await because we're using the latest SQLAlchemy, the beta version that supports actually asynchronously talking to the database. Super cool, hopefully you'll appreciate this a ton. I think it's really, really neat, and it unlocks some amazing potential for your web app.
|
|
|
|
41:39 |
|
|
transcript
|
2:06 |
So we built a really fine web application with dynamic templates and static files and all that awesome stuff that most web frameworks have, on top of FastAPI and that's great. It leaves us the option to do all the API side of things with the best API framework out there in addition to doing all the cool web things. But web apps are not fun for you, just you and yourself. The whole idea of a web app is you put it on the Internet with a domain and the whole world is now there to find your app through search, through other ways of getting the word out and hopefully start using it. So in this chapter, what we're gonna do is take the app that we built and deploy it. We're gonna put it out on a Linux server, on the Internet. We don't quite go so far as to map the domain name to it because we don't have a domain name. But it's really a, short, short step to go from what we're gonna do in this chapter to actually having a product on the Internet and it's gonna be awesome. Now, here we are in the github repository. Over here, you can see we have a link, cause we don't actually have source code for this chapter because we're not going to deploy the app we built here. In our other FastAPI course we already deployed an application, and it is literally identical to this application. Now, technically, the contents that show on the screen are not the same. I'll show you that, it's right here. We built this weather endpoint. So it's a, whether service or whether API but also you can see right here we've got things like static files, we've got this dynamic template and so on. It's actually exactly the same. If we click on it, it even does some cool API stuff right there. Apparently, it's lightly raining now. We're going to deploy this application and here's the source code with all the config files and stuff that you might want to work with. You can make a very slight adjustment to deploy the app that we're doing here. Given that we did such a polished job deploying that weather application on Ubuntu, out on the Internet, I think it makes most sense for us to go through and look at that example there. The adjustments are incredibly small, but hopefully you'll have a great time putting your web application out on the Internet for all the world to consume.
|
|
|
transcript
|
4:29 |
Now, before we jump into actually see deploying the weather application, I do wanna show you something that can be super, super important. A security issue, if you will, at least usability issue, potentially a security issue for your web application. So let's, let's go over here first and look at whether.talkpython.fm Remember, this is an API endpoint, and it does just arbitrary http exchanges to URLs that are not necessarily obvious. And so to help people consume this API, FastAPI automatically builds a really cool set of documentation. That's not obvious, so if you go to a FastAPI app and you type "/docs", check out what you get. Here's our one endpoint "/api/weather", and if we scroll down, there's all these different things that are exchanged. Like here's a forecast, and the forecast has wind, which is made up of this stuff. Now if we actually go and click on this, it'll let us explore it, to try it out, so we could put in like Portland. We could type in something there, and it shows you what the response is gonna be. Like look down here you have this. Oh, what you're gonna get back, it's gonna have a weather. the description and category, the wind, the units, the forecast and so on. These are the type of errors that you might expect, some kind of validation. Well this is cool, I mean it's really cool for this API, you know what? our web app has this too. Watch this. So we come over here and say "/docs" and look at that. It's every endpoint in our application, now many of these are public, and it's totally fine. But some of them might not be. What if we had a special, supposed to not be public, semi secret admin section? or we had other things that maybe we use, but we don't really want people to know about? You wanna show those here? Do you really want a form that lets people just arbitrarily post stuff over to the registration? Probably not. So there's two things that we can do to make this not show up for our website. It makes sense for an API but it doesn't make sense for a website. So if we come over here, the easiest and quickest thing to do. Remember, there's a ton of options when you create these FastAPI instance. One of them is the docs_url, we can say that's None and the redoc_url, we also say that's None. So this means just turn off the documentation entirely. I want this all to go away. So now if we go back to our site like this and we try "/docs", 404, there are no docs, can not do this, forget it, no docks for you. It could be that the reason you're using FastAPI is, most of this is a website, but there's some really cool APIs and you would still like that cool documentation for the APIs but not for the website. So we can do a slightly less intense thing over here. We can go down to our views and let's say we just want home and about to show up. We want those to be part of our documented API. Of course that doesn't make sense, but let's just say so. What we can do is we can go to these others where we have our router, our app, and we can say include_in_schema is False. That means exclude this endpoint from that docs URL. Let's do that for account as well. Now just put it on every single router.get, router.post. It's getting include_in_schema = False. Remember, our decision was to say, well let's have the packages and account stuff hidden, but let's actually have this part of our endpoint. Now, like I said, doesn't make sense. But if you had special API endpoints like we kind of touched on potentially over there, then this was how you would do it. Let's go back here and try our "/docs" again. And yes, we have docs, but only two. Only the two that we did not exclude. One for getting the "/" and one for getting home slash index, home slash about, the others are gone. But it's really important that if you don't want this HTML views to be listed and shown on your site, I cannot think why you would ever want that. You very unlikely, very unlikely you want that. You want to hide them, either the safest way to do it, is to just blast them out like this. Or if you do have APIs, you wanna be careful about that, then you can go through and just exclude everything you want to be hidden. That's it. Just make sure you address this before you put it on the Internet. Otherwise, you might find people poking around in places you didn't know that they would find
|
|
|
transcript
|
5:49 |
I often get asked: where should I host my web app? my Python web app? People either ask me that after taking one of my courses or they'll ask me how to do that because of the podcast or something along those lines, and I have one answer that I typically give. But I want to talk about the spectrum of the options here because not everyone fits into the same bucket. So at the, probably easiest to get started and certainly easiest to operate, we have these platform as a service type of hosting environments for Python web applications. So Heroku has been hosting many web applications as a platform as a service, and they have great Python support. So what does platform as a service means? It means you'll do something like point, you know, connect Heroku to a GitHub repository, if that repository has a requirements.txt or other Python indicators right at the top, it will automatically determine that it needs to run under Python. You add a file to say here's the execute command, and it'll just go on, create a server, set it up, make sure it runs. You push a new thing to that GitHub repo, you'll grab it, redeploy it with zero downtime, all of those kinds of things. So this is super helpful, but you don't have as much control here, right? You've got to fit into their ecosystem. You want to use a database? Great, you're probably using their hosted database, which is not that cheap, honestly, depends on where that money is coming from and what you're doing. But it's not nearly as cheap is doing it yourself, that's for sure. So Heroku is actually, if you're very unsure about working with things like running and maintaining Linux servers and virtual machines and stuff, Heroku or other platforms as a service are a really good idea to get started. My favorite place for hosting is Digital Ocean, and in fact, at the time of the recording, all of the infrastructure for Talk Python Training runs over at Digital Ocean. We've got about eight servers there, and we do all sorts of interesting things with them to make all of our APIs, our APPS and our web app and whatnot go. Digital Ocean just launched something like a platform as a service that Heroku has, called their app platform. So you might consider using that, Python is definitely supported there. What I use is just their, what they call droplets. This is their virtual machines you can go create. Notice, starting at $5 a month. So for literally $5 a month, we could get this Python FastAPI up and running, no problem. We have a lot of database requirements? Maybe we've gotta add a dedicated database server. If it's very, very lightweight, maybe we could actually put it on the same server. Anyway, it's quite cheap to get started. Linode is also really good, and they're comparable to Digital Ocean in that they have hosting of like these droplets, these virtual machines. They don't call them droplets, but same idea. They also both Digital Ocean and Linode have kubernetes clouds or clusters, if you want to run Docker. I'm not necessarily recommending that, but it's you know, if that's the way you wanna go, they both have great support for that. Also, notice up at the top here, this URL talkpython.fm/linode If you do want to go to Linode, use that and you'll get $20 off, get a $20 credit towards your account. Not gonna change the world and I, it just lets them know that I'm sending people over. I don't actually get paid, this is just part of their sponsorship of the podcast. But, you know, it'll give you guys a little bit off so go ahead and use that if you feel like it. Next up, we've got a couple of the big ones. We've got a AWS. Now, AWS is amazing, I use AWS services for various things, like generating transcripts, the first pass of transcripts for the courses. Delivering some of the video content and things like that. But I don't host my service there. I think AWS is massively complicated and massively expensive. To run that $5 VM we saw over at Digital Ocean or the similar one at Linode, how much does it cost? About %50 - $60 a month for exactly the same thing. Yeah, and the thing is, it's super, super complicated because AWS runs extremely large scale applications, things like Netflix and so on. So all the tooling is really dialed in for these advanced use cases, which means the simple case is not so simple. But there is a simple, simplified version of AWS, if you guys are over there, it's called Amazon Lightsail. And to run that $60 server over a normal AWS, you can get it for $3.50 on lightsail. Go figure, it's very weird the fact that they have these two things, but they do and my theory is that this is a direct response to Digital Ocean and Linode, and it's a very similar and simple way of creating things, so you might consider it. Again, I'm, I'm sticking with Digital Ocean. We also have Microsoft Azure, they let you run web apps as VMs, they let you run web apps as a platform as a service as well. So those are the hosting places that I would first go look at If I was hosting my stuff on the Internet. If I was was trying to take this FastAPI we built, put it somewhere that has good data centers, has good reputations, has good pricing, at least you know, excluding the bare VMs that say AWS and Azure. But the, one of the uniform things about this, all of them,is that they're gonna ultimately run on Linux. So final thing, we're really in this chapter gonna just focus on getting our FastAPI running on an Ubuntu virtual machine in the cloud. We're gonna actually create it on Digital Ocean, but that's just like a few clicks in some web app. And then, you know, you won't even know what server, what host you're on. You're just gonna log into the server remotely and do a bunch of steps. So really, what we're gonna do is figure out where we're gonna run our Ubuntu virtual machine and on the platforms as a service, even when you're not directly interacting with that server, you really are running on some kind of Linux machine the vast majority of the time. So understanding what's going on under the covers is probably a good idea anyway
|
|
|
transcript
|
3:51 |
Here we are inside my Digital Ocean account. Now over, under these projects, we've got Talk Python and then we've got this thing called Playground. If I had already clicked on Talk Python, you'd see we have a whole bunch of servers that are hosting many services and databases and all sorts of stuff going on over there. But this one is just a nice little empty space where I can work, so this should look roughly like what you would have. Now, here's the platform as a service, this Apps thing, but what we're gonna do is just create a droplet, and droplet is, you know, code word for I'm gonna create a virtual machine. So you can see you could create a server based on many different versions of the operating systems, we could do FreeBSD, Fedora, Debian and so on. And then within those you get to pick which version. I recommend, if you go with Ubuntu, you pick an LTS Long Term Support Version. Otherwise, you'll stop getting updates and that won't be fun. We could also go for containers. You can go to this place called the marketplace, and it will let you, like, grab a Word, pre configured WordPress server or whatever. But that's not what we're doing, we're gonna create a distribution, and then you pick, well, what kind of server do you want? I'm gonna pick the $5 server for this one. Now you might think, well, this is a toy server, it's not really gonna be able to do much. But these servers can actually handle a lot. And Python does not put much of a load on these servers. It depends on what you're doing, but this little wimpy server, unless you have got some kind of crazy computation stuff going on, if it's a relatively standard web application, it should be able to handle multiple millions of requests per month. So it's actually a pretty good starting point. The next thing we're gonna pick, we could add an extra hard drive. We don't care about that. You might need that, if you had say, like, tons of data in a database, you'd wanna put that over there. Could make sense. We're not gonna do that. Now, you want to pick a data center that makes the most sense for the consumers of your application. For many of us, that probably means either Europe or the East Coast of the United States. For us, our servers are in New York City. The reason is that's good for all of the United States and North America, it's also pretty good for Europe because it's a straight shot across the ocean, so that covers many of our users. We also have people all over the world, you know, places that are far from there, like Australia, New Zealand, which is not ideal. But we gotta pick one place and just, for us, East Coast of the US made a lot of sense. However, I'm on the West Coast. So just to keep things quick as local, well, we're gonna pick this, right? So you pick the one here that makes the most sense for you. Just be careful, if you're gonna create multiple servers like a web server and a database server and you want them to talk to each other, it's much, much better if they're in the same same data center. We could use VPC, virtual private networking, it's on by default, but we're not gonna do anything with it. Might as well turn on monitoring, this lets us look at the server through some of the management tools here. We're gonna use an ssh key which allows us to just log in, you can just go ahead and type ssh and go and register the ssh key. We won't have any username or password to mess with, gonna to turn them all on. Here's the project it's gonna go into on Playground. You could turn on backups, we're not doing that. So watch how quick this is. Oh, I should have given it a name. Well, be sure to give yours a better name, but I'm gonna leave this going in real time so you can see how long it takes. So I'm not going to cut anything out here. I'll just keep kind of rambling on. It should take usually about 30 seconds. So virtual machine is there. I think it's probably starting right now. Maybe some final startup scripts, for the first time are running and wait for it. That's it. I don't know, what was that, about 30 seconds? We can go back and check, but not very long. And so now we have a virtual machine. Over here, we just click that to copy the IP address. Ultimately, you wanna map a domain name over there. But basically we're done with Digital Ocean, that's it. That was all of the Digital Ocean that we care about.
|
|
|
transcript
|
2:04 |
I wanna say ssh root@ that address. Obviously, you'd probably put some kind of domain name there. But first time it'll say: you have never been here, are you sure you want to exchange your ssh keys with them? Yes, and just like that, we're in. So the very first time you see, like, this warning and whatnot and it says, you know, you really should do "apt update" and then "apt upgrade". This is, check for updates, apt update, and then apt upgrade is apply those updates. And if you've ever put anything on the Internet, you want to know, you know that you need to patch it right away like here. If we log out and then log back in, notice it has 18 security problems. That's not good. So let's go and just upgrade it right now. Oh, and I believe it's like checking for its own updates the first time it came to life. So let's see how long this'll take. Here we go, it was still doing like some background stuff with the upgrade system. Alright, so it should be up to date, or ready to update. When you already see these Linux headers, that means there's a new kernel upgrade as well. Okay, that took a moment, because there's an insane number of updates to apply, but no big deal. Now, if we log out and just log back in, you'll see that a system restart is required. Not always the case when you apply updates that that's true. But when do a kernel upgrade or major things, it is. So we'll just have to reboot. Wait about 5 to 10 seconds, and our machine should be completely up and running and ready for us to configure as our web server. Perfect, so here we have our web server up and running not a web server yet, it's gonna be made into one. But we have our Linux server running on the Internet safely because we've applied the patches. We still need to do things like set up firewall rules and other types of stuff to make it more safe. But it's a good thing to have here running, that we can start working with and configuring, and we'll do that throughout this chapter.
