|
|
|
9:43 |
|
|
show
|
1:27 |
Hello and welcome to Asynchronus Techniques and Examples in Python.<br>
In this course, we're going to explore the entire spectrum of asynchronous programming in Python.<br>
This means threads, this means subprocesses the fancy new asyncio and the async and await keywords.<br>
All of that and much, much more.<br>
I hope you're excited about digging into it because I'm super excited to share it with you.<br>
Now before we get into the details of what we're going to cover, let's talk really briefly about what asynchronous programming is.<br>
If we go and look at Wikipedia it'll say asynchrony and computer programming refers the occurrence of events independent of the main program flow and way of dealing with such events.<br>
These may be outside events such as the arrival of signals or actions started by the program without blocking or waiting for results.<br>
Now what's really important about this statement is it doesn't say asynchronous programming is you create threads and then you join on them or you create other processes and wait for them to finish or get back to you.<br>
It just says stuff happening at the same time.<br>
So we're going to look at many different ways in fact we're going to explore three very different approaches that Python can take to this: threads, processes, and asyncio.<br>
We're going to explore more than that of course.<br>
But there's actually a lot of ways in which asynchrony can be achieved in Python and knowing when to choose one over the other is super important.<br>
We're going to talk all about that.
|
|
|
show
|
1:51 |
Here's a graph we're going to come back to and analyze at great depth later in the course.<br>
It came from a presentation by Jeffrey Funk.<br>
You can see the SlideShare link there if you want to go check it out.<br>
It's actually 172 slides.<br>
I want to just call your attention to this graph around 2005.<br>
If you look at, most importantly, the dark blue line that is single-threaded performance over time.<br>
Note, it's going up and up and up following Moore's law, that's the top line and then it flattens out and it actually is trending downward.<br>
What is going on here?<br>
Well, look at the black line.<br>
We have the number of cores going from one up to many right around 2005 and continuing on today.<br>
To take full advantage of modern hardware you have to target more than one CPU core.<br>
The only way to target more than one CPU core is to do stuff in parallel.<br>
If we write a regular while loop or some sort of computational thing in regular Python that is serial and it's only going to run on one core and that means it's following that blue downward line.<br>
But if we can follow the number of cores growing, well, we can multiply that performance massively, as we'll see.<br>
One of the reasons you care about asynchronous programming is if you have anything computational to do that depends on getting done fast not like I'm calling a database or I'm calling a web service and I'm waiting.<br>
That's a different type of situation we'll address.<br>
But no, I have this math problem or this data analysis problem and I want to do it as fast as possible in modern hardware.<br>
You're going to see some of the techniques that we talk about in this course allow us to target the new modern hardware with as much concurrency as needed to take full advantage of all the cores of that hardware.<br>
So like I said, we're going to dig way more into this later I just want to set the stage that if you have anything computational and you want to take full advantage of modern hardware, you need asynchronous programming.
|
|
|
show
|
4:52 |
Let's talk about the actual topics that we're going to cover chapter by chapter and how it all fits together.<br>
We're going to start digging further into why do we care about async, when should we use it, what are its benefits.<br>
So we're going to go way into it so you understand all the ways in which we might use asynchronous programming in Python, and when you might want to do that.<br>
Then it's time to start writing some code and making things concrete.<br>
We're going to focus first on the new key words introduced in Python 3.5 async and await.<br>
Now some courses leave this to the end as the great build-up, but I think you start here.<br>
This is the new, powerful way to do threading for anything that is waiting.<br>
Are you calling it database?<br>
Are you talking to a web service?<br>
Are you talking to the file system, things like that?<br>
We do these kinds of things all the time in Python and it' really not productive to just block our program while it's happening.<br>
We could be doing many other things.<br>
And the async and await key words in the asyncio foundation make this super straightforward.<br>
It's almost exactly the same programming model as the serial version but it's way more scalable and productive.<br>
Next we're going to focus on threads, sticking to making a single process more concurrent doing more at once.<br>
We're going to talk about a more traditional way of writing asynchronous code in Python with threads.<br>
We'll see sometimes this is super-productive.<br>
other times it's not as productive as you might hope especially because of things like the GIL raise its head.<br>
And we'll see when and how to deal with that.<br>
Some things are well-addressed with threads others not so much.<br>
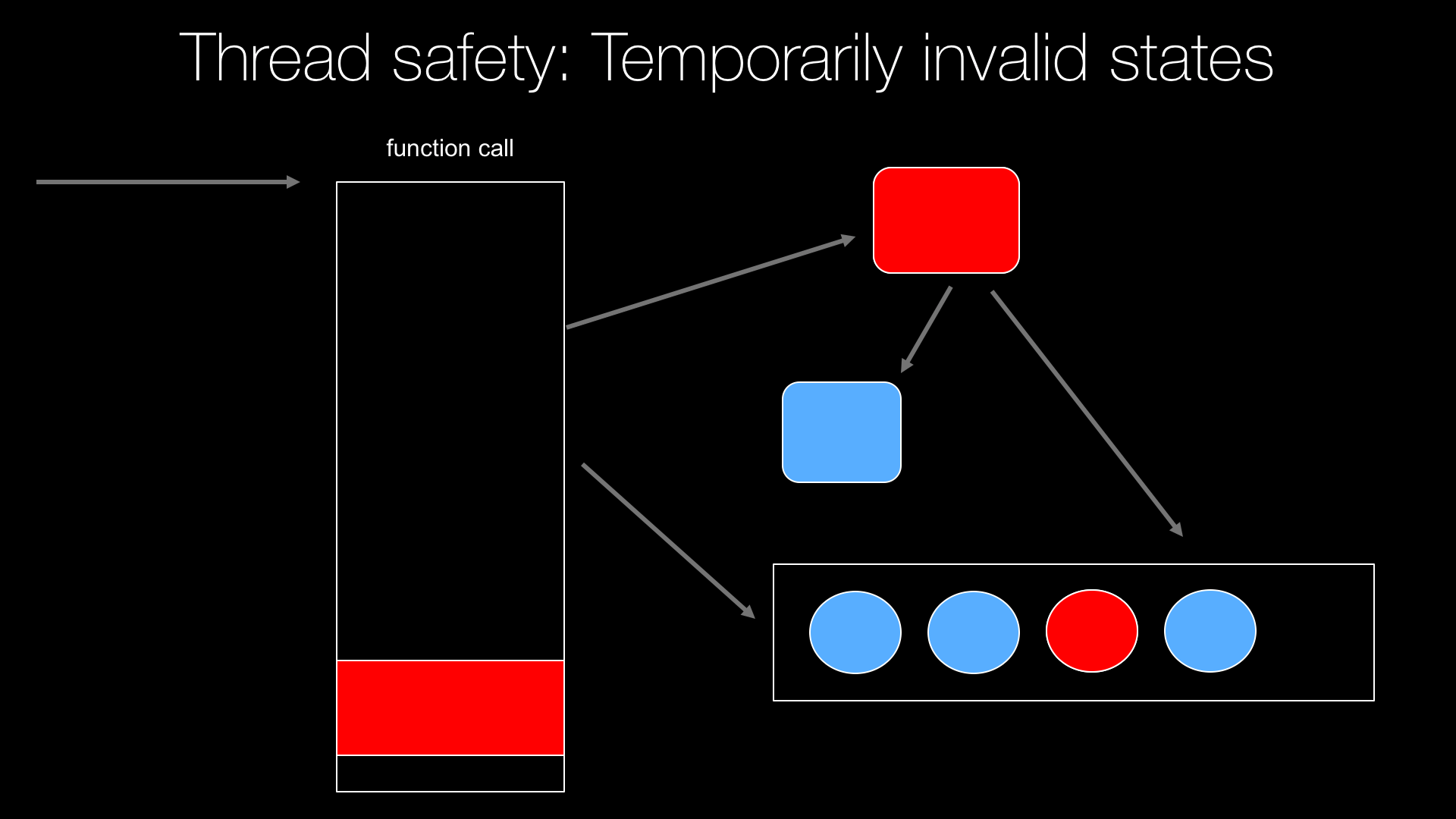
When we start writing multithreaded code or asynchronous code, in general we have to think very carefully about the data structures that we use and making sure that we don't encourage a race conditions or deadlocks.<br>
So in this chapter we're going to talk about both of those.<br>
How do we prevent race conditions that might allow code to see invalid data or corrupt our data structures?<br>
And how do we prevent deadlocks from completely freezing up our program by the improper use of the tools trying to prevent the first?<br>
So we're going to talk a lot about thread safety make sure you get that just right.<br>
Now Python has two traditional types of parallelism threaded parallelism and process-based parallelism.<br>
And the primary reason we have this is because of the GIL.<br>
We'll see that threaded-based parallelism is great when you're waiting on things like databases or web calls, things like that.<br>
But it's basically useless for computational work.<br>
So if you wanta do something computational we're going to have to employ process-based parallelism.<br>
We're going to talk about Python's native, multiprocessing process-based parallelism, with tools all around that meant to take a bunch of work and spread it across processes.<br>
You'll see that the API for working with threads and the API for working with processes are not the same.<br>
But the execution pools are ways to unify these things so that our actual algorithms or actual code depend as little as possible on the APIs for either threads or processes, meaning we can switch between threads or processes depending on what we're doing.<br>
So we wanta talk about execution pools and how to unify those two APIs.<br>
Then we're going to see two really interesting libraries that take async and await and asyncio and make it better make it easier to fall into the pit of success.<br>
You just do the right thing, and it just happens.<br>
The way it guides you, things work better.<br>
So things like cancellation, parent/child tasks or any mix mode of, say, some IO-boundwork and some CPU boundwork.<br>
That can be really tricky, and we'll see some libraries that make it absolutely straightforward and obvious.<br>
One of the great places we would like to ply asyncio is on the web.<br>
That's a place where we're waiting on databases and other web services all the time.<br>
We'll see the traditional, popular frameworks like Django, Flask, Pyramid do not support any form of asynchrony on the web.<br>
So we'll take something that is a Flask-like API and adapt it to use asyncio and it's going to be really, really great.<br>
We'll see massive performance improvements around our web app there.<br>
Finally, we'll see that we can integrate C with Python and, as you know, C can do just about anything.<br>
Your operating system is written in C.<br>
It can do whatever it wants.<br>
So we'll see that C is actually a gateway to a different aspect, different type of parallelism and performance in Python.<br>
But we don't wanta write C.<br>
Maybe you do, but most people don't want to write C if they're already writing Python.<br>
So we'll see that we can use something called Cython to bridge the gap between C and Python and Cython has special key words to unlock C's parallelism in the Python interpreter.<br>
It's going to be great.<br>
So this is what we're covering during this course and I think it covers the gamut of what Python has to offer for asynchronous programming.<br>
There's so much here; I can't wait to get started sharin' it with you.
|
|
|
show
|
0:44 |
Let's take a moment and just talk really quickly about the prerequisites for this course.<br>
What do we assume you know?<br>
Well, we basically assume that you know Python.<br>
This course is kind of intermediate to advanced course I would say, it's definitely not a beginner course.<br>
We run through all sorts of Python constructs classes, functions, keyword arguments, things like that without really explaining them at all.<br>
So if you don't know the Python language you're going to find this course a little bit tough.<br>
I recommend you take my Python Jumpstart by Building 10 Apps, and then come back and pick this course up.<br>
You don't have to be an absolute expert in Python but like I said, if you're brand new to the language take a foundational course first and then come back and dig in to the Asynchronous Programming after that.
|
|
|
show
|
0:49 |
Finally in this chapter, I just want to say hello and thank you for taking my course.<br>
My name is Michael Kennedy, find me on Twitter @mkennedy.<br>
You may know me from The Talk Python To Me podcast or the Python Bytes podcast.<br>
I am the host or co-host on both of those and each of them cover different aspects of asynchronous programming, so for example I've had Nathaniel on to talk about Trio which is one of the libraries we're going to cover.<br>
Philip Jones to talk about Quart another thing we're going to use in this course on the Talk Python To Me podcast.<br>
You can listen to those interviews.<br>
And on the Python Bytes, we highlight all sorts of libraries that are really useful for asynchronous programming.<br>
So make sure to check those out if you're interested and I'm also the founder of Talk Python Training.<br>
Welcome to my course, it's great to meet you and I'm looking forward to helping you demystify asynchronous programming.
|
|
|
|
5:57 |
|
|
show
|
1:40 |
In this short chapter, we're going to talk about setting up your computer so that you can follow along.<br>
Do you have the right version of Python?<br>
What editors are you going to use?<br>
Can you get the source code to get started on some of the examples?<br>
Things like that.<br>
Obviously this is a Python course so you're going to need Python.<br>
But, in particular, you need Python 3.5 or higher.<br>
Now I would recommend the latest, Python 3.7.<br>
Maybe you're on a Linux machine, and it auto-updates as part of the OS, and that's probably 3.6.<br>
But you absolutely must have Python 3.5 because that's when some of the primary async language features were introduced namely, the async and await keywords.<br>
Do you have Python, and if you do, what version?<br>
Well, the way you answer that question varies by OS.<br>
If you are on Mac or you're on Linux you just type 'Python3 -V' and it will show you the Python version.<br>
In this screenshot, I had Python 3.6.5 but in fact, 3.7 is out now so you might as well go ahead and use that one.<br>
But if you type this and you get an answer like 3.5 or above, you're good.<br>
If it errors out, you probably don't have Python.<br>
I'll talk about how to get it in a sec.<br>
Windows, it's a little less straightforward.<br>
You can type 'where Python' and the reason you want to do that is there's not a way to target Python 3 in particular it just happens to be the first Python.exe that lands in your path.<br>
So by typing 'where' you can see all the places and down here you can see I typed 'Python -V' again same command but without the '3' and I got Python 3.6.5, the Anaconda version.<br>
That would be fine for this course Anaconda's distribution should be totally fine.<br>
But, again, has to be 3.5 or above.
|
|
|
show
|
0:39 |
If you don't have Python or you have an older version of Python or you would just like to get a newer version of Python yes, you can go to Python.org and download it but I recommend that you check out Real Python's article on installing and managing and upgrading Python.<br>
So just visit realPython.com/installing-Python and check it out.<br>
The guys over there are putting lots of effort into keeping this up to date.<br>
For example, one of the ways you might want to install it on macOS would be to use Homebrew and that's different than what you get off of Python.org.<br>
It let's you upgrade it a little more easily.<br>
That's the way I'm doing it these days and really liking it so far.<br>
So this article will help you find the best way to install it on your OS.
|
|
|
show
|
0:53 |
In this course like most of our courses I'm going to be using PyCharm.<br>
Now you don't have to use exactly the same editor.<br>
You can use Visual Studio Code with a Python plug-in.<br>
You can use Emacs.<br>
You can use Vim.<br>
Whatever makes you happy.<br>
But if you want to follow along exactly.<br>
Then I recommend you use Pycharm.<br>
Now almost all of this course can be done in the Community Edition, the free edition of PyCharm.<br>
There is one chapter on web development.<br>
Maybe it's a little bit easier with PyCharm Pro but because we're not really working with CSS, JavaScript the template, anything like that I think you could actually use PyCharm Community Edition for the entire course.<br>
So if you want to use that just visit jetbrains.com/pycharm.<br>
Get it installed and I'll show you how to use it along the way.<br>
If you want to use something else, like I said, no problem use what makes you happy.<br>
Just be aware this is the one we're using so you have to adapt your editor and waverunning code to what we have over here.
|
|
|
show
|
0:30 |
You might consider what hardware you're taking this course on.<br>
Most of the time, the courses we have it doesn't matter what you're running on.<br>
You could probably take many of the courses we have on here, on say like, a Raspberry Pi or something completely small and silly like that.<br>
However, on this one you really need to have at least two cores.<br>
If you don't have two cores, you're not going to be able to observe some of the performance benefits that we talk about.<br>
So here's my machine, I have a MacBook Professional 15 inch, 2018 edition with the Core i9 which you can see 12 cores here.<br>
Six real cores, each of them hyper thread.<br>
So it appears as 12 to the operating system.<br>
But this system will really let us see a difference from when we're running on single threaded mode to parallel mode that actually takes advantage of all of the processors.<br>
But you don't have to have 12 cores.<br>
If you have two or four that will already let you see a difference but the more the better for this course because when we get to the performance section in particular, the CPU bound type of stuff we're trying to take advantage of the CPU you'll just see a bigger benefit, the more cores you have.<br>
So at least dual core is not required but to see some of the benefits you have to have more than one core.
