|
|
|
24:18 |
|
|
transcript
|
1:58 |
So you've got a Python-based web application and you want to make it fast. I do too. I don't know about you, but when I go to websites that are just slow and spinning and spinning and spinning, it's super frustrating to me. And not only me, Amazon and other folks have studied this and shown that for every 100 milliseconds of delay people have getting to your website, there's a measurable drop-off in conversion, in engagement, in sales, all of those things. So it's super important, not just from a user satisfaction, but also from an engagement perspective, to make sure your web app is fast. Now, there's lots of things you can do on the server side, we can make our database faster with indexes and proper queries, we can optimize our Python code with the right frameworks, we can use cool techniques like even compiling parts So it was Cython or using profilers. But that is only part of the story. As you will see in this course, the other half is what happens after HTML is delivered to the user. Well, there's a whole bunch of other stuff that has to happen involving static files, large files, geo distribution and all those things. So in this course, you're going to see how without very much complexity on your behalf at all, we can easily use CDNs to make our app much, much faster. With what you're going to learn in this course, you're going to have at your disposal what many of the huge tech companies leverage, and your app is going to be way faster than many of them out there. So really excited to share this with you. It's going to be lots of fun. It's easy to adopt, but you also need to make sure that you're thinking of a couple of considerations to make sure it's easy to operate over time as well. So, if you're looking for a fast web app and your app is written in Python, welcome to the journey.
|
|
|
transcript
|
3:07 |
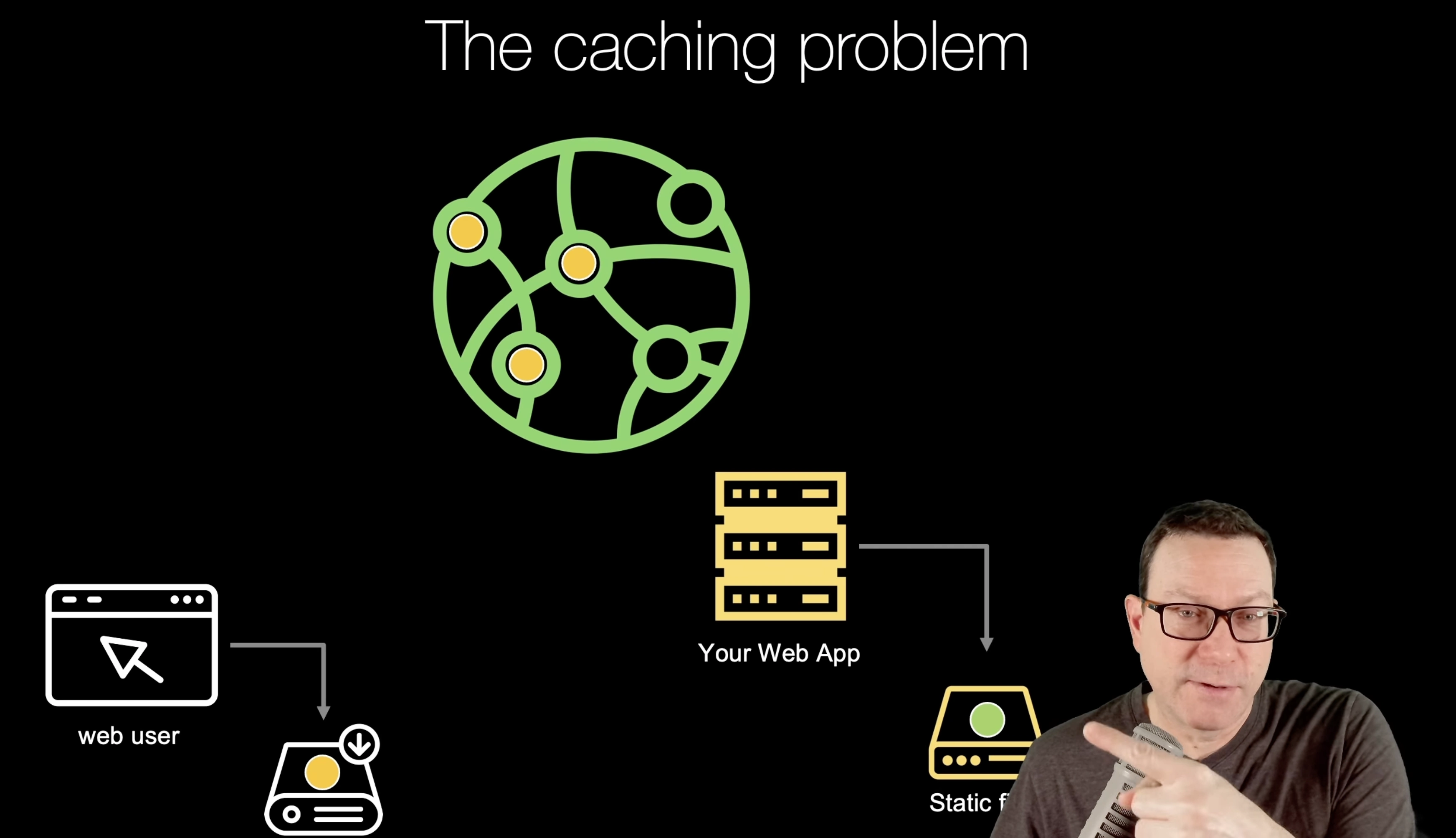
Let's start with a quick visualization. What is a CDN or content delivery network? Well, let's see how the web works without one. See that over there on the East Coast of the US, that little pink dot, that's your web app running on some data center on the East Coast of the United States. And over here on the West Coast of the US, we have one of our users and they wanna check out our website. They wanna go check their mail or see a message or buy something from us, whatever it is they do on their web app, they wanna do it today. So they're gonna come over here and they're make a request, ping time, West Coast to East Coast US, it's about 100 milliseconds, connections are pretty good there. So this user is having a good experience. We have multinational users, we're a multinational company. And so we've got another user over here near Sydney. Now, they also wanna interact with our website. So they're going to make a request and it's got a little bit further to go. So the ping time is longer, the network is slower, that might be a problem. Now, to be honest, if all we're exchanging is one page, or one API response, something like that, this, this would be probably be just fine. It turns out there are many files requested per page as we'll see. So even though there might be some delay here, this is amplified maybe 20 or 50 times worse than what you would imagine for a single request. So it's not a great experience. And the larger the files, the harder it is to serve a multinational set of users. So a CDN comes along and says, well, what if all of those files that we are going to request, what if we could just put them on a bunch of servers and replicate them throughout the world? So when our West Coast user makes a request, most of the files they request are just a few hundred miles away, maybe 20 milliseconds delay. But the same thing for our folks in Australia, as well as in Japan, or South Africa, or Sao Paulo, all over the world, our files are automatically replicated, at least our static files are automatically replicated to all these locations. So when users interact with them, it's as if every single one of them is right by the data center. And that is fantastic. That takes load off of our servers, and it makes it way nicer for all of our users. So our goal throughout this course is how do we take the web app that looked like this first one here, it's already working, but it only serves files straight out of its local data center, not directly out of its Python code, but you know, Nginx just outside of our Python code and probably the same server and convert it to use a cool CDN that's easy to use, extremely fast, and has over a hundred different server locations throughout the globe. So, it turns out it's easier than it sounds and it's really, really effective. You're going to have a good time building this.
|
|
|
transcript
|
1:55 |
I told you that web pages require more than one network request to load them up. Well, let's make that concrete. Here's an example that's close to home, the courses catalog page over at Talk Python Training. Here we have our different courses that you might take. So this involves some CSS, some plain HTML, of course, lots of images. Every course has an image file. Now look down here in the bottom. I've opened up the network tools, the dev tools, and gone to the network section in my browser, Vivaldi. We are going to spend a lot of time down in the network tools for your browser because that's how you see exactly what's happening with all this interchange. So you can see down here that there is actually 109 requests to serve this page. And this isn't even a fancy front-end framework type of situation. We're not using Vue or Angular. We're just doing straight server side responses with HTML. And then there's just a bunch of resources you've got to get. And yet the content is loading incredibly fast, 196 milliseconds. And in this scenario, I told you the servers on the East Coast of the US and the users on the West Coast. Well, I live on the West Coast. That's where I made this request. And the server is actually hosted on the East Coast in New York City. So it's also close to Europe, not just Americans. And so the ping time there is about 100 milliseconds. So this page loads incredibly fast, but it still has to make a ton of requests. When you think about that picture and those users who are far away like Australia or Africa or places like that, they've got to make a lot of requests back to get those static resources, at least the first interaction they have with them. And it's not just that one ping time, that one load time of that basic HTML page, it's amplified across, in this case, 109 requests.
|
|
|
transcript
|
5:26 |
The easiest place for us to optimize our code is that server side Python. After all, that's what we consider the heart of our application to be. So we do our database queries, we check user privileges, we do basically most of the work of our app on the server side. And yes, that cannot be slow, or we're going to pass that slowness on to the user. And that's not going to be great. But it's not just about the server side code. As you saw with 109 requests, that's one of the things that affects how users perceive our code and perceive our web app to behave. But it's also about how do those images show up on the page? How does the CSS work together? Is there JavaScript that's running a lot of times? So there's a bunch of different things that take effect. So for example, let's look at a somewhat terrible web application, CNN. Why is it terrible? this thing, it packs so much junk onto it. There are 43 different trackers, 43 different tracking tools and applications they put on you when you visit here. So it really puts a load onto your browser trying to like do all that tracking on behalf of all these different companies plus just their web app running which is kind of intense. However, they are very impressive in one way. If you look at that response time of this page, 40 milliseconds from end to end all the way to my browser, that's fantastic. So they might be feeling pretty good about this, they might think, Oh, look how fast our code is. This is amazing. We've done a good job. But there are tools we can use to actually ask what is the perceived experience of a user of our web application? If they're using mobile, how do they perceive If they're using a desktop browser, how do they perceive it? They're far away, if they're on a slow network like a cellular network versus a fast gigabit one, whatever. So that's very hard for us to test. But luckily, we've got some tools. Google came up with this thing called PageSpeed tools or PageSpeed insights. And you can go to their link here and say analyze with PageSpeed insights. Give it the URL to one of your pages and it'll do a bunch of analysis and say how does this look to somebody on a 3G network? How does it look to somebody on this type of browser or on this type of computer? And it'll give you a report. That's great. One of the drawbacks of this is it can only access public pages. It can't access, you know, for example, a talk Python if you're taking a course, the course listing page that you have to log in and own the course for, it can't analyze that. Plus you've got to wait for that thing to run on the server and all that. So there's actually a built-in version in many of the Chromium-based browsers. This is Vivaldi. And if you go to the DevTools here, you can see in addition to the network tools we saw, there's Lighthouse. Lighthouse is the code name that preceded PageSpeed Insights. So this is the same basic thing, okay? If we look at CNN with PageSpeed Insights or Lighthouse turned on, maybe the folks over at CNN aren't feeling so smug and happy about how they built their code because the performance is poor, the best practices are poor, and see the 31 errors on the right there? That's because Vivaldi plus my network DNS blocker, NextDNS, all of those are prohibiting many of these tracking tools from getting in. So they're kind of crashing. This would actually look worse if I let all those trackers run as well. But even without them, even with all that blocked 70% performance, that's kind of okay. I don't know. It's not that great. 50% best practices. You know, even SEO is not that great. So we're going to use this lighthouse in addition to the network tools to really understand like, is our app behaving Not just for me locally, because things are always fast when they're local, but how does it look for somebody on a slower computer, on a different kind of browser, on somebody far away, on this type of network or that. And we want these numbers to be green at least, and clearly they're not yet here. But it doesn't have to be. I talked about those 109 requests over on the course catalog page. Look at this. We got 97 perform. 100% accessibility, 92% or 92 of 100 for best practices and 100 for SEO. I'm sure that CNN spends more on their data centers, more on their delivery and more on their technology by a factor of a thousand than I do on this page. And yet here we are running incredibly fast. Part of this has to do with writing good code that communicates back well and the other part is using a CDN that really delivers things ultra quick. So you want yours to look like this, not like that. We're going to start out with an app that is slow like the CNN one, but throughout this course we're going to make it a lot faster and you'll be able to take those ideas and apply them to your own existing web apps or new ones you're building.
|
|
|
transcript
|
4:19 |
I suspect like many of you, I have clearly known about CDNs for a long time. And yet I avoided them. Why? Probably you have as well and you're here to think about maybe changing that too. So I'll tell you why I avoided them at least. First of all, I didn't feel like I needed it. And to be honest, I kind of didn't. I traveled around to different places in the world and I've interacted with the various websites that I run, most importantly, Talk Python training courses site, but also the podcast ones and a bunch of services and things behind there. With the right amount of static caching and lifetime type of stuff, maybe one request is a little bit slow, and then it was nice and quick after that. I remember sitting in a hotel in Israel, which is quite far away, and interacting with a site and it was much, much quicker than many of the other ones. similarly been in Europe and it seemed fine. Now, that was until last Black Friday. Last Black Friday, I sent out the announcement, "Hey, Black Friday, there's some sales we got going on. Everyone come check it out through email and over social media." And to my, very much my honor, a bunch of people came and checked it out. However, I decided to log into the server and see how it was doing. And I could see the CPU usage on the main server was 85%. That's a little close to the limit, isn't it? It was going up 89%, 90, 91, 92, 93%. If that hits over 100, it's done, right? It just can't keep up, the stuff will, the requests will queue up and it's only gonna get worse and harder for it to keep up and it's just gonna come crashing down. I was like, oh my gosh, what do I need to do? Surely the Python code is not running quite right or something with a database is not keeping up. No, actually that wasn't it at all. Although the Python code was using like 8% of the CPU, the MongoDB server was at 10% maybe. They were just more or less chilling. What was going crazy was Nginx serving up a bunch of static content, a bunch of JavaScript, a bunch of CSS, a bunch of images. I couldn't believe it. And so do you know what will take, easily, easily take all that load off my server and distribute it and make it a better experience for the users? CDN. So that finally gave me the kick that I needed to go, all right, well, if it's not even a Python server-side code problem, maybe I should supply, apply some kind of tool like a CDN that is exactly built for solving these at scale. At Talk Python, we're a small team, me, couple of consultants, some authors, but we don't have a big DevOps team, we don't have a big data center team, none of that kind of stuff. And so for me, I've always avoided complexity, especially operational and DevOps type complexity, like crazy, I want something simple that works, it works well enough that's not too expensive. And so my thought was, well, the CDN is just going to add complexity with cache staleness and in a bunch of things like that. So nope. I also thought it might be expensive. We do about 15 terabytes a month, so 15,000 gigabytes a month of traffic. That's no joke. I mean, I know some of you all out there probably have more, but that is a lot of traffic to be running through one server. So if we were to run that through S3, our bill would be $1,400 in bandwidth every month. And well, my first thought was a CDN is like, if it's going to go to 114 or over 100 different locations throughout the globe, surely it's more than S3, right? So whatever that number is and we multiply it, eh, not really wanting to pay that at the moment. So we'll see that is not the problem. It's actually incredibly affordable, which turns out to be surprising to me. And finally, just honestly a bit of lack of awareness on my part. Like I said, I knew about CDNs, but I haven't really used them for interesting things until I dove into this and started integrating it into our infrastructure. And wow, how cool is it? So hence this course, why we're all here, right? To learn more about it and get better at using them.