|
|
|
transcript
|
3:18 |
Now that we've got our virtual machine running on the Internet somewhere, in this case up on Digital Ocean, what we're gonna do is talk quickly about what applications and server, services on that server are going to be involved and how they fit together. So this little gray box represents Ubuntu, our server. What we're gonna first install, or first interact with, when we make a request to the server at least really we'll probably start from the inside out. But the first thing that someone coming to the server is gonna interact with is this web server called Nginx. Now Nginx serves HTML and CSS and does the SSL and all those cool things, but it's not actually where our Python code runs. We don't do anything to do with Python there. We just say you talk to all the web browsers, all, to the applications, everything that's trying to get to the web infrastructure. This thing is where they believe they're talking to, and it is what they're talking to. But it's not where, what is happening. That's not where the action is, right? Where the action is, is gonna be in this thing called gunicorn You saw that we used uvicorn, which is the asynchronous loop version of gunicorn to run our FastAPI, but gunicorn is more proper server that is going to do things like manage the lifecycle of the apps running. So, for example, if one of the apps gets stuck and that process freezes up, gunicorn has a way to run in supervisor mode. So it can say, actually that thing is stuck or it ran out of memory, let's restart it so the server doesn't permanently go down, it's just gonna have a little glitch for one user, and then it'll carry on. In order to do that, gunicorn is gonna spin up not one but many copies of our FastAPI application over in uvicorn, which we've already worked with. And this is where our Python code that we write, our FastAPI lives. So when you think of, where does my code run? what is my web app doing? It's gonna be this uvicorn process, and in fact, not one but many. For example, over Talk Python Training, I believe we have eight of these in parallel on one of our servers. So when a request comes in, it's gonna hit nginx, it's gonna do its SSL exchange and all those things that the web browsers do with web servers, nginx is going to realize, oh, this request is actually coming to our FastAPI application. Depending on how we've configured it, it's gonna send a request either over HTTP or Linux sockets directly. gunicorn says okay, well, we've got this request for our application, and there's probably a bunch going in parallel. Which one of these worker processes is not busy and can handle requests? Well, this one. Next time a request comes in, maybe it's this one. Another request comes in, maybe those two are busy and it decides to pick this one. So it's gonna fan out the requests between these worker process processes based on whether or not they're busy and all sorts of stuff. So it's gonna try to even out the load across them, especially it'll know if they're busy and not overwhelm any one of them. So this is what's going to be happening in our server and we're gonna go in reverse. We're gonna install uvicorn and our Python web app, then we're gonna set up gunicorn to run it. And once we get that tested and working inside the app, inside the server on Ubuntu, then we're gonna set up nginx and open it out to the Internet and make this whole process that you see here flow through.
|
|
|
transcript
|
1:10 |
Before we start configuring our server, I wanna set up Oh My Zsh, or Oh My Z shell Now, this is absolutely not required. But I find the ability to go back through history and use frequently commands and adapt them and stuff and just knowing how to work with git, you can see, like in the little screenshot here, the prompt changes based on where you are in a git repository and things like that, just a lot, a lot nicer. So I'm gonna go over here and I'm gonna copy this bit right there because that's how we're going to install it. And let's to reconnect to the server. I renamed the host name because it was driving me crazy. So now it's weatherserver. And in order to install this, I have to say apt install zsh because this is based on Z shell. And then run this, wait for a minute, make it the default. And now we have a little bit of a nicer prompt. The next time we log in, actually gotta log out twice the first time because you log out of z shell, then log out of bash. We'll have this, you see, our little new shell is here. And we'll see maybe some stuff as we go through it. But this is just a nice little step. I find this a much, much nicer way to work with servers. So I encourage you to set this up. Don't have to, but I find it makes life a little bit nicer.
|
|
|
transcript
|
3:37 |
I've copied what we built over in chapter seven into chapter eight and made a few minor changes. And I did this without recording it, because you'll see they're just a bunch of config files we're gonna have to set. Like, for example, here's our nginx config file. We never type that from scratch, we find some example, and we adapt it. So that's what I did, we'll talk about that in a minute. But we also, I also put in here, there's a script that sort of takes us through these steps to set up our servers So we've done our upgrade and patch. We've installed Z shell. Now we're gonna need a few other things in order to further secure our server and to make it ready, to get it ready to run Python. For example, make sure we have the Python3-dev tools so we can install things and so on. So let's go over here and put the build-essential, git, zip, and some other things. Not all of them are required, but they're all useful. Now we have things like git set up. That's cool. Let's set up Python, on Linux when we install Python3, it doesn't necessarily come with pip or with virtual environments. So we're gonna install all three of those now, and just talking about z shell. If I type apt for stuff that I could have done, because I typed sudo, didn't I? So if I type sudo, you can just see it'll only cycle through the sudo stuff as you arrow whereas bash, it just goes through the history and things like that. So there's a bunch of little nice touches. All right, so now we should be able to run Python -V, Python3 -V. There we go, 3.8.5. Now we're gonna do a couple of things here to make the system a little more secure. We're gonna do three things in particular. We're going to set up what's called fail2ban and to do fail2ban, what this is if somebody tries to log in over ssh and they fail either through user name password, which we don't have set up or through ssh keys, if they do that too many times, then they're going to be banned from attempting to log in. So this is a nice little service to avoid sort of dictionary attacks or brute force attacks against logging in. We also want to turn on a firewall. Linux, Ubuntu comes with a firewall, uncomplicated firewall, uwf. And what we wanna do is we wanna say, allow ssh traffic and allow web traffic. So port 80 to start things off on HTTP and 443 to allow SSL HTTPS traffic. Other than that, we won't allow nothing. And when we turn it on, it says, if you have not allowed ssh and you say turn on the firewall, you're never coming back. But luckily, we have. So let's close this and just reconnect to make sure it's fine, it is. An then the other thing is, what is our user? I'm root. Do you think running as root is a good idea? No, not a good idea at all. So we're gonna install, create a new user. A user that doesn't have log in permissions, apiuser and we're going to run our web application that, that way, in case somebody happens to break through and take over our system, they're only gonna be able to do what a apiuser can do, not what root can do, so that's good. We also want to create some log files, locations here and then give that user permissions I think I probably, they must have to exist first. So let's do that. And then we can say give them modify access to where the web app needs to keep its logs. All right, so we're not, we don't have our code on here yet. We don't have the libraries needed to run set up, like Uvicorn or FastAPI But our server is much closer. We've got fail2ban, we've got the firewall running for only the ports we want to explicitly expose, the three. And then we've got our user that is a less privileged user to run our web app as.
|
|
|
transcript
|
4:16 |
Next up, we need to get our source code on the server. Well, guess where the source code is? It's right on GitHub. In fact, it's right here on this public GitHub repository. So what we're gonna do is just clone it. And this is a really good way to get our code over there. You make a change, go into the server, do a "git pull", restart the server. In fact, over at Talk Python Training, we have a certain branch in our GitHub repository called production. And if we push to that branch, we've got some infrastructure that will automatically look at that, get the new version, install the new requirements, restart, you know, take the, one of the servers out of, a load balancing situation, reconfigure it, start it up, then put it back in. Really, really, sweet. So all we've gotta do is push to GitHub and that deploys to our Linux server. We're not gonna go that far because that's fairly involved. So what we're gonna do is just manually do git pulls if we make any changes But that's a really nice way for us to get the source code on the server and keep it up to date. So we're gonna do these two things. Now, I'm gonna clone into app_repo so we don't have some huge long name. There we go. And if we see over app_repo, here's our source code and chapter eight, this is where we're working. Okay, so we've got our source code over here, and you can see we've got all of our files. Now, one thing I do wanna do, we're gonna need to run pip install requirements to set up our requirements. However, I realized I did skip a step. What we want to do is we actually wanna create a virtual environment for our web application, okay? why do we want to do that? Well, when we pip install requirements here, we're changing the server set up. And just like locally, we probably don't really wanna change the server set up. Also, having a virtual environment means if something goes dramatically wrong with your Python set up, you can just erase that virtual environment and recreate it. It's not like something that you've got to reconfigure the server before, so that's a really big advantage. So what we're gonna do is we're gonna create this virtual environment and go back to our chapter eight, here we go. Now we have our virtual environment we can pip install -r requirements.txt And with that done, we should almost, almost be able to run our app. So we should be able to say Python3 main.py and that'll run it, right? But there's a problem, it's a secret, do you remember? Our settings.json is not there. Remember we have our settings template like that, and it says you're gonna need to create a settings.json file with your actual keys. So I'll just nano settings.json. Actually, let's start from our template. And then all we gotta do is, we don't need this. It just says, put your key here. So I'm going to, go and put my key right there and save it. Off course I don't wanna share my key with you, this is where your key goes. So I'm gonna pause the recording and then save this, should be able to run. You do that for your key. So with our virtual environment activated, the requirements installed and the settings.json there, we should now be able to come here and actually run our main. Yes, look at that. How awesome. So uvicorn is running on our server as we hoped. Now, how do I test it? If I test it, I can't test it here because this window is, you know, it's busy, busy running the server. But let's go open up another window here, another terminal, and we can curl that url. Now curl is fine, but there's a really cool library. HTTPie, that is really much nicer for doing this kind of stuff, but look at that. What do we got? Here's our Copyright Talk Python Training. Here's our weather service, our RESTful weather service, right there. So it looks like our service, our server's running. You could even see it process the GET over there. So that is fantastic. We're very, very close. Now we need to find a way to make the system run this, cause you can see when I hit Ctrl + C or if I would have logged out of my terminal, obviously the server stops. That's not good. We just want this to start when that server turns on. When you reboot, it just comes back. It just lives as part of the server. So we need to create a systemd service or daemon over there so that it will run our Python web app. But it's basically working, isn't it?
|
|
|
transcript
|
1:12 |
On the server, it's only purpose is to run this web application. To run this web application, we need to have the virtual environment activated. So what I'm gonna show you is that. Lets ask really which Python3 real quick. So we know where it is, there. Having that directory is gonna help. What I'm gonna propose is that we change our login. So as we log in, it just activates that virtual environment. Otherwise, we do Python stuff, pip and Python and so on. It's gonna work with the system one. We almost never, ever wanna change it. We almost always just want to work with this one virtual environment, so let's just make that the default. So we'd say nano ~/.zshrc, go down to the bottom here and we'll say source that bin, instead of Python, we'll say activate like that. If I exit out and I log back in. Look at this. Yes, that's the right one. If I "pip list", it's all the stuff that we just installed, FastAPI and so on. That's super cool, right? So I totally recommend that you set it up so when you log into your server, it just sets up the environment for that one on web app. If you've got 20 we apps and all sorts of things going on, maybe it doesn't make sense. In this simple world, I think this is the best thing to do.
|
|
|
transcript
|
4:13 |
Now we want our web app to work all the time on this server. And if we try to request it, mmm not running, why? Because I logged out, that's silly. We just want it to be part of the server. And so what we're gonna use is something called a unit file over here, to set up a systemd server. So this is going to tell the system: run this command when you boot, basically. So it says, go to this directory, run this command. And let's, just let me do some line breaks here to make this mean stuff. So it says we're gonna run gunicorn, we're gonna bind to that address. We're gonna run four copies of you uvicorn as workers. I talked about having multiple worker processes where our Python code and our FastAPI code is actually gonna run. So if you want 10, you put 10 there, 4 is fine though. And we're gonna run not WSGI gunicorn stuff, but ASGI uvicorn ones. We're gonna go to the main module and pull out the app api instance that's configured. Tell the process it's called that, make sure that that's the working directory cause sometimes this is little wonky. Set a log file there for access, set the error log file there, then run as the user apiuser. It's a lot, right? But that has to be all one line because it, the way it's issued. So I'm gonna just copy that. Now, you wanna make sure this is going to work before you try to set it up as a system daemon. Okay, so just making sure that line is gonna do something is a good idea, and it doesn't. Why? cause there's no gunicorn. So we've got to go back over here and we've got to install gunicorn, and gunicorn and uvicorn on the server require these two libraries as well. So we're just gonna do those three things. Ah, looks like a pip install wheel would have made that a little bit nicer, but I'll change the script for you all, here we go. Anyway, all those installed slightly, slightly quicker. Now with those set up, let's go and try to run our command here. Run uvicorn this, what happened? Nothing. And that's good, all the output is going to these log files. Okay, so let's just make sure that we can connect over here and now we'll be able to http localhost:8000. Nice. See, for example, color coding, you see the header information, all kinds of good stuff, it's better than curl, but still working. Good. So let's get that to the side for a minute and we get out of here. It looks like it works. One thing that may be helpful sometimes, specially if you're getting errors is if you just try it without the logging. That way you see all the messages right here, and if we go back and do this again, ah you still don't see that, but at least you see the start up process. If something goes wrong, often, you'll see the error right there. Ctrl+C to get out. So it looks like that command is working, that means it's likely going to work if we set it up as a system process instead of just typing it in. So what do we gotta do to do that? We just copy that file over here, like this. And then we say we want to use the system control to try to start the thing called weather. Right now, if we look, not there. If we try this, so this has kicked off the thing as a server in the background, now it's just running. Yes, it works. How cool is that? And you can ask, go up here, you can ask "status", what's it doing? Look, there's four worker processes all running over here, that's great. Now we also want to say: do that when I reboot, not just this one time. It's the way we do that is, we say enable, perfect. And now we could do a test, reboot and just make sure when we get back, things are still hanging together. So give that about 10 seconds, you don't have to do this, it would've been fine, but just, you know, peace of mind to make sure that it really is set. And it's back. Let's do our http localhost Yes, all right. We re booted the server and now our service is running still, so perfect. We've now set up gunicorn and uvicorn to always run our app. But you still can't get to it from the outside. remember it's listening on localhost but this is a huge start. Actually, this is the hardest bit of it all. If we get this working, we're pretty golden.
|
|
|
transcript
|
3:29 |
The last thing we need to do really, is to set up in nginx so you can talk to our web api from the outside. So this is super easy, we're gonna install nginx, I'll go back here and off it goes, it's going to stall a bunch of stuff, nginx is a fantastic front end web server. Do all sorts of cool things with it. Okay, now we're gonna need to, just like before, copy a configuration file over cause that's how this all works. And in order for this to work, what we want to do is we're gonna have a domain name, imagine like weatherapi.talkPython.com or something, but because this is not a real thing with a real domain, it's just a simple demo, I'm gonna just put the IP address here as well, let me actually get the IP address, copy it here. You wouldn't normally do this, probably, but because we don't have a domain name and I don't want to mess with DNS and wait for it to propagate, we're gonna do that. So the thing basically says I'm gonna set up a server to listen on port 80 to the domain and maybe IP addresses. There's a set of static files that live here. So if someone asks for /static, give them files out of that folder, Otherwise, anything else go and proxy_pass over to port 80 on localhost. That means talk to gunicorn, which will fan it out to the uvicorn workers, and that's about it. There's really not a whole lot else going on, but notice this change, we've gotta get this up to the server. Let's go commit that and then push that to GitHub and then we'll go here and we'll cd to our apps/app/repo We'll git pull, you can see our server change there, and then we're pretty much set. We just gotta copy this file, which you might as well copy paste, so you don't get it wrong and then we need to tell it also, we want to remove the default, just nginx's installed file and make it use ours and we're going to tell it to start when the server starts and then we're gonna restart it so it re reads the config files. All those things are good, now if we try http, remember that localhost:80, port 8000. What if we just do local host? This will talk to nginx. Oh oh oh, it's working. So go over here, I need my IP address back. Let's go on the internet and see if this works, fingers crossed. Yes, look at that. Our server is up and running, and all we gotta do is go to the DNS and put a proper domain name there, and we would have our thing fully on the website. Up and running on our Ubuntu to server. So what does it mean to have a domain name? You can just go to wherever your DNS is and tell it that this IP address is where that domain name goes and make sure that that domain name is right here. You can have multiple domain names, like you can have, all right, we could have reports.talkpython.fm, whetherapi.talkpython.fm and so on and so on. Whatever ones you wanna point to the server, as long as there in there, the rest will just flow through the system. So super cool, we got this working. Let's just check that our API does its thing. Yeah, we went out to OpenWeatherMap, we've got it, put it here. Now, of course, it's using this caching. Let's actually do an inspect element, look at the network, make a call again, look at that, 45 milliseconds, 39 milliseconds. That's all the way to the server across the Internet, down to San Francisco or wherever it was and we picked it. Very, very cool, so our job here is basically done.