|
|
|
show
|
1:13 |
Every single thing you see me type in this course will be available to you in GitHub.<br>
Before you go farther, pause the video and go over to GitHub.com/talkPython/async-techniques-Python-course You can also just click the link to this GitHub repo in your course details page.<br>
You want to make sure you get access to this and go over there and star and consider forking it as well.<br>
That way you have a copy of exactly we're working with during this course.<br>
I encourage you to play around and write some code and try out the ideas from each chapter as we get to them.<br>
Most of the chapters have a starting and final version of code.<br>
So if you wanted to take, say, a serial single threaded computational little app that we build, and convert it to threads and convert it to multiprocessing, and things like that you'll have a copy over here on GitHub.<br>
So just be sure to star this, and consider forking it.<br>
Definitely check it out so you have access to it.<br>
If you don't do Git and that's fine, just click where it says clone or download, and download a zip, and then you'll have the source, as well.
|
|
|
|
1:02 |
|
|
|
26:24 |
|
|
show
|
3:42 |
Let's begin our exploration of async by taking a really high-level view, we're going to look at the overall async landscape, some of the particulars about working with async in concurrent programming in Python, and the two main reasons that you care about asynchronous programming.<br>
In this first video we're going to focus on async for speed or for performance, the other main reason you might care about asynchronous programming or concurrent code would be for scalability, doing more at once.<br>
Right now we're going to focus on doing things faster for an individual series of computations.<br>
Later we're going to talk about scalability say for web apps and things like that.<br>
Let's look at some really interesting trends that have happened across CPUs in the last 10 years or so, 15 years.<br>
So here's a really great presentation by Jeffrey Funk over on SlideShare and I put the URL at the bottom you can look through the whole thing, you can see there's 172 slides, but here I am pulling up one graphic that he highlights, because it's really, really interesting.<br>
See that very top line, that red line, that says transistors in the thousands, that is Moore's Law.<br>
Moore's Law said the number of transistors in a CPU will double every 18 months and that is surprisingly still accurate; look at that, from 1975 to 2015 extrapolate a little bit, but still basically doubling just as they said.<br>
However people have often, at least in the early days thought of Moore's Law more as a performance thing as the transistors doubled, here you can see the green line "clock speed" and the blue line "single threaded performance" very much follow along with Moore's Law.<br>
So we've thought about Moore's Law means computers get twice as fast every 18 months and that was true more or less for a while, but notice right around 2008, around 2005 it starts to slow and around 2008 that flattens off and maybe even goes down for some of these CPUs and the reason is we're getting smaller and smaller and smaller circuits on chips down to where they're basically at the point of you can't make them any smaller, you can't get them much closer both for thermal reasons and for pure interference reasons.<br>
You can notice around 2005 onward, CPUs are not getting faster, not really at all.<br>
I mean, you think back quite a bit and the speed of the CPU I have now is I have a really high-end one, it's a little bit faster but nothing like what Moore's Law would have predicted.<br>
So what is the take away?<br>
What is the important thing about this graphic?<br>
Why is Moore's Law still effective?<br>
Why are computers still getting faster, but the CPU and clock speed, really performance speed, single-threaded performance speed, is not getting faster, if anything it might be slowing down a little.<br>
Well that brings up to the interesting black graph at the bottom, for so long this was one core and then when we started getting dual-core systems and more and more CPUs, so instead of making the individual CPU core faster and faster by adding more transistors what we're doing is just adding more cores.<br>
If we want to continue to follow Moore's Law if we want to continue to take full advantage of the processors that are being created these days we have to write multi-threaded code.<br>
If we write single-threaded code, you can see it's either flat, stagnant, or maybe even going down over time.<br>
So we don't want our code to get slower, we want our code to keep up and take full advantage of the CPU it's running on and that requires us to write multi-threaded code.<br>
Turns out Python has some extra challenges, but in this course we will learn how to absolutely take full advantage of the multi-core systems that you're probably running on right now.
|
|
|
show
|
3:54 |
Let's look at a real world example of a Python programming that is doing a very poor job taking advantage of the CPU it's running on.<br>
I'm running on my MacBook that I discussed in the opening, has 12 cores.<br>
This is the Intel i9 12 core maxed out you know, all nobs to 11 type of CPU for my MacBook Pro, here, so you can see it has a lot of processors.<br>
It has a lot of cores.<br>
In particular, has 12 hyper-threaded cores so six real cores, each one of which is hyper-threaded.<br>
Here we have a program running in the background working as hard as it can.<br>
How much CPU is the entire computer using?<br>
Well, 9.5%.<br>
If this were 10 years ago, on single core systems the CPU usage would be 100% but you can see most of those cores are dark, they're doing nothing they're just sitting there.<br>
That's because our code is written in a single-threaded way.<br>
It can't go any faster.<br>
Let's just look at that in action real quick.<br>
Now, this graph, this cool graph showing the 12 CPUs and stuff this comes from a program called Process Explorer which is a free program for Windows.<br>
I'm on my Mac, so I'll show you something not nearly as good but I really wanted to show you this graph because I think it brings home just how underutilized this system is.<br>
So let's go over here and we're going to run a performance or system monitoring tool actually built in Python which is pretty cool in and of itself, called Glances.<br>
So we're sorting by CPU usage, we're showing what's going on.<br>
We had a little Python running there, actually for a second, running probably in PyCharm which is just hanging out, but you can see the system is not really doing a whole lot, it is recording.<br>
Camtasia's doing a lot of work to record the screen so you have to sort of factor that out.<br>
Now, let's go over here and create another screen notice right here we have 12 cores.<br>
Okay, so if we run PtPython, which is a nicer REPL but just Python, and we write an incredibly simple program that's going to just hammer the CPU.<br>
Say x = 1, and then while true: x += 1.<br>
So we're just going to increment this, over and over and over.<br>
I'm going to hit go, you should see Python jump up here and just consume 100% of one core.<br>
This column here is actually measuring in single core consumption whereas this is the overall 12 core bit.<br>
Here it's working as hard as it can.<br>
You'll see Python'll jump up there in a second.<br>
Okay, so Python is working as hard as it can, 99.8% running out of my brew installed Python, there.<br>
But the overall CP usage, including screen recording on this whole system?<br>
11%, and of course as we discussed, that's because our code we wrote in the REPL, it only uses one thread, only one thread of concurrent execution that means the best we could ever possibly get is 1/12%.<br>
8.3% is the best we could ever do in terms of taking advantage of this computer unless we leverage the async capabilities that we're going to discuss in this course.<br>
So if you want to take advantage of modern hardware with multiple cores, the more cores the more demanding or more pressing this desire is you have to write concurrent multi-threaded code.<br>
Of course, we're going to see a variety of ways to do this both for I/O bound and, like this, CPU bound work and you handle those differently in Python which is not always true for other languages but it is true for Python.<br>
And by the end of this course, you'll know several ways to make, maybe not this simple, simple program but to make your Python program doing real computation push that up to nearly 100% so it's fully taking advantage of the CPU capabilities available to it.
|
|
|
show
|
3:53 |
Now you may be thinking, "Oh my gosh, Michael you have 12 CPUs, you can make your code go 12 times faster." Sorry to tell you that is almost never true.<br>
Every now and then you'll run into algorithms that are sometimes referred to as embarrassingly parallelizable.<br>
If you do, say, ray tracing, and every single pixel is going to have it's own track of computation.<br>
Yes, we could probably make that go nearly 12 times faster.<br>
But most algorithms, and most code, doesn't work that way.<br>
So if we look at maybe the execution of a particular algorithm, we have these two sections here, these two greens sections that are potentially concurrent.<br>
Right now they're not, but imagine when we said "Oh that section and this other section.<br>
We could do that concurrently." And let's say those represent 15% and 5% of the overall time.<br>
If we were able to take this code and run it on an algorithm that entirely broke that up into parallelism, the green parts.<br>
Let's say the orange part cannot be broken apart.<br>
We'll talk about why that is in just a second.<br>
If we can break up this green part and let's imagine we had as many cores as we want, a distributed system on some cloud system.<br>
We could add millions of cores if we want.<br>
Then we could make those go to zero.<br>
And if we could make the green parts go to zero like an extreme, non-realistic experience but think of it as a upper bound then how much would be left?<br>
80%, the overall performance boost we could get would only be 20%.<br>
So when you're thinking about concurrency you need to think about, well how much can be made concurrent and is that worth the added complexity?<br>
And the added challenges, as we'll see.<br>
Maybe it is.<br>
It very well may be.<br>
But it might not be.<br>
In this case, maybe a 20% gain but really added complexity.<br>
Maybe it's not worth it.<br>
Remember that 20% is a gain of if we could add infinite parallelism basically, to make that go to zero which won't really happen, right?<br>
So you want to think about what is the upper bound and why might there might be orange sections?<br>
Why might there be sections that we just can't execute in parallel?<br>
Let's think about how you got in this course.<br>
You probably went to the website, and you found the course and you clicked a button and said, "I'd like to buy this course," put in you credit card, and the system went through a series of steps.<br>
It said, "Well, OK, this person wants to buy the course.<br>
"Here's their credit card.<br>
We're going charge their card then we're going to record an entry in the database that says they're in the course and then we're going to send an email that says, hey, thanks for buying the course here's your receipt, go check it out." That can't really be parallelized.<br>
Maybe the last two.Maybe if you're willing to accept that email going out potentially if the database failed, it's unlikely but, you know, possible.<br>
But you certainly cannot take charging the credit card and sending the welcome email and make those run concurrently.<br>
There's a decent chance that for some reason a credit card got typed in wrong it's flagged for fraud, possibly not appropriately but, right, you got to see what the credit card system and the company says.<br>
There might not be funds for this for whatever reason.<br>
So we just have to first charge the credit card and then send the email.<br>
There's no way to do that in parallel.<br>
Maybe we can do it in a way that's more scalable that lets other operations unrelated to this run.<br>
That's a different consideration but in terms of making this one request this one series of operations faster we can't make those parallel.<br>
And that's the orange sections here.<br>
Just, a lot of code has to happen in order and that's just how it is.<br>
Every now and then, though, we have these green sections that we can parallelize, and we'll be focused on that in this course.<br>
So keep in mind there's always an upper bound for improvement, even if you had infinite cores and infinite parallelism, you can't always just make it that many times faster, right?<br>
There's these limitations, these orange sections that have to happen in serial.
|
|
|
show
|
1:49 |
Next up, let's focus on how we can use asynchronous or concurrent programming for scalability.<br>
I want to take just a moment to address this word, scalability.<br>
Often, people sort of think of scalability as performance and performance equaling speed and things being faster.<br>
And that's not exactly what it means.<br>
Let's think in terms of websites here.<br>
That's not the only time we might think of this scalability concept.<br>
But let's think in terms of websites.<br>
If your website can process individual requests 10 times faster, it will be more scalable because it won't back up as much, right?<br>
Scalability doesn't refer to how fast an individual request can be it refers to how many requests can your website handle or your system handle, until its performance degrades.<br>
And that degrade might be just really long request times before you get back to someone or the browser.<br>
It might mean it's so bad that requests start timing out.<br>
It might mean that your system actually crashes.<br>
There's some point where your system degrades in performance.<br>
And when you talk about how scalable is a system it's how much concurrent processing?<br>
How many requests at one time can it handle until it starts to degrade?<br>
As we add scalability to the system we might even make it a tiny bit slower for an individual request.<br>
There's probably a little bit more work we're doing to add this capability to scale better, maybe.<br>
It's not exactly talking about individual request speed because that actually might get worse.<br>
However, it means maybe we could handle 10 times as many concurrent users or 100 times as many concurrent users on exactly the same hardware.<br>
That's what we're focused on with scalability.<br>
How do we get more out of the same hardware?<br>
And we'll see that Python has a couple of really interesting ways to do that.
|
|
|
show
|
3:34 |
Let's visualize this concept of scalability around a synchronous series of executions.<br>
So many web servers have built in threaded modes for Python and to some degree that helps but it just doesn't help as much as it potentially could.<br>
So we're going to employ other techniques to make it even better.<br>
So let's see what happens if we have several requests coming into a system that executes them synchronously one after another.<br>
So a request comes in, request 1, request 2 and request 3 pretty much right away.<br>
In the green boxes request 1, 2 and 3 those tell you how long those requests take.<br>
So request 1 and request 2, they look like maybe they're hitting the same page.<br>
They're doing about the same thing.<br>
3's actually really short.<br>
Could theoretically if it were to move to the front be needing a return much quicker.<br>
So let's look at how this appears from the outside.<br>
So a request 1 comes in and it takes about that long for the response.<br>
But during that time request 2 came in and now before it could even get processed we have to wait for most of 1.<br>
So that's actually worse because we're not scaling.<br>
Okay, we can't do as much concurrently.<br>
And finally if we look at 3, 3 is really bad.<br>
So 3 came in almost the same time as 1 started but because the two longer requests were queued up in front of it, it took about five times four times as long as the request should of taken for it to respond because this system was all clogged up.<br>
Now let's zoom into one of these requests into request 1 and if we look deep inside of it we can break it down into two different operations.<br>
We have a little bit of framework code I'm just going to call that framework because you can't control that, you can't do much with that, right.<br>
This is the system actually receiving the socket data creating the request response objects, things like that.<br>
And then right at the beginning maybe the first thing we want to do is say I would like to find out what user's logged in making this request.<br>
So when I go to the database, I want to get we'll maybe get a user ID or some kind of cookie from their request and I'm going to use that cookie to retrieve the actual object that represents this user.<br>
Then maybe that user wants to list, say their courses.<br>
So then we're going to do a little bit of code to figure out what we're going to do there.<br>
Okay, if the user's not None and we're going to make this other database call and that database call might take even longer in terms of more data.<br>
And then that response comes back.<br>
We do a little bit of work to prepare it we pass off to the framework template and then we just hand it off to the web framework.<br>
So this request took a long time but if you look why it took a long time, it's mostly not because it's busy doing something.<br>
It's because it's busy waiting.<br>
And when you think about web systems, websites web servers and so on, they're often waiting on something else.<br>
Waiting on a web API they're calling waiting on a database, waiting on the file system.<br>
There's just a lot of waiting.<br>
Dr.<br>
Seuss would be proud.<br>
Because this code is synchronous, we can't do anything else.<br>
I mean theoretically, if we had a way to say well we're just waiting on the database go do something else, that would be great.<br>
But we don't.<br>
We're writing synchronous codes, so we call this function call the database query function and we just block 'til it responds.<br>
Even in the threaded mode, that is a tied up thread over in the web worker process so this is not great.<br>
This is why our scalability hurts.<br>
If we could find a way to process request 2 and request 3 while we're waiting on the database in these red zones, we could really ramp up our scalability.
|
|
|
show
|
2:14 |
Let's look at this same series of requests but with our web server having the ability to execute them concurrently at least while it's waiting.<br>
So now we have request 1 come in and it's...<br>
we can't make that green bar get any shorter that's how long it takes.<br>
But, we saw that we were waiting before and if we could somehow run request 2 while we're waiting and then request 3 while both of those are waiting we could get much better response times.<br>
So if we look at our response time again we have...<br>
1 takes exactly as long as it did before cause it was the first one, it was lucky.<br>
But it takes as long as it takes.<br>
However, request 2 is quite a bit shorter.<br>
Didn't have to wait for that other processing we're able to execute it concurrently.<br>
request 3 is the real winner here.<br>
Actually, it returned much, much sooner.<br>
It takes as long as it takes to process it instead of five times.<br>
Now we can't possibly get perfect concurrency, right?<br>
If we could do every single one of them concurrently then there'd be no need to have anything other than a five dollar server to run YouTube or something.<br>
There is some overhead.<br>
There are bits of R Code and framework code that don't run concurrently.<br>
But, because what our site was doing is mostly waiting we just found ways to be more productive about that wait time.<br>
Zooming in again, now we have exactly the same operation.<br>
Exactly the same thing happening but then we've changed this code.<br>
We've changed ever so slightly how we're calling the database and we've freed up our Python thread of execution or just the execution of our code.<br>
Let's not tie to threads just yet.<br>
So that we can do other stuff.<br>
So request 2 came in, right during that first database operation we're able to get right to it.<br>
By the time we got to our code section request 2 had begun waiting so then we just ran our code, we went back to waiting request 3 came in, and we just processed that because both of the others were waiting and so on.<br>
So we can leverage this wait time to really ramp up the scalability.<br>
How do we do it?<br>
Well, it's probably using something called AsyncIO which we're going to talk about right away.<br>
It may even be using Python threads but it's probably AsyncIO.<br>
If you don't know what either of those are that's fine, we're going to talk about them soon.
