Eve: Building RESTful APIs with MongoDB and Flask Transcripts
Chapter: Setup and tools
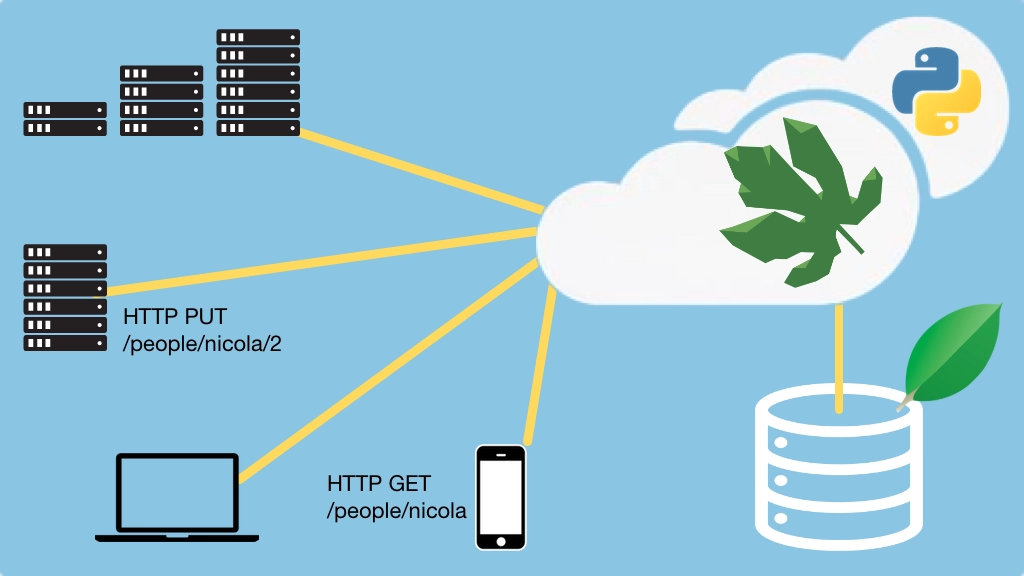
Lecture: Working with different versions of Eve
Login or
purchase this course
to watch this video and the rest of the course contents.
0:00
In this section, we're going to look at summary statistics for that student data that we just loaded. Let's get going.
0:06
Here's the summary statistics. This is taken from that University of California, Irvine website.
0:11
We've got multiple columns in here describing a student. And at the bottom here, we've got grades.
0:18
This data set was used to look into what features impact how a student performs on their grades.
0:24
And we see that there's a G1, G2, and G3, which are the grades. Now I'm not really going to get into modeling in this section here,
0:33
but we will look at some of the summary statistics. So the first thing I generally do when I've got a data set
0:40
is I'm going to look at the types of the data. And with Pandas, we can say .dtypes. This is going to return what's called a Pandas series.
0:49
And in the index of this series, we see the columns, and on the right-hand side, we see the types.
0:56
In this case, you'll notice that in brackets, we have PyArrow indicating that we are using PyArrow as the back-end,
1:04
and we have optimized storage there. We also see that there's int64s. So those are integer numbers that are backed by PyArrow.
1:13
They're using 8 bytes to represent the integer numbers. And we're not seeing any other types other than strings and integers here.
1:20
Another thing I like to do with Pandas is do this describe method. I was once teaching this describe method to some of my students
1:28
when I was doing some corporate training, and when I did it, someone went like this and hit themselves in the head,
1:33
and I asked them, what? What happened? Did I say something wrong? And they said, no, but we just spent the last three weeks
1:40
implementing this same describe functionality for our SQL database. So this is one of the nice things about Pandas.
1:48
It has a bunch of built-in functionality that makes it really easy. Describe is one line of code, and you get a lot of output from it.
1:55
So this is returning a Pandas data frame. Pandas is going to reuse a data frame and a series all over the place.
2:02
In this case, the index is no longer numeric. In the bold on the left-hand side, we can see count, mean, std, min.
2:09
That's the index. You can think of those as row labels. Along the top, we have the column names. These correspond to the original column names,
2:18
but these are the numeric columns. So for each numeric column, we have summary statistics. Count has a specific meaning in Pandas.
2:27
Generally, when you think of count, you think of this as how many rows we have. In Pandas, count doesn't really mean that.
2:34
It means how many rows don't have missing values. You just need to keep that in mind when you're looking at that count value.
2:43
Mean, that's your average. Standard deviation is an indication of how much your data varies.
2:48
We have the minimum value. At the bottom, we have the maximum value. In between there, we have the quartiles.
2:54
I like to go through this data and look at the minimum values and the maximum values to make sure that those make sense.
3:00
Maybe look at the median value, which would be the 50th percentile. Compare that to the mean to get a sense of how normal or how skewed our data is.
3:10
Also, look at those counts to see if we have missing values as well. In this case, it looks like most of our data is 5 or below.
3:19
We do have some going up to 22 or 75, but most of it is not very high. It doesn't look like we have any negative values.
3:28
Now, remember, we just looked at that Dtypes attribute, which said that we are using 8-byte integers to store this information.
3:36
Most of these values don't need 8 bytes to store them. In fact, all of them could be represented with 8 bits of memory.
3:45
We could use pandas to convert these integer columns to use 8 bits instead of 8 bytes for each number. That would use 1 8th the amount of memory.
3:56
We could shrink this data even further than we got by using PyArrow without any loss of fidelity in our data.
4:03
There are a bunch of other things that we can do. One of the methods is the quantile method. I'm going to run that. This actually failed.
4:12
Let's scroll down and look at the error here. It says, arrow not implemented. It says, function quantile has no kernel matching input type strings.
4:20
The issue here is we have non-numeric columns. To get around that, we can specify this parameter, numeric only is equal to true.
4:27
This is going to give us back a series. Why did this give us back a series? Because this is an aggregation method.
4:36
You can think of our original data as 2 dimensions. We are taking the quantile, the 99th percent quantile.
4:43
That is taking each of those columns and telling us what's the 99th percentile of that. It's collapsing it to a single value.
4:50
Because we have 2 dimensions, we're going to collapse each of those columns to a single row.
4:55
Pandas is going to flip that and represent that as a series where each column goes in the index and the 99th percentile goes into the value.
5:05
You'll see that Pandas uses data frames and series all over the place. You need to get used to these data structures.
5:11
The quantile method has various parameters that you can pass into it. In Jupyter, I can hold down shift and hit tab to pull up that documentation.
5:19
You can see that this Q parameter, the first parameter, accepts a float or an array-like or a sequence-like parameter.
5:27
In this case, instead of passing in 0.99, a scalar value like I did above, I'm going to pass in a list.
5:34
Let's say I want the first percentile, the 30th percentile, the 50th percentile, the 80th percentile, and the 99th.
5:41
When we do that, instead of getting back a series, we're now going to get back a Pandas data frame.
5:48
But if you look in the index here, the index is the quantiles that we asked for.
5:53
This illustrates that power of Pandas that you can do relatively complicated things with very little amount of code.
6:01
Also, you need to be aware that this is kind of confusing in that you can call the same method and it might return a one-dimensional object
6:09
or it might return a two-dimensional object depending on what you're passing into it. In this section, we looked at summary statistics of our data.
6:17
Once you've loaded your data into a data frame, you're going to want to summarize it to understand what's going on there.
6:24
That describe method is very useful. Then there are various other aggregation summaries that we can do as well. as well. I showed one of those which is