|
|
|
transcript
|
2:05 |
Alright. Final, final thing. Notice this up here says the connection is not secure. That's weird. So browsers these days and Google and so on are making sure that we have HTTPS for almost everything. And if they're not, they're not secure. Even if this was a domain name, would not be happy. So how do we do that? Do we go and buy an SSL certificate? That's so 2 years ago, now we wouldn't do that. So what we would do is we would go over here and we would add this repository like this over here. And once we've done that, we're going to install Python-certbot-nginx. So this is gonna use Let's Encrypt. Python3 yeah, okay, good, beautiful. And I'll update that as well here for you. And then we would just run certbot --nginx like that for this domain. And it's gonna look and says, great, what's your email address? I'm michael@talkPython7.com I'm gonna put a little thing here so it doesn't actually email me or contact me, because this is not really gonna work. And it says: do you accept the terms? We do accept the terms, I don't want to share that cause it's fake, so it's gonna try to go get a certificate, but it's gonna fail. Why did it fail? Cause it said, alright, great, you want to set up a certificate for weatherapi.talkPython.com, is the place I'm running on where that URL, over that, resolves to. Like, am I actually on the weatherapi.talkPython.com server? No, because that domain doesn't go anywhere. But if I had pointed it here and waited for the DNS to resolve, this would just automatically install SSL on server and it would just keep it up to date. Beautiful, so that's all we gotta do to make SSL work. But of course, it requires this DNS thing so you can't create fake servers elsewhere and so on. Not gonna actually go through this step by doing the DNS, but it's super simple to follow. There's a few questions about whether or not you want to redirect if somebody hits the non SSL one, say yes. So this is a really beautiful, free an automatic way to keep an up to date SSL certificate on your web server
|
|
|
|
16:21 |
|
|
transcript
|
1:13 |
Well, we've come to the end of the course and congratulations on making it this far Hopefully, you've worked through building the application along with me as we've worked through all the different chapters and the different technologies. So it's time to bring it home. You're now ready to build production grade apps, not just APIs but full on web applications with FastAPI. And let me just reiterate, the reason I think that's super valuable here. Sure, there are many web frameworks, and FastAPI is a great API framework, but you often want to have both. There's often some web UI component to your app and an API. You don't wanna have those things be separate. You wanna have the ability to use the same framework. So if we build our web applications with FastAPI instead of like, say, the foundation like Starlette or a completely different framework like Django, we have this ability to seamlessly move between them. And I think that is super, super, powerful. FastAPI is such a great framework that it actually makes one of the best web application, the dynamic HTML side of the web, really, really nice as well. So I think you're gonna get a lot out of this. And during this chapter, we're going to go through all the different topics that we've covered during this course and just do a quick review of what you've learned.
|
|
|
transcript
|
2:23 |
The first major thing that we covered was, how do we get started with FastAPI? Let's build the absolute most minimalistic web application, not just API endpoint, but web application with FastAPI. And the fact that it fits in that square grey box that we're about to light up, that tells you, it's not too complicated, is it? So we're gonna need two things to get started. We've gotta import fastapi so we can use it. And then, in order to run the application created with FastAPI, we need a web server. So we're gonna use uvicorn, which is a fantastic, production grade, ASGI, Asynchronous Web Service Gateway Interface Server. We start by creating an app instance from the FastAPI, our FastAPI instance. I'm calling it app here, sometimes it's called api, sometimes it's called app. Doesn't really matter as long as you're consistent. Then we define a function that's gonna be called for a given URL when we request it with a web browser. So we say app.get("/"). That means if we do a basic normal HTTP request against the, just the server. This is what's going to run, not a POST or other HTTP verbs, just a GET standard web request. And then, in here, we're going to generate a message very, very simple in this case, we just have a header that says "Hello web!". Now remember, if we return just the string by itself, return "<h1>..." and so on, FastAPI is an API framework first, with this ability to do HTML second. So if we did it that way, we would get a JSONResponse, which has a string "Hello, web!". That's not at all what we want. We wanna have a web page, not an API response, right? So we're gonna use one of the specialized responses, it really comes from Starlette, but we'll find that under fastapi.responses.htmlResponse. Doing it this way, we tell the web browser what you're getting back is a web page, not some JSON data exchange. This is gonna be our home page here. Not very impressive as you saw it when we got started, but we built on it throughout the course, and then finally, in order to run our application, unlike Flask, you can't say app.run(). Instead, you say uvicorn.run(), and then, if you'd like, you can specify the host and the port. The port defaults to 8000. The host, I believe, defaults to 0.0.0.0 or listen on the Internet. Not a big fan of that, so I'll just listen on localhost here.
|
|
|
transcript
|
1:59 |
While returning the string "<h1>Hello web!</h1>" from our API method, our view endpoint there was fun, it is not at all the way we should be building web applications. What we should be doing is getting a standalone, dedicated HTML template language to generate dynamic HTML from the data our web app provides it, and then turning that into proper HTML with all the cool stuff, like global shared layout pages and little smaller, customized, specialized pages that just fill in the holes about what's unique for each page We also looked at three possible candidates to solve this problem. Jinja2, Mako, and Chameleon. Now Jinja2 is sort of built-in, sort of built-in to FastAPI. It's not entirely built-in cause you've got to install Jinja2 in order to use it, but there are some capabilities in there. Chameleon, not at all, but we went through the different languages and we said, well, what are the advantages and disadvantages of each? And I said, I'm going to use Chameleon because I believe, at least for the things that I value most, it is the best template language. Remember, you don't get to write arbitrary Python, which some people see as a disadvantage. But I see that as a way to enforce you to write better factored code and to put that code not in your template, but somewhere better where it belongs. Also, the templates are proper HTML, like this thing you see here. This is valid HTML with, with some weird attributes that .gitignored. But that's OK for HTML, as opposed to Jinja, which has all these begin end blocks and little funky segments that are not valid HTML. So for that reason, I said, hey, I think this is the one we're going to use. We used it, we used my fastapi-chameleon decorator in order to make this incredibly easy to use. If you don't like Chameleon, again, there's the fastapi-jinja template that is almost exactly the same thing, but for Jinja2, so you can just use that one as well. Those are really the two best choices, I think. I definitely prefer Chameleon so here we go and you can choose whichever one you like.
|
|
|
transcript
|
2:17 |
Our next major area that we focused on were two design patterns, view models for the most part, and we also touched on this one that I was calling services, not web services or APIs, just services to the general larger application. And I think the view model pattern is worth focusing on a little bit here in the review. Remember, with the view model pattern, it plays a lot of the same roles that maybe Pydantic models do for the API endpoint. Because Pydantic and FastAPI go so well together, it makes sense that maybe we should just be using Pydantic models for this type of exchange here but the problem is that Pydantic models, while fantastic, they completely just give up if they run into a problem. And we saw, one of the really important things was, I'd like to be able to show a form, let people type into that form, try to submit it, if that doesn't work, I need to reload the form with the old data. Well, that's not how the Pydantic models work. They just say you gave me something wrong, go away. And so for that reason, we have, a more forgiving pattern that is also quite similar, but a little more manual called view models. The idea is, there's a known set of data and data types and rules for validation for an HTML template, the white thing here on the left. And so let's create a Python class that knows about all that required data, how to get it from the page, how to convert it, how to exchange it, what this validation rules are and completely separate that from the rest of the behavior. So, for example, if our action method here was to register, create a new user. We shouldn't have to worry about all that validation. We should just be able to go: is it valid? No, tell them to try again. Is it valid? Yes, then create the user with the data that we got, send them a welcome email, put them in the database, all the things that you would expect to do, the actual business of this endpoint this view or action method rather than all that validation and data exchange and conversion. So that's the idea of these view models, I think they're super, super valuable in web applications. They make things like testing, the validation, all by itself without getting into web testing and fake requests and all that kind of stuff really, really easy. So this view model, I think it's a great pattern. Take it or leave it. But I suggest that you try it in your apps, I think it's highly valuable.
|
|
|
transcript
|
1:55 |
The next thing that we looked at was, how do we get users to register or log in to the website? We talked about a lot of interesting things like, how should we structure our User class? And what kind of validation should we have? And how do we store it with things like passlib and so on? But one of the important takeaways, the more broad lesson from that chapter really was about: How do I create an HTML form that I let the user type into, with validation that they can then submit back to the site? The starting point for that was understanding we're probably best off using this GET > POST > Redirect pattern, and it's incredibly easy to do in FastAPI. So we're gonna set up a page that we GET, that's the empty form, we're gonna fill it out like, hey, click here to register for the site and the empty form fills up, shows up. We fill it out by editing it locally, and then we want to save it. Now, assuming that we passed all the local validation like the HTML5 required and is an email and so on, we're gonna submit that through an HTTP POST, that's how forms are submitted to a different method in our website. we put the @app.get() on the first one, we put @app.post() on the second one, even though they have the same URL. Over there we used our view model to validate and convert our data, if everything worked, we saved that back to the database, and then we issue a 302 Redirect. Remember, with FastAPI, a regular redirect keeps the POST behavior, the POST verb flowing. So we wanted to issue a 302, it's over here, go do a GET request to that, which was the more standard web behavior that you would expect. If this didn't work, we just have the view model return the data that they had entered back to the form by returning the dictionary with the same template. Easy as it can be. This is the way almost every HTML form, that's not some kind of JavaScript single page app driven type of thing, this is how it works and how it's easiest to implement in FastAPI.
|
|
|
transcript
|
1:59 |
The next major area we focused on was to actually start saving all of this data to the database. Remember, we had taken the top 100 packages, and once we were able to save stuff to the database, we imported those there. We started having our users actually saved in the database when they registered and then validated from the database when they logged in and so on. So a couple of things that we did there for those models was we created this declarative_base. So sqlalchemy, extensions, declarative, declarative_base. And this is really just a class, as if you type the word class space something, but it's more dynamically generated. And the idea is: Everything that derives from this class will be a table that is managed by SQLAlchemy. You have Package, Release and User because they all three derived from this particular instance of this base class, this particular type we created here. It means that when we go to that base class and say, create all your tables or you have relationships or things like that, all those tables are gonna be related and created through that one action. And it's all this base class, the SqlAlchemyBase class, that makes that happen. And then, for each one of these classes, in this case Package, we're going to do a couple of things. We define a dunder table name and then we're gonna give it some columns that are also fields in our classes, so an id, in this case we're gonna say this is an integer, it's autoincrementing, and it's a primary key, so we don't have to set it, just as we insert stuff in the database, it will automatically get this primary key set appropriately and uniquely from the database. Then we'll have a summary, which is a string, a size which is an integer, a home_page, which is a string. We even saw we can set up really cool relationships like for example, this package has a bunch of releases. So instead of doing additional database queries manually, we're just gonna set up the relationship. And if we interact with the releases collection, it's automatically going to get that from the database, either because we've done a join ahead of time knowing that's gonna happen or through a lazy loading thing, and it'll go back to the database and get that data if we need it.
|
|
|
transcript
|
2:10 |
We saw that to truly unlock FastAPI's massive, massive scalability and performance, we have to make our view methods, our endpoints async because when you have a web application, most of the time, what is it doing? Its waiting on external things. It's waiting on a queue, it's waiting on a database, it's waiting on some microservice or external third party service. All of that waiting can be completely put aside and allow your app to do other work, maybe start other things that then in turn, run awaits on those, right? So most of a request is actually made up of waiting. And if we have a synchronous web server like Flask, like much of Django, like Pyramid and so on, the traditional WSGI applications, they don't have this capability. So when a request comes in, well, the first one gets processed right away, and it takes as long as the expected time, the green one. But because the server's busy, until we get done with Response 1 we can't start with 2, it actually takes quite a bit longer and poor old fast little Response 3, it's queued up, put behind in the line here for those two requests So even though it's short, it actually takes the longest of all three of these. We dive in, we see the problem really is that we're mostly just waiting on other stuff, we're like 80% weighting, 20% doing something computational on our end. If we just rewrite this to say await database query, await web service call and make our view methods async, FastAPI will completely rework how it runs our code, and it will process Request 2 while it's waiting on the database for 1. And then it will be waiting on the database for 1 and 2 so it can zip over, get Request 3 done really quick and then get back to waiting for the others. And it really, really amplifies the scalability. Now the scalability, of course, depends on the scalability of the thing on the other end, right? If you have a database and the actual roadblock, was the database is really wimpy or it's poorly written without indexes or something like that, eventually you're gonna hit a limit where just further down the line, you're waiting on something else, and it won't make it that much better. But in a lot of cases where you have a fast database or external APIs or many different services, this is gonna see a huge improvement for your app.
|
|
|
transcript
|
2:00 |
After we were happy with our app and we got it built and running, it was time to put it on the Internet, and we decided Nginx plus Gunicorn would be a great way to deploy our FastAPI web application. Nginx is by far one of the most popular front end web servers that handles things like static files, it handles SSL, and you know, upgrades requests to things like HTTP2, all sorts of cool stuff that's happening over there. It will be the front line server that our clients actually talk to. But when it comes to running, our Python code, our FastAPI code, we're gonna do that, managed by Gunicorn. We already saw that Uvicorn, which comes from Gunicorn, is how we were, we've been running our app so far, and we're gonna continue to use that in production, but not just by running it, but by having a bunch of them that Gunicorn can manage. So it's gonna spin off 5, 10, who knows how many makes the most sense for your server and the number of requests you're getting, but multiple numbers of your process as if you had started it just on the command line multiple times. And then when a request comes in, Nginx is gonna figure out where it goes. If it's a Python request, it hits Gunicorn and says, hey, drive one of these Uvicorn worker processes that's not busy. Well, this one, it's not busy, it can handle a request. Another request comes in, says here, this one's not busy this time. Now then maybe those two are busy, another request comes in, it picks this other one this next time. And this is generally how our web application works. We saw that setting up Gunicorn to run, we had a special config file to do that as a systemd service. And then we have a special config file to set up Nginx, and then we also had a whole script to actually build out the Ubuntu server just the way we wanted it. It might be a lot to take in at the beginning, but if you go through it a few times, you'll figure out what the important parts are to pay attention to, and the rest, you'll just copy and paste; and remember, this script goes there and then we're good to go. Not too bad. So good luck running your app in production.