|
|
|
transcript
|
2:58 |
Some courses, tutorials, demos, and all those things have honestly incredibly boring types of technology and presentations. It's foo this and bar that and just terminal stuff. Not in this course. I've made a point of picking a really cool technology that is both modern and could be used in current Python web apps. And so let's just really quickly talk through the tech stack for this app that we're going to build. Now, before we do, I want to point out you don't really need hardly any experience with these. You'll need a little experience with Python, you'll need a little experience with the web in general, but you don't need to know too much about this technology because we're going to take that and just plug the CDN into it. But it's here and it gives you a use case for CDNs and this idea, these ideas that you're learning here. So I think it's really cool, the tech stack that we got put together. But again, don't feel like, "Oh my gosh, I need to know all these things." Not true. You just get to kind of play with them, which is fun. Our app is built in Flask on Python 3. We're going to be using Python 3.11 for this course. But as long as it's modern Python 3, we're not using any super crazy new features of it. So Flask is a really, really popular and well-known Python web framework. That's why I'm choosing it. You could apply these ideas to Django or FastAPI or others. We're also using HTMX to allow us to write almost zero JavaScript but get really cool interactions and some of these dynamic pieces that are as we interact with our site are returned little HTML fragments that are live and they of course also have bits that interact with the CDN which is cool. We have a database with a couple of tables that we're going to be working with. By database, I mean a SQLite database, so there's no server-side application to set up for that. It's just going to be a file, but we're going to talk to that using SQL Model. SQL Model is built on top of SQLAlchemy by Sebastian Ramirez, the same guy who created and maintains FastAPI, and it integrates with Pydantic. a super cool ORM that we get to use throughout this course. And we're also going to keep our code extremely clean using Jinja partials, something that I actually created, you can get on PyPI as well. And this allows us to exchange little tiny HTML fragments in reusable ways, kind of like functions for HTML. And those little bits that come back in these partials or these fragments will, of course, As I said, plug in to HTMX and interact with our CDN. So that's the technologies that we're going to be using and they'll combine together to make a pretty awesome web application that we're going to start out being somewhat slow and then make super fast.
|
|
|
transcript
|
3:33 |
Now, before we get into too much of the technical details, getting set up and some of the beginning ideas, I want to show you the destination, where we're going to and planning out what we're going to build. So let's take a walk through the final application to see what things are going to be like when we're done in the end. That way you know where we're going. Here's the app we're going to work with. I called it Video Collector. Get your favorite videos, old school Yahoo style. What does that mean? Well, Yahoo predated search engines. Believe it or not, for all the things that Yahoo became, all it was was basically a bunch of static files sitting on a web server that humans would go around and say, "There's an interesting website and there's another one. This one is under JavaScript and this one is under Apple or this one is under racing." And they literally would just write them down. That's all Yahoo was when it started. So we're going to do that, but for our videos. So we have these different categories of videos here and if we go into the different categories you can see that they've got these are all mostly YouTube videos at the moment but you know here's like the WWDC for Apple. Here's iJustine. Here's a video that Paul Everett and I did together exploring that. We go back and we'll pick some racing and click down here you can actually play these like this video right here is this crazy guy that built a hundred thousand dollar sim racing setup that is mixed reality along with real reality with virtual realities. It's pretty cool. Anyway, you can check those videos out. The point is not so much the videos but that we can collect them here. And here's some more Python ones, some fun ones for sure. So that's one of the features. Another one is we can search. Notice this will do search without refreshing the page using HTMX. So if we wanted to see some of those WWDC ones, we just type WWDC whatever, some part. You'd see stuff about Apple or we could see things about Python or even IndyCar racing. Notice how that's super responsive. As we interact with it, this is really fast and I'm running this remotely somewhere. I'll discuss how I'm doing that, but it's about a hundred or maybe 150 milliseconds ping time away. And yet, look at how, you know, these images are large. Look at how quickly we can bounce around here. Click on the JavaScript one, click on the Python one, super fast. So that's really, really cool. And that's what we're going to do throughout this course. One final feature here, we have infinite scroll. So as you go here, when you get to show three at a time, a little more, you'll, you'll think for a second and show it actually got to make it slow down and pretend to think otherwise you don't really see the loading but there you go. So that's the final feature of this website. We can also add new ones and come down here and add a video but we're not really probably going to do that in this course. Maybe we'll get there but primarily we're just going to interact with the data as it is. So this is the app that we're going to build. Check at how super cool and fast and responsive this is as we interact with it. The CDN is doing a lot of cool stuff for us here along with Flask and Jinja Partials and HTMX. But again, that stuff's all pre-built so you don't need to know how to work with it, but you will get to experience it throughout the course. It's a fun app. I think you're going to dig working with it. It'll give us a chance to see a lot of cool things.
|
|
|
transcript
|
1:02 |
As we close out this chapter introducing the course and ideas behind it, I just want to introduce myself. Hey there, I'm Michael Kennedy. You maybe know me from some of my podcasts and things, but it's great to have you here in this course. If you want to read some of the articles and things like that, some essays that I've written, check out mkennedy.codes. Obviously I'm the host and founder of the Talk Python To Me podcast. So if you don't listen that please give it a look. I'm also the co-host of Python bytes Python News Weekly Show. I'm the founder and one of the principal authors here at Talk Python Training, including this course as you might imagine. It's also a great honor to be a Python Software Foundation fellow. And finally, if you want to connect with me online, find me over at mkennedy@fosstodon.org on Mastodon. Thanks for coming to the course. I'm looking forward to talking about some of these ideas with you.
|
|
|
|
5:41 |
|
|
transcript
|
0:50 |
Sometimes we might start from a brand new application from scratch and you can just say file new project, open up a file or folder and just start going. That's not the case with this one. We're not learning how to build web apps, we're learning how to take an existing web app and make it faster. So there's a couple of things you're going to need to do in order to get set up to follow along and that's what this very short chapter is all about. So I would just at the beginning here. I want to encourage you to replicate what I'm doing here on the screen in my version, replicate that on your machine. Got questions, you're wondering about something, you know, play with it, explore it. It's easy to do with Python and the CDN. So I just encourage you to get out there and play. You'll get a lot out of it that way. All right, let's get into the setup.
|
|
|
transcript
|
1:13 |
In order to use our web application and play with it and follow along, you're going to need that source code. So go over to the GitHub repository, you can see the URL here at the bottom. Also, you can click on just the GitHub button in the talk Python player. Come over here and fork this code as well as start so that you have it on your GitHub account, and then clone it and play with it. Again, the best way to learn this stuff is to play around and try it hands on. So this is just a standard Flask app. We'll talk about getting set up and going in just a little bit. But notice that right now it just says code/starter project. Well, that's because we haven't done anything yet. This is the beginning of the course. As we make our way through it, you'll see chapter three, chapter four, chapter five code show up. And here's the trick. If you want to start at the beginning of chapter five, go to the chapter four code and grab that. That's what we finished at chapter four. On the other hand, if you want to see the final code from chapter five, that'll be in chapter five. So you can jump in at different locations, but I do encourage you to follow along. And we'll talk about setting this up and making it run when we get to it for the first time.
|
|
|
transcript
|
1:04 |
Surprise, you're going to need Python 3 to follow along with this course and run our Python based web application. Now if you have Python already, great, go and run with that. But if you need to get it installed, or verify which version you have, we put together this guide. It's over at training.talkpython.fm/installing-python. Now you will need to make sure that you have Python 3.9 or higher, or the code will not run in Python. The reason is we're using type hints and the way that you could specify type hints for collection types was improved in 3.9 in a way that didn't work in 3.8 but will in 3.9. So make sure you have 3.9 or higher. I don't see any reason you really need any more than that. But I always try to use the latest version. As I said during this course, we're using Python 3.11, which is a nice, fast, new and fresh version at the moment. But if you need to make sure you have the right version of Python or you do need to install it, follow our guide here.
|
|
|
transcript
|
1:04 |
In this course, I'm going to use my preferred editor, PyCharm. I think PyCharm is absolutely amazing. I know not everyone uses PyCharm. If you want to use VS Code, you're more than welcome to. That's the other big choice that people choose. But I'm going to use PyCharm just so you know. And if you want to follow along exactly with me, you're probably better off using PyCharm. Now, you can use the free and open-source Community Edition and not the paid version of PyCharm. In order to do that, you're going to lose just a little bit of support. For example, professional PyCharm has autocomplete and syntax highlighting for Jinja templates, which will be part of the HTML you're working in. We won't have that if using the community edition, but the amount of HTML you write is really, really small, so it probably doesn't matter, honestly. Nonetheless, I'm going to be using PyCharm. If you want to use another editor, go ahead. That's totally fine. PyCharm or VSCode are probably the big two choices that people will be using for this course.
|
|
|
transcript
|
1:30 |
The other thing that you're going to need for this course is an account over at bunny.net. Bunny.net is the CDN that we're going to be using for this course. Again, many of the ideas and concepts and techniques that you're going to learn in this course could be applied to any CDN, Cloudflare, Fastly, whatever, but we've got to pick one to be concrete and use, and I'm a huge fan of bunny.net. I think it works fabulously. So we're going to use this. Be sure to go over there and create an account. There is a free trial, a two week free trial that you can use. So what I'd recommend is make sure you're about ready to start this course and then start your free trial. However, if you think about how much is it going to cost if you for some reason, go past your 14 day trial, it's incredibly cheap. I think I pay a half a cent per gigabyte. And if you did a gigabyte of traffic on here, that would be kind of crazy, that would be a lot. So it's going to be a couple of cents, if you actually ended up to pay for it. But again, use the 14 day trial. I'll actually give you all a peek inside the talk Python account. And you'll get to see our numbers as well. But super affordable, you do have to create an account, but I wouldn't worry about the pricing. It's free or pennies. And that's it. You follow along these steps, you should be all set up and ready to go. So after this, we're going to be writing some code.
|
|
|
|
49:17 |
|
|
transcript
|
0:46 |
With the stage set, we're now ready to start integrating our CDN, into our web app to make all the static content in our website just fly. We're thinking about things like images, but also stuff that's not exactly seen, such as CSS, JavaScript, fonts, all of those types of things. So in this chapter, we're gonna go set up our, it's called a pull zone in our CDN, plug that into our website and then start pulling the static content out of the web server and then we're going to link that to the clients, to all the users of our app through the CDN and the CDN is going to take it from there. It's going to be excellent. It's time to take off and fly.
|
|
|
transcript
|
7:28 |
First step to writing some code is making sure that we can install and run the web app on our computers. So let's do that now Over here on the desktop I've checked out the github repository for the code the one that I've introduced in the introduction to this course Now we don't have all the code There's gonna be a chapter four and five and six because we're working our way through it, right? We're creating that code as part of the course But other than that, this is exactly what you'll get when you check it out from source control. So what we want to do is we want to run this web application in our editor on our computer so that we can play with it. Now again, I'm going to be using PyCharm down here. You could also use VS Code. Those are the two good options. Now in order to do this, you can see that we have some requirements that we have to install here. And in order to do that, we want to create a virtual environment. So there's a couple of ways I could do that. I could open this in PyCharm and have PyCharm create a virtual environment. It'd open in VS Code and then create a virtual environment or I could do the environment stuff manually. So you see how that works. I'll do the manual way 'cause the others are pretty obvious. All right, so let's open up a terminal here. You can see that we have some requirements. Now I'm a huge fan of using this tool called pip Tools. pip Tools allows you to state your top level requirements without version pinning. So for example, here's a list of basically the stuff I said is the tech highlights of what we're covering, Flask, Jinja Partial, SQL Model, and so on, okay? What we can do with that is we can run a command that says snapshot this and create a report and requirements file that we can use to actually manage our requirements. And that is over here in the requirements.txt. Notice how it says you have Flask 'cause you asked for it, but you have it's dangerous because Flask needs it. All right. Now you don't need to worry about this and run those commands or anything. I just wanna let you know what's going on there. It's also highly recommended there. All right, so I wanna first create a virtual environment. So that's Python, let's say Python 3-M, VENV, VENV. not active yet, so we have to activate it. So I'll say -venv/bin/activate. Notice the prompt changed over here for me, but it may change on the left for you, but it should change somehow to indicate it's active. You can always ask which Python 3, and it'll show you where it is. On Windows, you would not say this. On Windows, you would just say venv\scripts\activate.bat. activate.bat but we're not in Windows so we're not going to run that command, right? It won't work. Now we need to install our requirements, but first let's say pip install -u for upgrade pip, make sure we got the latest pip. I think it's almost a bug that Python always gives you the old outdated pip and then turns around and complains to you that it's out of date. You should just upgrade it as you create a virtual environment, in my opinion. Anyway, let's say, "pip install -r requirements.txt", that's the one you want. There it is. Now we can see that they should all be installed at their latest version, more or less. So excellent, we're ready to go and we can go back and now open this in our editor. Again, you can open it in VS Code, you can open it in PyCharm, whatever makes you happy. We're using PyCharm on my end. Now on macOS I can drag the folder and drop it here and it'll open. Let's make a little room for a second there. In Windows you can drag files but not folders. Last I checked and so you've got to just go file, open directory and browse to it. Same thing you can drop it on VS Code. Now PyCharm is a great tool but it has always had this kind of weird relationship with virtual environments. It like it understands them and understands them. it kinda doesn't, then it does again, and then it kinda doesn't. At the time of this recording, it's in a I don't really understand them anymore mood. I don't know why. Notice here it says Python 3.11, great. But that is Homebrew System Python 3.11. Great, so we'll add a new interpreter, local, and it suggests exactly what we wrote. But it says, oh, Warning, you can't do that. That's already taken. Guess what? Maybe you should just use it like you did suggest it automatically earlier. Anyway, you got to make, go over here and say, use this one, and it should change down here to start using the right virtual environment. Right now, the other thing that we're doing, there's two ways to work with the code here. One, you can go into each folder. I can come over here and say, okay, right now I'm on chapter three, make a virtual environment here and open this one. I'd like to work with a starter code sometimes, so I'll make a virtual environment and open this one. You can do that. and it might be easier depending on the tools you're using. Because for example, if I come over to my app and I say import DB, I try to run this, it's probably not gonna like it. Let's give it a try, see what happens. Oh, it did work, okay. Looks like there's a leftover Python running from when I was playing with earlier, gotta kill it. But the editor is gonna have some issues with this. For example, This is the working directory. That's probably what it changed over here for running correctly is where is the working directory? Yeah, that's why that worked. But over here in the editor, when it sees import db or from db import something, it'll potentially look here and say, "Well, I don't know anything about that. I don't see any db here. I only see code and course image." So what we need to do is come over here and right click and say mark directory as sources root. So in PyCharm, you can cycle between these. I can say, oh, actually unmark that one and mark this one now because now I want to run that, that DB, not that DB. Okay, so we can go over here and right click and say mark directory as in PyCharm and you probably need to do that for everything to hang together just right. So make sure you only have one of these marked as blue when you're running it in PyCharm. Alternatively, like I said, just open up that folder as its own project or that folder as its own project. Let me quickly fix that port sharing issue. There we go. I just had another copy running in the background. All right. So now we should be able to run our code. Starts up super quick. Click on it. So there you have it, running locally on port 10001. There were some conflicts with the way we're sharing this over the internet for the CDN along with AirDrop on my Mac, so 10001 is the port instead of the default 5000, but nothing really special there, just trying to make that work and not conflict. And here's our app, again, just like we saw before, as we click around, it's working great. So everything's set up, ready for us to make changes to our code.