|
|
|
show
|
4:25 |
I want to draw a map or an illustration for you of Python's Async landscape.<br>
So you'll see that there are many different techniques that we're going to employ throughout this course and different techniques apply in different situations or they will potentially give you different benefits.<br>
So we're going to break the world into two halves here.<br>
On one, we're going to say "Can we do more at once?" That's exactly the thing we just spoke about with say the web server.<br>
While our database request is busy waiting let's go do something else.<br>
The part we opened this chapter with about leveraging the CPU cores and actually computing a single thing faster by taking advantage of the mutli-core systems, that's doing things faster.<br>
Over in the do more at once, we have this thing called Asyncio.<br>
Asyncio was introduced to Python around Python 3.4, but really came into it's own when the language began to work with it, with async and await keywords in Python 3.5.<br>
So Asyncio is the easiest, clearest, simplest way to add scalability like we just saw in our concurrent request example.<br>
You're waiting on something, go do something else.<br>
We also have threads and threads have been around much longer.<br>
They're harder to coordinate, they're harder to deal with error handling, but they're also a really great option to do more at once.<br>
In some programming languages, threads would also be over in the do things faster.<br>
We're going to get to why that is, but you may have heard a thing called the GIL and the GIL means computationally threads are effectively useless to us.<br>
They let you do more things at once if there's a waiting period, but if it's purely computational in Python, threads are not going to help us.<br>
What will help us?<br>
Because the GIL is a process level thing, Python has this capability to spawn sub-processes and a lot infrastructure and APIs to manage that.<br>
So instead of using threads, we might kick off five sub-processes that are each given a piece of the data and then compute the answer and return it to the main process.<br>
So we'll see multi-processing is a tried and true way to work with adding computational performance improvements and taking advantage of multiple cores and this is usually done for computational reasons.<br>
We want to leverage the cores, not we want to talk to the database a bunch of times in parallel.<br>
We would probably use threads for that.<br>
We're also going to look at C and Cython.<br>
C, C++, and Cython.<br>
So C obviously can do multiple multi-threaded stuff.<br>
It could also do more at once but you know, we're going to leverage it more for the aspect of doing things faster in a couple ways.<br>
However, writing C can be a little bit tricky.<br>
It can be error prone and so on.<br>
As a Python developer, it would be better if more of our code could actually be in Python or very very close to Python.<br>
So we're going to talk about this thing called Cython not CPython but Cython.<br>
Cython is a static compiler that compiles certain flavors of Python to C and then basically compiles that C and runs it under the restrictions that C has which are very limited rather than the restrictions that Python has which is fairly limited.<br>
So we'll be able to use Cython for very powerful multi-threading as well.<br>
That's more using the threads in a computational way.<br>
So this is the landscape.<br>
On one hand we have do more at once.<br>
Take advantage of wait periods.<br>
On the other, we have do things faster take advantage of more cores.<br>
Now these are all fine, Asyncio is really nice, but there is also other libraries and other techniques out there that allow us to do these things more easily.<br>
We're going to look at two libraries.<br>
These are by no means a complete list of these types of libraries, but we're going to look at something called Trio something called Unsync.<br>
Aynsc Unsync - get the play on words right?<br>
So these are higher level libraries that do things with the Asyncio capabilities, with threads with multi-processing and so on, but put a new programming API on them, unify them, things like that.<br>
This is your Python Async landscape.<br>
Do more at once do things faster, do either of those easier.<br>
Basically, that's what this course is about.<br>
By the end of this course, you'll have all of these in your tool box and you'll know when to use which tool.
|
|
|
show
|
2:53 |
I mentioned earlier that threads in Python don't really perform well.<br>
They're fine if you're waiting but if you're doing computational stuff they really don't help.<br>
Remember that example I showed you how we had our Python program doing a tight while loop that was just pounding the CPU and it's only getting 8.3% CPU usage.<br>
Well if we had added 12 threads to do that how much of a benefit would it have gotten?<br>
Zero, it would still only be using 8% of the CPU, even though I have 12 cores.<br>
And the reason is this thing called the GIL or the Global Interpreter Lock.<br>
Now the GIL is often referred to as one of the reasons that Python isn't super fast or scalable.<br>
I think that's being a little bit harsh.<br>
You'll see there's a lot of places where Python can run concurrently and can do interesting parallel work.<br>
And it has a lot of things that have been added like AsyncIO and the await, the async and await keywords which are super, super powerful.<br>
The GIL is not the great terrible thing that people have made it out to be but it does mean that there's certain situations where Python cannot run concurrently.<br>
And that's a bummer.<br>
So this is the reason that the Python threads don't perform well.<br>
The Global Interpreter Lock means only one thread or only one step of execution in Python can ever run at the same time regardless of whether that's in the same thread or multiple threads, right?<br>
The Python interpreter only processes instructions one at a time, no matter where they come from.<br>
You might think of this as a threading thing and in some sense it's a thread safety thing but the GIL is actually a memory management feature.<br>
The reason it's there, is it allows the reference counting which is how Python primarily handles its memory management, to be simpler and faster.<br>
With the Global Interpreter Lock that means we don't have to take many fine-grained locks around allocation and memory management.<br>
And it means single-threaded Python is faster than it would otherwise be although it obviously hurts parallel computation.<br>
But the thinking is most Python code is serial in its execution, so let's make that the best and the GIL is what it is.<br>
It's going to make our parallelism less good.<br>
As you'll see throughout this course Python has a lot of options to get around the GIL to do true concurrent processing in Python and we're going to talk about those but the GIL cannot be avoided and your should really understand that it exists, what it is, and primarily that it's a thread safety feature for memory management.<br>
You can learn about it more if you want at realPython.com/Python-gil, G-I-L and there's a great article there it goes into all the depth and the history and so on, so go check that out if you're interested in digging into it.<br>
Keep in mind, this GIL is omnipresent and we always have to think about how it affects our parallelism.
|
|
|
|
56:33 |
|
|
show
|
1:15 |
We're going to start our actual exploration and programming examples of concurrency in Python without threads and without sub-processes.<br>
That's right, we're going to do concurrent programming no threads, no sub-processes.<br>
It may sound impossible.<br>
It certainly sounds kind of weird, right?<br>
We think of parallel programming as involving multiple threads or maybe multiple processes in the case of a sub-process.<br>
But we're going to see that there's a new, fancy way that is mostly focused on scalability that does not at all involve threads in Python.<br>
It is my favorite type of concurrent programming in Python by far.<br>
Of course I'm speaking about AsyncIO.<br>
AsyncIO is what you might call cooperative concurrency or parallelism.<br>
The programs themself state explicitly "Here's a part where I'm waiting you can go do something else.<br>
Here's another part where I'm waiting on a web request or a database you can go do other work right then, but not other times." With threads we don't have this certainly with multi-processing in Cython we don't have this.<br>
So where are we on this landscape?<br>
We're in this green AsyncIO area and of course, Trio and Unsync are built on top of that.<br>
So, I kind of highlighted that as well but we're not going to talk explicitly about those yet.<br>
This is the foundation of those libraries.
|
|
|
show
|
3:51 |
If you haven't worked with AsyncIO before it's going to be a little bit of a mind shift.<br>
But it turns out the programming model is actually the easiest of all the concurrent programming models that we're going to work with.<br>
So don't worry, it's actually the easiest, newest, and one of the best ways to write concurrent programs in Python.<br>
So let's step back a minute and think about how do we typically conceptualize or visualize concurrency?<br>
Well, it usually looks something like this.<br>
We have some kind of code running and then we want to do multiple things at a time so we might kick off some other threads or some other processes.<br>
And then our main thread, and all the other threads are going to run up to some point, and we're going to just wait for that secondary extra work to be done.<br>
And then we're going to continue executing along this way.<br>
Like I said, this is typically done with threads or multiprocessing, okay?<br>
Many languages it's only threads in Python, because the GIL multiprocessing is often involved.<br>
Now, this model of concurrent programming one thread kicking off others waiting for them to complete, this fork-join pattern this makes a lot of sense.<br>
But in this AsyncIO world, this is typically not how it works.<br>
Typically, something entirely different happens.<br>
So in this world, we're depending upon the operating system to schedule the threads or schedule the processes and manage the concurrency.<br>
It's called preemptive multithreading.<br>
Your code doesn't get to decide when it runs relative to other parts of your code.<br>
You just say I want to do all these things in parallel it's the operating system's job to make them happen concurrently.<br>
Now, contrast that with I/O driven concurrency.<br>
So in I/O driven concurrency we don't have multiple threads.<br>
We just have one thread of execution running along.<br>
This may be your main app, it actually could be a background thread as well but there's just one thread managing this parallelism.<br>
Typically, when we have concurrency if we have multiple cores, we're actually doing more than one thing at a time assuming the GIL's not in play.<br>
We're doing more than one thing at a time.<br>
If we could take those multiple things we're trying to do and slice them into little tiny pieces that each take a fraction of a second or fractions of milliseconds and then we just interweave them, one after another switching between them, well it would feel just the same, especially if there's waiting periods, this I/O bit.<br>
So what if we take our various tasks green task, pink task, blue task, and so on and we break them up into little tiny slices and we run them a little bit here, a little bit there.<br>
So here's a task.<br>
Here's another task.<br>
And we find ways to break them up.<br>
And these places where they break up are where we're often waiting on a database calling a web service, talking to the file system doing anything that's an external device or system and we keep going like this.<br>
This type of parallelism uses no threads adds no overhead really, and it still gives a feeling of concurrency, especially if we break these things into little tiny pieces and we would've spent a lot of time waiting anyway.<br>
This is the conceptual view you should have of AsyncIO.<br>
How do we take what would be big, somewhat slow operations and break them into a bunch of little ones and denote these places where we're waiting on something else.<br>
In fact, Python has a keyword to say we're waiting here, we're waiting there we're waiting there, and the keyword is await.<br>
So we're going to be programming two new keywords async and await, and they're going to be based on this I/O driven concurrency model and this you might call cooperative multithreading.<br>
It's up to our code to say, I'm waiting here so you can do, so you can go do something else when I get my callback from the web service please pick up here and keep going.<br>
It's really awesome how it works and it's actually the easiest style of parallelism that you're going to work with.
|
|
|
show
|
9:05 |
It's high time to write some code and much of what we are going to do going forward is to write demos and then think about how they worked how we can change them, what were the key elements there.<br>
Let's begin by actually building a little of foundation.<br>
So, what we're going to do is we're going to talk about using asyncio.<br>
Now, asyncio is quite magical in how it works but actually pretty easy in the programming model that you're going to use.<br>
So, what I want to do is give you a conceptual foundation that's a little easier to understand that doesn't actually have to do with concurrency.<br>
So, we're going to look at this idea of generator functions.<br>
If you're familiar with the yield keyword you'll know what exactly I'm talking about.<br>
So, let's go over to our github repository.<br>
We have 04 section and we have generators and we're going to move on to this producer and consumer thing.<br>
But, let's start with generators.<br>
Now, the first thing I want to do is open this in PyCharm and configure this to have it's own virtual environment.<br>
The generator example won't have external packages but, the other stuff will.<br>
So, let's get that all set up.<br>
We'll come over here and we're going to create a virtual environment.<br>
Now, I have a little command that will run Python3 -m venv and then activate it and then upgrade pip and setuptools.<br>
That all happened.<br>
Okay, so, now we can pip list see are Python has this virtual environment we just created here.<br>
And in Windows, you would type where Python.<br>
Okay, so, we're going to hope this in PyCharm.<br>
So, here's our new virtual environment and we can see that it actually is active.<br>
So, we have our Python that is active here.<br>
So, this is great.<br>
Now what we want to do is we want to write a very simple generator.<br>
Why are we messing with generators?<br>
Why do we care about this at all?<br>
Like, this is not asynchronous stuff.<br>
Generators don't have much to do with asynch programming or threading, or things like that.<br>
Well, this idea of a coroutine or what you might think of as a restartable function is critical to how asyncio works.<br>
And, I think it's a little easier to understand with generators.<br>
So, what we want to do is write a quick function called fib.<br>
And, at first we're going to pass in an integer and it's going to return a list of integers.<br>
We can import that from typing.<br>
So, we're going to take this and we're going to generate that many Fibonacci numbers.<br>
Totally simple.<br>
We're going to write it as a straightforward, non-generator function.<br>
So, I'm going to return a list.<br>
We have to have some numbers.<br>
Put those here.<br>
Those would be our Fibonacci numbers.<br>
And, then we're going to have current and next.<br>
These are going to be 0 and 1.<br>
The algorithm is super simple.<br>
While, a line of numbers.<br>
Say next.<br>
Say it like this, current, next = next and then current + next then numbers.append(current).<br>
We'll return a lot of numbers.<br>
Let's see if I wrote that right.<br>
So, let's print fib of the first ten Fibonacci numbers.<br>
Go over here, I'm going to run this.<br>
And, let's just actually set each one of these are going to be separate code examples so I will mark this directory as a source root.<br>
Doesn't look up above this for other files and we'll go and run this.<br>
1, 1, 2, 3, 5, 8, 13, 21, 32, 55 Perfect, it looks like I managed to implement the Fibonacci numbers, once again.<br>
However, there's some problems here.<br>
Not very realistic.<br>
The Fibonacci sequence is infinite, right?<br>
By passing in this number, we are working with a finite set.<br>
What if we want to work through these numbers and go, I'm looking for the condition where the previous and current Fibonacci numbers excluding 1 and 2, are actually both prime numbers may be greater than 1000.<br>
Who knows.<br>
Something like that.<br>
If you're looking for that situation you don't know how many to ask for.<br>
What if you ask for 10,000.<br>
Well, that didn't work.<br>
Ask for 100,000.<br>
did that work?<br>
I don't know.<br>
Ask for 1,000,000.<br>
What will be better is the consumer of this truly infinite sequence could actually decide when they've had enough.<br>
And, what we can do that with is what's called a generator.<br>
So, I'm going to comment that one out.<br>
Actually, let's duplicate it first.<br>
I'm going to change this.<br>
First we're going to leave it like this here except for we're going to say, no longer returns that.<br>
So, what we're going to do, is we're actually going to go through instead of creating this list, right and, I can just make this true.<br>
Let's actually just make the whole sequence all at once.<br>
It's a little easier.<br>
So, what we're going to do, is this.<br>
Now, we're never going to return numbers.<br>
Instead, what we're going to do is generate a sequence.<br>
And, in Python, there's this really cool concept with this yield keyword of these coroutines.<br>
These generator methods.<br>
The idea is, there are effectively restartable functions.<br>
So, what yield does, it lets you say I want to execute up to some point in a series until I get to one and then I can give it back to whoever asked for it.<br>
They can look at it, work with it and then decide whether this function should keep running.<br>
It's a totally wild idea, but it's entirely easy to write.<br>
So check this out.<br>
We do this, we don't want to print all of them.<br>
So, now, we want to be a little more careful cuz that's an infinite sequence for n in fib(): print(n) And say, this is going to be comma separated there.<br>
Then we'll say, if n > 10,000, break.<br>
Then break and done.<br>
So, now, we have an infinite sequence that we're deciding when we want to stop pulling on it.<br>
Well, let's just run it and see what happens.<br>
Hmm.<br>
If we want one more print in there.<br>
Here we go.<br>
1, 1, 2, 3, 5.<br>
And, incredible, it just went until we decided to stop asking for it.<br>
How does that work?<br>
So, understanding what is happening here is key to understanding how asyncio works.<br>
So, let's set a breakpoint.<br>
Actually, let's set it up here.<br>
Set it right here.<br>
I'm also going to set a breakpoint right there.<br>
On a normal function, what would happen is we would hit this breakpoint.<br>
This line would run and it would of course, go in here and execute all of this and then this code would run.<br>
But, these are restartable functions, these generators.<br>
Just like the async coroutines.<br>
So, let's step through it and see what happens.<br>
Here we are, we first ran to this and that makes perfect sense.<br>
Nothing surprising there.<br>
But, watch this breakpoint on line 14.<br>
If we step over it didn't run.<br>
What we got back is not a sequence but is a generator that we can then iterate.<br>
So, it's not until we start pulling on this generator that it even starts to run.<br>
So, I'm going to step a little bit.<br>
I'm going to be over here in current notice.<br>
0 and 1.<br>
This function is starting up.<br>
It's totally normal.<br>
Now, we're going to yield, which means go back here.<br>
Oh, I need to use the step into.<br>
We're going to step in down here now n is a 1, the second 1 actually.<br>
We go down here and we print it out.<br>
Now, we're going to go back into the function but look where we started.<br>
We started on line 16, not line 13 and the values have kept what they were doing before.<br>
So, I'm just going to run this a few times.<br>
Now if we step in again, again it's back here and it's 3 and 5.<br>
These generator functions are restartable.<br>
They can run to a point and then stop and then resume.<br>
There's no parallelism going here but you could build this cooperative parallelism or concurrency pretty straightforward with just generator functions, actually.<br>
You just need to know how and when to say stop.<br>
So, let's go through just a little bit more until we get to here.<br>
So, now we have n at this point and if we don't no longer loop over we break out of the loop we start pulling on the generator and that basically abandons this continued execution of it.<br>
So, if we step, we're done, that's it.<br>
So, the last time we saw these run they were, you know whatever the last two Fibonacci numbers were.<br>
And then, we just stop pulling on it it stopped doing it's work.<br>
We didn't restart it again and this example is over.<br>
So, of course I'm going to put this in your code.<br>
You can play with it.<br>
There's nothing that hard about the actual written code it's the order and flow of the execution that is really special that you kind of, get a little bit used to.<br>
So, I encourage you to take moment and open this up in PyCharm or something like that that has a decent debugger and just go through the steps a few times and see what's happening.<br>
Once you get comfortable with that we're ready to talk about asyncio.