|
|
|
transcript
|
0:25 |
Well, that's it. You've come to the end of the course. Thank you. Thank you. Thank you for taking this course, for spending this time together. I hope you really learned a lot. I hope you enjoyed it. And most importantly, I hope you built something awesome. If you did, and you get it out on the Internet, be sure to shoot me a message. I'm @mkennedy over on Twitter, or you can find me through the Talk Python sites in a couple of ways. So thank you for taking this course and best of luck on your project.
|
|
|
|
54:50 |
|
|
transcript
|
4:07 |
One of the absolute pillars of web applications are their data access and database systems. So we're going to talk about something called SQLAlchemy and in many, many relational based web applications this is your programming layer to talk to your database. SQLAlchemy allows you to simply change the connection string and it will adapt itself into entirely different databases. When you use a local file and SQLite for development maybe MySQL for testing and Postgres for production I'm not really sure why you would mix those last two but if you wanted to, you could with SQLAlchemy and not change your code at all just simply change the connection string. So SQLAlchemy is one of the most well known most popular and most powerful data access layers in Python. SQLAlchemy, of course is open source you'll find it over at sqlalchemy.org. It was created by Mike Bayer and his site is really good. It has tutorials and walkthroughs for the various which you can work with SQLAlchemy one for the object relational mapper one for more direct data access, things like that. So why might you want to use SQLAlchemy? Well, there's a bunch of reasons. First of all, it does provide an ORM or Object Relational Mapper but it's not required. Sometimes you want to programming classes and monitor your data that way but other times you want to just do more set based operations in direct SQL. So SQLAlchemy lets you work in a lower level programming data language that is not truly raw SQL so it can still adapt to the various different types of databases. It's mature and it's very fast it's been around for over 10 years some of the really hot spots are written in C so it's not some brand new thing it's been truly tested and is highly tuned. It's DBA approved, who wouldn't want that? What that mean is, by default SQLAlchemy will generate SQL statements based on the way you interact with the classes. But you can actually swap out those with hand optimized statements. So if the DBA says well, there's no way we're going to run this all the time you can actually change how some of the SQL is generated and run. Well, the ORM is not required I recommend it for about 80%, 90% of the cases. It makes programming much simpler, more straightforward and it much better matches the way you think about data in your Python application rather than how it's normalized in the database so it has a really, really nice ORM or lots of features and this is what we're going to be focusing on in this course. I'll also use this as the unit of work design pattern and so that concept is I create a unit of work I make, insert updates, delete, etc. all of those within a transaction basically and then at the end, I can either commit or not commit all of those changes at once. Cause this is an opposition to the other style which is called active record, where you work with every individual piece of data separately and it doesn't commit all at once. There's a lot of different databases supported so SQLite, Postgres, MySQL Microsoft SQL Server, etcetera, etcetera. There's lots of different database support. And finally, one of the problems that we can hit with ORMs is through relationships. Maybe I have a package and the package has releases. So I do one query to get a list of packages and I also want to know about the releases. So every one of those package when I touch their releases relationship, it will actually go back to the database and do another query. So if I get 20 packages back, I might do 21 overall database operations separately. That's super bad for performance. So you can do eager loading and have SQLAlchemy do just one single operation in the database that is effectively adjoined or something like that that brings all that data back. So if you know that you're going to work with the relationships ahead of time you can tell SQLAlchemy, I'm going to be going back to get these so also load that relationship. And these are just some of the reasons you want to use SQLAlchemy.
|
|
|
transcript
|
1:35 |
When you choose a framework whether that's for a database or a web framework it's good to know that you're in good company and that other companies and products have already tested this and looked around and decided Yep, SQLAlchemy is a great choice. So let's look at some of the popular deployments. Dropbox is a user of SQLAlchemy and Dropbox is one of the most significant Python shops out there. Guido van Rossum and some of the other core developers work there and almost everything they do is in Python. So the fact that they use SQLAlchemy that's a very high vote of confidence. Uber. Uber uses SQLAlchemy. Reddit. Reddit's interesting in that they don't use the ORM but in fact they use only the core. At least, wow, hey we're using only the core aspect of SQLAlchemy, that's pretty cool. Firefox, Mozilla, more properly is using SQLAlchemy. OpenStack makes heavy use of SQLAlchemy. FreshBooks, the accounting software based on, you guessed it, SQLAlchemy! We've got Hulu, Yelp, TriMet, that's the public transit authority for all of Portland, Oregon. The trains, the buses and things like that so they use that as well. So here are just a couple of the companies and products that use SQLAlchemy. There's some really high pressure some of these are under. You know if it's working for them it's going to work well for you, especially Reddit. Reddit gets a crazy amount of traffic, so pretty interesting that they're all using it and we'll see why in a little bit.
|
|
|
transcript
|
2:14 |
Before we actually start writing code for SQLAlchemy, let's get a quick 50,000 foot view by looking at the overall architecture. So when we think of SQLAlchemy there's really three layers. First of all, it's build upon Python's DB-API. So this is a standard API, actually it's DB-API 2.0 these days, but we don't have that version here. This is defined by PEP 249 and it defines a way that Python can talk to different types of databases using the same API. So SQLAlchemy doesn't try to reinvent that they just build upon this. But there's two layers of SQLAlchemy. There's a SQLAlchemy core, which defines schemas and types. A SQL expression language, that is a kind of generic query language that can be transformed into a dialect that the different databases speak. There's an engine, which manages things like the connection and connection pooling, and actually which dialect to use. You may not be aware, but the SQL query language that used to talk to Microsoft SQL server is not the same that used to talk to Oracle it's not the same that used to talk to Postgre. They all have slight little variations that make them different, and that can make it hard to change between database engines. But, SQLAlchemy does that adaptation for us using its core layer. So if you want to do SQL-like programming and work mainly in set operations well here you go, you can just use the core and that's a little bit faster and a little bit closer to the metal. You'll find most people, though when they're working with SQLAlchemy it will be using what's called an Object Relational Mapper, object being classes relational, database, and going between them. So what you do is you define classes and you define fields and properties on them and those are mapped, transformed into the database using SQLAlchemy and its mapper here. So what we're going to do is we're going to define a bunch of classes that model our database things like packages, releases users, maintainers and so on in SQLAlchemy and then SQLAlchemy will actually create the database the database schema, everything and we're just going to talk to SQLAlchemy. It'll be a thing of beauty.
|
|
|
transcript
|
3:10 |
When you're trying to model something like PyPI a website with a database the clearer of a picture you have the better you're going to be. So let's look around this running, finished version. Remember this is not even though it looks very much like what we built this one is actually the finished one that we're going to be sort of be aiming for. Alright, now we're not going to look at the code but we'll poke around what the web looks like and we could just as well look at the real one but let's look at this. So on any given package this is pulling up the package AMQP and apparently that's a low level AMQP client for Python. Okay, great, actually I've never used this. We have a couple of things going on here. We have the name of the package, the version bunch of different versions actually a description, right here. We actually have a release history so each package has potentially multiple releases. You can see this one had many different releases and we can pull up the details about different ones. Jump back there. We have downloads, we have information like the homepage. So, right over here we can go to GitHub apparently that has to do with Celery. We could pull up some statistics about it. It has a license, it has an author. So remember, up here we have a login and register so we could actually go login to the site or create an account just as a regular user and then we could decide as Barry Pederson apparently did, to just publish a package. And then there's a relationship between that user and this package as a maintainer and it's probably a normalization table. We also have a license, BSD in this case. If we want to model this situation in a relational database let's see how we do that. PyCharm has some pretty sweet tooling around visualizing database structure. So, here we're going to have a package and it's going to have things like a summary and a description and a homepage license, keywords, things like that. It has an author, but it's also potentially has other maintainers. So we have our users, name, email, password things like that. And then I don't have the relationship drawn in this diagram but there'll be a relationship between the user id and the user id and the package id and the package id there. So this is what's often referred to as a normalization table for many-to-many relationships so that's one part. And then the package, remember, it has releases. So here, each release has an id it has a major/minor build version a date, comments, ways to download that different sizes as it changes over time. We also have licenses, that relate back there and we have languages. So here, this is going to relate back say to that id right there. Finally, we're not going to track any of this but there actually are download statistics about this about downloading all these packages and the different releases and so on so we went ahead and threw that in there. So this is what we're going to try to build but we're not going to build it in the database. We're going to build it in SQLAlchemy and SQLAlchemy will maintain the database for us. Think the place to get started is packages so let's go on and do that.
|
|
|
transcript
|
8:31 |
Let's start writing some code for our SQLAlchemy data model. And as usual, we're starting in the final here's a copy of what we're starting with. This is the same right now, but we'll be evolved to whatever the final code is. So, I've already set this up in PyCharm and we can just open it up. So, the one thing I like to do is have all my data models and all the SQLAlchemy stuff in its own little folder, here. So, let's go and add a new directory called data. Now, there's two or three things we have to do to actually get started with SQLAlchemy. We need to set up the connection to the database and talk about what type of database is it. Is it Postgres, is a SQLite, is it Microsoft SQL Server? Things like that. We need to model our classes which map Python classes into the tables, right, basically create and map the data over to the tables. And then, we also need a base class that's going to wire all that stuff together. So, the way it works is we create a base class everything that derived from a particular base class gets mapped particular database. You could have multiple base classes, multiple connections and so on through that mechanism. Now, conceptually, the best place to start I think is to model the classes. It's not actually the first thing that happens in sort of an execution style. What happens first when we run the code but, it's conceptually what we want. So, let's go over here, and model package. Do you want to create a package class Package? Now, for this to actually work we're going to need some base class, here. But, I don't want to really focus on that just yet we'll get to that in a moment. Let's stay focused on just this idea of modeling data in a class with SQLAlchemy that then maps to a database table. So, the way it works is we're going to have fields here and this is going to be like an int or a string. You will have a created_date which, is going to be a datetime. We might have a description, which is a string, and so on. Now, we don't actually set them to integers. Instead, what we're going to set them to our descriptors that come from SQLAlchemy. Those will have two distinct purposes. One, define what the database schema is. So, we're going to set up some kind of column information with type equals integer or something like that. And SQLAlchemy will use that to generate the database schema. But at runtime, this will just be an integer and the creator date will just be a datetime, and so on. So, there's kind of this dual role thing going on with the type definition here. We're going to start by importing SQLAlchemy. And notice that that is turning red and PyCharm says, "you need to install this", and so on. Let's go make this little more formal and put SQLAlchemy down here's a thing and PyCharms like "whoa, you also have to install it here". So, go ahead and let it do that. Well, that looks like it worked really well. And if we go back here, everything should be good. Now, one common thing you'll see people do is import sqlalchemy as sa because you say, "SQLAlchemy" a lot. Either they'll do that or they'll just from SQLAlchemy import either * or all the stuff they need. I preferred have a little namespace. So, we're going to do, we want to come here and say sa.Column. And then, we have to say what type. So, what I had written there would have been an integer. And we can do things like say this is the primary_key, true. And if it's an integer you can even say auto_increment, true which, is pretty cool. That way, it's just automatically managed in the database you don't have to set it or manage it or anything like that. However, I'm going to take this away because of what we actually want to do is use this as a string. Think about the packages in PyPI. They cannot have conflicting names. You can't have two separate packages with the name Flask. You can have two distinct packages with the name SQLAlchemy. This has to be globally unique. That sounds a lot like a primary key, doesn't it? Let's just make the name itself be the primary key. And then over here, we're going to do something similar say, column, and that's going to be sa.DateTime. I always like to know almost any database table I have I like to know when was something inserted. When was it created? That way you can show new packages show me the things created this week or whatever order them by created descending, who knows. Now, we're actually going to do more with these columns, here. But, let's just get the first pass basic model in place. Well, it's going to have a summary. It's going to be sa.Column(sa.String we'll have a summary, also a description. We're also going to have a homepage. Sometimes this will be just the GitHub page. Sometimes it's a read the docs page, you never know but, something like that. We'll also have a docs page or let's say a docs_url. And some of the packages have a package_url. This is just stuff I got from looking at the PyPI site. So, let's review real quick for over here on say SQLAlchemy here's the name. And then what, we're going to have versions that's tied back to the releases, and so on. Here's the project description we have maybe the homepage we'll also have things like who's the maintainers what license does it have, and so on. So, let's keep going. Now, here's the summary, by the way and then, this is the description. Okay, so this stuff is all coming together pretty well. Notice over here, we have an author, who is Mike Bayer and we have maintainers, also Mike Bayer, right there and some other person. So, we have this concept of the primary author who may not even be a maintainer anymore and then maintainers. So, we're going to do a little bit of a mixture. I'm going to say, author name it's going to be one of these strings just embed this in here and it will do email so, we can kind of keep that even if they delete their account. And then later, we're going to have maintainers and we're also going to have releases. These two things I don't want to talk about yet because they involve relationships and navigating hierarchies, and all that kind of stuff we're going to focus on that as a separate topic. The last thing we want to do is have a license, here. And for the license we want to link back to a rich license object. However, we don't necessarily want to have to do a join on some integer id to get back just the name to show it there. It would be cool if we could use somehow use this trick. And actually, we can, we can make the name of the license the friendly name, be just the id, right. You would not have two MIT licenses. So, we'll just say this is an sa.Column(sa.String which, is an Sa.string. That's cool, right, okay, so here is our first pass at creating a package. So, I think this is pretty good. It models pretty accurately what you see over here on PyPI. There's a few things that we're omitting like metadata and so on, but it's going to be good enough for demo app. A couple more things before we move on here. One, if I go and interact with this and try to save it into create one of these packages and save it into the database with SQLAlchemy, a couple of things. One, it needs a base class. We're going to do that next. But, it's going to create a table called Package which is singular. Now, this should be singular, this class it represents a single one of the packages in the database when you work with it in Python but, in the database, the table represents many packages all of them, in fact. So, let's go over here and use a little invention in SQLAlchemy to change that table name but, not the class name. So, we'll come down here and say __tablename__ = 'packages', like so So, if we say it's packages that's what the database is going to be called. And we can always tell PyCharm that, that's spelled correctly. The other thing to do when we're doing a little bit of debugging or we get a set of results back in Python, not in the database and we just get like a list or we want to look at it it's really nice to actually see a little bit more information in the debugger than just package, package, package at address, address, address. So, we can control that by having a __repr__ and just returning some string here like package such and such like this. I'll say self.id. So, you know, if we get back, Flask and SQLAlchemy we'd say, angle bracket package Flask angle bracket package SQLAlchemy. So, that's going to make our debugging life a little bit easier as we go through this app. Alright, so not finished yet but, here's a really nice first pass at modeling packages.