|
|
|
transcript
|
3:36 |
Let me walk you through the codes because I have a very structured layout for the way I like to put my web apps together. And a lot of how the structure is tells you exactly where to look to make changes, who are to understand what we're working with. So we have our app. This is a standard flask. There's not a whole lot going here. But notice in this register blueprints, we've broken up all the different HTML or URL endpoints into separate files all within the views folder using the blueprint pattern from Flask. I really, really don't like putting just everything into one file. It makes it super hard to work with, super hard to know where to go and how to organize things. So I use this blueprint model. So for example, over here in home, we have a blueprint. And instead of saying app.get, we say blueprint.get and we bring that back in. So if you care about stuff on the homepage, it's here, you care about the URLs, about videos, like here's the video categories or playing a video, it's in this videos folder, all that within the views. Now that structure tells you a lot. I'm using this pattern called a view model pattern. And over in the view models folder, well, there's a mirror image of the way that the the views themselves are structured. So we have a videos folder, we have a home folder and a feed folders. And in the videos, we have a category view model, a play view model down here, we have a get, get for adding categories, and we have search, for example, a search view model to use files for grouping them. And then we have these view models. And we We have a separate class, for example, this one that knows the data that we're trying to work with and how to exchange it with the HTML templates. Speaking of templates, go over here. First of all, there's a problem with the way PyCharm understood our project. So see how this is gray? It should be marked as a special template thing so we can right-click, at least in PyCharm Pro. I don't know if you can do this in standard community PyCharm. So, say market as a template directory, and that tells it this is where the templates are, it creates some like auto-complete, jumping around intelligence. Again, just like before, we've got our video views and we've got our video templates like search play and show category, okay? We have our static content, that's gonna be a big topic of conversation in this section and this course. And then we have a bunch of database stuff down here, things that mostly are just leave them alone, put them back there. So for example, if we go to services, and we go to video service, like here's how you might do a query to get all of the videos, or here's how you do a query using SQL model to get all the categories. All right, and here is the quote database, the video collector DB, that is the SQLite data model backed by, are fronted by, I guess, by SQL model. And yeah, that's pretty much it. If you understand those pieces, you know how to find your way around, right? So the views are over here. They all have methods and those folders and those methods help you locate, basically, your way through the rest of the application.
|
|
|
transcript
|
2:23 |
When we just ran that app, I bet it felt super zippy and really fast. You know why? Because local is always fast. It doesn't really get much faster than I need to download that image So let me just read it right off of disk basically or run it over local loop back on the network. It's always fast and We're not concerned about using a CDN to make local code fast we're trying to use the CDN to make the stuff at the far edges of the globe compared to our server but not our users, we wouldn't make that fast. And so we need to do something other than run it locally in order to actually test that. Now we could go and set up an actual web server topology in one of our data centers. We could create a virtual machine or use a platform as as a service and say, well, here's Nginx and here's g unicorn or micro wsgi, and we're going to do all the trouble to set that up and manage a server. Now we're not going to do that I'm going to show you something that will actually simulate the same thing and is kind of properly slow, but not so slow that it's terrible. It'll be great. So we're going to use this thing called ngrok. ngrok if you have not heard of this is a super cool tool. What it does is you run your code locally, you never ever put it on the internet. So for example, notice up here that it says localhost colon 10001. That's where our code is running. But what it does is it creates a reverse SSH tunnel back to our system and it puts that on the internet at cdn-talk.ngrok.io. We can share that. So we're going to share that with our CDN so it can get to the static resources and stuff that it needs to sort of begin the process of seeding the whole network with them. But this is great if you're just working on a project and you're doing some kind of meeting with a client or your team members, you say, "Hey, look at it running on my machine." And instead of just screen sharing, you just give them that link and you let them explore it live and you can even debug it. I've used this to debug API interaction with our Talk Python mobile app and our backend API. So really, really cool. And we're gonna use ngrok for setting up a slower public interface to our web app.
|
|
|
transcript
|
3:45 |
If you have Ngrok already, fantastic. Welcome to the club. If you don't, then go over to ngrok.com and you can download it here. Just click download and you can install it with Homebrew or you can just download the Apple Silicon version. You can check out pricing. You can see that it has this free tier which would be perfect for what you're doing. I actually have this paid one that allows me to use more stable subdomains instead of, normally it just creates what's called an ephemeral or random domain and it'll just change every time. So you kind of gotta, if you do this, either just leave it running or connect it, go back and update the connection at the CDN. You'll see how to do that in a minute. So once you have it installed and set up, you can say ngrok HTTP and let's say 10001. It's not our final command, but let's start here just to see. So what this is going to do is it's going to create this ephemeral random domain over HTTPS, which is pretty excellent. And then if I click on this, it's going to loop over to local port 10001 and in PyCharm, I still have this running. Okay, so it's hanging out down there. No connections yet. But if I click this, notice it's pretty slow. Look at it dragging along here. But sure enough, our stuff's coming along. That's our web app. We can go over here and we could search for Apple. And there are our results coming in slowly, which actually is really good because it's gonna give us a huge opportunity for speeding it up. And you can see behind the scenes how it's pulling in some of these items. Okay, so we're gonna use ngrok to see how this can be nice and slow. And I said this is not the final command I'm using because notice that number ends in E05. If I run it again, now it ends in 029 every time this changes. If you have a paid account, I recommend that you, let's call it, and talk is fine. You can put a subdomain here and it'll create something. Now, as of two days ago, they just deprecated that, but I'm not sure how long it'll last. There's some other features instead. There's a replacement feature instead that's a little more involved, but you should probably be able to do this for a good long while. Anyway, I can now use this and it won't change from time to time when I run it. Still takes a second for this to all come rolling in. There we go. We have our website on the internet temporarily until we shut down in Grok. It's got a decent, somewhat slowish ping time. So we could come over here and say ping that. And look at that, it's about around 100 milliseconds, which is slow enough that we can actually get, oh, look at that, it's bumping up for a few times. It's slow enough that it'll give us some real benefits when we get to the CDN. It's not at all local. It's not just read that file over local loopback. So in Grok, while we don't have to do much with it, we just set it up and point it at our website here, and then we just use this for the rest of the time to get to our website, to feel the natural slowness of it, not the fast local version. There's not a lot of effort to make this happen, but it's a really important aspect that allows us to avoid paying for server infrastructure, setting up Linux, making sure we don't forget to turn that thing off, end up paying for it in the longterm, all those things, right? Really nice and simple way for us to accomplish, what we're doing here.
|
|
|
transcript
|
4:03 |
Before we open up the admin section over on bunny.net CDN page, let's talk real quickly about the different kinds of options and how the CDN might interact with our data so you know which one to pick. We're going to talk about something called a pull zone. And those are basically the origins that feed data into the large CDN network that is then shared with the rest of your users throughout the world. And we'll see how those click together. So let's imagine we have this web user, they're over there on their browser, could be a phone, it could even be a mobile app accessing the data over an API, doesn't matter. They just wanna make HTTP requests to your content. And so in the HTML, we're gonna put a link that says instead of forward slash static/image, it's gonna say CDN domain/static/image. As far as they're concerned, they're never getting data from your website. They're getting it from the CDN. So once they've gotten the HTML, their browser says, well, let's go look for these static files. And it asks the CDN, hey CDN, I'm looking for cat.jpg. CDN says, nope, no cat.jpg here, but that comes from a pull zone. And the pull zone is associated with this web app. and let me spring into action to first populate the network if I can find that file. There's two ways in which this might be done. It might be done through having something like S3 or some kind of cloud storage. So it could be a cloud drive over here and especially the CDN itself has a way to sort of connect its own cloud drive that it will look at, which is a really great option because it's local and super fast and even replicated for the CDN itself. So it might say, is that over here? But that's not the kind we're talking about. This is like large content, we're gonna come back to this later. So no, not this. This is one option, it's called a storage pull zone. It's not what we're doing now for our static content. What we're gonna do is we're gonna say CDN, you give them this public URL, kind of like ngrok actually, and you say, but come look on our website for the matching content. So they, the website, the web browser has said, I want cat.jpg. And it tried to get it from the CDN, the CDN knows about our location on the internet. So it comes back and says, I want /static/cat, cat.jpg. And our website says, great, I have that. So let me go pull this out of my static files here and I'll give it back to you. When it does, the CDN starts to replicate this to different locations. Probably not automatically, but as users ask for it from different regions, it'll replicate. We turn on what's called origin shield, transfers will start happening within the nodes of the CDN and not ever make its way back to our web app potentially. So it really takes the load off of distributing it. So this is called a URL or origin pull zone. Right, so we have these two kinds, store zones or origin or URL zones. For the static content section, what we're talking about is this web server style, this URL zone. We're gonna do that pretty much 100%. When we get to the large content section, we'll go over to the storage zone. This might be MP3 files, this might be video, this could be user generated content like, here's a ginormous PDF I uploaded to the website and I somehow need to share that back. Right, you wouldn't check those things into source control and then associate them with your web application. At least my rule of thumb is the stuff that's checked in the source control and the web app itself serves, that comes out of this origin zone. For the most part, loose files that are kept alongside your web app separately in things like S3 and other cloud storage, that probably belongs in a storage zone or pulled directly from places like S3.
|
|
|
transcript
|
10:25 |
It's time to start configuring the CDN. Drop over to bunny.net. Remember in this setup section, we talked about creating your account. So you are going to need an account here. You've got the 14 day free trial. It's even when you pay for it, it's basically free. You know, a couple of cents. You went crazy for using data during this course. So no problem, but you do need that account. So once you have your account, go over and hit login. Here you can see the talk Python panel. This is all of our infrastructure and stuff running here. So you can actually, I'm gonna show you a little bit about what's happening behind the scenes. Notice we're doing at the moment about 14 terabytes of traffic and a little over 2 million requests in the last 30 days. And amazingly and really great, 88% cache hit rate. So 88% of the users who come to it are like, yep, you've got this, or we're serving it out of a node and don't have to come get it from another node or even from the origin servers we just talked about. We have some storage zones. You can see we have our podcast and our course video. In fact, this video right now that you're watching and hearing is coming to you through bunny.net, through that storage zone right there. All right, that's the large content section. We also have these pull zones and this is what we're gonna set up. We're gonna set up something called a pull zone. Before I move off this page though, I just want to point out our traffic here is 14 terabytes. Our price is $40. And look at this, this is 18 times cheaper than S3, Amazon S3 or Azure. Incredible. Last time I checked, those were 9 cents a gigabyte for bandwidth. This is half a cent. Really, really good. Another thing to be aware of, these numbers across the top, those are a 30 day rolling average. These numbers across the bottom, this is calendar month. So they don't exactly line up. this really is more like 70 or 80 bucks a month, but it's still considering that much traffic, it's nothing. Okay, this chapter we're messing with pull zones, next chapter storage potentially. There's cool stats and other stuff you can see. We'll go and pull up the stats, see what we can see here before we get to them. So here it'll give you numbers like, oh, look over here, we served 775 gigabytes, but only 24 of that was uncached, which is great. or you can see which one this is the origin shield and for that 47 gigabytes of traffic that it served internally and only had to go back to the server for six, seven, eight. Some of those also may be the storage as well. So that is even less traffic on our server. But again, cache versus uncached. And here's a really cool picture to explore is actually use this for the course image. So you've seen this before in a sense, here's all the different nodes and the brightness or darkness of them shows how much of your data is in that particular, what's called a point of presence or POP, basically local server, file server on the internet. And then down here, it'll show you how much storage you're using there. So for example, in the Chicago data center, we have five terabytes, in Miami we have a little under a terabyte. All right, enough of the survey, let's jump into this pull zone. There's two kinds that you can have. You can have a standard one, which is built for like CSS files and images, or you can have a volume one. The volume one we use for MP3 files that are 50 megs each or video files that are more potentially, sometimes they're smaller, but a lot of times they're a couple of hundred megabytes. So that lets them to be a little bit cheaper. And here's this one that I've already set up. I'm gonna actually copy this URL 'cause I'm gonna need it in a second. We'll go and set up another one here called VideoCollector, let's say class. This is what I was doing to demo it before. We're gonna create a new pull zone. The name, so this is, this name you put here, you may never use this, but you can, and I'm not gonna, because I don't have a domain for our VideoCollector site, I have to use this. If you had your own custom domain, you would probably use a subdomain. So for example, it's like images.talkpython.fm or videos.talkpython.fm, something along those lines is what we actually use on our site, but there's a b-cdn.net equivalent one that we could use. So that's what this is asking here. We'll call this video collector. Just like that. Let's go with this. And here's those two types of storage zones we had in that animation, that previous video. Do you want it to come back to your web server and serve it as if it was a local browser of the website or do you want to put it into a cloud drive that you manage independently? We're going to use URL for this static content that we're talking about. Over here, this says where if I have to go, if somebody requests something and it doesn't exist in the CDN, where do I go find it? Or if it expires, you know, the cache time has expired, where do I get a new copy? So we're going to say go to the ngrok destination. This is the point where if you don't have a paid ngrok plan, this is going to keep changing and as you shut down and open ngrok, you just need to come back here and edit this field. It's super easy, but that's how it works. Here we have the standard tier, not the high volume tier for this one because it's optimized for more performance, not for large files. And then you can also talk about where you want to be available. Do you want to be available in the Middle East and Africa? Do you want to be available in Europe? Here's the cost that you pay for these different locations. It's slightly different, but that's fine. I'm going to hit add. It gives us a little bit of help on how to get started. It says, The public domain and the public URL with your previous static content was things like What you said your domain was so we the CDN and grok thing /images /logo, and it says alright. Well now you got to use your CDN Prefix and okay great ready to go if you wanted to add a custom domain like Static.video collector.com I have no idea what that is please don't visit it You would set that up with your DNS and this actually guides you through doing that. If you need to come back and edit your ngrok, just edit it right here, okay? So we're only of this one, but you can have multiple ones. That's how we do it. So we can click on the origin. It says what type again, you can figure that. It says what is the price you're paying? You can tell it how to deal with timeouts and if it can it'll replay things. This one's important. We come over here and say caching. I want to It can take a guess on what to do that doesn't make me happy. So what I'm going to do, it could let our website communicate the caching ideas. But I'm just going to set this really high three months. And you'll see that while that might give you the idea we're going to lead to a lot of stale caches and problems, it's not going to absolutely fix this. Do you want to let it normalize the query string order? Sure. And then this one is important. We don't need it now, but we'll need it later. Set URL query string querify. We're going to do that because we want to be able to prefix something on the end to say, "Here's a new version of file like question mark v=2." That'll give us a new CSS file or a new image or whatever we put that query string on, but only if you turn this on, it's off by default. Okay. Yeah, it looks pretty good here. So you can say also you even serve out of a stale cache if things are broken on your server, you know, leave that off. What else can we do? We're going to go down here to origin shield. And I can say enable origin shield. So what this will do is says, if somewhere in the CDN network, the file they're asking for exists, instead of coming back to my server, say, there's a user who's loaded in the CDN South America and then someone in Australia comes back and tries to access it. Instead of going to my server, keep it within the CDN. Okay, so that's what this is about. That's always good. There's lots of security, including restricted files and stuff that you can do. You can pass along headers, for example, you can do cores stuff or link back to your site if you need to. A bunch of other things. I think we don't really need to worry about these. I guess the last one is, if you really need to clear out the cache, you can just blast it away right there, but we shouldn't need to. All right, now we haven't done anything yet. Let's see how this works. We'll go back to our website here. Here's our website, but remember, we don't want this one. We want the ngrok URL. So I'm going to launch it from here again. And notice it's coming in really slowly. There's nothing that has gotten better with what we did over the CDN yet. It's all the same. So what I need to do is I need to open up one of these images. Let's go here and say image, open in a new tab. And this is our ngrok version. But what we put into the CDN is we said we want to use video collector-bc. This is not a great name. I would use a subdomain if I were you, but we don't have a subdomain. So here's what we got. But we hit this very first time, it's a little slow. The CDN actually came if you look at ngrok, it came over and requested that right there. That was the CDN that did that, not us. And then the CDN served this up. But now if we hit this again, notice, basically instant and also notice down here not coming back to our website. It's there for three months in the server until we either go and explicitly delete it or it's just going to be there for three months. It's there for a good long while. And super fast, going to start geo-replicating. Beautiful.