|
|
|
show
|
3:08 |
Let's begin our exploration of asyncio by looking at this common pattern called a producer, consumer pattern.<br>
The idea is, there's some part of the system that typically runs independently asynchronously, that generates items.<br>
Maybe it receives a request to fulfill a job charge to this credit card, send these emails import this data file, things like that.<br>
There's another part of the system that is also running asynchronously that looks for work to be done, and as the consumer it's going to pick up these jobs that are created by the producer, and start working on them.<br>
I have an extremely simple version of that here.<br>
It doesn't really do anything useful.<br>
So, we have generate data, and we have process data.<br>
And we're just using this list to share to exchange data between these two.<br>
So, let's look at generate data.<br>
It's going to go, and just create the square of whatever number we give it and it's going to store in our list, a tuple.<br>
So that's one thing going in the list that is a tuple the item that was generated, and the time at which that generation happened.<br>
And then it prints out in yellow.<br>
We're using this cool library, called Colorama to do different colored output.<br>
And color, in threading concurrences is super helpful to understand what part is happening where and what order it's all happening in.<br>
We're also flushing everything to make sure there's no delay in the buffer when we print stuff.<br>
As soon as we say print, you see it.<br>
So, to simulate it taking some time to generate some data or do the producer side, we call time.sleep() for between 0.5 and 1.5 seconds.<br>
On the process data side we're going to look for some data if it's not there, this structure doesn't really have a concept of get it, and wait we'll talk more about that later.<br>
But once an item comes in, we just grab it.<br>
In cyan we say we found it, and we also print out and we determine how long, from when it was created till we were able to get to it, and process it.<br>
Because the lower that number, the more concurrency the better we have.<br>
A soon as something is deposited for us to use, and pick up we should immediately get to it.<br>
But this code is synchronous.<br>
We do all the generation, then all the processing.<br>
So the first item is not going to be processed until all the generation is done, in this 20, and 20.<br>
Let's just run it and see what this means.<br>
The app is running, you can see we're generating in yellow.<br>
It's kind of a subdued color in the pycharm terminal but yellowish it's going to come out and cyan for the consumer.<br>
We're waiting for all 20.<br>
There we are.<br>
Now we're starting to process them.<br>
Notice, we were not able to get to the first one until 20 seconds after it was created.<br>
Now, the consumption of these is faster than the production so we were able to catch up somewhat and we got it down to 10 seconds, 10.48 seconds for the best case scenario.<br>
You can see these numbers that we picked up out of there were the ones generated previously.<br>
In the overall time it took to run that was 30, 31-ish seconds.<br>
None of this is great, and we can actually dramatically improve this with asyncio.<br>
Not a little bit, a whole lot.
|
|
|
show
|
5:36 |
You've seen our producer consumer running in synchronous mode.<br>
We generate all the data and then we process all the data.<br>
And of course the first thing happens and then the second because we're not using any concurrent algorithms or techniques here.<br>
Now also notice I have a produce-sync and a produce-async.<br>
Currently these are exactly the same so I'm going to leave you this sync program in source control so you can start from scratch and basically where we're starting from right now if you'd like.<br>
But we're going to convert this what currently is a synchronous program to the async one.<br>
So in the end async program will be, well the async version.<br>
So there's a couple of things we have to do to make our program async.<br>
Syntactically they're simple.<br>
Conceptually there's a lot going on here and we've already talked a lot about that with the event loop and slicing our functions up into little pieces.<br>
We've talked about the generator function and these restartable resumable coroutines.<br>
All of that stuff is going to come in play here.<br>
But the API, pretty straightforward.<br>
So what we need to do is two parts.<br>
Let's start with the execution of these things.<br>
So in order to run asynchronous coroutines we can't just call them like regular functions like right here.<br>
We have to run them in that asyncio loop and that asyncio loop is going to execute on whatever thread or environment that we start it on.<br>
And it's our job to create and run that loop.<br>
So let's go over here and create the loop.<br>
And it's really easy.<br>
All we do is say asyncio and we have to import that at the top.<br>
We say, get_event_loop().<br>
And later we're going to say, loop.run_until_complete().<br>
And we have to pass something in here.<br>
So we're going to talk for just a moment wait just a moment to see what we're going to pass there.<br>
So we're going to create the loop we're going to give it these items to execute and then we're going to have it run until they are completed.<br>
The other thing that we need to do is we need a different data structure.<br>
So right now we're passing this list and we're just this standard Python list and we're asking, hey is there something in there?<br>
And if there is, let me get it otherwise let me sleep.<br>
And we technically could do that again just with the async version.<br>
But it turns out that asyncio has a better way to work with this.<br>
So we can get what's called an asyncio.Queue.<br>
It's like a standard queue.<br>
You put stuff in and it sort of piles up.<br>
You ask for it out it comes out in the order it went in.<br>
First-in, first-out style okay?<br>
The benefit is this one allows us to wait and tell the asyncio loop you can continue doing other work until something comes into this queue and then wake up resume my coroutine, and get it running.<br>
So you'll see that it's going to be really helpful.<br>
Now it looks like somethin's wrong.<br>
It sort of is.<br>
Right here you see this little highlight around data and that's because in the type annotations we've said that this is a list but we just need to type that as an asyncio.Queue and then just adapt the methods here.<br>
Okay so we don't have an append, we have a put.<br>
We don't have a pop, we have a get.<br>
Now we're going to see some interesting things happening here that we're still going to have to deal with but we're going to use this asyncio queue.<br>
So the way it's going to work is we're going to track the execution of these separately.<br>
We're going to kick them off we're going to run all of those and then we want to go down here and say start them and wait until they finish.<br>
So we're going to use another concept to get them started here.<br>
We're going to go to our loop and we'll say create task and we're just going to pass in here.<br>
And we actually call the data with the call the function or the coroutine with the parameters.<br>
But like a generator function it doesn't actually run until you start to pull on it, make it go and that's what create_task is going to do.<br>
So we'll say task1 equals this and we'll do exactly the same for the other except we'll call it task2.<br>
And then we want to wait come down here and run our loop but wait until complete.<br>
Now if you look at what this takes it takes a single future or task.<br>
A single thing that is going to run and then we can wait on it.<br>
Not two, one.<br>
And that's super annoying.<br>
Why that's not a star args and they do what we're about to do automatically for us.<br>
It's okay, so we'll say final_task or full task final_task, and we're going to go to asyncio and say gather and what you do is you give it a list of tasks.<br>
task1, task2, et cetera.<br>
And then we run the final_task to completion.<br>
Alright so this is the execution side of things.<br>
We create the loop up here on line 10, create the loop.<br>
We use a better data structure we kick off a few coroutines and we convert them into a single task that we can then run until complete.<br>
What's interesting is nothing is going to happen until line 21.<br>
If we printed out hey starting this loop, starting this coroutine starting this method, generating data.<br>
None of that is going to actually do anything until we start it here we're going to block and then we'll be done and we'll figure out how long it took.<br>
So this is how we run coroutines but we don't yet have coroutines down here.<br>
So our next task is going to be to convert those into actual asynchronous coroutines rather than standard Python methods.
|
|
|
show
|
7:17 |
We've got the execution of our async loop working and we've created our tasks, we've gathered them up we're waiting to run until complete.<br>
But obviously these are standard old Python methods so what we need to do is adapt these two methods generate_data and process_data so they work.<br>
If we try to run it now I'm not really sure what's going to happen it's got to be some kind of error, let's find out.<br>
Run time warning, stuff is not awaited.<br>
Well they did start but when we tried to generate and when we tried to gather up the data and process it didn't work out so well, did it?<br>
No, it did not.<br>
Yeah, right here it said you know that didn't work, we called it it returned None and this thing said I expect a coroutine not this thing that ran and returned some value.<br>
Let's go and convert this, now there's two things that we have to do to make our method's coroutines, asynchronous coroutines and there's two Python keywords to make this happen.<br>
So what we have to do is we have to mark the method as an async method.<br>
So we say async like this this is a new keyword as of Python 3.5.<br>
So now we have two async methods, and if we run them they do sort of run but notice there's no asynchronous behavior here they're not actually asynchronous, so that's not great.<br>
Because just the fact that we say they're asynchronous you know, Python doesn't decide how to slice them up.<br>
Our job is to take this code here and say I would like to break it into little pieces that can run and the dividing points are where we're waiting.<br>
Well, what are we waiting on here?<br>
So PyCharm helps a little bit and this data structure helps a lot.<br>
So there's two places we're waiting on generate_data we're waiting, clearly on line 33, we're saying time.sleep.<br>
Now you don't want to use time.sleep this puts the whole thread and the entire asyncio loop to sleep.<br>
There's a better way to indicate I'm done for a while I'm just going to sleep, you can keep working so we can use the asyncio's sleep, okay?<br>
Same as time.sleep, but now there's two warnings and what are those warnings?<br>
It is PyCharm saying you have an asynchronous method with two places you could wait you could tell the system to keep running and go do other stuff, but you're not.<br>
So Python has a cool keyword called await and you just put that in front and these are the markers on line 30 and 33 that tells Python to break up the code into little slices.<br>
Come in here, run until you get to this point wait and let other stuff happen here when you're done with that and you have some time come back and do this and then wait until you're done sleeping which is, you know, .5 to 1.5 seconds and then carry on again, okay?<br>
So we've converted this to an async method now we got to do the same thing down here.<br>
So this is async, and this one, what we have to do is for some reason PyCharm doesn't know about the get but if you go here you can see it's an async method.<br>
So that means that we have to await it when you await the item, it's going to block until the return value comes out and the return value is going to be this tuple.<br>
Notice before the await, we had errors here it was saying coroutine does not have get_item.<br>
So when you call a coroutine you have to await it to actually get the value back from it, okay?<br>
Again, we were sleeping down here so this is going to be an asyncio.sleep and now that it's that style we have to await it as well.<br>
So pretty simple, the two steps mark the methods as async required and then once you do that, you can use the await keyword anywhere you would have waited.<br>
You're calling a function that is async.<br>
In this case it's kind of silly, sleep stuff but we're going to do a much better, realistic example when we start talking to web servers and stuff, real soon.<br>
So this is sort of a toy example we're going to get some real work done with async and await in just a moment.<br>
I think we're ready, our times are awaited and they're async and the various places where we get and put data we're awaiting and we have the async methods here let's run this and see what we get.<br>
Notice we don't need time anymore.<br>
Notice a very different behavior, look at this we're generating the item and then we're going to wait on something, waiting for more data to be generated or delivered, so then we can immediately go and process it.<br>
Look at that latency, 0, soon as an item is delivered or almost as soon, we can go and pick it up.<br>
It took 20 seconds instead of 30, that's pretty awesome.<br>
Now we're having 0000 here because the producer is not producing as fast as the consumer can consume.<br>
So let's take this and make one minor change here let's generate one more of those, I call that a task2 that task3, and this one we need to tell it it's expecting more data we're not dealing with cancellation and our other types of signals like that not yet, task3, okay.<br>
So now we should be producing more data than we can consume and that should be even a little more interesting.<br>
Notice the beginning it's kind of similar but now we sometimes process two sometimes we're processing one.<br>
The latencies are still pretty good but like I said, we can't quite keep up, so that's okay let's see what happens at the end.<br>
Yeah, pretty good, so in the beginning we generated a couple had to kind of do a couple double steps to catch up but in the end we were more or less able to keep up after we generated all the data especially when one of them finished and the other was still working.<br>
Really, really cool, even generating twice as much data it took only 22 milliseconds.<br>
I believe that would have been 50, sorry 22 seconds I believe that would have been 50 seconds if we had done that synchronously.<br>
How cool is this?<br>
So all we had to do is to break up these functions into parts where we're waiting on something else we're waiting on putting items into a queue we're waiting on, well, time, but like I said that's a stand-in for database access file access, cache, network, etc.<br>
Okay so we just break them up using this await keyword we didn't have to change our programming model at all that's the most important takeaway here.<br>
We didn't have to, all the sudden start off a thread, use callbacks and other weird completion.<br>
It's exactly the same code that you would normally write except for you have async and you have these await sections.<br>
So the programming model is the standard synchronous model that you know and that's really, really nice and important.<br>
All right, that's a first introduction to asyncio.<br>
We create the loop, we create some tasks based on some coroutines that we're going to call and then we run until they're complete.
|
|
|
show
|
1:17 |
Now that you've seen our asyncio example in action let's look at the anatomy of an async method.<br>
Remember there's two core things we have to do.<br>
We begin by making the method async.<br>
So we have a regular method def method name and so on.<br>
To make it async you just put async in front.<br>
Remember requires Python 3.5 or higher.<br>
And then you're going to await all of the other async calls that you make so anytime within this method if you're going to call it another async method you have await it.<br>
And that tells Python here is a part, a slice of this job and you can partition with other slices of other jobs in the asyncio event loop.<br>
So we know that get is an async method.<br>
Python didn't help us this time very much on this one but if you go to the definition you'll see and also we didn't actually get a tuple back we got a coroutine, so that's a dead giveaway there.<br>
And that's pretty much it.<br>
You don't really have to do much differently at all.<br>
The most important thing is that anytime you can that you use some sort of method that actually supports asynchronous calls.<br>
So if you're talking to a database try to find the driver that supports asynchronous operations and so on.<br>
We're going to talk more about that later as we get farther in the class but the more times you can await stuff the more fine-grain the work will be probably the better.
|
|
|
show
|
1:46 |
Let's take a moment and just appreciate the performance improvements that we got.<br>
And there's two metrics on which I want to measure this.<br>
One is overall time taken for some amount of work to be done and the other is what is the average latency?<br>
How long does it take for the consumer to get the data that the producer produced?<br>
So, here's the synchronous version a subset of it, we generate all the data and then we process all the data.<br>
And you can see the overall time it took was about 30 seconds and the average latency is about 15.<br>
The best we ever got was 10 seconds that was for the very last one that we processed.<br>
And if we did the example where we had two of them, it would be even worse.<br>
So, this is okay, but it's not great.<br>
And we saw that with asyncio we can dramatically improve things.<br>
So over here, we don't have all the work being done in terms of producing and then all the consumption we have them interleaved because there's all these points where the producer's waiting on certain things the consumer's waiting.<br>
So that time can be more productively spent letting the other parts run.<br>
So we're generating some data we're processing it, generating a few more processing a few more, things like that.<br>
Now, this one took a total of 21 seconds that's about 9-10 seconds better.<br>
Good, not rock your world better but certainly an improvement.<br>
But, the latency.<br>
The latency is so much better.<br>
Look at those numbers.<br>
So, it's 8.5 seconds faster and 60 times less latency.<br>
I think that's amazing.<br>
I think this is really, really great and it was, as you saw, super easy to accomplish.<br>
So, anytime you're waiting on I/O files, database, webservice calls things like that, this is really, really a great technique.