|
|
|
transcript
|
1:51 |
Νow we defined our package class we saw that it's not really going to work or at least I told you it's not going to work unless we have a base class. So what we're going to to, is going to define another Python file here and this is going to seem a little bit silly to have such small amount of code in its own file but it really helps break circular dependencies so totally worth it. When I create a file here called model base. And you would think if we're going to create a class it would be something like this, SQLAlchemyBase. Then we would do stuff here right? That's typically how you create a class. But it's not the only way and it's not the way that SQLAlchemy uses. So what SQLAlchemy does is it uses a factory method to at run time, generate these base classes. We can have more than one. We can have a standard one. We can have a analytics database one. All sorts of stuff. So you can have one of these base classes for each database you want to target. And then factor out what classes go to what database based on like maybe the core database or analytics by driving from these different classes. We don't need to do that. We're just going to have the one. But it's totally reasonable. So let's go over here and say import sqlalchemy.ext.declarative as dec add something shorter than that. And then down here instead of saying the class then we say the dec.declarative_base(). That's it, do a little clean up, and we are done. Here's our base class and now we can associate that with a database connection and these classes. So we just come over here in the easiest way and PyCharm is just to put it here and say Yes, you can import that at the top. So it adds that line rewrite there, and that's it. This class is ready to be saved to the database. We have to configure SQLAlchemyBase itself a little bit more. But package, it's ready to roll.
|
|
|
transcript
|
6:01 |
Before we can interact with our packages and query any or save them to the database or anything like that, we're going to need to well, connect to the database. And a lot of the connections and interactions with the database in SQLAlchemy they operate around this concept of the unit of work. Construct inside SQLAlchemy that represents the unit of work is called a session and it internally manages the connection. So with that in mind, let's go and add a new Python file called db_session.py. So in this file, we're going to get all the stuff set up so that you can ask it for one of these sessions and commit or rollback the session and so on. So we need to create two basic things. We need a factory, and I'll just say None for the moment and we need an engine. Now the engine I don't believe we need to share but this factory we're going to need to somehow keep this around right this is kind of we'll use the engine to get the factory and so on. So let's go and let's create a little function here called global_init(db_file: str) and we're going to use SQLite. It's the simplest of all the databases that are actual relational, you don't have to set up a server, it just works with a file but it's a proper relational database. The way we do that is we pass in a db_file which is a string. So what we want to do is work with this and see if, this has been called before we don't need to run it twice so we'll do something like this. We'll say first let's just make sure that's global factory - we'll say if factory: return. No need to call it twice, right? But, if it hasn't been called let's do maybe some validation here. We'll say if not db_file or not db_file.strip() it'll raise some kind of exception here, like right, something pretty obvious. You have to pass as a database file otherwise we can't work with it. Then we're going to get an engine here. The way we get the engine is from SQLAlchemy so we're going to have to import sqlalchemy. Maybe we'll stick with this as sa so here we just say sa.create_engine. Super simple. Notice the signature here though *args, **kwargs". I utterly hate this pattern it means, you can pass anything and we're not going to help you or tell you what could possibly go in there. In fact, there is a known set of things you can pass in here, so they should just be keyword arguments. Well, anyway, that's the way it goes. So, we're going to pass a couple of things. We need to come up with a connection string and when you're working with SQLAlchemy what you do is you specify the database schema or the type of database that's part of the connection string. So we'll say sqlite:/// and then we just add on the DB file like this. Maybe just to be safe we'll say "strip", just in case. That seems like that's a pretty good one and then here we'll just pass the connection string as a positional parameter, and then we also may want to set this, so I'll go ahead and like prime the pump for you. I'll say "echo=false". If you want to see what SQLAlchemy is doing what queries it's sending, what table create statements it's sending, stuff like that you set this to "true", all the SQL commands sent to the database are also echoed out both just standard out, and standard error, I believe. But I'm not going to show that, but just having this here so you know you can flip that and really see what's going on here. So we're going to set the factory here but what we need is we actually need import sqlalchemy.orm as orm So we come in here and we say orm.sessionmaker session... maker. So this is a little bit funky, but you call this function and it creates a callable which itself when you call it, will create these units of work or these sessions. So we got this little bit of a funky thing going on here, but then we also come in here and we say "bind=engine". So when the session is created it's going to use the engine which knows the database type and the database connection, and all that kind of stuff. And that's pretty much it! We're going to use this factory after everything's been initialized. We're actually going to do a couple of iterations on this file to make it a little bit better and better as we go, but let's not get ahead of ourselves. I think this pretty much does it so let's go ahead and call this over here. Let's go - here we are, register_blueprints like, setup_db(), let's have just a function down here... So let's go ahead and create a data folder not a data data, but a DB folder. In here is where we're going to put our database file. So what we need to do is work with the OS module and we're going to actually figure out where this is. So we want to say "durname", "pathoutdurname" and we're going to give it the dunder file for apps. So that's going to be the directory that we're working in so right now we're this one, and then we need to join it with DB and some file name. Let's say "DBFile" it's going to be "OS.path.join" this directory with "db" with some database file. Let's just call it "pypi.sqlite". The extension doesn't matter but, you know maybe it'll kind of tell you what's going on there. And then we can just go up here. import pypi_org.data.db_session as db_session and come down here and just call our global_init(). Pass the db_file, and that's it we should be golden. Let's go ahead and run it just to make sure everything's hanging together. Ha ha, it did, it worked! Off it goes. There it is up and running. Super super cool. Did anything happen here? Probably not yet, no, nothing yet. But pretty soon when we ask SQLAlchemy to do something, like even just verify that the tables are there, you'll see SQLite will automatically create a file there for us. Okay, great, looks like our database connection is all set up and ready to go.
|
|
|
transcript
|
6:26 |
Well, we've got our connection set we've got our model, at least for the package, all set up we've got our base class. Let's go ahead and create the tables. Now, notice we've got no database here even though over in our db.session we've talked to the database. We haven't actually asked SQLAlchemy to do any interaction with it, so nothing's happened. One way we could create the tables is we could create a file, create a database and open up some database design tools and start working with it. That would the wrong way. We have SQLite. We've already defined exactly what things are supposed to look like and it would have to match this perfectly anyway. So, why not let SQLAlchemy create for us? And, you'll see it's super easy to do. So, you want to use SQLAlchemyBase. Remember, this is the base class we created. Just import that up above. This has a metadata on there. And here we can say create_all. Now, notice there wasn't intellisense or auto complete here. Anyway, some stuff here, but create_all wasn't don't worry, it's there. So, all we got to is pass it, the engine. That's it! SQLAlchemy will go and create all of the models that it knows about it will go create their corresponding tables. However, there's an important little caveat that's easy to forget. All the tables or classes it knows about and knows about means this file has been imported and here's a class that drives from it. So, in order to make sure that SQLAlchemy knows about all the types we need to make sure that we import this. So, because it's only for this one purpose let's say from pypi.org.data.package import package, like this. Now, PyCharm says that has no effect you don't need to do that. Well, usually true, not this time. Let's say, look, we need this to happen and normally you also put this at the top of the file but I put it right here because this is the one and only reason we're doing that in this file is so that we can actually show it to the SQLAlchemyBase. So, first of all, let's run this and then I'll show you a little problem here and we'll have one more fix to make things a little more maintainable and obvious. So, notice over here db folder empty. We run it, everything starts out well and if we ask it to refresh itself, oo, look! There's our little database, and better than that it even has a database icon. It does not have an icon because of the extension it has an icon 'cause PyCharm looked in the binary files and said that looks like a database I understand. So, let's see what's in there. Over here we can open up our database tab. This only works in Pro version of PyCharm. I'll show you an option for if you only have the Community in a moment. If we open this up, and look! It understands it, we can expand it and it has stuff going on in here. If, if, if, if, this is a big if so go over here, and you say new data source, SQLite by default, it might say you have to download the drivers or maybe it says it down here it kind of has moved around over time. Apparently, there's an update, so I can go and click mine but if you don't go in here and click download the drivers PyCharm won't understand this so make sure you do this first. Cool, now we can test the connection. Of course, it looks like it's working fine because we already opened it and now here we have, check that out! There's our packages with our ID which is a string create a date, which is the date, time all that good stuff, our primary keys, jump to console and now, I can say select star from packages, where? All through email, homepage, ID, license there's all the stuff, right? Whatever, I don't need a where clause and actually it's not going to be super interesting because it's empty. Obviously, it's empty, we haven't put anything in there but, how cool! We've had SQLAlchemy generate our table using the schema that we defined over here and it's here up in the database tools, looking great right? Well, that pretty much rounds it out for all that we have to do. We do have some improvements that we can make on this side but that's a pretty awesome start. I did say there was another tool that you can use. So, if you don't have the Pro version of PyCharm you can use a DB Browser for SQLite that's free. And if I go over to this here I can open up the DB Browser here and say open database, and give it this file. And check it out, pretty much the same thing. I don't know really how good this tool is I haven't actually used it for real projects but it looks pretty cool, and it definitely gives you a decent view into your database. So, if you don't have the Pro version of PyCharm here's a good option. Alright, so pretty awesome. I did say there's one other thing I would like to do here just for a little debugging now let's just do print connecting to DB with just so we see the connection string when it starts up so you can see, you know a little bit of what is happening here, and that will help. And the other thing is, I said that this was a little error prone, why is this error prone? Well, in real projects you might have 10, 15, 20 maybe even more of these package type files, right? These models. And if you add another one, what do you have to do? You have to absolutely remember to dig into this function, and who knows where it is and what you thought about it, and how long? And make sure you add an import statement right here and if you don't, that table may not get created it's going to be a problem. So, what I like to do as just a convention to make this more obvious is create another file over here called __all_models and basically, put exactly this line right there. And we'll just put a note, and all the others all the new ones. So, whenever we add a new model just put it in this one file. It doesn't matter where else this file gets used or imported, or whatever, if it's here, it's going to be done. So, to me, this makes it a little cleaner then I can just go over here and just say import __all_models and that way, like, this function deep down in it's gut, doesn't have to change. It should still run the same, super cool. Okay, so that's good. I think it's a little more cleaned up. We've got our print statement so we got a little debugging and then we've got our all models so it makes it easier to add new ones.
|
|
|
transcript
|
5:00 |
Let's return to our package class that defines the table and the database. I said there was a few other things that we needed to do and well, let's look at a few of the problems and then how to fix them. created_date. created_date is great. What is it's value if we forget to set it? Null. That's not good. We could say it's required and make us set it but wouldn't it even be better if SQLAlchemy itself would just go right now, the time is now and that's the time it's created on first insert? Super easy to do that. But, we've got to explicitly say that here. We're here in the emails. Maybe we want to be able to search by author/email. So, we might want to have an index here so we can ask quickly ask the question: show me all the packages authored by the person with such and such email. Boom. If we had a index, this could be super, super fast. The difference in in terms of query time for a query with an index and without an index with a huge amount of data can be like a thousand time slower it's an insane performance increase to have an index. Helps you sort faster, it helps you query faster and so on. So, we're going to want to add an index on some of these. And maybe the summary is required, but the description is not required. So, we would like to express that here as well. So, SQLAlchemy has capabilities for all these. So, let's start with the default value. So, pretty easy, we're going to set defaults here and it could be something like 0 or True or False if that made sense, it doesn't for datetime. Well, what would be the value for a datetime? Well, let's use the datetime module and we can import that at the top. And use datetime.now. Now, notice if I just press end and then enter bicharm is super helpful and it puts parenthesis here. That is a horrible thing that happened. What this will do is take the current time when the application starts and say well that time is the default value. No no. That's not what we want. What we want, is we want this function now to be passed off in any time SQLAlchemy is going to put something in the database, it goes, oh, I have a default value which is a function so let me call that now to get the value. So, that will do the trick of getting the insert time exactly as you want. Here we can say, nullable=False you can say, nullable=True. Not all databases support the concept of nullability like, I think SQLite doesn't, but you don't want to necessarily guarantee that you're always working with that, right? We may also want to say, all like, all the packages or the top ten packages are the most recent ones. And, for that you might want an index cause then that makes it really fast to do that sort, so we can say index=True. And that's all you got to do to add an index it's incredible. We also may want to ask, you know, show me all the packages this person has written. So, then we'd say index is true, that'll be super fast. Also, you might ask, what are all the packages or even, how many of them are there that have say the MIT license? And, then you could do a count on it or something, right? So, this index will make that query fast. These we'll deal with when we get to relationships. But, these simple little changes here will make it much, much better and this is really what we wanted to define in the beginning, but I didn't want to overwhelm you with all the stuff at the start with. All right, so we have our database over here. Let's go and you know, and we have it here as well. Let's go and run the app, rerun it see if everything's working and if we just refresh this what's going to happen. sad face, nothing happened. Where are my indexes? Where is my null, well, nullability statements things like that. This is a problem, this is definitely a problem. The reason we don't see any changes here is that SQLite will not create or modifications to a table. It'll create new ones, great new tables. If I add a new table it'll create it like uh release it or something, you would see it show up when I ran it. But, once it exists, done. No changes, it could lose data or it could make other problems, so it's not going to do it. Leader, and this is very common, you want this but SQLAlchemy won't do it. We're going to later talk about something called Alembic which will do database migrations and evolve your database schema using our classes here. But, we're not there yet. We just are trying to get SQLAlchemy going. So, for now, what do we do, how do we solve this? We could either just delete this file, drop that table and just let it recreate it, right, we don't really have any data yet. When you get to production migrations, but for now just super quick, let's just drop that table. I'll rerun the app, refresh the schema, expando and look at that, here's our indexes and author/email creator date and license, here's our uniqueness constraint on the id which comes with part of the primary key. You can see those, blue things right there those are the indexes. So, we come over here and modify the table, you can see here's your indexes and your keys and so on. Cool, huh? All we need to do is put the extra pieces of information on here and when we enter one of these packages we'll get in and out and we'll have an index for it and so on. Super, super cool.