|
|
|
transcript
|
2:32 |
It looks like this URL pull zone is working for our web app through ngrok back into the Flask development server running in PyCharm. How insane is that? But we're ready to go and actually start adding the CDN aspects, the CDN URLs to our static content. So let's jump over here and open up. Let's first go to the homepage here because in here we've got our content for our image. So when we see /static /image /categories, so like over here, /static /image /categories, and then we have this Apple Webp, that's the category icon up here. We need to add this, this prefix to it. So we're gonna come over here and for now, just put this. We're gonna run into some issues with it in the future, but for now, we're just gonna put that there. Here's one thing that's really important about this web app, it doesn't auto reload the views. So in order for this to take effect, be sure you shut it down and start it up again. Not ngrok, just the web server for the Python code. Okay, so now let me put ngrok in the back here and I'll put this over to the side. So if we refresh this page, it's going to need to go and find all those images at the CDN location. And when it does that, it says, well, that's a URL zone. So we're going to come back and ask the server, it's at ngrok, which is going to route its way back. So you should see these requests start showing up over here. Look at that. Here they come. And you see them rolling in nice and slowly. That was slow, wasn't it? All those pages. It was slow because it was slow for us before. It's also slow for the CDN to load it. But now if we load it again, boom. We go back over to search. We come back. Wham, look how fast that is. Because where are these coming from? Let's do a different one this time. Image, open a new tab. Look at that, it comes out of the CDN. And I can load it again and again and super fast. Cool, right? So that was easy. All we have to do now is find everywhere else where we were doing some /static /something in our website and upgrade that.
|
|
|
transcript
|
5:11 |
Well, we got one done. Let's find the rest. I'm going to do a search throughout the entire project for /static/. Everything that is static content in this website comes out of that static directory and also only interested in the HTML files. Let's open that in the find window so we can make our way through it. That one we don't need at the moment. What about this? Nope. These are comments for us for later. All of these are actually comments up here, so we don't need those. All right, this one, /static/imagebars, this is for infinite scroll. It's getting the CDN prefix here as well. That's the one we already added. We've got a bunch of CSS files here. So same thing, we want to serve them out of the CDN. We could use a different pull zone and a different domain, but it turns out to be not that great of an idea. I like using the same domain here. This part of the top about using the CDN, that's what we're doing. And this beware caching is stale caching. We'll come back to that. Now it looks like something's wrong. Like PyCharm's highlighted this as there's an error. It just says, I want to download this so I can do autocomplete out of it. We'll let it do that in a minute. back to finding all these items. Down at the bottom, we have a bunch of JavaScript. So we're gonna use the CDN here. Here's our HTMX. All right, those are all good. And what else we got? Okay, excellent. We got the thumbnails for the videos. So put that in there. Here's the category image. Now, when we load up the category, it takes that banner image and puts it as like a hero in the background. So we'll put also want to load that out of the CDN, why not? Some more infinite scroll. Oh, be careful, these are in the starter project that I don't want. I don't want to mess with those. The rest of these are all in starter. Okay, so it looks like we've made all those changes. It's a little tedious, but I did want to actually go through it with you just so you saw like, yep, it just means go through and replace all these things. Let's run it again. And now remember, it's so tempting to click this and go, "Oh, it's so fast," but that's not what we want. We want to make sure that we're using ngrok because that uses the CDN in the proper way, right? So let's click here and see what happens. Nothing, because this page seemed to be out of the CDN, but did you notice up here it's still thinking about it for a minute? Let's look at this. Look, it's going and getting all of, all like the fonts and the CSS and the JavaScript. But if we exit and start again, and we click here, super fast, super fast. All it did is go get the HTML from forward slash and then it said, well, you need the CSS, you need this JavaScript, you need these images. And it went to the CDN or it believed the CDN when it said you can cache it. away, it didn't come back here. Let's try again. Let's go to one of these. I'll click on Apple for the category of videos. Notice it's pulling a bunch of these thumbnails. This is the CDN again coming and getting all the thumbnails to seed the network through the URL pull zone. But if we go away and we come back, nothing. It just does videos category Apple and then slash(/). Then, sorry, it's at the top. Videos category Apple slash(/). No more content because all of these images you see flying in, they're flying in off of the CDN. How cool is that? All right, let's try one more just for fun. Let's do Python. You can see them coming in slowly the first time because the CDN had to load them coming in there, but subsequently, bam, super fast out of the CDN. And importantly, let's go and this is Vivaldi. In Vivaldi you can hit control on Windows or command on Mac, command E or control E and say dev tools or view source. Super cool browser. But check this out. We've got the video collector. Here's our bootstrap and that's coming out of the CDN, no longer out of our site. Here we've got HTMX coming out of the CDN, no longer out of our site. for the images, same thing right there. Very very neat stuff. So you can see that it's picked up not just the static stuff we see like the images but also things like all the JavaScript and CSS and all those extra requests. When you saw the 109 requests from the course catalog page, almost every one of those came out of the CDN in just the same fashion.
|
|
|
transcript
|
4:27 |
Our app is so much better. But there's a few things we can still do to make it better still. And one of them is this thing called Preconnect. You probably haven't heard of it, maybe you have. It's one of these more esoteric but powerful tags or features of HTML. And the idea, according to the developer network over at Mozilla, a great place for HTML resources, It says you can use this as a hint to browsers that the user is likely gonna need to talk to this location, that you put into the pre-connect URL. And therefore, if you can start the process of resolving that DNS name to connecting to that server, so by the time a little bit farther in the HTML, you see I need to get an image or a CSS file from that location, you already connected and most of the work is already done. So we can hint to all of our pages that you're gonna want to connect to the CDN somewhere in this page. So please, as soon as you can, get going with that. All right, let's put that in place. Now, the way I've designed this web application is if you look at say home, what it's doing is it actually extends this shared layout. That way, when you look at the different pages, so for example, you look at this page, it has this nav stuff over here. You look on this page, it has that nav. it always has the same footer, the same CSS, right? We can just leverage that and say, you know what? This shared section over here, way up at the top, we can come in and probably sooner is better than later. I put a comment to remind myself there's a good spot. Let's put this pre-connect here and instead of example.com, we're gonna connect to that. That's the CDN. Again, if this was your subdomain, you would put your pre-connect for the subdomain there. Now, I don't like this having these weird colors, so I'm gonna tell PyCharm it can download it. In order for this to work, you have to have ngrok running and you have to have the site running. So, that's how it loops back to actually figure out what this is. So I'll say download, although it may not be necessarily the second time because it's cached, you know? But I'll just do that to make these warning looking things go away. Now, let's just run this and make sure there's no warnings anywhere. Remember, in order for changes to the HTML to apply, you need to restart it. Probably some flask setting I could set, but I didn't. Now, also, it opens here, but let's not do that. Although that did do the pre-connect, let's just kind of make a habit of using the ngrok variant. So there it goes, and we click around a little just to see that, yeah, this is a pretty zippy web app already. And let's pull up the dev tools and just check and see that there's no warnings in, say, the console. Now, this is not a big deal. It's just looking for a lookup for the minified JavaScript. So these we can ignore. I don't like seeing them there, but I don't really have the map files to share, so there they are. But there's no other warnings other than this, like we're missing some debugging stuff for some of our external JavaScript files. Yeah, it looks great, right? It looks like there's no errors and our pre-connect is in there. Pull up the page source and sure enough, there it is. Yeah, that's the one. Oh, one more thing I did notice here just now. I didn't check this on the pull zone. This is important. Notice we can visit this and actually get the whole site. That's not great for SEO and canonicalization and stuff. So let's go back to our pull zone really quick here. And it was a security, yes, block root access. Okay, so we don't want them to be able to pull up that site and get to something like this. Let's try it again. Here we go. Hard refresh, forbidden, 'cause I told it to cache that for three months. So nope, it can't go here, but you can go to static/images or anything else under there, right? So you wanna make sure that people can't navigate through the CDN and get a clone or a copy of your website. So make sure that, go to security and say block root access. Here we go. All right, Preconnect, making things even a little bit faster.
|
|
|
transcript
|
3:35 |
CDNs are fast, but it's faster still if you ship small images over a fast network rather than large images over a fast network. I have two recommendations for you. On the CSS, JavaScript side, bundling and minification are still relevant here. That always helps. On the image size, one, choose a more modern format. So PNGs are great. They're really, really high resolution. But here's the screenshot that I had on part of the slides earlier, and it was 1.5 megabytes as a PNG, and it's only 1200 by 800. That's not very efficient. I exported it as a JPEG, which is common on the web for stuff that can be lossless. It doesn't have to be super precise lines and things like that, like this image. And it went way, way down to 342K. That was pretty good. But for quite a while now, actually, there's been a new format called WebP and a video equivalent called WebM that Google championed, but all the browsers support it these days called WebP. And exporting this as WebP gave it 208 kilobytes. So that's basically 50% better than even JPEG. And there's a lossless variant that would be probably better than the PNG. So choose good formats. The other thing that you probably haven't had a lot of experience with but is super easy, takes a little while but it's super easy to do, is to minify your images like you would your JavaScript. There's different tools you can use for this. There's one called ImageOptim. Now this is only a Mac app but it links to a bunch of tools. It's basically a front end to a bunch of open source tools. which is open source itself, that can be run across your image. So what it'll do is it'll do things like scrub out EXIF information. It'll say, yeah, you're using some really high color palette here, but in fact, you only have four colors. We can completely take that huge color palette and super precise data out and replace it with like, this one's green and that's black, you're done. Right, and it will do this with 100% lossless transformations. There is a way to let it be lossy, but by default, it will just take all the stuff that has no perceived difference to it, and it'll take that out. So really, really cool. The way you use it is you go to your static folder or even just the top root of your website and just drop it on the folder. It'll traverse everything, look for all of the PNGs, the SVGs, the JPEGs, etcetera, and it'll minify all of those in a lossless way. So really, really awesome. If you've got a website already, maybe make a copy real quick the first time you play with this, and then throw it in here and see what happens. It gives you this little report, like here it said it saved 41% on one of the files. I've had huge success with this, really bringing like 30, 40% of the size out of my images. So it's great. It doesn't work on WebP. I think WebP already, the format itself, brings these optimizations into it. But many of the traditional formats, JPEG, PNG, and so on, give it a try. It'll be a lot faster. 'Cause serving smaller files over the same fast network is only gonna be faster, right?
|
|
|
transcript
|
1:06 |
Finally, let's end this chapter with a quick little bit of a warning. If we're caching stuff super hard and replicating it and sharing it with people throughout the globe, you clearly don't want to take somebody's private content. Like here's the listing of your account page with your email address and the last four of your credit cards, and then give that to someone else when they tried to get to the account page and said, "Well, I got a cached version for you." Guess what? Here it is. So my rule of thumb is just don't put private content through the CDN and be careful with that. The way that bunny.net works is if you return a cookie as part of the response, it thinks that might be private and it'll never ever cache that. I can't find that in writing and I don't see any documentation on how to deal with this. But when talking to the people there, that's what they said. So I would just say don't, don't serve private content through this CDN. just not what it's for at the moment. There's stuff that they're working on that might make this awesome and possible but at the time not yet. So just be aware of this, okay?
|
|
|
|
26:27 |
|
|
transcript
|
2:12 |
We've seen how awesome the CDN is for our static content, CSS files, JavaScript, and even somewhat large image files. But there's a whole class of content that doesn't belong in that workflow. It doesn't belong in our app being served out of our app. If you are working on like legal documents that got to be signed and you've got a 50 Mega byte contract word file. Should you serve that out of your file out of your website? Probably not. Chances are you're not even including that file in GitHub or in your source control and it's not really in the static folder. Maybe it's coming out of the database and then it probably would actually possibly go through that same previous CDN style. But if you have these large files just laying around and you're not putting them in source source control, maybe you serve them up a different way. Especially user-generated content that is really, really large. Here we have a video vlogger type of guy here and his video might be 100 megs or a gigabyte. You're definitely not going to want to put that in your database in source controller in your static folder. You're going to store that on some kind of cloud drive. And even more boring kind of behind the scenes stuff, like maybe you're generating reports. And those reports are large documents, like analytics out of your site, and you want to store those, generate them point in time, save them to disk and be able to serve that content up, either by serving up a large JavaScript file than having some client process that or just storing a PDF and serving it. So all of these use cases and many more that I'm sure you can think of are what we're gonna talk about now in this chapter. When you have content that you want to serve through the CDN, you want it to be globally distributed and you want it to be as fast as possible, but it's not part of your application. It's not in source control and it's not served up by your app directly.
|
|
|
transcript
|
1:49 |
For these large media files and user-generated content files that don't go in our application or in source control or things like that, where do they belong? Where do we serve them up? Certainly, one option is to create an S3 account or a DigitalOcean Spaces or Azure Blob Storage, put your content over there and then point at that with some kind of URL pull zone just like we did with our static content, but pointed over there. However, that might not really be the easiest case. If the goal is to take these files and put them somewhere that the CDN can serve, you can actually put them into object storage inside of bunny.net. So you've got this blob or object storage that's very similar to AWS S3 or Azure blob storage. And then that gets stored in one location and then the actual blob storage gets replicated globally. You can pick how much that happens and then you front that with a pull zone just like we did for our static content and that can be a better experience for people accessing that content through the CDN. Now, would I use this as my one and only place to store that data? No, I don't usually store any important data in just one place ever. So I might have also an S3 storage or Azure Blob storage or some other backup mechanism for this, you know, just in case like you should your database and you should many other things. But for the process of actually getting this data up onto the website and serving it, this is actually a really, really cool option. When it creates some of this object storage for some large user generated content and then serve it over our app.
|
|
|
transcript
|
1:39 |
Let's jump over to the bunny.net panel, the admin section. Notice over here for Talk Python, we've got a couple of storage zones. These are where these objects are stored, these binary objects or large objects are stored that we can serve up. We have two that we're working with. So if we go over to Talk Python and we pick the latest episode and we click download, watch where this goes. - Agreed. - It's going to the downloadcdn.talkpython.fm/the file. So that's this one right here. And when you're watching a video, this very video right now over on Talk Python training, if you go and watch a video over here, all of this video content is delivered through this particular storage zone. And let's bump over to the pull zones real quick. You can see here we've got Python Bytes, same story, there's its downloads, here's the Talk Python downloads and the videos for Talk Python video. If you scroll over, notice here that we've got the volume tier and also see this color with the folder icon, the origin? This is HTTPS Pythonbytes.fm, this is Talk Python and so on, but these, these are the storage zones here that we're actually pointing at. Okay, so that's how we're serving up those two pieces of large content. And that's what we're going to do for our demo app here as well.
|
|
|
transcript
|
2:15 |
We're on to a new chapter. So a new set of source code. Now over here, we've got our chapter three static content. And now there's a chapter four. It's basically the starter code from the previous one. But a big important thing to notice to see this blue appear, this is still the one that we're working with. So we need to right click mark directory as unmarked sources route or hit the hotkey, which I'll be doing in the future. And come down here and mark this one as the sources route or again hit the hotkey as I will be doing in the future. So over to chapter four, right? Make sure you run this one. I've already set up something with a run configuration with a better name, but you know, right click save run that to get this to run. And let's go over here and have a look where we might So be able to use this storage. Now all of these traditionally have been YouTube videos. So if I go over to the racing ones, every one of these is some kind of YouTube video, right? So for example, if we watch this one, you can see that it's talking about trail braking, which is a technique for getting more traction when you're trying to go through a corner, posted on YouTube right here, right? This is all the YouTube player. Most of these videos are just things we've collected off of the internet. However, let's look here, for example, in this one, This Michael Kennedy one. We've done this one, we've created this ourselves. We own this. Maybe we don't want to host it on YouTube for the purposes of this course. Maybe we want to host this ourself. And in the Python section, there's a bunch of these that are ours. So for example, this talk Python interview I did here, this Python bytes one, another Python bytes, this HTMX interview I did with Carson Gross. All of these are our videos or my videos. and maybe we want to self post these. And we do. So what we're going to do is we're going to actually stop linking to the YouTube videos. We're going to put, I've already downloaded them and I'll provide the video files to you. What we're going to do is we're going to put those in this storage in bunny.net and then feed them through our CDN and you'll see they'll probably behave even a little bit better than what we're getting out of YouTube.