|
|
|
show
|
4:42 |
I want to highlight a project that can almost effortlessly make your asynchronous code faster and the project is called uvloop.<br>
So, uvloop is a reimplementation of the asyncio event loop.<br>
And it turns out that the way Python was built that asyncio event loop can be replaced with others.<br>
And so the async and await keyword can run on different implementations of that IO loop.<br>
And this happens to be one of them so it's a quick drop-in replacement for the built-in asyncio event loop.<br>
It's implemented in Cython, and uses libuv.<br>
So Cython is basically Python compiled to native optimized C code and libuv is a lower level library that is an event loop for different languages built in C.<br>
And if you look here, a quick claim here is uvloop makes asyncio 2 to 4 times faster.<br>
So here you can see built-in socket behavior versus over here, that socket one, that's quite a bit faster.<br>
Or protocol versus this protocol it's actually a little hard to figure out what goes where but these are all the native standard behavior speeds and these are if you just do this quick drop in.<br>
So how do we do that?<br>
Well, it's not too hard.<br>
So let me show you a simple little program that I built.<br>
It's a little bit fake, but that's OK.<br>
So it's going to come on here and it has a limit of 250,000 items.<br>
I guess we could make it more obvious like this.<br>
And it's going to use the async event loop and it's going to run, and run, generate generate, and process.<br>
And now what we're doing is we're not doing hardly any sleep.<br>
We are sleeping a tiny, tiny bit but we're just saying "give up our time slice and let something else run but then immediately pick us up, and keep going." And we're doing this 250,000 times.<br>
So what we're doing is, instead of having a few big blocks that we're slicing our work up into like previously I think we had 20 things we produced and 20 things we consumed, and each one had two sort of waiting points, so at most we broke it into 80 slices.<br>
And those little slices were executed over a period of 21 seconds.<br>
Here, we're going to take a quarter million slices executions, twice, actually we're doing this here so maybe 4 times that actually.<br>
So, what is that, a million times 2 so that's a couple million slices running as fast as we can.<br>
And when we have things that fine-grained very, very quick and fine-grained then we start to see the behavior the actual performance of the underlying asyncio event loop itself come into play.<br>
So if you just have a few coarse-grained slices this is like, not required, right?<br>
But if you're breaking things into vere fine-grained bits that run for very short periods of time maybe this technique is going to be helpful for you.<br>
So let's run this real quick.<br>
We have a standard version and a uvloop version and we'll do the uvloop from scratch.<br>
So here you can run it with two times the quarter million actions.<br>
Now we wait, and it takes 8.7 seconds, OK.<br>
So that's how long this one took.<br>
Let's go and do the work to implement our uvloop version.<br>
Now, we're going to have uvloop as a dependency.<br>
And we're going to need to install that here.<br>
I don't think it's installed.<br>
Let's go to our terminal and say pip install uvloop.<br>
Spelling is hard.<br>
OK, that worked.<br>
Now all we have to do is we have to import uvloop and we have to say asyncio.set_event_loop_policy().<br>
Event loop policy.<br>
So basically this is telling asyncio when you create your event loop use UV's event loop implementation.<br>
That's it.<br>
We haven't had to touch our code or anything.<br>
We just have to run that at startup and let's see how things work now.<br>
4.7 seconds.<br>
8.7, 4.7, and all we did is change the underlying implementation.<br>
If this kind of stuff is going to give you a big improvement go ahead and take the dependency on uvloop.<br>
You're probably depending on other packages anyway.<br>
It's really awesome.<br>
Like I said, if you're breaking it up into very coarse-grained things you know, it probably is not worthwhile.<br>
But it's such a easy performance win that if it helps you, you should definitely think about using uvloop.
|
|
|
show
|
1:07 |
So the example you saw before this producer and consumer thing maybe it felt like a toy example, an artificial example.<br>
And you're like, "Well, Michael, you took this latency of average of 15 seconds down to 0.25 seconds made it 60 times better, but it was fake.<br>
It wasn't a real thing and how about we do some real work and actually see if you get anything close to that?" Well, we will, we definitely will.<br>
So it is time to do some real work and the example that I chose is web scraping.<br>
So what we're going to do, we're going to go do some web scraping, make a bunch of HTTP requests against the server download some stuff, run some BeautifulSoup web scraping type queries against it, and get a little bit of data out and then print that out to the console, okay?<br>
We're going to request a bunch of pages and this is a perfect example for asyncio 'cause while we're waiting on one server to respond we can issue another request and another, and another, and another, right?<br>
Within that hundred milliseconds or whatever the response time is we could issue many requests to many of our servers and really just incredibly amplify the speed so that's what up next.
|
|
|
show
|
3:08 |
Let me introduce you to another program that we're going to use here.<br>
This is the web scraping example that I just spoke about and it's going to use a couple of libraries requests and Beautiful Soup, and so I've added a requirements file for it.<br>
Just start by pip installing those requirements which we can do by copying the path like that.<br>
Okay, so we have our code, and this is just where we're going to start from.<br>
We don't have to write anything but I want to walk you through it so you see what it is we're doing when we get to the async stuff.<br>
So there's a couple methods up here, get_HTML and get_title.<br>
Now the get_title is purely in memory CPU bound sort of thing.<br>
It's going to use Beautiful Soup which is a library that understands the HTML DOM in memory on the client side like here, and it's going to let you do queries against it that are basically like CSS queries.<br>
So we're going to say give me the header and either we're going to get missing or it'll give us the text cleaned up out of the header.<br>
This get_HTML is more interesting.<br>
We're going to give it an episode number so we're going to go to my podcast talkpython.fm and it's going to use this like short, little URL here this shortcut, talkpython.fm/<some episode number> and it will go and redirect us to the right place follow that redirect, and then get that data.<br>
So we're just going to use requests, do a get on the URL.<br>
We're going to verify that that worked and then we're going to return just the text and if we look down here, we're going to say get_title.<br>
So what it's going to do is go from episode 150 to 160.<br>
It's going to first get the HTML, and then it's going to get the title, and then it's going to print.<br>
Now of course this is all serial code, right?<br>
This is in order, so when we run this don't expect any speedups, but you should see it working.<br>
So here it is, it's getting the HTML for episode 150 then it's getting the title, and it found that it's Technical Lessons Learned from Pythonic Refactoring then 151, and then Gradual Typing for Production Applications, and so on and we're finally eventually done.<br>
Let me just run it one more time without me around and just watch how long it takes get a sense for the speed here.<br>
It's doing one.<br>
It's waiting on the server to respond.<br>
It's getting a response back.<br>
It's not terribly slow.<br>
My website's pretty fast, but it's not that fast and of course, I'm on the West Coast of the United States the server is on the East Coast.<br>
There's a long ping time just to go from west to east back, about a 100 milliseconds, I'm guessing.<br>
There's a lot of places for improvement here.<br>
That's what we're going to work with and our job is going to be to take this program apply asyncio to the places where we're waiting namely that line right there you're doing lots of waiting there and make this go much, much, faster.<br>
And it turns out, the algorithm that we have here won't actually make it go faster, at least for this particular application.<br>
If we had a bunch of different attempts running parallel it's a really straightforward transition but there's one more thing to be learned to make this actually go faster in pure performance.
|
|
|
show
|
9:16 |
Now we're in our asyncronous program but notice it's still using requests and it's still doing the synchronous version.<br>
Our job, our goal, during the next few section is to convert this over to an async version that works much, much better.<br>
Now, in order for us to actually write async code that does anything interesting we need to use a library that supports asyncio, that has async methods and coroutines that we can actually await.<br>
So we're not using a requests we're going to switch over to this thing called aiohttp.<br>
Now, this is both a server and a client it does web sockets and all sorts of stuff.<br>
What we care about is this client thing.<br>
So we're going to use this to very simply convert our requests code over to asyncio.<br>
So let's get started.<br>
So instead of using a requests we're going to use aiohttp, and we're going to need to install some new requirements.<br>
So we don't need requests anymore and we're going to use aiohttp.<br>
That's the main library but there's actually two other libraries that will make this even faster.<br>
So aiohttp has to do DNS lookups and other things so there's actually an aiodns, and a cchardet.<br>
These two are going to be a little bit better.<br>
So, we're going to copy that path and install those requirements.<br>
With the requirements in place now we can start writing our code.<br>
We actually don't have to change very much.<br>
This line right here, I'll comment it out for a second so we still have it that's the line we have to change.<br>
Now, I'm going to introduce you to a new bit of syntax that is a little bit funky.<br>
We've seen how to make this method async.<br>
We say, async, right?<br>
And you might think, I would just write, await but it turns out aiohttp client runs in a context manager.<br>
Otherwise known as a with block.<br>
And the with block itself has to do asyncronous stuff.<br>
So, Python has been extended to have what are called asyncronous with blocks or asyncronous context managers.<br>
So what we're going to write is async with aiohttp.clientsession, and then within the session we're going to make a request so we have another with block we're going to get the URL as the response and then it's pretty similar to what requests has.<br>
We do this, and we do that.<br>
Now, this text here, if we look at it it's an asyncronous function.<br>
So, first of all, it wasn't a function in requests it is here, but it's also async so we have to await it.<br>
This line right here is probably the most important one.<br>
This one and this one, these are the two most important ones here for what we're trying to do.<br>
So we take this one line, and yeah it gets a little more complicated but trust me, the benefit is huge.<br>
All right, so let's go make this run.<br>
So if I just try to run it down here notice this is not going to work so much.<br>
So this is actually returning a coroutine not a string, and when we try to pass that where a string is expected, it goes whoa whoa whoa.<br>
Not great.<br>
So, how do we do this?<br>
Actually, sorry, I don't want to run it here.<br>
Let's go up here and do it in main.<br>
Then over here, I'll just say loop.run_until_complete and we're going to give it this which means we're going to make this async as well then this gets pretty simple.<br>
All we have to do is await.<br>
Now, this is going to absolutely run it's going to do it asyncronously I think everything is going to be perfect.<br>
But it turns out, there's one little problem that we're going to run into.<br>
But, let's just run to see that it still works at least the way it did before.<br>
So, we're going to run the program.<br>
It's working, you can see the titles are correct, understanding and using Python's AST How Python evolves, etc, etc.<br>
But, did you notice a difference in speed?<br>
Did you see things happening concurrently?<br>
No.<br>
Let's look at that.<br>
That's a little bit weird here.<br>
So, if we look at the main part we're running this function so let's go look at the get_title_range.<br>
And I'm going to make a copy of this so you can see how it was I'll call this version one this will be the old version let's call it old version.<br>
This is the real one.<br>
So what happens when we run this is we go through here and each time we block and stop before we do anything else and then we get the title and go on.<br>
So, yeah, there's this event loop but we're only doing one thing at a time.<br>
What we need to do is start all the requests and then then go process the responses as they come in.<br>
So we need to make a tiny little change here.<br>
Let's call this tasks equals this and we're going to kick them all off so we're going to say, we're going to append now I want to store basically this.<br>
So I'd love to just store this response here that we get back, however this coroutine that's been started, however this is not actually going to start it.<br>
Remember, these are like generators you have to trigger them to go.<br>
So, what I can do over here is I can say asyncio, I create_task of that I also need when I print this out I need to pass the number and the HTML so I'm going to need that later.<br>
So let's also pass the number as a tuple so we're passing one thing to our list which is actually this tuple right here.<br>
So what our goal is, is to start all the tasks and then for each one of them we then want to do the other work.<br>
So we'll say the HTML is await t and then we're going to put it in there.<br>
So we start all the task, they're running and then we're going to either just get their value right back or we're going to now block and wait for that response to come in and then get the next task maybe it's already done, we'll get it's response right away and we got to wait on the next one so the key thing here is instead of trying to do one at a time, we're going to start them all and then process them all.<br>
Now, if you were asking for hundreds or thousands of pages, you might want to somehow rate limit this so that the tasks don't get too out of control but if we're only doing 10, it's not too bad.<br>
Are you ready for the grand finale?<br>
For the big moment, to see if we actually got our code one, working, and two, faster?<br>
I think we have, let's try.<br>
Look at that.<br>
Man, that is just awesome.<br>
I did nothing to speed that up.<br>
I didn't edit the video at all.<br>
Let me run it one more time.<br>
That is so awesome, let me run it one more time.<br>
Start.<br>
Done.<br>
Bam.<br>
Notice, we started all of the requests and then as they came in, we started to process them.<br>
The way in which we processed them was the order we started them and it's probably not the order they actually finished.<br>
But that doesn't matter because all the latency around the ping time you know we're making 10 requests over to the server that's a whole second right there just waiting on the internet.<br>
Well, we can do all those requests and get them all started and really just incur probably more or less the ping time of one for this particular server.<br>
Maybe 100 milliseconds, not 1,000 which is really, really great.<br>
And then of course, all the concurrent processing that the server's doing as well.<br>
So really, really awesome and that's how we were able to use asyncio and a library that can do web requests that itself supports asyncio to dramatically increase the speed.<br>
While we're on the subject of aiohttp let me just tell you a really, really quick story to drive this point home of how useful this library and this technique can be.<br>
We talked about this on my other podcast Python Bytes, and there was a listener he knows I share this story every now and then and it's pretty fun.<br>
So, he had some project where he was requesting a whole bunch of pages and he was using requests, and it was taking hours or something like that.<br>
He switched to this technique where he's using aiohttp and async and await and things like that, it went so fast that it actually crashed his server because the server ran out of memory trying to process all the requests it was getting back all at once.<br>
So, I think that's awesome.<br>
It goes from hours to less than a minute and so much data you actually have to think about the performance of receiving that much data at a time because you're adding so much concurrency to the system.<br>
And how hard was it?<br>
Well, yeah, this was like four lines instead of two maybe instead of three?<br>
So, not too bad at all.<br>
The real key to the technique is to make sure you start all of the work and then start to process the responses.<br>
'Cause we saw in our first version our old version, that we got actually zero speed up from that.<br>
Just a little bit of added complexity for no real benefit.<br>
So here's doing some real work with asyncio and async and await.
|
|
|
show
|
1:24 |
We've seen just how powerful asynchronous web requests can be.<br>
After all, what are you doing when you're making a web request?<br>
You're waiting on the server.<br>
So, you can wait on a whole lot of servers all at the same time, and get a ton done concurrently.<br>
So, let's review some of the concepts around it.<br>
Well, of course, we're going to have an asynchronous method this get_HTML method.<br>
If it's not async, we can't do this.<br>
But assuming we're within an asynchronous method what we need to do is we're going to need to find these async with blocks for the aiohttp library.<br>
So, we're going to create a client session and then from that session we're going to asynchronously do a get request that'll give us a response.<br>
That one's the one that probably takes the longest.<br>
Want to do this raise_for_status just to make sure that we got to 200 or some form of success code.<br>
And, by the way, that does not come up in PyCharm when you say resp.raise_for_status() doesn't come up but it is there and it works.<br>
And then finally, we want to read the content from the network stream.<br>
So not just start the response but actually get all the content back.<br>
So, we'll say resp.text and that's also a coroutine so we're going to await it as well.<br>
Convert it from a coroutine into a string and send that back.<br>
So, here's how we do asynchronous web processing web request, with aiohttp and asyncio.
|
|
|
show
|
3:41 |
It's critical that the libraries we're using to talk to the various external systems support asyncio if we want to take advantage of them at all in some sort of asyncio system.<br>
We might be able to use them in threading or other situations if they don't but to use them with asyncio, they need to have asynchronous methods that we can call.<br>
So to give you a sense of how this works and how you find these libraries and so on we're going to go through four libraries that talk to common, mainstream, external systems MongoDB, Postgres, file systems, and Redis.<br>
Of course, you may want to talk to something else and that's totally fine.<br>
This is more to inspire you to say there's probably some kind of asyncio-enabled library for the thing that you're working with.<br>
Now, if there's not, we'll talk later about how to mix and match these things when we get to unsync and other stuff much further in the course.<br>
But, for now, we're going to just talk about these libraries that enable asyncio for these four systems.<br>
Now, we're not going to do any demos here so I'm just going to show you the github repos.<br>
So the first one, file IO.<br>
If I say with open, that's the standard way to open a text file or a binary file in Python.<br>
I might also do like a JSON read when I give it like the filestream that came with open.<br>
None of that stuff supports asyncio.<br>
It's ironic, right?<br>
We're doing file IO in Python that does not support asynchronous IO.<br>
Anyway, that's a whole side discussion.<br>
So here is one project that you could use aiofiles.<br>
So it basically just has the ability to open files and read and write from them asynchronously.<br>
And these are async methods you call and you can await them and use them properly within your async methods.<br>
This is probably not the only one for Python but it's an example.<br>
If you need it, go have a look.<br>
MongoDB, very popular NoSQL database.<br>
Its primary way to talk to it from MongoDB doesn't support asyncio, meaning the popular ODMs Object Document Mappers don't support asyncio.<br>
However, here's a pretty cool one called umongo.<br>
umongo, it's supposed to be a mu, a Greek mu at the beginning, even though it's a u.<br>
So umongo has both synchronous and asynchronous support for MongoDB.<br>
It's really cool, it actually has a bunch of different subsystems you can swap in and out like Twisted versus asyncio, but not getting into that here is cool library that you can use if you want to talk to MongoDB map classes to and from it, and you want to do that using async and await.<br>
Don't like MongoDB?<br>
Postgres is probably the other most popular database choice for Python developers, and if you want to talk to it asynchronously you need asyncpg not the standard one that doesn't support asyncio.<br>
You can check out asyncpg.<br>
It's very popular, and of course, lets you use Postgres in async and await.<br>
Finally, our final example here is going to be Redis.<br>
If you want to talk to Redis, this is primarily used as an in-memory cache, but also can be used for, like, queuing systems and things like that.<br>
Redis is quite popular in the Python space.<br>
If you want to read and write objects from it connect to it asynchronously, well, asyncio-redis is one of the ways you can do that.<br>
So like I said, this is not an exhaustive list by any means.<br>
It's just an example, a tour to inspire you that hey, if there's a thing I'm working with there's a good chance that somewhere out there there's an asyncio library for it.<br>
And if there is, that's awesome, because then you can go and plug that into your code and you've seen how much scalability and parallelism you can get by doing stuff while you're waiting on external systems like Redis, or MongoDB, or even the file system.