|
|
|
transcript
|
4:24 |
Now for the rest of the tables I don't want to go and build them piece by piece by piece. That'll get pretty monotonous pretty quickly. We did that for package and it's quite representative. So let's just do a quick tour of the other ones I just dropped them in here for you. So we have download and of course change the database name the table name to downloads, lower case. And again we have an id, this one is an integer which is primary key in auto-incrementing, that's cool. created_date, most of our tables will have this because of course you want to know when that record was entered. You almost always at some point want to go like actually, when did this get in here? Or all of these or something like that. So always have that in there. And then this is going to represent a download of a package like pip install flask, right, like when that happens if that hits the server we want a analytical record of that. So we want to know what package and what release we hit and we may want to query or do reporting based on that so we'll use an index here. We also might just want to track the IP address and user agent so we can tell what it is that's doing the install. That one's pretty straightforward, what's next? Languages, again wrote in this trick where the name of the language are like, Cython or Python 3 or whatever. That's going to be the primary key 'cause it was very unique and then we also have when it was put there and a little description about what that means. Licenses like MIT or GPL or whatever, same thing. One more, one more ID is the name. Or you can avoid, join potentially and get things a little quicker that way. Little description and create a date, always want that. This is an interesting one here this is for our many to many relationship. We have users and we have packages and a user can maintain many packages and a package be maintained by multiple users. So here's our normalization table we have the user ID and package ID and these are primary keys. Possibly we should go ahead and set up these as foreign key relationships, but I didn't do it. We'll do that over here, so this one hasn't changed we still got to add our relationship there at the bottom. Our releases, this one is going to have a major, minor and build version all indexed. Just an auto-increment and primary key. Maybe some comments in the size of that release and you know, stuff like this. And finally we have our user these are the users that log into our site auto-incrementing ID, the name, it's just a string email. It has an index we should also say this probably is unique. It's true as well 'cause we can't have two people with the same email address, that would be a problem when they want to reset their password. We also, speaking of passwords, want to store that but we never, never, never store just the password. That is a super bad idea. We're going to talk about how we do this but we're going to hash the password in an iterative way mix it in with some salt and store it here. So to make that super clear this is not the raw password but that is something that needs transforming we put hash password. But we also want the created date, maybe their profile and their last login just so we know like who the active users are and whatnot. That's all of the tables, or the classes that we've got. If you look over here, I've updated this. And guess what? We don't need to go change like our db_session or whoever cared about importing all these things. It's all good. Notice also that I put this in alphabetical order. That means when you go add a new class or table it's super easy to look here and see if it's listed and if it's not, you know put it where it goes alphabetically. It'll help you keep everything sane. So let's see about these tables over here we have not run this yet. Notice we just have packages, but if we rerun the app what's going to happen? It did not like that, our package singular. Let's try again. Here we go, and now if we refresh, resynchronize boom, there they all are. So we see our downloads and it has all the pieces and the indexes say on like, package ID right there our license and so on. Everything's great. So SQLAlchemy did create the new tables it did not make any changes to packages. Luckily we haven't actually changed anything meaningful about packages, so that's fine. If we did we'd have to drop the table or apply migrations, right. But it's cool that at least these new tables we're defining they do get created there and then yeah it's pretty good. All right so I think we're almost done we're almost done we just have a few more things to tie the pieces together to relationships and our data modeling will be complete.
|
|
|
transcript
|
7:16 |
The last thing we have to do to round out our relational database model is to set up the relationships. So far we've effectively have just a bunch of tables in the database with no relationships. We're not really taking advantage of what they have to offer so in order to work with these let's go up here I'm going to do a little bit more of an import the ORM aspect to we'll talk about relationships and Object Relational Mappers and so on. So over here, what we want to do is we want to have just a field releases and when we interact with that field we would like it to effectively go to the database do a join to pull back all the releases through this relationship that are associated with this package. So basically where the package ID on the release matches whatever ideas here. So the way that we're going to do this is we're going to go over her and say this is an orm.relation relation just singular like that and then in here we talk about what class in SQLAlchemy terms this is related to. It's going to be a release, that's good and that alone would be enough but often you want the stuff you get back through this relationship to have some kind of order. Wouldn't you rather be able to go through this lesson say it's oldest to newest or newest to oldest releases? That would be great if you had to do no effort to make that happen right? Well guess what, we can set it up so there's no effort so we can say, order_by= Now we can put one of two things here. We could say I want to order my one column on the release class so we'll just say release and import it at the top. You could say we want to say accreted data descending like this and that would be a totally fine option but what we want to do is actually show, if we go over here we want to order first by the major version then the minor version, then the build version. All of those descending so in order to order by multiple things, we're going to put a list right here like so and let's say we're going to order it by major version minor version, and build version. All right so that means we get it back it's going to go to the database and have the database do the sort. Databases are awesome at doing sorts especially with things with indexes like these three columns right here have. Okay so that's pretty good and we're also going to have a relationship in the reverse direction so package has many releases. Each release is associated with one package. So over here when I have a package for a moment I'm going to leave it empty but we're going to have this field right here. So what we can do is we can say is back populates package what does that mean? That means when I go here and I get these all filled out and I iterate over my get one of the releases off maybe I hand it somewhere else somebody says .package on that release it will refer back to the same object that we originally had that we accessed it's here so it kind of maintains this bidirectional relationship behavior between a package, it's releases and a given release and it's packaged automatically so might as well throw that on there. All right this one's looking pretty good let's do the flip side. How does it know that there's some relationship? I just said this class is related to that boom done. Well that's not super obvious what this is. So what we're going to do is like standard database stuff is we're going to say there's a package_id here and this is a field or column in the release table to maintain that relationship and this will be a sa.Column, SQLAlchemy Column and what type is it going to be? It has to correspond exactly to the type up there. Okay so this has to be SQLAlchemy.string but in addition that it'll be SQLAlchemy.ForeignKey. So it's a little tricky to keep these things straight in your mind but sometimes we speak in terms of classes sometimes we speak in terms of databases. Over here I said the class name for a relationship but in this part, the foreign key you speak in terms of the databases, it'll be packages.id lowercase right that's this thing we're referring to that and the ID. So here we're going to have that foreign key right there and then this we can set that up to be a relationship as well. So again we got to get ahold of our orm orm.relation and it's going to relate back to package. Okay, I think that might do it. We're going to run and find out but we have it working in both directions so here we can go to the releases and then we can go, this will establish that relationship and this will be that referring the thing that refers back to it. Now we've already created those tables so in order for this to have any effect we have to drop those in this temporary form or member migrations later but not now. All right, let's run it and see if this works. All right, it seems happy that's a pretty good sign SQLAlchemy's pretty picky so we go over here there really shouldn't be anything we notice about this table but here we should now have a package and notice in that blue key, even right here there's a foreign key relationship if we go back and interact with this, say modify table we now have one foreign key from package_id which references packages ID, that's exactly what we wanted. Now we don't have any data here yet so this is not going to be super impressive but let me show you how this will work. Imagine somehow magically through the database through a query which we don't have anything yet but if we did, I'm going to come over here I'm going to go give me a package, right? Now I'm just allocating a new one but you could do a query to get to it right? So then I could say print P., I don't know what ID would be the name and then I could say print our releases and say for r in p.releases that will print out, here we go we go through and print them out. All right and we would only have to do one query except when explicit query here to get that and then down here, once it's back this would go back to the database potentially depending how we define that query and then do a query for all the releases ordered by the way we said and then get them back, that's pretty cool. Maybe like notice it says you can't iterate over this it's kind of annoying, let's see if I can fix this to say this is a list of release. Import that from typing, all right. So now it's happy and if I say r. notice that so maybe this is a good idea, I'm not sure if it's going to freak it out or not but I'll leave it in there until it becomes a problem. All right, let's actually just run it real quick make sure this works. Yeah that worked, didn't crash when we did that little print out. There was nothing to print but still, pretty good. So those are the releases. Once we get some data inserted you'll see how to leverage them even for inserts they're pretty awesome.
|
|
|
transcript
|
4:15 |
Before we actually start using SQLAlchemy to insert data and query data, and so on let's talk about some of the core concepts we've seen and some of the fundamental building blocks for modeling with SQLAlchemy. So we started with the SQLAlchemyBase. Remember, the idea was every class we're going to store in the database derived from this dynamically defined SQLAlchemyBase class. You can call it whatever you want. I like SQLAlchemyBase. But there's other, you know, it's just a variable. Name it as you like. So I want to create this singleton base class to register the classes and type sequence on the database. Remember, there's one and only one instance of this SQLAlchemyBase shared across all of the types per database. So for example, we're going to have a package to release a new user, they all derive from this one and only one SQLAlchemyBase type here. To model data in our classes, we put a bunch of classable fields here, ID, summary, size homepage, and so on, and each one of them is a Column. SQLAlchemy.Column and they have different types like integer, string, and so on. We can see some of them are primary keys and even if it's an integer, they can even be auto-incrementing, primary keys which is really, really nice. And we can also have relationships like we do between package and releases. One really nice feature of databases is they have default values. We saw with our auto-incrementing ID our primary key, we don't have to set it. The database does that for us. So here we can pass datetime.now, the function not the value, the function, and then it's going to call that function now whenever a row is created and set that value to be, well, right now. That's super nice. We can also do that up here with more complex expressions. So in the bottom one, we literally passed an existing function, datetime.now but above, we want to define this default behavior in a more rich way. So we're passing our very own lambda expression that takes the UUID for identifier converts it to a string, and then drops the dashes that normally separate it into just one giant scrambled alphanumeric super thing. You can create these default values by passing any function, a built-in one or one of your own making. We also want to model keys and indexes. So primary keys automatically have indexes. We don't have to do anything there. Let's our uniqueness constraint as well as indexes. This created one, maybe we want to sort by the newest users, for example. Well, if we're going to do that, we very much want to put an index on that. As I pointed out, indexes can have tremendous performance benefits, it's totally reasonable to have a thousand times difference performance in a query, if you have tons of data on whether you have an index or not. Indexes do slow write time but certainly in this case the rate of user creation versus querying and interacting with them is, it's no comparison, right? We're creating far fewer users, probably than we are querying or interacting with them. We can also specify uniqueness we didn't do that in our example. We can say this email, we can't have two users with the same email, emails are very often used to reset your password and if you have two users who's going to get their password reset, all of 'em? One of 'em, who knows, none of 'em? So you might want to say there's a uniqueness constraint on the email to say only one user gets to use a particular email and that's super easy to do by just saying unique=True. Finally, once all of the modeling is done we have to actually create the tables. Now turns out that that's super easy. We import all the packages, get the connection string and we can create an engine based on the connection string and then we just go to SQLAlchemyBase to it's meta-data and say create underscore all and pass the engine, boom, everything is done. Remember though, this only creates new tables it does not modify existing ones so if you need to modify it wait till we get to the alembic chapter, the migration chapter or do it yourself or if you're just in development mode maybe deleting it and just letting it recreate itself that might be the easiest thing, that's what we did.
|
|
|
|
52:56 |
|
|
transcript
|
2:18 |
In this chapter, we're going to look at actually using SQLAlchemy. Previously we had modeled all of our data but we didn't do anything with it. We didn't do any insert queries, updates none of that. That's what we're going to do now. And to get started we're just going to jump right into writing some code. And so I just want to point out we are now in Chapter 10 Using SQLAlchemy, working on the final bits here. So let's switch over to PyCharm grab our new chapter and get going. This is the code from before, just carrying on. And what we're going to do is we're going to actually have over here a new directory called bin. Now, this is just a convention that I use. I've seen it in other places as well and this bin folder comes along with our website for little admin tasks and scripts that we need to run and so on. It's not directly involved in running the site but more like maintaining the site. So, for example we're going to do some importing of data. And to do so, we're just going to write some scripts here. They don't actually run normally but they're going to run here. Let's go over and add a Python file called basic_inserts.py. We're going to take two passes at showing how to insert data. First, we're going to write some example data just standard make-up stuff. And then I'm going to show you I've actually got a hold of the real PyPI data for the top 100 packages using their API and we're going to insert that. Turned out that's super, super tricky. There's lots of little nuances and typecasting and all that kind of stuff we have to do to make it work just right. We're not going to do that first we're going to do like a simple example and then I'll show you the program that'll actually generate our real database. So, here it is. We already have our database right here and if we look at it we'll see that we have our packages and releases put together. And, of course, there are the interesting ones. Actually, I'll go over here and show you a little more. Show you a visualization pop-up. It's kind of a cool feature of PyCharm. So we have our packages and this relationship between the releases. That's probably the most interesting part of our database. We didn't actually set up save, like the maintainers and what not here. This should maybe have, like some relationships and so on but we didn't set up all the relationships for our data model, just the really important ones. So, we're going to focus on just those two tables.
|
|
|
transcript
|
1:36 |
Now what we're going to need to do is work with our SQLAlchemy engine and the factory and the connections and all that. And remember in order for that to work we have to go to our db_session. We have to initialize it. So let me just copy over a function here. This was just like the one we worked with before. So we're going to import os. import pypi.org and we can say that's spelled correctly. And we also want our db_session like so. And now it has this global_init. So, we just have to call this somewhere. Before we try to do anything, and just to remind you over here this sets up the connection string initializes the engine, and most importantly initializes this factory right here. So, what we're going to do is we're going to have a def main. Here this is going to be like our main startup. And in here we'll call global_init for the database. And we'll use our main convention at the bottom and just run the main function. Here we go. I guess we can go ahead and test it and see that it runs. Oh, it didn't like that. Let's just use this in here we'll just go up one. That should do. Okay, great. So here we're connecting to final, dah dah dah. It might even be worthwhile to say os.path.abspath. Here we go. Now we have the absolute path, in looks right to me.
|
|
|
transcript
|
1:33 |
Okay off to a good start and we no longer need this so this is good. Now what we need to do, let's just say while true we're going to insert a package. We'll write a little function that will does that. So down here, this can just enter package. So how do we insert a package and maybe some releases that are related to it? Well, how would you create a package if you forgot about the database and you only thought in classes and objects? You would say this p = Package(), like so, and you would import that from pypi_org.data.package. You would set some properties like the id might be, and we could ask the user input package id, name and we could do a strip in the lower just to make sure that is all consistent. What else do we need to set? Well, let's go actually look at our package real quick here. And we can say, what do we need to set? Well this, sometimes we don't have to set the primary key. This one is not auto_incrementing so we do. This one has a default value so that's solid. These could all be set, the releases we'll deal with in a second. So let's go over here and just put a little long comment string to show us what we got to do. So it'll be p.summary = input("Package summary: ").strip() For description I think we'll just ignore that all of those we can ignore. Let's just put author name and license.
|
|
|
transcript
|
3:36 |
Classes model records in our database so all we have to do is go and save this back into the database and that's where this unit of work in the factory from db_session, comes from. So what we'll do is we'll say session equals db_session.factory. So, this is pretty cool. If we come over here and say db_session. notice all the cool things you can do? No, no you don't. There's none. If I actually set the type here. I'm not going to leave it like this but, if I were to import sqlalchemy.orm like this, and set it to a session all of a sudden, we have, oh look autoflush, and commit, and bind and rollback, and all the database things and add, and so on. Let's go ahead and get this set up real quick and then I'll show you what we'd actually do. We'll make this a little bit nicer. There's some stuff down the road. We're going to need to make this better anyway. All right, so, we're going to do some work and then, the way this unit of work works is you say, I'm going to make a bunch of changes in this area create the session, make a bunch of changes. No interaction with the database will have happened until line 26, when we call commit or, if we had entered some kind of query but we're not querying, we're only inserting. Let's do this. Let's come over here, and we'll say session.add. That's it. If we run this, it's going to insert it right away but let's add a couple of releases. So we'll say, r., r is a release. I'm going to import that. Let's go over to releases and see what we got to set. id auto_increment in, we don't need to set. Those, we should definitely set. created_date is its own thing. So, let's just do those three and maybe the size. So, we'll say r.majorversion equals... Now, we're just going to assume that they know how to type an integer and, if they don't, well, it's going to crash, but it's OK. It's just a little example. Minor, and build. And, last one, will be size in bytes. OK. Looks pretty good. Now, how do we let's do a quick print. Release one, something like that and let's do it again for release two. So there's actually more than one release per package, OK? How do we associate this release with this package? There's a lot of ways. We could add each release separately. So we could say session.add each time and this, and then commit it as long as we had set r.package_id = p.id. Now actually, in this case, this would be fine but normally, windows are auto-incrementing IDs. You need to first save the package and then you can set it, and it gets real tricky, right? Like, it's not super simple to do this but, what is super simple is to work with this relationship over on packages. So, let's go to here, package. Remember this, releases? It's a relationship but it kind of acts like a list. Let's just try that. What happens if I say, p.releases.append as if it were a list. You know that's going to work. It is, it's awesome. OK, so we're going to append those and we're never going to tell the session to add it but it's going to traverse the relationships and go, I see you have other records to insert into other tables, and relationships to set up.