|
|
|
transcript
|
1:08 |
Over on the GitHub repository, I've added a link to these large files that you're going to need. So if you scroll down, there's a section that'll say "Large files used during the course." And here you can click this and download about a 1.1 gigabyte zip file full of five MP4's that we're going to use as our user-generated content that we want to deliver through this object storage. Now, just be aware that where this is located on the page, it's probably going to jump around because this is only a partially filled out readme, but somewhere here you'll have this link to self-hosted videos. You don't have to do this, you don't have to install these, but if you wanna follow along with this particular chapter, you can download these, or you can just upload any other content that you want that's also a video, but for following exactly along, get these and then you'll be able to upload them in just a second as we'll see. Once you download them, you can unzip them and it's gonna look like this, self-hosted-videos, that's important. We'll upload them, I'll show you how to do that in just a moment.
|
|
|
transcript
|
3:25 |
Now we know what kind of user generated content we're gonna work with for our demo app and how to get a hold of it, it's time to set everything up over here in Bunny. So the first step is to create the storage zone and put the files there, and then we need to put some kind of CDN front end in front of it, just like we did with our URL zones. So let's go over to the storage here. You can see for the podcast, we have 880 files at around 30 gigabytes. And for the video storage, we have 15,000 video files at 121 gigs. Ooh, that's a lot of data. It's been working perfect though, so no problem there. Let's create a new one. Just like the CDN, we gotta give it a name, a unique name here. So Video Collector Demo Storage. This is not the public name, but this is what we see on the inside. So we're gonna do that. We're gonna use standard, we could replicate this to the edge at higher expense and be faster, but we're already gonna put the CDN in front of it, so we don't really need to do more than that. We can tell it where our home region is and when we log in and we upload and interact with it. What I think, my philosophy here is the very closest that you can do to you, to your team is probably best because you're gonna be uploading and downloading files through either some tool or maybe through the API in your app, depending on how it works. So whatever thing is interacting with the storage directly, probably just pick the closest location. This is not where they're gonna be served from for the users. So I am on the West Coast, so I'm gonna say Los Angeles, there we go. And you can also enable geolocation if you want. I could turn this off, but it'll replicate out here. So for example, if somebody in Singapore, for example, wants to watch the video instead of pulling from over here, it could pull from over here to populate it CDN potentially. Alright the price per month is 3.5. We turn off the geo-replication. It doesn't say. It said, you know, you really need to have that. That's a good idea. So we'll do this. Oh, I actually had created one of these before and I decided I didn't want it. I wanted to clean it up so it looked fresh. So let's do this again really quick. I'm going to call it store. Apparently it's like, you know what, that's the old one. So I didn't delete it. I thought I could delete and recreate it, but apparently not yet. Here we'll call it store. Perfect. Here's our content. And if you want, you can go and use this to upload the files that you manage right here. I like tools that are a little bit, I don't know, a little bit better, as we'll see. So I'm gonna set up, go to the FTP and API access to do that. You can also set up error handling, replication, and then connected pull zones, which we don't have yet. And if you decide you don't need it, you delete it, which when I did the other one, it just wasn't finished. So, in the next video, we'll see how to get our content uploaded here. Again, you could do it here, but like a little more polished tools and so on. So, we're gonna go do that with something else next.
|
|
|
transcript
|
4:02 |
How do we get our files up there? Well, we saw over here that it says FTP and API access, or we can work here. And again, if you want to do that, but what I'm gonna do is use something else. And I'm gonna go over here and it says, you can use any kind of FTP or other API tool to talk to this. And it gives you basically the login information here. All right, so they say you could use FileZilla. I'm going to choose something that's really awesome for the Mac called Transmit. The local company here in Portland called Panic. And this is a super nice app. It lets you work with things like this storage, but it also lets you work with Backblaze, with S3, a whole bunch of different places that are pretty excellent. So I'm going to fire this up. Again, if you're not on a Mac, maybe check out FileZilla as well. So down here, we've got it all fired up and I'm gonna add a new server. A whole bunch of choices here. And the one that we wanna pick that works here is FTP with explicit TLS SSL. We'll give it a name. I'll call this funny video user generated content. Let's call it that. Next, and we need to have information about where's the server? What is my username? And so on. That's all over here. Close that up. So the host name is la.storage.bunnycdn.com, port default is fine. My username is actually the storage I've made. Then everything else here is the default other than I got a copy of the password from here to there. I'm not going to show you that there's the password, although it doesn't really matter if you were to see it because I'm going to delete this, the storage zone just to clean up my bunny account after this. I don't need it hanging around. Now let's see how we do. Hit save, double click. What's going to happen? Oh yeah, there it is. So let's go to the desktop where I had those files. And here we have our self-hosted videos. Now one thing that's weird about this interaction is I think you remember which site this was. So I can create a new folder here and and say, I call it a test, but notice it says, oh, you can't rename it. You can create folders, but you can't rename them. (sighs) Probably happens in all the different clients here. So you can't really create a folder and put them in there. The way that I always manage that is I'll create a folder that I want to put up there and then just drag the whole folder and that'll name it. So let's do this. And while we're at it, we can delete this one. Let's see how we're doing here. This is going to take a while. You can see about four minutes at a time. I have a nice fast internet connection down. Unfortunately, the upload speed is as fast as you can get it, but it's not that fast around here. So I'm going to zoom through this section, and then when it's all uploaded, we'll go from there. Excellent. Everything is all situated over here. And let's go back to our file manager. We should be able to refresh this. There we go. There's our self-hosted videos all uploaded. Now the names might look a little weird, but those are the IDs in the database. So they should be really easy to connect back. Speaking of connecting back, we're going to find we have to connect a pull zone still before this actually will do anything. But at least we've got our tools connected to the object storage, and we've uploaded our files using them.
|
|
|
transcript
|
2:51 |
Now, in order to serve these files, we don't want to serve them out of object storage. We want to serve them over a CDN. So a new pull zone, here we come. This will be the second time. And what are we going to call it? Probably not exactly the name. So we'll just call this video collector user generated content or something like that. That's what I'm feeling coming on. And then we can pick the storage zone, not the URL like we did, a storage zone. And it says, well, which one? How about that one? This is the one we just created, uploaded the files to. We can pay a little bit less if we treat it as a high volume large file store 'cause it's not just that it's coming out of a storage zone but that there are hundreds of megabytes of files coming out of the storage zone. So we'll add that. Now we already know how to do this but let's copy this URL just so we don't have to remember it anymore. Again, you can put your own domain name here like we do for Talk Python, but for this demo, it doesn't make any sense to do so. Let's go over to caching. One month is probably fine. And have our URL query string if we wanna keep that. And it's optimized for video delivery automatically, which means it actually breaks the video up into smaller pieces so you can seek through it in a much, much better way. That's awesome. So thank you for that. Origin Shield. Sure, I guess. Maybe we want that. I actually am not totally sure whether we want it. It could be pulling from the replicated zones potentially, but I'll go ahead and say yes. And then, yeah, that looks like that's probably all that we're going to need to set. So let's go and do a quick test. We could try to get to this. If we go to one of these, let's say this one. I'm gonna click on this. - The top item in the main. - We'll be able to go and say, well, we need that URL there, but it's gonna be like this slash, what was it? Self-hosted videos/that.mp4. See if I got it right. Look at that, super fast. And that was the first time we hit it. All right, it's not auto-playing, but you'll see after I like poke around a bit, It'll have cached a bunch of this stuff. It should be really, really quick. Super nice. Now, all we gotta do is basically come up with this URL somewhere in our app instead of, instead of playing just the YouTube embed or sending the YouTube embed HTML, we'll just say we want a video element and the video is right there.
|
|
|
transcript
|
7:06 |
We saw that the videos are coming through the CDN, which is excellent, but let's update our code here, specifically our HTML, to make it play. So here's what we're doing currently. We just say go to this video player section and just embed, just do the standard YouTube embed. Now if we look over at the video model, it has a self-hosted flag. Now what I've done is I've already copied those IDs and said if it's one of the IDs that we just uploaded, we're going to consider those self-hosted. Otherwise, we don't have a copy or permission to own a copy. So what we're going to do is just play that from YouTube. So we can use that here. This is just Jinja syntax. We'll say if video.selfhosted, then we're going to do something else. We're going to do this. And at the end, we're going to say end if because, yay Jinja. Over in this self-hosted section, what we need to do is add a video HTML tag. Now it says source, we don't want to put source here. We could, but we can be a little bit more explicit by setting a list of sources because maybe we want to offer MP4, WebM, MOV, all the different formats. And then the player can pick based on the browser that's watching what the best matches. Over here, we also want to have a couple things that are similar to this. So we had auto playing and those aspects. So we can do that here as well without YouTube, we just say auto play and say controls because we want pause play type of things to show up for the user. And finally, we could add a poster. Let's add preload as well. Auto. So that might pull it down a little bit quicker and we have a poster. And the poster is going to be the image or the thumbnail that can show before the video loads or starts playing, which would be a nice touch. We already have that from our section over here, our shared video image. It looks like this. That's the thumbnail out of the other CDN, the static file CDN. So we can put that in here. Now for this section, we need to have a source. Not all caps. And the source consists of the type that we're offering up, again, like mp4, webm, or whatever, and then the source, the actual video file. So remember, the example that we had before was this one, where we tested out for that particular video, and that part right there that's highlighted, that's actually the ID of the database. So it's just video.id, which is super easy. All right, well, one other thing that's nice to put here just in case is a message if for some reason the person watching the video, their system doesn't support it. We can put a message like this, sorry, it seems your browser doesn't support any of our formats. And then finally, one other thing I just wanna throw in here real quick is just a div that has a style text align center and background color is black. Now, of course we should use CSS for that, But just for the moment, let me put it like this. Let's see how this works. I'm gonna restart our app. Go back to the ngrok version. Remember, ngrok's running, our app is running, all those things. Let's go test it out. First of all, let's test it on one that we don't control. This one we don't. The YouTube one is playing, great. Let's try again. But now, moment of truth. Let's see, do this one with Dr. Becky. Okay, this is looking pretty good. We have our poster and it's starting to play, although for some reason it's huge, but look at that, it's playing. Ooh, and here's our controls. Amazing. Well, let's do one more real quick thing here. We'll just throw in a style width, 100% like that. Hopefully that'll fit it to the screen. There we go, that's looking better. Doesn't look all sorts of wacky. So it's not playing, so this is the poster, but if I hit play, there you go, notice, there's no sound or action for a second, but excellent. That's our video playing out of the CDN. If we copy the video address, turn it down a little, over here you can see that's coming out of the CDN just like you'd expect. Excellent, let's go test another one. By the way, Dr. Becky's awesome, you should check her out. She's a great YouTube channel. A lot of cool science plus Python. All right, over here, let's see. What about this one with Brian and Cecil? Boom, just like that, amazing. That was the first experience with the CDN too. We hadn't touched that one in any way before. All right, so looking pretty good. What about, pick one more, but about this one. These are going great. Now let's see if I can seek around. All the way to the end here. Because it broke that up in those five megabyte chunks, it's just like, well, you're getting this little chunk here at the end. Beautiful. Excellent. Okay, well, it looks like our self-hosted content is working surprisingly well. Let's try one more time. Let's hit one that we've done before, so see how quickly it loads. Instantly. Like the poster just flickered for a second. And it's like, nope, video is playing. Beautiful. We can also go back to the control panel for bunny.net, go to our storage zone. Now here you can see, this tells you how much size, let's go to the pull zone rather. You can see we've had 0.15 gigabytes of traffic, 69 requests, that might sound like a lot, But remember, the videos are broken up to a bunch of small pieces. So it's not one request per video, and 81% cache hits already. That's really excellent. So there you have it. That's how we host this large content in a storage zone link CDN in front of it, and then serve it up. And to me, like, I'll play with this, see how it works for you. Remember, this is still over in grok. When I go here and I click on one of these YouTube ones, it spins, spins, and then starts going. But when I click on one that we put in here, like this one, instant. There's no spinny. There's just goey. So it's really, really good. Very quick. I feel like if you're beating YouTube, you're doing all right. So there you have it. That's how we set this up. And I'll, of course, put this in source control. You can take it and run with it. But it's pretty straightforward, isn't it?
|
|
|
|
29:22 |
|
|
transcript
|
1:46 |
At this point, you're probably pretty excited about all the possibilities that CDNs can offer with their caching of our files, static small files, as well as our large ones throughout the globe. And I've shown you a lot of the positives, but now it's time to address one of the drawbacks or potential negatives that this can lead to. Stale files. How bad of a problem this is depends on what files it is and how much they have changed. So for example, maybe we've made a change to some image and because the way the cache works, maybe a user's already seen that file, that image, and they come back and instead of seeing the new image, they see the old one. That might sound bad, but it's actually the least of the problems you're gonna run into. A way bigger problem would be, If we try to completely redesign the site and we change the CSS, and then we also change the HTML that requires that CSS to be changed, but the CSS file stays cached, our website just won't look new, it'll look completely broken. So this is really important to understand and fix. Now, what's awesome about this chapter is what I'm gonna show you here will basically automatically fix it, keep it up to date and always, always in sync. There'll never ever be a stale cached file that you're gonna run into if you follow these techniques. And this is applicable to standard web deployments, not just CDNs. So really easy to fix, but it's something you absolutely need to be aware of because it's something you're gonna run into sooner or later.
|
|
|
transcript
|
2:48 |
Let's see this problem I described in action, at least conceptually. So the caching problem is we want our websites to be as fast as possible. And the way we've achieved that is taking these hundreds of requests and telling the browser, you keep that, and if you've ever seen it before, you just don't even go back to the CDN, you just show it to the user. And we've told the CDN, hey, you don't come back to us for this information. You keep it for months. And that's awesome for speed. However, you can see down here in our network tools, that this is all just coming out of memory cache. So when something changes on the server, it doesn't even go back and ask, hey, should I get a new version of this or no? This is the fastest way to get the web app to run. However, it absolutely leads to that staleness, that cache staleness problem that I talked about. And you're probably familiar with this if you've done a lot of web development. This happens on regular web servers as well where you serve up static files and you tell the clients to cache them for the same reason. But it's a little bit worse on CDNs 'cause there's a multi-level problem. So let's suppose we've got this web user and we've got our web server and this yellow dot up there, those three yellow dots are three copies of the same file. This is, let's say, version one of our CSS file. Now, when somebody comes to visit our website, you can see they make a request and then they save that file in their local browser cache as we ask them to because that's the fastest. Now, we've got a grand new idea for updating our website. We make some changes and you can see right there, And now we have a green version, that's the new version of this file that we want them to share. Now, if this web user comes back and makes another request, what are they going to get? They're going to get the stale file, the yellow one, because that's the one in the CDN. Moreover, they're probably not even going to get that, right, as we saw. But if for some reason they're like, "Oh, I think it might be a cache problem," and do a complete refresh, they dump their cache or they do a hard reload and they completely go back to the what they consider to be the source of truth, the CDN where we sent them to, it's still going to give them the yellow file because we also told the CDN not to come back to us. So we've got this multi tier problem, how do we get the web user and their browser to realize oh, stop caching that use something else? as well as how do we make the CDN understand the same thing.S
|
|
|
transcript
|
3:14 |
So you may be thinking there's some complex or non-obvious infrastructure way to solve this problem. Maybe we tell the CDN some command so that it always knows to come back and look for a new thing. And then there actually is an API you could say remove all the stale files instantly. But we don't really need to do that. It's really, really simple but not necessarily obvious. So if we have a link like this, cdn.site.com/static/image/car.jpg, this thing is cached. And if we change it, how is the web browser and the CDN supposed to have any idea that it's changed? It won't, because we said for performance reasons, please don't even ask us just, if you see car.jpg, it's good for three months. Let's roll with that, okay? But what we can do is we can change this URL in a very small way. What we can do is we can somehow stick a version onto it. And the way we can do that is through the query string. Especially for static images, query strings are meaningless. They don't tell you anything about the particular file you're getting. There's like, here's the file, and I guess there's some query string information in the URL, but I don't know what to do with that. Here's your static file. Thank you very much. So what we can do is we can change this link a little bit and put something on the end. end. I'm calling it a cache ID, it doesn't matter. What matters is that this query string key and value change any time that the file changes. Now we could do versioning of this and if this was coming out of a database it'd be super easy to say every time you update it increment the version. Here's version 2, here's version 3, so it could be question and mark V equals two, V equals three. That would be great if there was a centralized management place of it like that. But if it's just a file on disk, well then you got to keep renaming it and updating it, no. So what we're going to do is we're going to base that version or what I'm calling a cache ID as a fragment, kind of like a SHA in a Git check-in on the actual file contents. So you don't have to think about, Well, is it a new version? Is it the same version? Does it matter if it updates? You don't worry about it. If the file content changes, then that link on the right hand side, this green part changes, which tells the browsers, which tells the CDN, this is not the same file. Because while it doesn't actually matter to static files, they don't know that. This could be some server-side generated thing that's actually looking at this to generate the file. So it's gonna go back and make another request. And that just means if the file content changes, the URL changes. And so yes, you'll have two cached versions of the old car.jpg and the new car.jpg, but the web browser and the HTML will only be using the new one instantly, automatically. So that's how we're gonna fix things in this chapter. It turns out to be pretty simple. I've got some code to accomplish this for you, in both an easy and automatic as well as high performance way. And we're gonna put that to place.