|
|
|
|
32:24 |
|
|
show
|
1:07 |
Threads have been around and available in Python for a long time and using threads for parallel programming is certainly one of the main ways in which we can add concurrency to our Python programs.<br>
Let's quickly look at our landscape here.<br>
So we're over in this green threads box and that generally puts us in the do more at once.<br>
So threads are very similar to AsyncIO in that sense.<br>
Because of the Python GIL, the Global Interpreter Lock that we spoke about in the Introduction to Async Programming in Python chapter threads don't really let us leverage the multiple cores to do actual concurrent CPU-bound operations.<br>
Some languages they do, in Python they don't.<br>
That puts thread concept squarely in the do more once category in our little landscape here.<br>
So we're going to focus on threads this is, like I said, it's been around for a long time so many different systems are built taking advantage of threads.<br>
And there's still many good use cases for them and certainly understanding how they work and how to use them in Python is critical to having a well-rounded, asynchronous programming tool set.
|
|
|
show
|
1:12 |
It's always good to have a picture of what's going on in our code, in our programs as they run.<br>
Here's a picture that I drew trying to simulate that, or visualize that for you in Python.<br>
So, this big box is our process and the process itself can kickoff different threads.<br>
And those are the little gray arrows.<br>
The ..., that's just waiting.<br>
We have our main program is running and then at some point it kicks off two additional threads does a little more work then waits for the two threads to finish and then carries on working.<br>
So, this fork-join pattern, kick a bunch of work off wait for it to finish, and then carry on is very common in threaded programing.<br>
And it's important to realize these threads are all in the same process.<br>
They all work on the same memory.<br>
So, if I have a variable or a data structure in Python which is always the pointer pointers are shared data structures per process in the global memory heap.<br>
If I have one of those, and different threads are working with it, it's the exact same object.<br>
So we'll have to see, you're going to have to be kind of careful with your data structures and the state of your program.<br>
When you're doing programing with threads in Python.<br>
So, here's a picture to keep in mind to help you visualize typically what's happening with our threads in Python.
|
|
|
show
|
2:33 |
Before we get into the actual programming with threads I want to take a little step back and help you decide which way to go between threads and AsyncIO.<br>
We've seen in that landscape section that they live in the same area.<br>
They're in the do more at once while you're waiting on other things rather than leverage the computational aspects of, say, your CPU cores.<br>
In some sense they kind of do the same thing.<br>
I'll tell you I think the AsyncIO programming model is actually nicer, it's cleaner.<br>
It's basically the synchronous regular programming model with just understanding these restartable coroutines.<br>
But once you get that idea it's a lot easier to do AsyncIO programming than it is to do threaded programming.<br>
So why are we talking about threads?<br>
Like, why would you even care about them?<br>
They're old school, get 'em out of here, we're done.<br>
Well, not so fast.<br>
We saw that you can only take advantage of AsyncIO if you have libraries that themselves are built for AsyncIO.<br>
Most libraries out there are not.<br>
Sometimes you'll get lucky and you'll find some system some library that you can talk to asynchronously with async and await, but much of the time you won't.<br>
There won't be anything available that you can use but you still want to take advantage of the concurrency.<br>
When we spoke about the GIL we said threads are no good for concurrency when you're trying to leverage CPU bound operations in the Python steps themselves.<br>
And that's because the GIL will only let you execute one operation at at time.<br>
One of the really important caveats around that is if you call a function that itself is, say going over the network or talking to the file system deep down in the implementation Python will let go of the GIL while it's waiting on that IO operation.<br>
So imagine I have, let's say, SQLAlchemy Code.<br>
I have no idea if SQLAlchemy is thread safe if this is a good idea, but it's just an example.<br>
So, suppose I have SQLAlchemy which is an ORM that talks to the database.<br>
Doesn't really have a great AsyncIO story.<br>
It does talk to the database so I could run these queries on multiple threads as we're waiting on the network.<br>
It's going to release the GIL and let it keep going.<br>
So we actually could add this AsyncIO type of programming to systems that don't have it.<br>
So here's the take away.<br>
AsyncIO when you can, threads when you must, all right?<br>
If you can use AsyncIO.<br>
Obviously it's a nice, cleaner way to do it in my opinion.<br>
But a lot of times it's not available.<br>
Threads are there to basically do the same thing.<br>
You just have to construct it a little more yourself.<br>
Hope that helps.<br>
Now, let's learn the threaded programming model.
|
|
|
show
|
4:59 |
Time to write some code about threads isn't it?<br>
Alright, here we have our demo code.<br>
This is in the GitHub repository under Chapter 5 threads we have basic threads, CPU attempt which we're going to get to these two shortly but right now I just want to focus on sort of the Hello World thread stuff.<br>
What are the basics of threads?<br>
How do we create them, how do they work?<br>
What are some of their little non-obvious nuances that we need to understand?<br>
And then we'll go build a real program with them.<br>
Here you can see a program called Hello let's go ahead and run that.<br>
It's underwhelming isn't it?<br>
Didn't do too much.<br>
It did run, but then it just passed.<br>
So let's go and do some interesting things.<br>
Let's have a method here, say def greeter.<br>
I want to pass in name, it's going to be a string and the greeter, also let's pass in a times.<br>
And that could be an integer.<br>
So we're going to pass in a name and a number times to do the greeting.<br>
So we'll just print out something like hello there whatever your name is.<br>
And then we're going to do this that many times.<br>
And we'll go over here and call the greeter and let's say Michael.<br>
Let's do it 100 times.<br>
Well that's interesting but let's make it go slower.<br>
Each time we're going to make it wait so we can say time.sleep().<br>
This will actually put the main thread to sleep if it were another thread it would put that thread to sleep as well and we'll release the GIL which is pretty awesome.<br>
Let's see if we can do this once per second.<br>
So this should take a little over a minute and a half.<br>
There it goes.<br>
What do you think, shall we just watch it?<br>
No of course, that's going to be boring.<br>
There's nothing to do with threads here anyway is there?<br>
So let's start bringing threads into action here.<br>
So the first thing I'm going to do is I'm going to say import threading and keep it nice and explicit like I do even for my production code.<br>
I like to use the module name the namespace style of programming here.<br>
So what we're going to do is we're going to create a thread call it just t.<br>
I'm going to create threading.thread.<br>
What we're going to do is set the target.<br>
The target is going to be the function, not calling it but just the function name.<br>
And then we're going to pass the args which are arguments as a tuple and you know we can sort of just decompose this really easily and just put that there.<br>
Now if I run this it's not going to be so super interesting.<br>
Let's do a little print done here.<br>
What happened to our greeter?<br>
Didn't it say anything?<br>
No, no no no it did not.<br>
Just because we created the thread doesn't mean it's running.<br>
We have to say t.start().<br>
There, wait a minute.<br>
It was done and now it's still working.<br>
That's weird.<br>
Here's the deal.<br>
Our program, our main method, exited but somehow this other thread is still running.<br>
It's still, you can see it's still goin' on down here doing it's thing.<br>
I'll finally stop it.<br>
That's because by default, threads in Python are what you would call foreground threads.<br>
If any of those are running even if your main thread that started your program stops or exits, it's going to keep on running.<br>
If you want this just to run in the background if your program exits then the threads get canceled then what we got to do is go here and say this is a daemon thread.<br>
Now we'll get a slightly different behavior.<br>
Hello, nope, we're done.<br>
Oh, okay well, interesting, there it goes.<br>
That wasn't really what you were hoping for maybe maybe it was.<br>
So we started our thread but somehow we need to do some other work.<br>
We could say print, this is other work.<br>
Like for example I could do math.<br>
I could tell you what two times two is.<br>
And then maybe after this point we don't have any more work to do but we want to make sure the thread still gets to finish its work and just so we don't go insane let's make that 10 okay?<br>
10 Michaels and we'll be good.<br>
And we could even do an in here.<br>
And print that out so we can keep track of where we are.<br>
Okay so then down here if we say we don't want to exit we'll say t.wait, no, join.<br>
So remember I spoke about this fork-join pattern the nomenclature here comes from fork-join.<br>
I would prefer wait and you'll see in other things in the threading world that we're going to get to wait is sort of the newer style but, anyway.<br>
Join it is, let's go.<br>
So we got this Hello.<br>
This is other work for, so remember computing for was our other work and now we're doing the other things.<br>
This is a zero-based loop, a computer loop not a human loop.<br>
So we get this out here.<br>
So we sort of kicked off some work, this is other work and this is our main thread our background thread is still working and then when it's finally done this line releases.<br>
And when it releases after it's done 'cause the thread stopped running we print our little final done and exit.<br>
So now our main method won't actually exit until the thread is done.<br>
If it does because it's a daemon that background thread and background work will be immediately aborted.
|
|
|
show
|
3:52 |
There's a couple of things that are interesting here that we might want to dig in deeper really quickly before we get to a real project.<br>
One is how do we work with say multiple threads?<br>
So let's go down here and rename this to t1.<br>
And then we'll have another one, t2.<br>
And this is going to be Sarah, and this will be five.<br>
And we're going to start both of those and we're going to wait for them both to finish and then we're going to be done.<br>
This is sub optimal but just hang with me for a minute.<br>
It's part of a journey.<br>
Alright look here we go.<br>
Hello Michael, Sarah is in the work.<br>
Hello, print, print, you can see the print is actually somehow even not getting the new line in there sometimes, that's pretty cool.<br>
So Michael actually had more but here Sarah, Michael, Sarah, Michael.<br>
Pretty cool.<br>
So you can see that the, more time to sleep.<br>
We're actually giving up our time slice to let the other thread run.<br>
That's pretty cool already.<br>
So here's how we could do this.<br>
What if we had 10 things we wanted to do?<br>
What if we had arbitrary many?<br>
Not so great.<br>
So let's do it like this and let's say all of our threads are going to be in here, just put them into a list, okay.<br>
This will be much nicer.<br>
Put them in a list, and then we can do a little list comprehension, t.start() for t in threads.<br>
And down here, similarly t.join().<br>
What do we get when we run those two comprehensions?<br>
A bunch of Nones probably but it doesn't matter.<br>
The fact is we're taking the return by here which like I said is probably None and just put it into a list but as part of going to that list to generate it we're of course waiting.<br>
So now this will do exactly what we had before and it lets us have even more of these.<br>
Sorry Mark, 2, 11 obviously some commas in there.<br>
Everything's going to go there they go.<br>
A bunch of stuff is happening.<br>
They're all cranking out answers.<br>
Pretty soon we're going to be done.<br>
But notice we're waiting for all of 'em.<br>
We've started them all.<br>
We're down here on line 18 waiting and now we're done.<br>
Okay so this is a real nice pattern here.<br>
This create a list of threads.<br>
Used a list comprehension to start them a list comprehension to wait on them and so on.<br>
The final thing I guess worth looking at here would be to say, come over here we could set a timeout.<br>
So we're waiting right now forever and let's say we're only willing to wait 5 seconds.<br>
So maybe Sarah will be done.<br>
Maybe Zoe, definitely Zoe will be done but Michael and Mark, they won't be.<br>
So let's say timeout is 5 seconds.<br>
It went through all of them because it first waited for that one which is 5 and then it waited on that one and that one.<br>
Alright so let's make that, 'cause we're waiting on a bunch to make that a little bit small and let's make it 1.<br>
So now we're waiting for 4 seconds I guess total probably.<br>
Here you go.<br>
So you can see we got through basically 3 sorry 4 reps that are based of all of them and then we just baled out.<br>
So you may want to use that.<br>
We're going to use that for good use in our little program we're going to build in a moment.<br>
Alright, so here's some cool techniques.<br>
I guess I'll leave the timeout there for you just in your code sample.<br>
Good technique, you want to spin up a bunch of threads.<br>
You want to start them, do the work potentially and wait on them.<br>
You can use a list and list comprehensions to make this a lot cleaner in Python.
|
|
|
show
|
3:10 |
Let's return to an old friend the producer consumer that we learned about in the asyncio chapter.<br>
So here we have the single threaded non-concurrent producer consumer thing that we've been playing with in the previous chapter.<br>
So we're going to generate a bunch of data and we're going to generate some more data then we're going to process it.<br>
Now if we run it, remember it generates some data the first time through and then it does it again, and so on.<br>
However, we saw that using asyncio let us really speed this up.<br>
Let's assume for some reason that we don't have asyncio available to us.<br>
Now what we're actually doing when we do and we've already implemented it and you've seen that but assuming that we don't, how would we model this with threads?<br>
A lot of the reasons I gave you before that might be the case here.<br>
Maybe we're interacting with some system here that we're waiting on, but it doesn't actually have an asyncio option for us.<br>
So we're going to do what we just talked about and we're going to have the threads that we're going to work with.<br>
I'm going to go in here and I'm going to create some threads need to import threading, set the target to generate_data, and set the args to be what they're going to be, so 20 and data and I guess if you want to use data you should probably define it above.<br>
That all looks good, and are doing that again and then the other one, we're using process_data and we're using 40.<br>
So that's going to get rid of those.<br>
Now again, this doesn't start them.<br>
So if we ran this now, it would be super fast zero milliseconds, zero seconds at least.<br>
However, it didn't do any work.<br>
So what we want to do is use our little trick t.start() for t in threads, and then we want to print started, somethin' like that and then we'll do join.<br>
Alright, so this, that should really be all there was to it, and let's try.<br>
Now this assumes of course that process_data will go through and it has this sort of continue step to know how much it's supposed to process.<br>
There's a little bit of work to make sure this works but it was already in place, and so we should be able to just run this now.<br>
There they go, see them producing and consuming in parallel.<br>
Perfect, right?<br>
Looks just like the asyncio version that we were working with, except for apparently we can't pop from an empty list let's see what we did there.<br>
Ah yes, alright, let's fix this.<br>
Alright, so that should work sorry about that, try again.<br>
See, threading will pull out interesting errors you did not think were there.<br>
Here you can see it's done, the latency's a little bit higher than we were looking at previously.<br>
The overall execution time is about the same as our asyncio version.<br>
Pretty straightforward right?<br>
We just use our technique, create a whole bunch of threads start them, maybe do other work maybe just chill, and then wait for them to finish by joining on all of them.
|
|
|
show
|
1:41 |
Let's review the basic API of working with threads starting and waiting for it to finish.<br>
So of course, we're going to use the threading module.<br>
This is built into CPython, you don't have to do anything.<br>
There's no external dependencies.<br>
It's just part of Python, that's great.<br>
So then, we have some function this is regular synchronous code that lives in here.<br>
This is the code that's going to run on our other thread.<br>
We're going to call this function and then execute it somewhere else and potentially wait on it.<br>
So then we're going to create the thread so create the thread object set the target to the method name the args to a tuple of arguments.<br>
Notice above it takes a number, which is an integer and an input, which is a list so we're going to pass 20 and just an empty list.<br>
And then we want to set the damon mode to be true.<br>
That means if our main method exits for some reason our process won't be become this zombie thing that's still running even though it appears to be exited, right?<br>
It'll actually abort that, generate_data method and just shut down the whole process if our main thread exits.<br>
Then we have to start it, right?<br>
Creating the thread isn't enough to make it do anything.<br>
You have to start it afterwards.<br>
Potentially we can do other work now, theoretically right?<br>
It's possible that the threads will be doing other stuff.<br>
Again, remember the GIL, so its computational then it doesn't help all that much, right?<br>
But there are plenty of reasons where it will work like talking to external systems, using networks files and so on.<br>
And then finally, were just going to wait for completion.<br>
So instead of letting our program exit and abort the thread we say work.join and we saw that we can give it a time out if we like but we don't have to.<br>
Alright, so this is the overall basic API of working with threads in Python.
|
|
|
show
|
0:41 |
We saw a few nice little techniques for working with sets of threads more than one thread at a time.<br>
So let's suppose that we're going to create three threads and we want to work with them as a set.<br>
Basically we want to spin those three off and then we're going to start them and then wait for them all to finish.<br>
So we did that in our producer consumer example while having a list of threads and we create them all and just in line like this.<br>
We could do it in a loop.<br>
Append if you wanted.<br>
But in this case we didn't need to do that.<br>
Next we're going to start them all using this cool little list comprehension.<br>
t.start() for t in threads.<br>
Potentially do some other work and then wait for them to finish.<br>
So t.join() for t in threads.<br>
Pretty simple right.