|
|
|
transcript
|
2:34 |
I think we're ready to try this. Let's go ahead and run this and see what happens. Off it goes, package name let's go with SQLAlchemy to start. Summary is ORM4 for Python. Author is Mike Bayer. License, let's just guess, it's MIT. The first version is 123. And it's that many bytes. The second one is going to be 2.0.0 and it's a little bit bigger, like so. So that inserted the first one. Let's do one more and say Flask, Microframework for Python. Let's go with Armand and David, right? Armand, originally, David Lord these days. Let's just say this is BSD. I have no idea what it is. And it's 1.0.0 and 1.0.02. There we go, that one can be bigger than one byte. All right, I think we're good. Let's go ahead and stop this. Notice, there were no crashes. That's pretty killer already. That's a good chance that something worked But let's go look in the database. So if I go over to Packages and I say Jump to Console and say, select * From Packages. Moment of truth. Tada! There they are, how awesome? We didn't set some of the values but we did set many of them. You can see everything we typed in there. Pretty awesome, isn't it? What about releases? Run those, look at that. There they are! And you can see what package they come from SQLAlchemy or Flask. That's really cool and that's actually the relationship. So I could go over here and, say, where package ID equals SQLAlchemy? Is it 1? I don't think it's what it equals. Here we go. So, we can go do the query for that and this is when we actually go back and do queries with SQLAlchemy and we touch that releases folder. It's going to do, basically, this query but it's also going to add an order by major version descending. And then minor and then whatever but this should be enough. There we go. So we'll get them back exactly in the order you would want them. All right, so this is how we insert data. Super, super simple, right? We go and just treat these more or less like objects. We create them, we set their properties we click them together through their relationships and we add them to the session, create a session and add it.
|
|
|
transcript
|
1:20 |
I guess, real, real quick, let's make this a little bit nicer. I don't like that this doesn't give us much information about what comes out of it and it's not super easy to get that to happen, so let's do this. Let's define a function called create_session(). That's more obvious. And it's going to return a session object that comes from sqlalchemy.orm and for now it's just going to say return __factory(), like this. Let's tell it that this is global, like that. Okay, this is pretty good. But of course when we now go to db_session. Uou still see it. You still see it at the top and I'd kind of like that to not be the case so let's refactor rename this to double underscore and you see it renamed it everywhere. And now, is it gone? Ah, yeah. We just have create_session and global_init. So where are we doing this factory we don't need any of this stuff anymore. That can all be gone, we just say = DBsession.createsession the type annotation on the return value there should be enough so that when we say session. Boom, there it all is. Okay, that's it. We're all good to go. We clear the session, we make the changes we call commit, beautiful.
|
|
|
transcript
|
5:09 |
Now you've seen how to insert data with sequel Commie. We're going to insert the actual real data and it turns out that this data I got is the actual Pipi I data I got from, ah, couple of AP eyes I put together and I have the top 100 packages in all their details in a bunch of Jason files. So what we're gonna do is load those Jason files, pull them apart, do some type conversion and things like that and insert them all into a database that is super into D gritty and it's really not worth going into So let's just skim quickly across that first off to run the program we were going to use to new requirements progress bar to so we can have a cool progress as we're doing our import, which is really, really nice. And then Python Dash date util, which is a really, really nice way to parse dates much better than the built in stuff. So I've already pip installed these, so they're just in the requirements now. So over here at the top of your repository, I have the pie p I top 100 each one of these is just a Jason file. For example, let's look at click circa a little while ago written my r Monroe knicker originally at least now managed by David Lord and the Pallets Project. But for the day that we got, this is what it says And it has the licenses BST but notice it doesn't just say licenses BST it has this, like, sort of funky name space style, if you will. It talks about the languages Python and being Colin Colin three. We're gonna parts that apart. Yeah, the license BST. It works on Python to and Python three and so on so you can scroll through and see, like, here's all of our releases All the details about the releases and the dates and Wolf has a lot of stuff, right? So we're gonna go and parse that apart and insert it into the database and that's gonna happen over here pretty straightforward. What we're gonna do is we're going to just go and ask really quickly like, Hey, is there any data in this database and the way of checking is are there any users? It could look at all the tables and you just ask. Are there any users? If so, Hey, we've probably already done this, so don't reinsert duplicates. Just don't do anything. Do a little summary there at the end. But if it happens to be empty, go load up those files, all of them. All the Jason files skin across all of them, find the distinct users, import them, do all the packages and their releases and so on. Pull out the languages licenses like that colon, colon BSD license thing we just saw. And then finally do a little summary. So we're just gonna run this through its Let's just look at the import languages and goes and uses our progress bar, which is pretty, pretty sweet. And it rates over them and pulls out the language classification that the interesting data base part is it says that we're going Teoh, just create session creative programming language, set the details of it added to the session and call commit and then update our progress bar Super straight for right. This is what we did before. It's just all this gu of juggling the Jason Files. All right, so let's go and run this and because it uses the Progress bar It looks better outside apply charm. It will run in here. No problem. But let's just make it as nice as possible. So I want to figure out where to activate my virtual environment. That's a long enough directory, don't you think? I will say that. Slash Activate. And then I want to runs a Python. The name of this script here where that one is gonna do the import. One other thing we also need to add system dup half upend toe our path. This folder right here because we're importing pipeline, not or in pyjamas is gonna totally work smooth, because guess what? PyCharm does that forest right there. But if we try to run this outside without setting this up, it's a package or something like this is not gonna work so great. Now her ready to run our code here till gonna run Python out of our virtual environment Pointed at a low data Here goes. So hearing see, it's loading up all of the users. All the projects it found 96 packages said there were 100. I think for some reason, some couldn't be downloaded. So let's go with 96 Top 96. Out of there, it went through, and it found the users found the packages and releases the languages. So in the end we found 84 users. 96 packages, 5400 releases embedded within those documents, 10 maintainers, 25 languages and 30 different licenses. All right, well, that's it. We should now have a whole lot more data over here. And if we go local quick, let's just go to the packages and jump to the console. Say, select star from packages. We run it like that. We had a whole bunch of them. Here's am Q P. Actors are pars, Flake eight and so on. We running for releases, you see a whole bunch of stuff and there related to their various packages over here on the right. Pretty awesome, huh? So now when we run our app, forgive over and run the actual app itself click on it, you can see Well, we're not quite using the data yet, but we're going to be able to start using all that data we've just loaded up and dropping it into these locations. So that's gonna be really awesome. We have true, accurate, realistic or even a snapshot in time. RealD data from Pipi I toe work with to finish building out in testing your app
|
|
|
transcript
|
2:22 |
One of the core concepts of SQLAlchemy is this Unit Of Work. Let's dig into that. The Unit Of Work is a design pattern that allows ORMs and other data-access frameworks to put a bunch of work together and then at the very end decide to go and interact with the database decide now we're going to actually save this data within a single transaction. So here we have a bunch of different tables customers, suppliers, and orders. They're all providing entities into this operation this unit of work. So maybe we have a couple of customers one supplier, and one order. We've also maybe allocated some new one like we did with package and we're inserting that into the database. And maybe we've changed things about the supplier we're updating those in the database. And the order is canceled so we're calling delete on that. All that gets kind of queued up in this unit of work. And then I'll call commit in SQLAlchemy syntax and that pushes all those changes which are tracked by the unit of work the so-called dirty records the things that need to be inserted the things that need to be deleted the things that need to be updated and so on. So we can use these unit of works like that and the way we create them are with these sessions. So we've seen that we create these engines and the engine gives us this session factory that was all encapsulated within our db_session class. We do this once and then every time we want to interact with the database we create one of these sessions. So we come over here and we call that session factory it gives us a unit of work which is often called a session kind of treat this like a transaction a bunch of stuff happens in memory then it's committed. Maybe we add something, maybe we do some more queries maybe that tells us what we've got to do to add some more. We could make changes to the results of those queries either updates or deletes. Other than the query there's not actually been any interaction with the database. This add doesn't actually add it to the database it just queues it up to be added. When you call commit that commits the entire unit of work. Don't want to commit it? Don't, then nothing will happen in the database there will be no changes to your data. And that's how the unit of work pattern appears and is used in SQLAlchemy through this session factory and then committing it.
|
|
|
transcript
|
5:55 |
Now that we've imported the data into our database I think it's time to start using it. How many projects did we import? Negative one, unlikely. That's not typically a count of real numbers, is it? So, what we need to do is actually go query the database to fill out those sections. We also need to fill out our releases down here at the bottom, but we're going to focus on just this little stat slice as we called it. So if we go over here, and we see right now what we're doing is we're going to our package_service and we're calling a function: get_latest_packages. Well, that's pretty cool, but we could look over here this is just fake data. So let's actually put in here we're going to need to pass more data over to our template. So we go to our template, it's super nicely organized. We're in Home View, so we go into the Home folder and run the Index function, so we go to Indexing. Boom, there it is. Well, that looks like a problem. Let's pass in some data. Now, we might want to just drop the number here like, package count, that'd be okay. Except for, if there's a million packages it's just 1-0-0-0-0-0-0 with no digit grouping. So we could do a little bit better if we did a little format statement, like this. Like so, and to do the digit grouping. Now let's just put that in for the others as well. I have release count, and user count. Of course, for that to work, if we try to run this again we go to refresh it, not so much. Unsupported format type. And let's go pass this data along here. So we're going to need to have a package count and let's just make this fake for a minute. Release. And user count. This should be auto-refreshing down here at the bottom. Here we go, it's active again, super. Refresh. One, two, three, looks beautiful. I was trying to pass None to format in digit grouping. None doesn't go that way. Right, so this is working in terms of the template but it's not working in terms of the data. So let's go and change this down here I'm going to call Package_service.get_package_count Now this doesn't exist, but it will in just a moment. Release count, we're going to do users in a separate service. So we can go over here and hit Alt + Enter create this function, and it didn't really know what to do. It's supposed to return an int. And over here, we saw how to do queries. If we start by creating a session and we're going to import our db so we'll say, import pypi.org. Get our little db_session there and we'll say create_session. That's cool. And then we simply have to do a query so we're going to come over here and we're going to say, I would like to go to the session and do a query, and then you say the type. We want a query package because that's what the count we're looking for. And we might do a filter to say where the package_id is this or the publish date is such and such or the author is this person or that but all we want to do is a super simple count. That's it, that's going to be our package count, and let's going to let it write that as well and we'll just grab this bit. So this one is the same except for instead of querying package, what are we querying? We query release. Clean that up, and then finally let's go over here and figure out where we are. We also want to have a user service. So if I come over here, and just copy paste I can change that to user. Do a little cleanup. All right, that looks pretty good. Now, it might seem silly to just have this one function but of course, we're going to log in, we're going to register there's all sorts of things this user session will be doing. So now if we go back we should be able to go to our import up here. And we'll do user service as user service. And here we'll do user_service.get_user_count. Okay, moment of truth. If we run this, it should be doing those queries from the database, creating our unit of work, our session. Now, it's pretty boring, all we do is do a quick query. We're not, like, inserting and updating data yet but it still should be doing some good stuff. Let's do a Save, which should rerun it. See the little green dot, it's still running so it should've rerun. Moment of truth: refresh. Bam, look at that! How cool is this? So 96 projects, 5,400 releases, and 84 users. That's exactly what we saw earlier. And if we go over to our little inspector and we go to the network, and we say just show us HTML and we do this again a couple of times you can see that the response time even going to the database and doing three queries is 11 milliseconds. That's pretty solid, right? Not too bad at all. So our site's working fast it's using the indexes that we set and it's pulling back the data. Well, it probably doesn't use an index for a count but it would if we were doing the right kind of queries like, for the new releases. So, I think our little stat slice is up and running and that's how we're getting started using this data that we inserted, that we got from those JSON files. Lots more of that to do really soon.