|
|
|
transcript
|
5:46 |
Back in PyCharm and time to write some more code. A new chapter, so remember, we're moving from the old to the new. That means we're unmarking that as a sources root and we're marking this one as it and we're running this particular file here. So just make sure you're running the right one. You can see I've already set up a chapter five run configuration for this. Now there's been a file hiding in our code the whole time because I put it in the starter project. I want to make sure that if you copy that and ran with it, you would just have it to work with at this point. So over in the infrastructure section, we have this thing called CacheBuster. And let's have a look at this file. And it has one important method, build CacheID. So recall we saw question mark, cacheID equals some value, here it is. So what's going to happen in here is we're going to give a file name. This is a static file like /static/image/car.jpg. And we're gonna, when we set things up, tell it what is the base folder for our installed web app. So we said our app is in /applications or webapps/whatever, and then it can resolve basically the full file path to that static file in order to work with it. It has two other options, whether it's in dev mode or not, as well as whether it will hash, it'll log these hash operations. And basically, right now it prints them. Here you can see if you want to see output from it, you can say, yes, please show me that. More likely you would plug this into your logging framework, like Logbook or LogGuru or something like that. But I don't know which one you're using, so you're going to have to adapt that if you want that behavior. The dev mode means basically every single change you make will live reload the cache. That's a little bit less efficient because every request has to cache all the requested files over and over again, which is not great. So you definitely want that off in production, but it can make things easier in development if you're not doing performance testing. Okay, so how does that work? We take this file name and we turn it into a full path name based on where the web app is installed, and then what is the relative full path within your web app, forward slash something, something, something. If it doesn't exist for some reason, we're not gonna crash, we're gonna return the cache ID of error missing file. That way when you do a view source, instead of seeing this cache ID or nothing and wondering why it's not working, it'll put this question mark, error missing file text in there. It also say, look, you gave me a directory, I can't hash a directory, I'm supposed to work with files and so on. Then it keeps a dictionary. Now this is a very, very simple version in memory. You might think, "Oh, well we need register, database or something like that." No. It keeps this up in memory and it says we're going to go here and compute the file hash. This is just the MD5. Now you might have heard, "Don't use MD5, please, because it's not cryptographically safe We're not doing passwords, we're not doing cryptography. What we're doing is we're just trying to get something that will change every time the file contents change and we want it to be fast. This is perfect here. So we're going to use MD5 and we're just going to pull that back in here and it just basically gets a short version. Actually, it's a whole thing but it is pretty short. So it'll say open up the contents of the file. binary thing, turn it into this hex information and store it in this dictionary and then return that value. Up at the top, I remember I skipped a section right here on line 11 or line 12. It says if it's not in development mode, and we've already seen this file before, that is we've already computed the hash, just return this. So this part makes it super, super fast. Now the reason we don't need Redis and a bunch of scaling and infrastructure is when we deploy our web app, we'll fan it out into multiple worker processes and sure the first request for a particular file to a certain server or certain worker process will have to recompute it but then once it's up and running, it's never going to hit it again. And this is a really fast operation anyway. And so instead of adding a bunch of overhead, just keep a bunch of file names and hash results in memory and if they got to be re-computed, no problem. And in production, the way to get this to trigger is you're going to have to redeploy the website or restart, just restart really the website. But typically that's how you put static, new static files and things up there anyway, so they're kind of tied together, hopefully. Anyway, that's how it works for us. I could have just said call this function, magic happens, but I really want you to understand that there's very little magic going on. For performance reasons, we're keeping a hash or a dictionary of given a file name, if I've seen it before, I know what the answer is. And otherwise, we're just gonna read the bytes of the file and return a binary hash of that, right? That's how we get that cache ID. And because the way MD5 and other hashes work, if the contents change, that number changes significantly, and that's gonna change our URL, which will erase this hashed staleness problem.
|
|
|
transcript
|
8:22 |
So we've got this cache buster build cache ID method here. How do we put it to use? Well, we need some way to communicate or pass this over to our HTML. And we have these view models whose job it is to pass all the data and functionality over into the HTML side. And guess what? We'll just leverage that. So down here in the view model base, we have this function called build cache ID, and it just takes a static file reference, a full path file within the web app. And then it's just gonna delegate to this cache buster build cache ID, passing the file, but then saying, "No, we're not in development mode," and then stashing the root folder, which is, as in this case, go to where this file is, go to its parent, its parent, its parent, which is right where the slash static would lead to up here. So a little bit non-obvious why there's three parents, but that's what we do for getting back to the top level of this web app here. Sure, we could make that a configuration setting, but if you can compute it and don't have to have configuration, even the better. And then this last one is about logging these operations. You probably want to turn that off once you get going, but we're going to leave it on for this chapter so that we can see what's happening. And then we just pass it back as build CacheId, a method that can be called by our HTML. So let's run our app. Remember, we could click this, and this will actually still work because everything else we're getting is still going to the CDN. But just to stay consistent here, let's go over to our ngrok and click this. There we go. Now we're running the ngrok version. Remember, it still has to be running down here in PyCharm, or however you're running it. But let's say we want to make these files here change. So for example, if I go image and look at this, it has this. The one and only URL is apple/webp. So this could be a problem. Let's go and make a change so we actually see that problem. So here I'm refreshing. I can do a hard refresh, a little bit of a flicker, but it's still basically instant. So come down here, and if you go into the images, the categories, let's open that in Finder. Notice there's this apple one here, but there's also this apple one. Let's suppose that we wanna use this now as the category. So I'm gonna make a quick change. We'll call that V1, and that'll be V1. And this now is just going to be Apple. There. Really, that's the one that we need to change. So if we come along here and we refresh it, notice this file did not change. Well, maybe the problem is I need a hard refresh. So I'll do a Command-Shift-R or Control-Shift-R on the other OSes. No. Maybe I can go over here and say, show my dev tools. Go to network, disable caching, and try to still see what's on the screen. And refresh. Nope, because remember, the CDN also has this copy of the file, and it says they'd said three months. We're barely into, we're a day or two into this. We got plenty of time left. So let's undisable caching, right? This is a trick that our regular users certainly won't be employing. They don't know it's changed. So how do we fix this? Well, let's go over here and find where that is. That is gonna be in templates. And again, new project or new sub project. We've got to mark the templates folder there. This is gonna be on home on index. And this is where we've got our full CDN version here. So what we want to do is we want to go to the end of this. You get as much room as we can, I suppose. I'll say question mark. Oops, I didn't mean to overwrite that. Say question mark, cache ID. You can put whatever you want here. You can put version, whatever. It doesn't matter. There just needs to be some query string thing that changes. And it's going to be the result of calling a function build cache ID. And in there, we got to pass a string. And what is the string? It is this. It's kind of kind of yucky looking like that, plus the image. There we go. Alright, so I'm not a big fan of how that looks. But it's not too So what we got to do is we just say the cache ID is go into Python mode, so double angle bracket. We want the string. I'll highlight the whole bit. Double angle brackets to take this result and turn it into a string in HTML or print it to the HTML. And then the file is going to be whatever it was here. But not the whole remote one, but just the static one. So /dynamic image category is this. Whew, all right. Now let's restart it. Remember, I told it to cache in the app, to cache its memory or use its memory of what it saw before for speed. So we do have to restart the app, but also because the HTML has changed. So no big deal, all right. Now remember, no matter what I tried from the browser's perspective, I couldn't get this file to change. Let's try again. Let's just navigate around. So if I click this, it'll reload the homepage. Soft reload. Hit it. There it is again. Now notice, every one of those was a little bit slow. Why? Because if we view source, and we scroll down, look at these big long cache IDs. Every one of these changed as far as the CDN is concerned. So the CDN had to come to us to grab that file so then it could show it. But now it's seen it before, so let's click away and then back. Notice every click it's super, super fast now. And it changed. You might be thinking, oh, well, you kind of reloaded the whole thing. Let's make that change one more time. Let's go back here, change that to V2, that to V2, and put these back as the way they were. So this will simulate just the file changing once again, the static file. Again, for this change to be picked up, the way I'm running it, you don't have to run it the same way, I have to restart that. And that's like kind of the production speedy style. If I click this, notice just the Apple one is redownloading. And it redownloaded cuz even though it had it before, it now thinks it's different. But again, navigating around. Super fast, okay, come back in here. Super fast, Apple, same images right there. Excellent, so that's how we avoid this cache staleness, even though the CDN is super aggressively caching, as well as our web app is aggressively caching, right? So we've got these multiple layers. The user's browser saves everything. It doesn't go to the CDN, and the CDN doesn't come back to us. But anytime the file changes, that part right there changes. And as far as the CDN and the clients are concerned, that's an absolutely unrelated new piece of static content it's got to get. So super, super cool way to do it. Very easy. The actual HTML you got to write is a little bit clunky, but just copy and paste it and you're good to go.
|
|
|
transcript
|
1:17 |
Do you remember when we set up the URL pull zone for our static files and I said, "Let's go through the caching section and it's really important that you check URL query string as one of the vary by options." I believe that was off by default on this one. I said, "In order for stuff to work that we're going to do later in the course, you have to click URL query string as one of the ways in which things could be considered as a separate file." and then we're gonna save that configure it you know make sure you press save that configuration right this trick we did with the cache ID if you don't have this checked well it's kind of say query string change but we're not supposed to treat those things as separate so same file and same still cache problem so we talked about this before but it might not have clicked on like well why does that matter this thing we just did to allow for us to make changes to CSS, JavaScript, image, and other static files, and instantly, without any effort on our part, have those changes all the way through the infrastructure stack, it's that little green checkbox right there. So make sure you've got that set if you're going to use this technique.
|
|
|
transcript
|
6:09 |
Now, we've made the change for this one particular static file, right? This is for a category banner image up here. These. But what about our YouTube thumbnails? And maybe even more important, what about all of our static files? So just to put a bow on this, I'm going to go through and add some of these cache IDs to everything that might change that we're sending through the CDN. I'm going to copy this because once you figure out that incantation of turn into a string in HTML and then encode it, now you're back into calling a function with single quotes versus double quotes. Yeah, it's kind of nuts. So let's go through and see where else we might change it. Well, we've got-- let's stick in the HTML for a moment. We've got our partial for our image here. And it's going to be about the same. So I'm going to paste that and then come back and say, OK, the URL is that here for this section. And then it's a video ID. Plus.jpg. Go let's just run this again and make sure everything. Still works so if we refresh this it should have to download those again but only once populate the CDN. There they go. And if we say view source. Perfect. We're not seeing that error missing file error missing file. Now everything's working. Excellent. And let's just double check. We'll hit the Python one. There's one other area where we need to work on this. If I click this, it's going to have the poster. So we need to go to the play section. But this is exactly what we're going to need. So I'm going to copy that. And videos play. Remember we said here's the thumbnail we want. So that goes right there like that. If I go and hit play here, you won't see it for long, but it was for a second. You could see there was the poster. So if we view source, I should go down and see poster has the cache ID. Excellent. So I think that covers it for the videos. And it should even work in things like infinite scroll over here. And it does because you can see they're a little bit slow The first time, if I go over here and search for WWDC, there's the two. We look at that again, open image in new tab, at the top there's the cache ID. Excellent. But let's also do the other static pieces of content. And those are in, let's close that all up for a minute. Those are going to be in our shared layout over here. So we can see I've said, "Hey, let's take this bit." Just to remind me what to type in. Where are we looking at? Just beware the caching staleness. I'm going to go to the end of this and put this long section there, which is going to be this. Now I'm going to put one of these here. Let's just see this bootstrap one is working. Refresh, a little bit slower just for a moment. Now it's got it. View source. Sure enough, it's working. I'm gonna go through and do that. All these other ones, you don't need to see that. So I'll just zoom ahead. Well, that took a moment, but here you go. We've got our font awesome, our site, our animations, all of these things, they have their static cache ID. And again, at the bottom, we did the same thing for our JavaScript. Just run it real quick, make sure everything works. Takes a moment, you can see it's pulling in the files. Now the CDN is populated and we can just check one more time. Up here, all these look good. All those look good, excellent. And now we can go and play with the website and it does all of its things super, super fast like it should be. But the magic now is if we change the site design in any way. So just to make that really obvious here, let's stop for a second, close that, go to the static site and is there anything with the body, Yep. Let's just set the background color here from this, I'll set it to be yellow. So we didn't do anything but just redeploy the website. And then now as a user is clicking around, they'll just click here and instantly new deploy, new static files. We've got a new design. It's amazing. Do you love the new footer? So super easy. We don't have to think about this ever again. We've set it up. We've set it up in our shared layout page over here. And basically it's on autopilot for the rest of the time. We just go do our CSS work, our JavaScript work, our HTML and images, and it just, as we deploy new versions, just picks them up automatically because the cache ID changed. You can see the cdn came back here and grabbed this. And it's building this new hash for those. But if I refresh it a few times here, you see it's no longer doing that because it's in its in-memory dictionary cache as well. So everything's working perfectly. Hopefully you find this technique really cool. It's a little bit to get started with, but once you get it set up, it just goes. It's excellent.
|
|
|
|
14:16 |
|
|
transcript
|
0:56 |
Help, you've gone and launched your site and it looks like this. Oh my goodness, what is wrong with it here? Well, multiple things, clearly the Apple category and the EV category are all sorts of broken. For some reason, the styles are gone, the navigation bar is gone, the colors are all messed up. So probably some CSS didn't show up, it looks like some images didn't show up. Yikes, what do we do? Well, that's the topic of this chapter. You'll of course use the traditional web debugging features, you know, looking for 404s and other types of errors, but with the CDN in the mix, you know, maybe those requests are never making it to you and you need to do a little bit more work So that's what we're gonna talk about in this chapter are what are the tools you have to figure out these errors, even when using a CDN.