|
|
|
show
|
6:02 |
Let's add one nice little trick or nice little feature to our program here.<br>
Notice it's doing all this work, but maybe I'm done I've seen enough, we can get out of here.<br>
I'd like to somehow cancel.<br>
Well, I can somehow, Ctrl + C my way out eventually.<br>
Well, not really right?<br>
Even that doesn't work.<br>
Like, that's not the best.<br>
You know, Python consists of this little like skull cross bones thing, til we're actually finished.<br>
That was super annoying.<br>
Wouldn't it be nice if there was a better way?<br>
Well, if we had set these to be daemons at least the keyboard interrupt would've taken it out.<br>
But still, maybe we want something a little bit nicer.<br>
Instead of saying started let's actually use our Colorama here.<br>
We can come out here and say something like press enter to cancel And you might think, well you can just do input.<br>
Like this, with nothing.<br>
And technically that will block this, but how do we know.<br>
We don't have to ask this anymore.<br>
You can't just ask have they pressed a key super easily in Python.<br>
There are some ways, but it's really sketchy.<br>
So let me show you one other way that actually is much easier.<br>
Instead of doing this, what I'd like to do is somehow ask this question, hey are any of these threads done?<br>
or rather all of the threads done?<br>
And if they are then we're just going to exit but if they're not, let's give people a chance to exit.<br>
By pressing Enter in the middle in a nice, clean way.<br>
Okay, so how are we going to go about that?<br>
So, this input, like I said there are ways in Python to read whether there's input but it's quite tricky.<br>
We can just add one more thread and ask that question.<br>
You know, what is the input over here?<br>
So let's do this.<br>
We'll create something called the abort_thread.<br>
Going to say threading.thread.<br>
And it's target, is going to be check_cancel.<br>
And its daemon mode is going to be True as well.<br>
So we need this function and we'll put it below.<br>
It's going to be incredibly simple.<br>
Watch this.<br>
check_cancel.<br>
Input.<br>
Actually let's put this down there.<br>
So here, we're going to run a thread and that thread is just going to see if you press Enter.<br>
If you press Enter, that thread exits.<br>
If you don't press Enter, that thread doesn't exit.<br>
But when we get to the end, because it's a daemon thread it'll be canceled, alright?<br>
Here's what we're going to do.<br>
Going to come over here, and we're going to say while any of these, t.is_alive().<br>
So we can ask the thread, are you alive?<br>
And if any of the threads come back and say yes, we're alive, then we want to wait a little bit.<br>
So let's wait, I don't know, five milliseconds.<br>
Could even make it shorter, right?<br>
Actually waiting this little bit doesn't matter, right?<br>
So we've got three threads, we'll wait three milliseconds.<br>
Just ask the question again Are these three threads alive?<br>
So you decide what number goes here, but it should be probably pretty small.<br>
And then after this we want to check is the cancel thread alive?<br>
We'll say if not, the abort_thread is alive.<br>
That's it.<br>
Under Print, canceling on your request.<br>
And that's it.<br>
We're going to stop joining the threads.<br>
If any of them happen to still be alive we're going to print out something and if they are still alive after that, main thread Exits it aborts all of them because they're daemon threads.<br>
Okay, phew, let's see if this works.<br>
Oh, do you know why it's not alive?<br>
We may have missed a little bitty important step Is it alive?<br>
No it's not alive.<br>
Why is it not alive?<br>
It's not alive 'cause we have not started it.<br>
Now let's try.<br>
Alright, so it's press Enter to cancel and now it's working If I come down here, say follow along.<br>
Boom.<br>
Cancel entering request, done.<br>
Right away.<br>
Won't have to hit a weird Ctrl + C, wonder what happened We got to even print out the apps exiting.<br>
Here's your final report.<br>
We spent 7.8 seconds.<br>
Do it again.<br>
I hit enter real quick, canceled right away.<br>
Of course if I just let it run, well, it'll take a moment 41 seconds or so for this to finish.<br>
That's enough time for us to go review what we did.<br>
It's a little bit of a hack, but if you want to be able to ask the user or give them an option to cancel this fork join work well, we can create another thread whose sole purpose is to look for user input assuming you're not getting it from other places at this point.<br>
And if it gets input, then it exits you know, it can even actually capture a value and then give that value back if you really want it to we just don't care at this point.<br>
So we're going to use the any operation on any of the threads alive.<br>
We're going to use the timeout feature, on join and then just give a really short timeout to say let's just check really quick wait, give them a little time to run and then if our question thread, do you want to exit is still running then we're not going to cancel.<br>
But if it is, we'll just cancel and get out.<br>
Maybe we want to do this in a different order?<br>
I don't know.<br>
There's a tiny bit of race condition about potentially saying we canceled it just at the moment that it didn't cancel but, you know, that's threading.<br>
It's tricky, and we're just going to leave it at this.<br>
But, here's a way in which we can use timeout, and input but it could've been a signal from another service could've been our web service called and told our threads.<br>
There's all sorts of operations that we could use to trigger the canceling of these threads.<br>
Cool little pattern there to make our threaded example even better.<br>
Oh, and let's see what our outcome was.<br>
Look at that, it ran all the way to the end.<br>
It got to 400 twice, like it should.<br>
And then it printed that it was done after about 20 seconds which is exactly what we expected.<br>
So here is the case where we did not cancel it.
|
|
|
show
|
1:21 |
Let's quickly review this timeout operation that we did.<br>
So here we have some threads and we've started all the threads.<br>
What we'd like to do is, if we get some kind of signal and like I said, this can be many, many different things.<br>
A Boolean variable should exit is set to true or a value set in the database or you've received an email I don't know, it could be anything.<br>
I want to let these threads run until I get that message and then I'm going to bail out of them.<br>
So far we've been able to make them stop by basically just letting our process exit.<br>
If this was like a web service or something that was alive for a long time you'd have to abort the various threads.<br>
So keep that in mind.<br>
So here we have a while loop and we're saying, while any of the threads are still working we're going to do a quick join on them and that let's us say real quick, hey, wait for a little bit and then we're going to do our check.<br>
Now we're going to ask the question, are you alive?<br>
And then basically use join to put our thread to sleep.<br>
We could just as well do a time.sleep(), I suppose but this one will cancel quicker if all the threads are basically finished.<br>
And then I want to check and we just keep going around and around we'd break out of this loop whenever we decide we're done waiting, we want to cancel out.<br>
If we don't break out then the threads are going to run to completion.<br>
That's a simple time out pattern that we can use in Python threads.
|
|
|
show
|
5:46 |
At the opening of this chapter I told you that threads belonged in the do more at once but not in the do stuff faster by taking advantage of the multiple cores on our system.<br>
And recall, on this computer here I have many, many cores, 12 cores up there.<br>
So I should be able to take advantage of all of those cores to do computational things way, way faster.<br>
In a perfectly parallel universe I should be getting 11 to 12 times improvement.<br>
So here I have a computational little program.<br>
I have the original and then this one, which starts as original but we're going to evolve it as we have been.<br>
And it has this function, do_math which is just going to do some multiplication and square roots and things like that.<br>
Didn't really matter what math it's doing.<br>
Just that it is doing math is pretty interesting.<br>
So let's run this singular serial version.<br>
It takes about 7.5 seconds to run.<br>
7.47.<br>
Excuse me for my inaccuracy.<br>
So it's done.<br>
It's done its work.<br>
If I was able to leverage this in some sort of threading way I would be really golden.<br>
I could make it go in half a second or something really great.<br>
So let me replace that line with an interesting little thing and the details are not super important so I'm just going to paste it for time sake.<br>
So what we're going to do is we're going to create a bunch of threads.<br>
We're going to start the threads and join on them.<br>
We've already seen that this pattern is super common here.<br>
And I'm going to import threads at the top.<br>
And instead of just doing math on how many is that?<br>
Let's make that number more obvious.<br>
On 30 million operations.<br>
We're going to partition this across n different processors from 1 up to processor count, alright?<br>
And why are we using processor count and not just 5, 10, 100, whatever?<br>
It turns out when you're doing computational stuff having more CPU-busy threads fighting for attention on the CPU itself actually slows it down.<br>
One thread runs for a little bit works with some variables and the other gets run by the operating system and kicks that thread off that processor.<br>
It needs different data which expels stuff out of the cache which means memory access is slower for a second and then it speeds up again.<br>
Things like that.<br>
So having too much contention for the processors in a CPU world is bad, bad news.<br>
Ideally, if nothing else was happening on the computer targeting the number of processors would be the exact right amount.<br>
Well, except for that in Python it's not going to help, as we'll see.<br>
But how did we get this number?<br>
We're going to have to bring in a new module here that we haven't seen yet.<br>
So we'll have to import multiprocessing.<br>
Now, multiprocessing is process equivalent of threads in Python.<br>
We're going to talk about it later.<br>
But it does have a cool little function: CPU count.<br>
There we go.<br>
And let's just do a quick print.<br>
Whatever your machine tells you is how many processors it thinks it have.<br>
Print that out.<br>
And if you want to be really ambitious we could put a comma there for when that goes over 1000.<br>
Anyway, let's just run it.<br>
Doing math on 12 processors.<br>
Should be half a second, or one second, something like that.<br>
Go, go, go, faster.<br>
Ah, that's a tiny bit faster.<br>
That's kind of cool, actually.<br>
Don't know how it got to be a tiny bit faster.<br>
Maybe because there's more threads.<br>
Actually fought against Camtasia which is recording my screen.<br>
Get a little more CPU time.<br>
Yeah, it does make it a tiny bit faster.<br>
But, you know, that ratio of 6.34 over 7.47 so that 15% speedup there.<br>
That is not super impressive, is it?<br>
So given that I have 12 cores we should have been able to do better than 15%.<br>
And I honestly think if I were to turn off Camtasia maybe it would actually not make any difference at all.<br>
I don't know.<br>
But here's an example of where the GIL is raising its head and causing serious, serious problems.<br>
So this, all of this work, is being done in Python in the Python interpreter, so every step of the way there's no sort of blocking waiting point it's just trying to do work.<br>
And the interpreter, 'cause of the GIL can only operate on one instruction at a time regardless of which threads or how many threads are running.<br>
That means this basically is parallel even though I gave it 12 threads to run.<br>
What's the fix?<br>
The fix is this problem is not solved with threads.<br>
This problem is solved some other way.<br>
I'll show you two ways in this course to make that number go down.<br>
I'll show you how to use multiprocessing to get that number under a second and I'll show you how to use Cython to get that number incredibly small.<br>
But the way it is right now it's not going to do a lot for us.<br>
We just can't make it go really any faster because the GIL is blocking any of the parallels that we're trying to take advantage of.<br>
Alright, so here's a concrete example of where the GIL is inhibiting threading.<br>
And of course, asyncio has even a worse problem, right?<br>
Remember, asyncio doesn't even have threads.<br>
It's all one thread, so there's not even a hope that you could have gotten anything better out of asyncio.<br>
But threading, some languages like C or C# this would have gone much faster.<br>
But because of the GIL, in this particular case this is where the GIL hurts you and you just don't get any extra parallelism, really.
|
|
|
|
28:30 |
|
|
show
|
0:46 |
No conversation about threads would be complete without discussing the very, very important topic of thread safety.<br>
Once we start working with threads we take on a whole new level of responsibility and we're going to talk about why that is and how we solve those problems and how we take responsibility for managing our data structures and making sure everything is safe there's no race conditions or otherwise corrupt data in our program.<br>
But before we get to that let's just talk about where we are on our landscape in our big Python parallelism and map.<br>
So again, we're over in this thread section and we already talked about why it's in the do one side and not the do things faster.<br>
We saw that previously as an actual demo even.<br>
When we're working with threads we have to be super, super careful about thread safety and we're going to talk about that throughout this chapter.
|
|
|
show
|
1:28 |
I'm sure you've heard about thread safety before, and there's things called race conditions and other problems that threads can introduce into your programs.<br>
And the fact of the matter is, threads require extra, explicit safety measures.<br>
We're going to talk about why that is and I've created a little visual graphic for you hopefully it really drives the point home for you.<br>
But before we even get to the graphic I just want to say that the errors that you find in threading are extremely tricky to track down in real programs.<br>
They're just super frustrating.<br>
The reason is, they depend on timing they depend on the hardware they depend on the load on the system.<br>
They often have to do with one part of your system and another part getting either in sync or out of sync in just a certain way based on a certain amount of load.<br>
And when you attach a debugger to that or you run an isolation on your machine without all the extra load maybe those conditions don't recreate themself.<br>
Because of that, there's this really cute and I think fairly appropriate name for these types of bugs they're often referred to as heisenbugs.<br>
Bugs that are there, until you observe them and then that actually changes them and maybe they aren't there anymore this sort of weird, quantum mechanic duality.<br>
If you think of quantum mechanics and that duality that's weird and hard to understand think of that in debugging, it makes it super hard.<br>
So you want to be really careful about that and we're going to see the various constructs in Python that we have to work with to make sure that the code we write doesn't have heisenbugs.
|
|
|
show
|
3:35 |
So I told you that threading requires extra safety, that it can introduce these bugs so lets talk about why they primarily exist.<br>
So let's take a step back and just think about the state of a program as we call an individual function.<br>
So this little box here this represents a function call and top to bottom is time, I guess.<br>
The blue stuff on the right, these are our data structures.<br>
We actually have two pointers one to the next, let's say a class that holds another class that then points at an item in a list.<br>
And then another one that actually holds a list.<br>
And what we're going to do is we're going to say blue represents a valid state.<br>
So if you were to stop running and let some other part of the system or return from the function.<br>
Your program is left in a valid state and unless you do something terribly wrong while you're writing code, this is always the case.<br>
You don't have to worry about some kind of weird situation coming up, you can exit your program and its in an invalid state.<br>
You normally don't write code like that.<br>
But you do often put your program into invalid states.<br>
Let's see how that works.<br>
So here we're going to come along we're going to call this function.<br>
A little bit of work happens.<br>
Everything's fine.<br>
We're going to make a bunch of changes to these data structures to evolve our program from one state to another.<br>
This happens all the time.<br>
We can't make them all at once.<br>
We can only change, say, one part now and then we're going to go along and run some more code and make another decision.<br>
And we're going to change another part here.<br>
And then finally we're going to make one more change that's going to put this all back into a valid state.<br>
What's the problem?<br>
Well, normally our code runs from top to bottom like that, and at the end it's back in some, probably new but still valid state.<br>
However along the way it enters these temporarily invalid states.<br>
The problem with threading is you have two of these things running at the same time, potentially.<br>
If they share any of these data structures one of the functions looks at it while another function has put it into this temporarily invalid state.<br>
Wham!<br>
You have a threading bug.<br>
So your goal with thread safety is to make sure that any time you're going to evolve your program into a temporarily invalid state during that step you don't let other parts of the program interact with the parts of data that you're working with.<br>
This can be very coarse-grained like, don't let anything else happen in the program while it's in this red state.<br>
Or it can be very fine-grained.<br>
Don't let anybody touch those two red pointers while it's in the state, but if they have other things to do, let them just carry on.<br>
There's this trade-off between how much work and management do you want to do to try to juggle that very fine grain, and stuff how much overhead is there having tons of little locks and other checks around all that kind of stuff.<br>
So, it depends on what you're doing how you're going to do this.<br>
But the key take-away is, you cannot help but put in your program into threading invalid states.<br>
Think of traditional C code that just even swaps two variables.<br>
That requires three steps.<br>
In Python we have tuple unpacking and so you can sort of do it in a line but probably in terms of operations that still could introduce some kind of threading problem.<br>
You have to have these temporarily invalid states.<br>
That's how programs work.<br>
Your goal is to isolate the data that is temporarily invalided when that's happening, and then, once it goes back you can let all the threads have at it again.<br>
Then, of course, our program returns and everything is left as it should be.