|
|
|
transcript
|
9:03 |
We have our little stat slice working just fine but the pieces here, not so much. Remember, this is just fake data. See the desk, all right, so now we're going to write the code to get the new releases. Let's go over here and have a look. So we're not going to call this test packages anymore we're actually just going to inline it Like that so we're going to go and implement this method right there. Obviously, it's not doing any database work yet, is it. Now, as we talk about this, there's going to be several ways to do this, some of them more efficient some of them less efficient and I want to look at the output, so the first thing I actually want to do is go over to our db_session and I told you about this echo parameter. Let's make it true and see what happens. You can see all the info SQLAlchemy looking at the tables to just see if it needs to create new ones. It doesn't and if I erase this and hit the homepage you can see it's doing three queries it's doing a count, against users against releases and against packages. Where is that, that is that part right there. Okay, now I just want to have it really clear what part is doing what, so I'm going to turn these off and just have them return 200 or whatever, some random number. I'm also going to do that for the user_service. So now let's refresh, I'll clean up this here and refresh, notice there's no database access. That's good because we're going to do database access here and we need to understand it really clearly. All right so let's go over here and work on implementing get_latest_packages. In fact, we were returning packages but what we really want to do is we want to return the latest releases with ways to access the associated packages. If we look at the release, remember each release has a package relationship here. So I'm going to change this around and rename this to latest releases like that and we're going to implement something here. It's going to start like this and let's go ahead and tell it that it is going to return a list of release, release is good, import that from typing. And it's also going to have a limb and that equals 10 or something like that. So if we don't specify how many latest releases we get 10. Okay so we're going to do some work and eventually we're going to return a list right here. Well what are we going to do, well it turns out that this is actually the most complicated thing we're going to do in the entire website. It's not super complicated but it's also not super simple so let's do one more import. I'm going to import sqlalchemy.orm and because we need to change or give some hints to how the ORM works. So let's go over here and say the releases are equal to, want to create a query so we've already done this a few times session query of release, now what we want to do is get the latest ones so we're going to do an order by. So we'll come down here and say .order_by and when we do an order by we go to the type and it's the thing we want to order by and we can either order ascending like this or we can say descending like so. That's a good part. And maybe we want to only limit this to however many they pass in, 10 by default but more, right, that's the variable passed in that's the function it takes and we want to return this as a list. So snapshot this into a list we're going to just return releases. So is this going to work, first of all, is this going to work? I think it will probably work. I'm certain it will be inefficient. Let's find out. So we rerun this and just clean that up here and let's go hit this page remember these are all turned off so the only database access is going to be to derive a little bit, if I refresh it what happens? Sort of works, well it actually worked let's go fix it really quick and then we'll come back and talk about whether it's good. So here we actually had r in releases and I think we also need to pass that in from our view 'cause even though we called this releases this packages so let's make it a little bit more consistent, releases. That's not super, p is undefined okay and now we can fix this. So we have r, now remember r is a package and it doesn't have a name but it has an ID and then r, it doesn't have a version it has a major, minor and build version but it also has a property which we wrote called version text. So if we go check out version text it just makes a nice little formatted bit out of the numbers and that make up it's version. And then here want to go to the r and we're going to navigate to its package and then we're going to say summary. Let's see what we get. Ooh, is it good, it is good, it's super good. We were actually able to use that relationship that we built to go from a bunch of new releases back over to a bunch of packages. Now there is some possible issues here. We could have these show up twice. AWSCLI two versions, but maybe that's okay. We're showing the releases not just the packages. However if I pull this back up, ooh, problems. Look at all this database access. Let's do one clean request. So here we are going in to our releases and then we go to packages and packages and packages over and over again. Why is that happening? It's happening every time we touch it right here, that's a new database query. Moreover that database query is actually happening in our template, which is not necessarily wrong but to me, strikes me as really the inappropriate place. In my mind I call this function database stuff happens and by the time we leave it's done. Well, let's make that super explicit. Let's close the session here and see how it works now. It's going to work any better? Think that's not better, not so much. It's a detached instance error. The parent release has become unbound so we can't navigate its package property. Actually we don't want to do that. It's okay that we close it here, we don't want more database access happening lazily throughout our application. Instead what we want to have happen is we want to make sure all the access happens here. So we can do one cool thing, we come over here and say options, so we're going to pass to this query we can say SQLAlchemy.orm.joinedload and I can go to the release and I say I would like you to pull in that package. So any time you get a particular release also go ahead and query join against its package so that thing is pre-populated all in one database query. So by the time we're done running it we no longer need to traverse reconnect to the database for this. Is it going to work, well let's find out. Hey it works, that's a super good sign. All of the data is there and look at this. Let's do one fresh one so it's super obvious. That's it, so we come in and we begin talking to the database, we do our select releases left outer join to packages and where it's set to be the various IDs and whatnot and a limit and offset and then this rollback here is actually what's happening on line 18. So we're just, we started a transaction when we interacted with it and it says okay actually we don't need this anymore, roll it back. Which is fine you've got to close your transaction either commit or rollback so rollback I guess. We don't really try to commit anything and we didn't want to so this is good. How cool is that, huh? I think this is pretty awesome. So we've done a single database query we've solved the N plus one problem and we've got our latest releases and we used the latest releases to pull back the package names and the package summaries and so on. So that we know our database stuff is working efficiently let's go and put these queries back here. So it's working for real. Go back and pull up our inspect element. Remember we're still running the debugger but we should get some sense of performance here. There we go, 13 milliseconds. What was it, 11 before, so going and get those releases and those packages in that join barely added any effort. Now remember we're running the debugger we could probably make this faster still but this homepage is working super super well. I'm really happy with how everything's coming together. And if we have true indexes it doesn't matter if we have a decent amount of data our queries should still be quite quick. All right, awesome, homepage is done.
|
|
|
transcript
|
9:18 |
The last demo driven part we're actually going to write during this chapter is what happens when you click here. Right now, it's a little underwhelming. So notice, we don't even have a link. But if I were to, you know, hack it in there project/flask or something like that it just says details for flask. Let's compare that against the real one. Huh, well, those are not quite the same, are they? I mean, we've done pretty well on the homepage here going back and forth but certainly not on the details. And if we click it, it doesn't even go somewhere. So that's what we're going to focus on in this lecture here. Well, if we go to the homepage, the index this is easy to change. This is going to be /project/{{ r.package_id }} Let's just get that working now. I can click it and it at least takes us to where we intend it to go. Now, it turns out the HTML here is quite complicated. We've spent a lot of time already putting the design in there and this is just a variation on that design. We have the heroes, we have Bootstrap all the kind of stuff. So I'm not going to go over it again. I'm just going to copy some over and we can just review it really quickly. We're going to focus on getting the data back and delivering it to that template. So, towards that, let's start over here on this page. And right now we just say package details for some package name, but what we really want is we want to get the package from the package service. And we'll do something like get_package_by_id or pass package_name.strip().)lower(). Okay, well, that's not so incredible. I mean, maybe we even want to do a little check here. So if not package name just so that doesn't crash we might do a return flask.abort. Status equals 404. Something like that. Okay, but let's assume this is working. And down here now. And we can go to a query. It still might not be found. So we might say, if not package, again, not found. Right? They could be they asked for a package, abc one, two, three, it doesn't exist. So we don't let that to crash. Now, let's go and have PyCharm write this function. It's going to be package_id, which is going to be a str. It's going to turn in optional package. We're going to import that from typing. It's optional 'cause, like I said you could ask for a package that doesn't exist in the database. Super. Well, how's it start? How do all of them start? They all start like this. And somewhere we say db_session.close probably. And in the middle, we do things like get us the package. And the package is going to be, again, one of these sessions. We're going to create a query a lowercase query of package filter and what we want to do is say package.id == package_id. And again, maybe this one would want to do that test. Actually something like this. It's a bit of a duplication but let's go package_id. Instead of returning abort, we'll return none which will see it as missing then it will abort it. And then here we'll just say package_id equals package_id. That's true. Okay. It's a little bit of data protection because that is user input right there. All right, so we're going to get our package. Now, if we do it like this, we get a query set back. Not what we wanted. All right, we don't a want a query set. What we want is, we actually want one package. So we'll go over here and we'll say first. And that's either going to return the package or nothing hence, the optional right there. Then we return package, like so. And we should be good. We can just do a really quick test here. And let's just do package. So this will show that we're either going to get a 404 or we'll get it back and will show its name when we click on the homepage there. Let's try. Put down, click on boto. Details for boto, woo! We got that from the database. It's pretty cool, right? And so super easy. I mean, seriously, like that is easy. However, our little package details page actually needs more information than what we have here. So we go look through this. You can see we're adding a new style sheet to the top of the page. And we're having our hero section, it has a id and package this and package that but it also has a handful of other things. So it wants to work with the releases. Now this is going to cause a tiny issue that we're going to catch and then improve. So we're going to have latest version is going to be zero.zero.zero to start, okay? We're also going to have latest release is going to be None. And we'll have to say is latest equals true. So the page adapts on whether or not you have the latest version. We're just going to say it is for now. We need to actually have the instance that is the latest release, if it exists and also the text of the version. So we'll say this, if package.releases remember this is sorted in the order of newest first. So we can say, latest release is package.releases of zero and latest version is going to be latest release version text. And we'll just leave is latest is true. Now the other thing we want to do instead of just returning the string is we want to go over here and say, remember to this? And we said, response, this was from long ago. And what was it? Template file is going to be it's going to be where is it in this folder? It's going to be packages slash details. So packages slash details.html. And then for this part, we don't return that. We return a dictionary of stuff. And there's a bunch of stuff that I got to put I here. So I'm just going to copy this over. There. So we have our package, we want to hand that off. Latest version, latest release whether or not it's the latest. Let's make this a little bit more obvious. Pass it through. And of course, a lot of this could be computed in the template. That would be wrong. The template is about taking data and turn it to HTML and not doing all this logic. It's best to get this as much ready for the view as possible. Here, we're going to talk about patterns that make this better later but right now it's already pretty good. Let's just rerun it to make sure we're all good. Over here and refresh. Now, what happened? Why did this crash? Well, if I didn't do that close inside here my package service, it wouldn't have crashed. So you might say, Well, just don't do that. Again, this means that like database query operations and lazy loading is leaking into our template. So one option is, we'll let it leak and everything will work. The other one is, well, what do we do up here, we add in one of these joined loads. We kind of basically need the same thing but in reverse. Let's put the dot here. And not there. So instead of saying I want to go to the release and load the package I want to go to the package and load the releases, plural. It should've reloaded when I saved, and ta-da. How cool is that? Look, it's already working. Yes, I copied over the HTML and the CSS. But that's not the hard part, is it? I mean, maybe it's hard at some point but that's not really the essence of this data-driven app. So here we've got our pip install boto. Here's the version. Is it the latest version? Yes, that's why it's green. You can go, here's a project description the release history. If I want to go to the homepage click on that, it takes me to the Boto3 homepage. Right? All this stuff. Let's see what we get if we put Flask up here. We have Flask, and we have all sorts of stuff like here's the license. We go to the homepage, we go to Pallets, and so on. And we don't have every bit of details in here that the main one does, but good enough for our demo app, right? This is cool, huh? We did some query against our database filtered by the ID, got the first one but then realized, oh, we're trying to navigate that relationship. So instead of doing the in plus one interactions with the database and, you know, leaking and lazy loading let's explicitly catch that by closing it. And then do a joined load to eager load it all in one query. That's pretty awesome. So now things are going really, really well. There might be times when you don't always want to do this and you might have to have a little flag you pass on whether or not you do this just because if you don't want it it's a little bit extra overhead on the database but generally, given a package, we want its releases. So I'm pretty happy to just put this right into the main method. All right? That's it. We have our data-driven package page and our homepage up and running. I'm really happy with the way the site is coming along.
|
|
|
transcript
|
4:03 |
We've written a few interesting queries and before we're done with this application we'll write a couple more. But let's talk about some of the core concepts around querying data. So here's a simple function that says find an account by login. We haven't written this one yet but, you know, we're going to when we get to the user side of things. It starts like all interaction with SQLAlchemy. We create a unit of work by creating a session. Here in the slides we have a slightly different factory method that we've written, but same idea. We get a session back, we're calling it s. We go to our session and we say s.query of the type we're trying to query from account, and then we can have one or more filter statements. Here we're doing two filter statements. Find where the account has this email and the hashed password is the one that we've created for them by rehashing it. And now we're calling one, which gives us one and exactly one, or None, items back and we're going to return that account. So if you actually look at what goes over to the database it's something like this: select * from account where account.email is some parameter and account.password_hash is some other parameter and the parameters are: Mike C. Kennedy, and abc. You'll see that you can layer on these filter statements, even conditionally. Like, you can create the query and then say if some other value is there, then also append or apply another filter operation so you can kind of build these up. They don't actually execute until you do like, a one operation, or you loop over them or you do a first, or anything like that. So here's returning a single record. Also, it's worth noting that the select * here is a simplification. Everything is explicitly called out in SQLAlchemy. The concept is, just give me all the records or give me all the columns. If we want to get a set of items back like, show me all of the packages that a particular person with their email has authored we would go and again get our session we would go and create a query based on package we would say filter, package.author_email equals this email. ==, remember, double equal. And then we can just say, all. And that'll give us all of the packages that match that query. This one's not going against a primary key so there'll be potentially more than one. Of course, this maps down to select * from packages, where package.author email equals well, you know, the email that you passed. Super simple, and exactly like you would expect. So the double equal filter, pretty straightforward. There's actually some that are not so straightforward. So equals, obviously ==. user.name == Ed, simple. If you want not equals, just use the != operator. That's pretty simple. You can also use Like. So one of the things that takes some getting used to is these SQLAlchemy descriptor column field the how you type multipurpose things here is they actually have operations that you can do on them when you're treating the static type interacting with the static definition rather than a record from the database. So here we say, the user type.name.like or N or things like that, and so there's, you know we saw the descending sort operation on there as well. So if we want to do the Like query, this is like find the substring Ed in the name, then you can do .like and then pass the percent to operators as you would in a normal SQL query. If you want to say, I want to find the user whose name is contained in the set Ed, Wendy or Jack, then you can do this .in_ remember the underscore is because in is a keyword in Python, so in_. If you want to do not, not in, this kind of a not obvious but you do the Tilda operator at the beginning to negate it. If you want to check for Null, == None the And you just apply multiple queries. The Or doesn't work that way, if you want to do an Or you've got to apply a special Or operator to a tuple of things. So here are most of the SQL operators in terms of SQLAlchemy. You can do a lot of stuff with this. It's not all of them, but many of them.
|
|
|
transcript
|
0:44 |
Databases are really good at filtering and ordering. Here is a function, find_all_packages and the idea is I would like, ideally a list of all the packages in the database showing the newest ones first and the oldest ones last. So we're going to do a query on package and we don't do any filtering because like we said the in name, we want them all. But we are going do an order_by so we say, query of package.order_by and then we always express these operations in terms of the type, so package.created If we just said package.created it would order ascending by the created_date but we want descending, so we go into that descriptor created and we say .desc we call the function to reverse the sort, and then we just say give us all the packages, here they come.
|
|
|
transcript
|
0:49 |
In order to update existing data we start like we always do, we get a session. And then we retrieve one or more records form the database. Here we're just getting one package. When I get this package back, and if we make changes to it so we set the author value to a new name we set the author email to a new email SQLAlchemy will track within the session that that record is dirty and it needs to be updated because we've changed some fields. And then, when we're ready to actually save it push all the changes back. I could apply this to as many entities as we'd like it doesn't have to just be one. Then we're going to commit the unit of work and it's going to look at the changes do all the changes in a single transaction back to the database. We use the unit of work to do our updates just like we do the inserts.
|
|
|
transcript
|
1:59 |
We saw relationships are extremely powerful and let us imagine as if our code and data were just connected, almost hierarchically the way we would in a regular Python program connected not split apart like we do in a database. The way we define these we add an orm.relationship field to the class so here we have releases so the relationship is against the release type that we're speaking in terms of SQLAlchemy entities, not database and then we're going to do an order_by this can either be a single thing or a list. Probably an iterable actually. And so, we're going to pass that in and then we're going to say it back populates package. What does that mean? We want this relationship to work in both directions so if we have a package we can see the releases and if we have an individual release. We can see the single package that it corresponds to. So, over in the release we're going to do the package_id value to actually store the relationship like we would store any value that's a string or an integer whatever it corresponds to in that other field. And then we're going to say this is a foreign key and in the foreign key part we speak in terms of database, packages.id. But them we also would like to establish that relationship so we say there's ORM relationship for the package type from release back to the package and it back populates releases and it's called Package so you can see the symmetry here not too hard to set these up once you have an example. Put them side by side you go okay, here's where I fill in the pieces for my particular dataset and then you saw that when we load a package it doesn't actually load the releases unless we interact with it. So, if we touch it it'll go back to the database and do the query. We also saw that if we create new releases and put them into the release package.releases well, it becomes a list and commit those changes that'll actually insert the releases. We work in the same but in the reverse as well if we had set the package on a release so it's sort of bidirectional in that sense.
|
|
|
transcript
|
0:37 |
We started off this chapter by demoing how to insert data. Let's actually summarize now here at the end. So again, we're going to create a session which is the corresponding unit of work bit of syntax in SQLAlchemy. Then we're just going to allocate some objects so here we're going to create a package and set its ID and its author maybe create some releases set the release, not package value other properties similarly relates to set its package, we're going to add the package call commit, whoosh! All three that are seeing this because of the relationships get inserted into the database; super easy!
|