|
|
|
transcript
|
1:04 |
Well, first off, let's pull up the Network tab. That's usually a really good place when you feel like files are not rendering correctly or they're not showing up. You can go to your DevTools in your browser. Chromium or Firefox-based ones are usually the best here. You can see there is trouble. We've got 11 errors in our little console warning section. We also go to the network and you can see all these red 404s for the style sheets, the bootstrap, and then this all.min is font awesome and our site CSS. Well, clearly, that's why a bunch of these things are busted and missing. Now, it's not always exactly a 404. Sometimes you would want to check out the console as well. It might have other information about, well, you tried to include the JavaScript, but the the JavaScript had an error in it, So it couldn't actually run, which means it couldn't transform the page or whatever. So check the console, but I would say network here is probably the place to start.
|
|
|
transcript
|
2:51 |
Another thing you can try to see if it's a CDN problem at all or it's just something wrong with the structure of your site, usually the static content, but it could be that some route URL is getting in the place and trying to process that instead of letting it flow through to the static files, is to just try without the CDN. So up here, you can see we've got cdn.site.com/static/image/car. Remember, we added that because we said, "Well, we used to just have /static/image/car, and while that worked fine locally, that was serving everything out of one location out of our data center for our web app and putting extra load on our web apps server as well." So we added this, but you can unravel it if you're having trouble. You can say, "Well, just for now, let me go back and turn off the CDN by effectively just deleting it out of the HTML, and then see how the site behaves. Does it still have the problem or no? So this will tell you does the problem belong with the CDN or with your site directly. Another variation here, which is what I actually use on Talk Python Training and the other websites is to pass this https://cdn.site.com this CDN variable here. I pass that actually as a variable into the HTML from Python into Jinja. And then at app startup, I can have a flag that says, what is the CDN prefix? So if I wanted to actually use bunny.net, which I almost always do, I just leave that there. But for example, if I'm doing lots of CSS work, and I want to, every time I hit go on the page, I don't want to have to redeploy the website. Remember, it's on a real server on a real domain, which is where the CDN is looking not locally, like we are for this. So I'd have to push to deploy to see those changes. So in dev mode, by default, I get the pink top version. And then when I push to production and run the production configuration, it then uses a different variable setting instead of just nothing that uses the CDN setting. And that way I can actually cycle between it. If you put that in place, you could just have a flag, flip it on and off in development here. So you can try without using the CDN. That doesn't necessarily mean going through your entire site and deleting a bunch of stuff, right? This could be a variable that you pass over throughout your entire app, and you just change it once, and then it adapts. But if you're not sure if the problem is with the CDN, try it without. If it's still there, then you can just rule that out and go back to standard web stuff and figure out like, well, why is this not showing up in my web app? Forget the CDN and then flip it back.
|
|
|
transcript
|
4:21 |
Let me show you what I mean about being able to turn the CDN on and off at development time. This is useful for troubleshooting, but it's also just useful in general for development, as we'll see. So, notice again, a new chapter here, I'm calling this troubleshooting, and I've got a bunch of blue files, I just changed those, we're going to talk about them in a second. And I got a new configuration to run this file. Make sure you got the blue sources root here and here only. Okay, so what we want to do is somehow pass a variable along to our app. Now that has that CDN information. So where does that variable come from? Well, one thing that's always providing data to every HTML file in this website is the view model. So the view model base, just like it's built cache ID can have this thing called the CDN prefix. And up here at the top, we have a global variable use CDN, true or false. And then when you create the view model, it says, well, if we're not using the CDN, we're going to put nothing. So just forward slash static the way it was before. And if we are using the CDN, then we're going to pass in our CDN here. And what that means is in different locations like let's go here instead of having that hard coded that CDN prefix. We'll have we're going to have the CDN prefix right there like that and here and here and here. So normally if we just run it the way it is now and we pull this up we say source you can see here's Here's our static CDN link. But if we go over here and we say, "You know what? In our app startup..." I'll have maybe another section here. I'll call this "Register CDN." And of course, this is going to be really simple. You would read this from an environment variable or a configuration variable or something, but for now we're just going to directly work with it here. So say viewModelBase.use_cdn = false. Okay. Let's run this. See how it looks again. Still works. That's actually a pretty big accomplishment. But if I view source again, notice /static, /static, /static everywhere. Here's the / static and let's put these side by side. Even down here where we're working with the images for the category, we still have our cache ID. We still want that. That's still relevant. So we're not having this prefix for the CDN when we turn that off. So what that means is we can now come over here and just start playing with this all we want and as we make changes or as we go to the dev tools and look at say the network story when we click on this, you can see all this stuff. If I scroll it so it fits on the screen, like this, it's coming out of localhost now. Okay. So this code is here. Really all you just got to do is everywhere where there was the hard-coded text of the CDN, we put this variable. And then at runtime, there we go, I'll put something like this to kind of give you a sense of whether or not it's in production. If it's in production, we're going to use the CDN. If it's not, maybe, maybe not, depending on what you're doing. So, but this is here for you to play with. I'm going to leave it just hard-coded to use the CDN for now. And so if we go back and we rerun this and then refresh this, now we look at this, you can see out of the CDN, once again, beautiful. Okay, so that is super handy. It's not, like I said, it's not just handy for solving problems. Very nice when you actually go to production and your CDN origin is pointing at your production server, you don't want to have to keep redeploying just to test minor CSS changes. So this is really relevant, this whole idea here to cycle it on and off, but again, it's a nice way for testing if you run into problems too.
|
|
|
transcript
|
2:07 |
Now, if you really do think it is a CDN problem or you just want to see historically what has happened with the static files or anything accessible through your CDN, over on the panel, the bunny.net panel, there's an actually a log section. So you can see in the left here, there's this logs thing in the vertical nav bar sidebar there. And you can come in and see all the requests going to a particular pull zone. So up here where it says video collector, you can pull that down and it'll let you look at any of your pull zones, whether that's storage or a URL pull zone. And then you can see all the requests Here I've got the 200, so successful requests, as well as 404 and I guess 400, other types of four category requests, 400s. So you can see there are some 404s coming in. I had intentionally misnumbered or misversioned my bootstrap version and it came in as a 404. It should be 460 and I typed in 461 and it came back as an error. So then I changed the 1 back to a 0 and it went, "Oh yeah, that's a 200. That's okay. We got that." You can also, where it says status filter up here, you can click those on and off. So we only have the 200s and the 400s, I believe, possibly the others are checked. but there's nothing. I think that just might mean they're not colored because none are showing up. But you can click on those and turn them on and off and filter it down to just show me the 404s, just show me the 500 server errors. Because it could be your servers crashing when it's trying to provide a file, right? There's lots of reasons that the content's not making it there. So if you want to see what the CDN thinks is going on with your website and what requests requests are coming to it, and then what happens to them, go over to this log section and you can search through them, toggle between pull zones, turn on and off successful requests, and only show errors, only show successes, and so on. So remember, the CDN keeps logs too.
|
|
|
transcript
|
2:57 |
We talked a lot about avoiding cache staleness, and that works really, really well. But maybe there's some times where you can't actually control what query string gets put onto a particular file somehow. Maybe it's out of like a storage zone and you don't have control over it or it's getting linked to other ways, and that is stale. So you've got a couple of options to solve those types of problems and you can just purge the cache and you can do this aggressively or you can do this gently. So for example, if you go to your pull zone in this example, we have the video collector, the static URL origin pull zone that we've been working with. And if we want, we can just click here and it'll say purge the cache. We'll get a warning at least. So that's really nice. Hold on, hold on, you're going to do an absolute dump of all the 114 POPs, points of presence throughout the world that may have replicated anything from you. We're just gonna do a global delete, globally, I guess. You can say yes or no, do that or don't do that. All right, so here's a really aggressive like, just remove everything, start over. Of course, the requests will then have to come back to your server that might put some load on it or a lot depending on how much but honestly it's probably not a lot because you might have origin shield turned on so like you hit one request and then off it goes. I don't know your situation but chances are this is something you could do it wouldn't be terrible. It's not anything I've ever done. I've never needed to do this but it it will wipe things out. You can be a little bit more specific or a little more cautious and this I have done before. And you go on this left nav bar and go to purge right there. And it says enter a particular URL to a file or you can put some kind of wildcard value like /CSS /star and say I just want to clear out all the CSS files or all the images under some subcategory. You would type those in here, including the URL, the actual CDN URL that you're using /the static file path, as you can see in the example here. Then you hit this and whoosh, some small subset is gone. I've done this where there was a video course we updated. A bunch of the files needed to be changed, but we didn't go and change all the file names in the database or particularly pass that information along. We just said, "The URL that maps all the videos in this particular course, hit it. Wipe those away," and that worked perfectly. Here's a more gentle way to purge the cache.
|
|
|
|
12:44 |
|
|
transcript
|
1:47 |
Fonts are tricky on the web. There's a whole bunch of cool fonts out there. And what you would like to say is, "Hey, can we use the Agave Nerd font mono for our code here?" Well, maybe, but by default, you gotta say, if I go to my CSS style sheet and say, "I wanna use the Agave Nerd font mono," and that's all, then whoever comes to that site is gonna have to have that installed on their system. So good luck, it's installed over here on my Mac. Oh, but on my Windows machine, it doesn't look like it. So this difference, this is a huge challenge. And like, let's not even get started on mobile platforms with a thousand different Android's and different versions of iOS and things like that. So it's a big problem. So what do people do? Well, they say, "What if we could use some kind of hosted font?" You saw earlier when I was diagnosing the problems in the troubleshooting section, we were having issues with the Font Awesome font, which was being served directly out of our website. Something that's really common to do is say, let's go use something like Google Fonts. So fonts.google.com, you can go over here and you can see there's 1,490 families of fonts. And then within each family, there's variations like a bold and italics, a thin, a light, all the variations you might expect there. So tons of options and all you do is you check off the ones you want and then you put some kind of link in your website. Problem solved. Because that way when people show up, it doesn't depend on them having the fonts. It says as part of this website, please go to fonts.googleapis.com, request this font family and then load it up and you'll be good to go.
|
|
|
transcript
|
2:08 |
So what's the problem with just using things like Google Fonts? Well, fundamentally, the problem is that at the very heart of it, Google is just an advertising company. They buy and sell our information and they treat you as the product. And so many of their services have been marketed as do no evil, let's get out there and just make the web a better place. And not detracting the good work, that they have done for certain things, Many of these come with very subtle but negative trade-offs. For example, did you know if you try to embed a YouTube document or a YouTube video onto your page, that puts a whole host of tracking on top of your users? Even if you just link to the YouTube image from a YouTube video, that puts cookies onto your users. And Google Fonts is the same way. So while it might seem like Google is putting these fonts out to help us to make things better so that everyone on the web, it's going to be free and it's going to be amazing, we're going to help you. Oh, and by the way, wouldn't this be a great way to just track everyone? So, yes, that's ultimately the problem is these services are being provided to us by companies that are making this trade-off between web developers and Google. But that's not who's getting tracked, not really. The people getting tracked are the visitors to the website who don't know anything about it. They're like, oh, that's a cool-looking website I love its font. Oh, yeah. Did you know you now are being tracked? So check out this article website find by German court for leaking visitors IP addresses via Google fonts So short version even using something like Google fonts is a GDPR violation unless you explicitly Let people know and make them opt-in and what are you gonna do if they say no? have the wrong fonts potentially, but that's gonna be a design nightmare. So Google Fonts, not a great answer. Turns out we have a really good one for you. This is not a negative chapter, I just wanna set the stage for the challenge here.
|
|
|
transcript
|
1:51 |
But you know what's great about Bunny.net? You pay them money, not a ton of money, but you pay them for a product. You are not the product and neither are your web visitors. Bunny.net, I don't know if I spoke about this at the beginning, but Bunny.net is based in Europe and they're a very privacy-oriented company. You can think of them a little bit similar to like ProtonMail and those types of companies that are European-based, more about providing privacy to their users and so on. And when they realized the same problem that we just discussed, they said, "Hey, you know we have this cool CDN, maybe we could solve this problem." So they came up with this idea of having their own parallel version of Google Fonts that is compatible from an API or from a way in which you use it with Google Fonts so it's super easy to switch between. So here you can see, on their fonts page and about. It says, "Bunny Fonts is an open source, "privacy-first web font platform designed "to put privacy back on the internet "with zero tracking and no logging policy. "Bunny.Fonts helps you stay fully GDPR compliant, "and it's fast because it's over the same network "all your other stuff is going over." And the UI looks incredibly simple, similar. You'll come down here and you're like, "All right, well, let me go find the font type "I'm looking for," and you can search for it, and then add the different variations and come up with a thing to include here in page to solve exactly the same problem. But instead of going through Google, which adds on these ad tracking, retargeting pieces of information, it just provides the fonts, nothing else. Okay, so super cool that they created this and we're gonna add it to our website here.
|
|
|
transcript
|
1:26 |
So if you're not super familiar with Google Fonts, and I said, "Bunny.net fonts are API compliant or compatible or interchangeable with Google Fonts," you might be like, "I don't know what that means. I didn't know fonts have APIs." They don't, but the way in which you get them on your page does. So here's an example of how we might use Google Fonts. So what you do is you go to the Google Fonts page and you select all the stuff you want. In this case, we wanted a breezy and Albert-sans, and we wanted the thickness or strength 400 and 400 italics for the first one, and 100 and 600, so a thin and a bold for the Albert-sans. And if we put that kind of information, these family and the sizes and strength, and put pipes separating them, this is how we tell Google Fonts in one request to give us these four different font families that then we can use throughout our site. So if we want to use bunny.net fonts, here is the magic that you have to do. You replace fonts.googleapis.com with fonts.bunny.net. Done. That's it. And then it will work exactly the same. So upgrading or migrating to bunny.net fonts is super duper easy. And we're going to go write some code next to do this in our example, but as you can see, really, really easy.
|
|
|
transcript
|
5:32 |
Here we are in our website, still running. We still have ngrok running in the background and we have it running the Python Flask app running in PyCharm. Same as always. I've actually changed, moved to a new set of code here just so you have an exact copy of what we're working with for this chapter as I have been for all of them. Again, unmark all the other source routes and set this one and set this to run here. You can see it's already running. chapter seven fonts is up and going. So I haven't made any changes there yet, but we'll have that new code to work with. Now, you can see there's some nice fonts here, this cool little super thin font there, and come around and search and sure enough, this is working a nice and fast. Right, just like we would expect. So we do a view source. Yeah, There we go. We have our Google Fonts in here. Now how do we fix it? Well, we could just do a find and replace and that would be well and good. But let's just go to fonts.bunny.net real quick and just have a look. So I want to show you how to use the site just in case you're not super familiar with it. It's not honestly entirely clear how to use it. But if you've already got one of these, we can fix it by doing that find and replace. But let's suppose we want to come down here, you can see 1492 families, just like Google fonts. Back that off a little. So let's say that this one is a really cool font that we might want to use, maybe that one. All right. So you can come down here and it'll show you examples. Apparently, this one only has the normal 400, like strong or thin or italics or anything, just this, just this was the only version. So what we can do is we can click add variant. Now over here, if we open this up, it shows us how to use it in CSS, or this is the actual CSS statement, or you can see the actual HTML thing to link to it like we saw in our example. We can also go and say, okay, not just that one, but let's go back here and say we also would like, that we also want this particular one. So it's got its one variant, And then we'll do one more, I suppose. Let's get a thin one like this advent row. And we can get a super thin and then a normal variation. And we go back to our fonts here, you can see right there, it's exactly what I described with the Google API, where it's got the different families and strengths all put together. So we can come over and just put that into our code. So that's how you use this site. Let's go and change it here. Remember all this stuff for the overall look and feel is in this layout thing. We got our to do fonts that is out. And what I'm going to put is fonts.bunny.net. Run it again. Over here, refresh this, you can see here's our fonts. Let's click on it, make sure it works. Sure enough, it does. And what it does is it pulls a CSS file that then links to all these secondary files there, which is pretty cool. And we refresh it. It looks exactly the same. Should it look any different? No, because what we have going on here is exactly the same font family, just the way we're getting it to our users is a little bit better, I would say. So we go to DevTools, we can look right there, see our fonts coming back 200 AOK. I suppose if I hit it a second time, you should see those straight out of memory cache like all the other CDN things. So pretty excellent. Here's the thing. If you've got a website that is using Google Fonts, go read that article, do a little research, Do some soul searching, see how you feel about fonts.googleapis.com and consider using bunny.net. For me, it's a no brainer at all because we're already using bunny.net for stuff that's more important for our site like CSS, JavaScript, and images than just the fonts. One more way to plug into that system doesn't bother me at all. If that were the only thing you're using, maybe you got it aside. To me, it seems like a really great service, and I definitely use it on our websites, for example. Right there, huh? Indeed, so great service, and by the way, I guess you're already using it as well because you came to this website to watch this video, right, unless you're using the mobile app. You could also throw in a pre-connect here, just like we did for the other CDN pieces, but I didn't put that over here on this page because literally the very first thing that the browser hits is go get this style sheet from that location. And so same pre-connect and then get the thing immediately seemed a little bit, I don't know, like unnecessary, but you could certainly add a pre-connect there, a little Explorer example up here as that pre-connect string for you if you want it.
|
|
|
|
16:21 |
|
|
transcript
|
1:04 |
You've seen examples of slow websites. You've seen how we can use a CDN and other techniques to make our website super, super fast. But how do you know? We all have an intuition, and as you interact with it, you can probably say, yeah, that feels better, but let's find some tools and use some tools to actually measure and put numbers to the changes that we're making. That way we can say, yes, It's not just feels a little bit better, but it's 32% better for most people around the world. That'd be a nice thing to say, right? So remember the PageSpeed insights, we talked about this at the very beginning about how CDN looked really fast, but then actually turned out to be slow in its overall experience. So we're gonna play with that in this chapter. And we're also going to play with the network tools directly. We've seen a lot of the stuff going on here, but we're going to specifically use them to compare the old and the new version of our website.
|
|
|
transcript
|
9:02 |
Now, we've got a lot going on here in order to run the old version and the new version side by side in a way that we can use. So notice I have two terminal open here, one to the starter project code and one to this chapter 8 performance testing, which is literally just a copy of chapter 7. I don't think we're going to make any changes to that code, but I want to have it there as a standalone thing for you. Also note we have the same Python virtual environment activated already for both so that we can run our app. I'm going to say Python app.py here. Notice this is running on 10001 as it has been. I made a very minor change to the starter project, which you'll need to make if you want to do this trick as well, because they can't share the same port. going to need to use a different one, so I made that 10,002, just so we can run them both at the same time without it complaining that, "You know what? This is, you know, I can't open a port here because something else is listening." So that's the two versions of the Python app running. We also need to have ngrok to get to it. So I'm going to open up a new tab here and I'm going to put it at the bottom so we can see it side by side. I'll say ngrok Like this, this is the one we've seen traditionally, what we've been using most of the time, this Kennedy CDN. And then same thing here, and I'll drag this to the bottom, like so, and I'll say Ngrok, and we'll just listen on 2002. So this FA whatever, this is the original version, and this Kennedy Talk, this is the thing that we've gotten to now. So let's open up that, And over here, open up that, you can see the request coming in. Like if I refresh this, you'll see that one running. And if we're over here, and I refresh this, not that one, this one, you can see it moving a little bit, but there's a lot of traffic on the original over here. See every request, do a hard refresh, you'll see a bunch of things coming in there. over here, even if I do a hard refresh, it's just a forward slash, oh, and the favicon, which we don't have a favicon, so too bad. Probably should add one just so we don't see those silly 404s. But anyway, these two things are running side by side coming through the two different ngroks. Whew, that's a lot of setup, isn't it? Okay, hopefully that makes sense. And remember this one with my name in the subdomain here, that one is the new fancy one. This is the original one without any form of the CDN stuff. It's just got slash static. It's got the Google fonts. All that's coming straight out of the website. Whereas this one, the CDN is going all those things. So let's go and see if we can find out information about it being slow or fast. Before we get to it, let's look at one that I'm pretty certain will be slow. Come over here to CNN. Make that a little smaller. So over here, let's go to the DevTools. Now we talked about PageSpeed Insights, which is this website. We can go and analyze it here and pull up the details for it. But that's also gone under the name Lighthouse. So if you're running a Chromium-based browser, you can go to this Lighthouse tab and you can say I want to analyze for mobile or desktop. For now we're going to do desktop. You can also analyze it for progressive web app correctness. There is no progressive web app that we built. So turn that off. It'll just be like a zero out of 100. All right. So we hit this on CNN for now, it's gonna go, look at that, 45 errors 'cause of all the trackers that we're blocking, terrible. Run this, it'll go talk to CNN on different types of browsers, different capabilities, different networks with, without caching, all the things that it does. And honestly, that's a little bit better than I expected out of CNN, but it's still really, really bad, right? Like even best practices in accessibility are bad, not just performance. So, you know, it is what it is. So here's a big professional website that is a very important front end to a big company. Put a lot of time into it. There's their numbers. So let's see how we can do with ours. When I first ran this and showed off how ngrok was working, ngrok was pretty slow. But look at this right here, 84 millisecond latency. I don't know what they changed in the last couple of days, but it is way faster. And so it's not, you know, there's a good thing in general, right? We don't want stuff to be slow, but for this example, it was nice that it was slow. It's less slow now. So the numbers, I just can't get terrible numbers out of the original anymore, but we should see an improvement anyway. So let's go over here to the DevTools for this particular one, and let's just run Lighthouse. Make sure you're consistent. It doesn't really matter what you pick for some of these, but just be consistent when doing the comparison. And we'll say, analyze the page. You see all the requests coming in on the left over here. Incredible. So came back with 99%. So like I said, they really made it faster and it's hard. I'm gonna go and delete this and just run it one more time, delete the cache and see if that makes any difference. But it's ranking quite high, which is really good, but thanks, ngrok. Thanks for setting us up like that. 93 it is. Okay, so this is the original, right? Let's go to our fancy new version that we've got over here and do the same thing. Go to the DevTools. Now, when I run this, you might say, "Well, 93, we saw 99." There's probably no difference. There's still a huge difference and we will see it, but just not with Lighthouse yet, so hang tight. This one I would expect to be at least as good. Let's see what we got. You do see some stuff coming through here, but really not much. Those 404s are the map lookup files, remember? Look at this, 99%, 100, 100. Chef's kiss, beautiful. Let's just hit it one more time. 99. Okay, really, really good. I guess we could see where we could do better, right? Down here we could scroll down to opportunities. We could improve the image size and eliminating blocking renders, which are our fonts, but you know what? We want fonts and we want bootstraps. So sorry world, we're going to need it. Anyway, there's a couple of options. You can come through here and make it still better. By the way, these numbers I got like a hundred for best practices. That's not how it first came out, but then I went and looked and made it a little bit better before we started. So some of this advice has already been taken by me before we got started. So here is how we can analyze this with Lighthouse. We could cruise around the web and find some other places and test them as well, just to give you a sense. So let's try a place like Arstechnica. Great website. I think this will probably be pretty good. Hit this one, see what comes out of it. Yeah, this one's pretty good at 90, although we're still doing better. Let's try the Verge. The Verge is, I think it's going to be less good, but we'll see. Take it back. The Verge is amazing. So, you can go around to different places on the web and just run Lighthouse and get a sense of like, these are the websites that I feel are really excellent when I visit them, and these are ones that are poor, and you can compare your own website to it. But most important thing is, where did we start? Where did we end up? Are we in a better place than we were before? And take the advice. When it has items down here, you could look and say, okay, well, what can I do better? Properly size images. Sometimes you can do this, but you know what? If it's a responsive design, well, can't really, like for example, see here, it's hard to see 'cause it's rapid, img-responsive. I'm not gonna set a fixed size on this because I want it to adapt. Like, quite literally, as it gets bigger, Those images should get bigger and smaller as you can see. So the advice, it's not gospel, right? You wanted those to change potentially. So you don't have to take all the advice, but do look at what it's recommending there. A lot of times it's not obvious, something you haven't noticed before and it will make a big difference.
|
|
|
transcript
|
6:15 |
So it looks like, yes, we have made an improvement, but it wasn't major, was it? Well, in fact, it was a major improvement. It's just not entirely obvious within the scales that Lighthouse was giving us. Let's go into, let's say this Python, we'll go to the Apple, Apple category, that's a good one. And we'll do that for both sites here. And we've got all of our thumbnails and that type of thing. So let's just say we're gonna look at this page. If we analyze the lighthouse one more time, we see 98 for the original, and we see 99 just ahead for the improved version. But let's see if we can check it out from another perspective. How fast did this page load? So if these are gone, and I come over here and I click away, and I click back, kind of, you can sort of see it clicking in. This is the original, right? You can see it clicking in. Let's try it for the one on the CDN. Click away, click in. Click away, it definitely feels faster, but let's put some more numbers to that. Let's go over here and let's go to the DevTools here and back to the DevTools here and go to the Network tab. Okay, let's start with Disable Caching. This will show us what it feels like for the very first request. and I'll go ahead and move that up quite a bit. So if we hit this here, notice it loaded within processing everything about 450 milliseconds for total load time. And if you actually look at the DOM content loaded, 280 milliseconds, okay? That's the new version. Here we do the same thing. See, it's clicking and clicking and look at that, 1.2 seconds or 1,200 milliseconds. That's three times slower. So the first experience when you first land on the page, right, that's your no cache. I just discovered this cool new website and somebody linked to it. So I just clicked here and visited it. Like what is your experience? That's this disable cache story. So this is 1.4 seconds or if you totaled The total DOM content loaded is just over a second. And this one, do the same trick. Click away, click back. Here we go, 348. So three times better for first run experience. And if we leave the caching on, which is every subsequent interaction after that, come down here and click it again, come over here and click it again. Notice this is 391. I guess I gotta do it one more time really get the cache in, so. There we go, this one is 660 milliseconds. We hit it a few more times, five, get that tooltip away, 592, 585, 578, that's 599. So around 600 milliseconds is the cached experience, like the warmed up website experience for a user on our original one. So that's what we started with is 600. And how are we doing now? Let's see. Hit it again. 333, 336, 332, 238, 237, 237 compared to 600. Again, this is about three times better. Not quite, but really, really good. So I'm super happy with the progress that we made here. And moreover, as we have larger and larger content, we have more results, obviously these improvements are going to make a bigger difference, right? So as we have like pages with more videos or more images or those types of things, and it's going to take a lot of load off our server. And you can see that absolutely over here. So if I just clear out the one on the left is the old school and the one on the right It's the new school and I come over here and I just click the homepage. On this one, there's this stupid debug map, which actually, let me turn off the dev tools here. Click it. What do we get? We just get this. So with the dev tools turned off, it's not trying to pull the debug information. How much traffic did that put to our site? Very little, right? just got the HTML, none of the other stuff. If we do exactly the same thing on that side, I just click here, look at all that traffic, all that stuff that is hitting our website. So it's not just that it's a better experience, it means that we can possibly pay a third of the price for infrastructure. And if we were farther away, remember the ping time down here is like 88 milliseconds, so great. If somehow I could arrange it so that that ping times 800 milliseconds, then you can bet that light speed scale is going to change and the performance difference is going to be way bigger. And that is exactly what happens when users are farther away from us. So it's a little tricky to simulate things that are out of your control here, but that's the idea, right? Test it with Lighthouse, test it with the network tools, test it with caching off, test it with caching on and see how things are working. but also don't underestimate like that amount of work versus all the work over here. Like that's a lot more requests that the website has to do to support your clients. And that means bigger machines, more expensive machines, possibly more complex infrastructure 'cause you might need more than one and so on. So tons of benefits we got. And in the end, it turns out to be about three times faster from this still pretty good local version. version, but again, the farther you get away, the better the CDN version is going to turnout to be.
|
|
|
|
5:29 |
|
|
transcript
|
3:58 |
Well, we've come to the end. Hopefully all of this exposure and practice with using a CDN has opened your eyes like it did mine when I first experienced it to see just how easy and powerful as well as affordable a CDN can be. How much you can improve your web application for your users, not just those who are near the server, but across the globe. So I've had great experiences using the CDN for delivering content exactly like this that you're listening to or consuming, as well as making the website faster. And I hope that you do as well. So remember, we started out by looking at just the static content, everything under slash static slash whatever, those were perfect candidates for taking the load off of our servers and pushing them to all the 114 different locations around the world, close to our users, but also in effect scaling up our ability to serve all that data by having many, many different servers to process that in parallel. So if you've got something under slash static in your website, the chances are really, really good that that belongs behind a CDN if you care about making it super, super fast globally. Then we also realize, you know, some content is not contained within our website. It's not slash static slash user uploaded video. No that belongs over somewhere else, right? We're storing that in a database. We're pushing that into a cloud storage and with bony.net and other CDNs, you can create a storage pull zone, either linking to someplace like an S3 link, or you can upload them directly to the CDN and geo replicate those as well as we did in our large content section. All of our apps are best when they're as fast as they can be. The way we can make them incredibly fast is just tell the browsers like, if you've ever seen this file, it's good for months and months. You don't have to come back. You don't have to check in with us, months. Just if you see this name, you've already got it, okay? That's great until you make a change to that, isn't it? And as soon as you make a change, all of a sudden that change is not showing up for some of the users, but it is for others, depending on when they came to visit your site. So we talked about how to use that hashing of the file and the cache ID to put some kind of effective version number onto every static file, as well as to flip the bit on our pull zone to say vary by query string. So we pass something different in the query string for a static file. That means it's a different file and come and get it again, cache that also for three months. Okay, so it's really important that you add that cache busting functionality. Then we came to troubleshooting. With troubleshooting, we saw that the CDN itself has logs. You can go look there. We also saw a way to add, instead of hard coding the CDN prefix for all the static content, add a variable there that we can turn on and off so that we could actually run locally without the CDN content always needing to be fresh. And that's not useful just for troubleshooting, but it's also really handy for development. We talked about fonts, how certain font providers might be violating the GDPR or at least require a really aggressive statement about how you're sharing their data. Don't want that, do you? So we use bunny.fonts.bunny.net over there, drop-in replacement for Google Fonts, very nice. And the last thing we did is we realized that even if our Python code is running fast, that's not how users are experiencing it necessarily, right? They might get the HTML fast, but the images and CSS really slowly. So we can do different types of performance testing with the Network tab, as well as the Lighthouse tab of our Chrome-based browsers.
|
|
|
transcript
|
0:27 |
You probably already have forked and cloned the repo as well as starred it, but just in case you haven't, be sure to go over here to the GitHub repository at https://github.com/talkpython/fast-python-webapps-with-cdns and at least star it so that you have access to come back and get this long after you're done watching this course. So be sure to take this with you. The best way is to fork it, but if you don't want to fork it, at least star it so you can get back to it.
|
|
|
transcript
|
1:04 |
And finally, I just want to say thank you. Thank you for taking this course and I'll give you a few ways to stay in touch with me. Follow my writing over at https://mkennedy.codes. Subscribe over there for the RSS feed if you're interested in hearing announcements of my personal things that are going on. Of course, listen to the Talk Python To Me podcast. We dive into so many ideas like this every single week and explore how Python is mixed with all the other amazing things going on in the tech world. So if that sounds interesting to you and you're not already a subscriber to the podcast, check that out. Also Python Bytes, totally different style. I co-host this one with Brian Okken and we cover a bunch of news items and cool libraries every week. So be sure to stay in touch with us there. Obviously, thank you for coming to Talk Python Training. And if you do want to get in touch with me, you can do so over on Mastodon where I'm at mkennedy@fosstodon.org or just go to the website and find the contact us email. That's also works. So again, thank you, enjoy the CDNs, see you around.
|