|
|
|
show
|
5:04 |
Welcome to our next set of demos.<br>
So we're going to have two or three different sets of programs we're going to go through.<br>
We have an unsafe bank which you should never, ever put your money in the unsafe bank.<br>
It may lose your money.<br>
Trust me this is bad.<br>
And we have this thing I've called a safe bank.<br>
Now the safe bank starts out unsafe.<br>
Our job is to take the unsafe bank and make it safe.<br>
How do we know it's unsafe?<br>
Well let's go and see what it does and we'll talk about it.<br>
So down here we have our main method.<br>
Well, first of all we have different accounts.<br>
They're extremely simple.<br>
They don't have to keep track of much.<br>
So we just have a balance right?<br>
In reality they have owners and numbers and things like that but ours just has a balance.<br>
And so we're going to create a bunch of accounts and we're going to figure out what the total number is in these accounts.<br>
The total value of these accounts and then we're going to go about transferring money between them.<br>
One of the mathematical properties that should always be true if we're taking money from one account and putting it into the other all within the same bank no matter how many accounts are there, the number the overall total should always be the same.<br>
Now that's excluding real things like fees and external banks and stuff like that but this is a simple bank.<br>
What we should be able to see is at no time will we ever not have a total amount whatever that total turns out to be of money in the overall bank if we look at all the accounts, yeah?<br>
And that's what validate_bank() does here.<br>
So we'll go look at that.<br>
Now we're going to kick off what is that, five threads?<br>
Going to kick off a bunch of threads and they're all going to run this do_bank_stuff() they're all going to have the accounts.<br>
I'm going to pass the total so they can do a little check to see if the bank is still valid.<br>
We're going to kick them all off and then we're going to wait for them to finish.<br>
That's standard stuff.<br>
We talked about that before.<br>
Now down here in do_bank_stuff() we're just going to go for 10,000 times around.<br>
We're going to randomly get two different accounts.<br>
We're going to create a random amount between one and $100.<br>
We're going to transfer money between them and we're going to validate that it's fine.<br>
So let's look at that transfer that's probably the last thing to do.<br>
So to transfer, super easy.<br>
We're given a from account to take the money from a to account to put the money in and how much to do.<br>
Add a little error checking in the top and then we just go take the money out of the top one and put it into the to account.<br>
Take it out of the from, put it into the to.<br>
And then just to simulate some real activity right something other than Python's GIL not really lettin' us do anything we're going to say, let's just give up our current time slice.<br>
We're not even sleeping for one millisecond but just imagine that this operation that we're trying to do here, this do transfer takes one millisecond right?<br>
It's just a little, tiny bit of time that is going to be the key to all sorts of problems.<br>
It just means these problems are going to be more observable but it doesn't actually mean the problem would go away if I were to comment that line out.<br>
Okay finally, final thing is we're going to say validate_bank().<br>
That is just to sum up the current balance and see if the current is the total and things like that.<br>
So if the current and the total ever differ we've got something wrong right?<br>
That's a property of our bank we should always have the same money if we're just shifting around accounts.<br>
Whew, well that's the introduction.<br>
You want to run it and see what happens?<br>
Let's kick off these five threads that are each going to do 10,000 requests across balance transfers between these various accounts and we'll see how it works.<br>
We're going to run safe bank.<br>
Alright so let's kick that off.<br>
Huh, what do you think?<br>
Well first of all, let's imagine we didn't do that.<br>
Let's put this away for one second.<br>
Let's imagine it's single-threaded.<br>
How does it work?<br>
We're starting transfers everything was good in the beginning did a bunch of transfers, was good in the end.<br>
That's how it should work all of the time but this is not thread-safe and I have set it up to be pretty likely to hit that error actually.<br>
If we run it now though you can see what's happening.<br>
One of these, let's say this thread is comin' along and transferring money from account A to account B.<br>
It's halfway through so it's taken money out of A but not in B.<br>
This one just finished a transfer and calls validate.<br>
It sees the invalid state that the first thread on line 21 has created, and it shoots out an error oh my gosh warning warning warning.<br>
Eventually the top thread here puts it back into a valid state but this is not good okay?<br>
So here you can see tons and tons of errors in this bank like look at that scroll bar.<br>
That is bad news bears right there.<br>
But at the end everything is fine, no problem.<br>
It's just a matter of did you observe that invalid state or not?<br>
And it turns out because so much stuff is happening you're observing it a whole lot.<br>
Would you like to put your money in this bank?<br>
It's called safe bank but it is nowhere near safe, yet.<br>
So our goal will be to use the various constructs in Python to make it safe.
|
|
|
show
|
4:35 |
We've seen safe bank is massively not safe and our job is to come in here and make it safe.<br>
So, how are we going to do that?<br>
Well, I'm going to use a different construct from the threading library.<br>
So we're going to import what you might think is Lock.<br>
Alright, Lock that's an obvious thing I would like to get however we do not want to use Lock.<br>
There's actually two different types of Locks in Python.<br>
Lock, which is a very low-level thing and RLock, or Reentrant Lock.<br>
The problem with Lock is if you call it from a function and that function somehow through some series of function calls ends up calling into that Lock again which is more likely than you would actually think it's going to deadlock.<br>
Right, so the lock cannot even be entered by a thread that owns that lock, and that's pretty limiting and it's hard to reason about.<br>
RLock means the thread itself can enter the lock many times as long as it exits as many times as it does but no other threads can get there and that's really the behavior we want so we're going to get RLock here.<br>
Now, what we're going to do is we're going to start out by doing a very coarse grain thing that just says let's fix this one problem down here and do transfer.<br>
It's this little bit that puts our program into a temporarily invalid state and then puts it back, so our goal with our Lock is to tell the other threads stay out, I'm about to put things into a temporarily invalid state, and in this coarse grain way what we're going to do is we're going to create one lock to say no other thread can do a transfer while any given thread is doing the transfer.<br>
So, first of all, let's run it just to see how long this takes.<br>
It's takes .71 seconds.<br>
Okay, great.<br>
That's the unsafe version.<br>
Now, let's go and create our lock.<br>
Let's call it transfer_lock.<br>
Okay, we we've created the lock, that's pretty awesome.<br>
Now, we want to go down here and I'll show you the not so good way and I'll show you the best way.<br>
So first of all, we're going to come down here and do it, I'll show you not good.<br>
Go to the lower lock and we're going to say acquire().<br>
You can see we can set a time out and things like that.<br>
we're just going to say we're going to block this thread until we get a chance to get in here and then we're going to go down here and say release().<br>
This will actually fix the problem.<br>
This will make everything good.<br>
But I said this behavior this pattern I'm using is not so good.<br>
It's going to work fine for what we have because I know there's no possibility of any of these operations failing, there's no chance of returning early or anything like that, but in reality we probably need to do this.<br>
Try and then finally, just in case there's some kind of exception in here we want to make sure that we release the lock.<br>
What happens if there's an exception and we catch it higher up but we don't do this?<br>
Program deadlock, we never, ever get into this function again ever.<br>
That's a pretty high consequence so you probably want to write this code instead of the prior code, I'll leave that one like that.<br>
So we could do the not so good kind but let's do something a little better.<br>
We can just say now with transfer_lock: and do the things we want to do.<br>
Like this, and of course this should be committed out cause we don't actually want to do it twice.<br>
So that, try, do this thing, finally release it well that's exactly what this with block does and you don't have to think about it you don't have to be really cautious about it.<br>
So, you want to do this with block.<br>
Now, our goal is to run this program and have it run the very first time when it says everything was great there were no errors, let's go.<br>
Man, that is so fantastic.<br>
Maybe it was just luck, alright, could be one of these weird heisenbugs, granted we did see a lot of errors so I'm pretty confident we fixed it.<br>
Well, let's just run it again, just to be sure.<br>
Nope, it definitely seems to be working so we fixed it, we made sure that any time our program is going to move into one of these invalid states we're going to tell all the other threads hold on, I'm about to mess up some stuff you shouldn't look at this, I'm going to do that and then I'll put it back let you all run as soon as it's done.<br>
Notice it did take .15 seconds, .15 seconds longer than it did here, 1.14.<br>
However, would you rather be slightly faster and wrong or slightly slower and right?<br>
We did take away some of the parallelism some of the concurrency that our threads had to work with but it was worth it, it was totally, totally worth it.
|
|
|
show
|
1:45 |
Now as I wrapped up that last presentation I realized there's one more thing.<br>
We actually have a little, somewhat small but still, little bit of a bug in this program.<br>
So remember our safe bank, it works correctly now it's a tiny bit slower, but it actually works correctly which is perfect.<br>
And we did this by adding a coarse grain lock everywhere we were doing the transfers.<br>
So down here, we use this lock and we block out access to this.<br>
Heres' the thing though, we need to make sure that no other thread can interact with these two accounts while this is happening and in this new transfer everything's fine but remember validate_bank()?<br>
We're also interacting with the account here.<br>
So we need to be super careful that we also take the lock there.<br>
So basically the idea is anywhere we're going to interact with the accounts we have to also take these locks assuming that's going to happen concurrently.<br>
So we'll say with transfer_lock:.<br>
Like this.<br>
Here we go.<br>
Run it again, it is a tiny bit slower because we're taking the locks more frequently.<br>
We could actually, the reason is, every single transfer we're calculating this is validate here.<br>
We don't have to calculate that frequently we could do some kind of other check but I'm just going to leave it like this not make any major changes but we technically have a little bug on line 83 here because we were accessing the accounts specifically the account balance for the accounts that were being transferred potentially between.<br>
It just so happened that that wasn't happening very often whereas this takes a little bit of time mostly because of that sleep this was so fast we actually never hit it but it was a bug one more time, see everything's good.<br>
Perfect.<br>
Works great.
|
|
|
show
|
5:50 |
We saw that our now safe bank uses a single global lock.<br>
And if we look and we think a little bit about that what that means is even if we have 50 threads trying to do transfers between thousands of accounts every single transfer is going to have to slow down and go through a single thread effectively a single processing pipeline because we're taking a lock for the entire process.<br>
And you may think well what we could do is we could actually, instead of using the same lock for every transfer, we could somehow come up with a lock that has to do with the various accounts.<br>
And if two accounts are being transferred by one thread and two other accounts are being transferred by a separate thread those two could actually happen in parallel.<br>
There's no data problem there.<br>
The problem is if they're using the same account you might think well we could gain a whole lot of parallelism, a whole lot of performance if we change from this coarse grain lock to a very fine grain lock.<br>
Now I want to say this right up front this turns out to be probably a bad idea in Python you'll see for performance reasons in this particular example and it turns out to make things a lot more complicated.<br>
We'll make it work.<br>
I'll show you how to do it but mostly the point of this the takeaway is going to be, oh that added a whole lot of complexity and it didn't really add any benefit or maybe it even made it worse or will see.<br>
Because of that, let's think about how much locking and how much complexity we're willing to do and what the trade-offs are.<br>
Okay so this is almost a lesson in don't go too far with this because it might become worse and not better.<br>
That said, let's set this up and see what we're going to do.<br>
So what we're going to do is have each account itself have a lock.<br>
I'm going to take both locks of this and locks take both of those locks at the same time before we can do transfers between any two accounts.<br>
Now that's easy.<br>
Just go over here and just say self.lock = RLock().<br>
And we see how to do this here.<br>
So instead of doing with transfer lock we're going to say from_account.lock like so and to_account.lock.<br>
And then we just indent this.<br>
It looks like everything is golden.<br>
It's going to be so wonderful.<br>
But remember, this is a lesson in what you need to be aware of.<br>
So I'm going to do a little print statement here.<br>
Because it's going to look like it actually goes slow but it's not going slow or there's something worse going on.<br>
Let's just run it so you can see the whole path here.<br>
So, what we're going to do is do a bunch of transfers and we'll be done.<br>
Shouldn't take that long.<br>
It's running.<br>
See we got some inconsistent balance.<br>
We'll talk about why that is in just a sec.<br>
It's just kind of sitting there.<br>
It is computing?<br>
Is it taking longer?<br>
No!<br>
If we go over here and we search for Python in the process, zero CPU.<br>
It's doing nothing.<br>
It's just sitting there.<br>
What the heck is it doing?<br>
Let's put some print statements.<br>
We could also do some debug statements but print statements will probably suffice here.<br>
Taking first lock, ...<br>
Taking second lock.<br>
And then we should see let's reverse that here.<br>
Oh I'm not going to leave this code in.<br>
But just so you see it we're taking the lock, we're releasing the lock.<br>
Things like that.<br>
All right again.<br>
Oh, we're taking...<br>
Doing some release.<br>
Taking first, taking second taking first and then we're done.<br>
We never got to taking the second lock.<br>
And what's going on here?<br>
So this is really hard to understand actually.<br>
We have one, two, three, four, five, six accounts and maybe six threads.<br>
If the accounts are separate everything is fine.<br>
But what if we're you know let's say thread 1 is transferring from account A to B.<br>
Thread 2 is transferring from B to A.<br>
They both get to line 64.<br>
They run that.<br>
Thread A takes a lock on.<br>
Sorry, thread 1 takes a lock on account A.<br>
Thread 2 takes a lock on account B.<br>
Now for B to continue, A has to release the lock on the first account, right?<br>
Sorry, thread 1 has to release the lock on the first account and for thread 1 to continue the lock on the other account has be to released.<br>
But they're both stuck here waiting for that second lock.<br>
All right, they've sort of criss crossed over on the two accounts and neither of them can make progress so they're in what's called a deadlock.<br>
So that's what's happened to our program.<br>
It's in a deadlock.<br>
You can see it's still trying to run here.<br>
So let me try to get rid of it.<br>
Kill these off.<br>
So the problem is by doing this we've actually created a deadlock.<br>
Now the other thing we have to do is this gets harder as well our validate_bank.<br>
Remember we're doing this safety check on the account.<br>
We're just taking one lock and then summing up all the accounts.<br>
Well, now we can't do that.<br>
We have to do it more like this.<br>
Let's copy that.<br>
We have to say account.lock.acquire for a in accounts.<br>
And we should spell that right.<br>
And then we should release it.<br>
And of course we should put this in to try/finally just to be safe but I'm just going to put it here like this.<br>
So we shouldn't see any of those errors anymore.<br>
Any of the inconsistencies cause now it's really safe.<br>
However, we're still deadlocked.<br>
Taking first lock, taking first lock, you are done.<br>
And these are where the threads are just finished.<br>
They've all mangled themselves up and they just stopped.<br>
So how do we fix this?<br>
Well, that's what we're going to do next.<br>
So we're going to come back and actually fix this and see if this trick that we did is really better than what we had before.
|
|
|
show
|
3:44 |
So here you see, we have our various print statements and we found that we go taking first lock taking first lock, done.<br>
This is deadlocking.<br>
How do we fix it?<br>
Well, the fundamental problem here is that different threads could say take first a lock on account A then B or maybe they go B then A and it's that order that is the problem.<br>
If we could guarantee all threads first took a lock on A and then they took a lock on account B regardless of whether that was the from or to account well then we could actually be great.<br>
We could just take those locks and we wouldn't have this deadlock problem.<br>
So, how do we fix that?<br>
Well, we can just decide some order for the accounts.<br>
If accounts had ID's we could figure out which one is lower and use that one first.<br>
Our account just has a balance and a lock but we can just ask for the memory address basically the Python ID of the pointer and that'll be good enough.<br>
So we can just say lock1, lock2.<br>
This is going to be a little clumsy and I can't think of a great way in Python to write it better, so let's just do this.<br>
We'll say from_account.lock to_account.lock, and we're going to do a test.<br>
If the id can get the id basically gives you back a number based on the pointer from_account is less than id of to_account.<br>
We'll say else, and return these in a different order.<br>
Then we just take this and say, you know what?<br>
We're using lock1 and we're going to use lock2.<br>
Now let's try it and see if it deadlocks.<br>
The deadlocked one is still running again.<br>
Kill it off there.<br>
It's slow because it has all these print statements.<br>
But it's not deadlocked, is it?<br>
Boom, it finished.<br>
Let's get rid of these.<br>
Alright, now we can run it without any of those print statements, just let it run pure.<br>
Whoo!<br>
So, do you see the huge performance benefit we got from this?<br>
We went and we said, look, we have six threads I have 12 cores, we have a bunch of different accounts.<br>
Let's actually let all of this happen in parallel and we're going to do way better.<br>
Our program is going to be so much faster because now, as long as it's not involving any of the two same accounts we can actually do concurrent transfers.<br>
Right, now we don't have that many here.<br>
If we added more accounts, you might think this gets better.<br>
But it turns out, this part gets faster but this part down here, those parts actually get equally slower.<br>
So, adding more accounts, which would add more concurrency actually just still kind of makes it more computational.<br>
And it turns out that it's just worse to remember what did we get before.<br>
Let me pin that, run that safe bank.<br>
This is the global one.<br>
We got 1.1 seconds.<br>
This new fancy high-performance version gave us 1.3 seconds and a bunch of deadlocks.<br>
So, I'm not saying you should never use fine-grained locks, I'm just saying you should think about whether it makes sense to use fine-grained locks or coarse-grained locks.<br>
And really the most important takeaway from this whole section has to do with this.<br>
If you're taking two locks from two different things you have to make sure you're always taking them in the same order, or there's a good chance you're going to deadlock your application.<br>
You don't want to do that, trust me.<br>
That is a really, really bad place to be.<br>
It's no fun to figure out what happened or why this is happening.<br>
Taking two locks, always take them the same order you don't have to use my little ordering technique figure out some way to order it but this works for this particular situation.
|
|
|
show
|
1:43 |
Let's close out this chapter by just talking about basic thread safety.<br>
We begin by importing threading, of course and we saw that there's actually several types of locks you can create.<br>
In fact, there's a bunch of locks we haven't even spoken about, like mutexes and semaphores and barriers and so on.<br>
There's all sorts of fairly-complicated stuff we can get into.<br>
But, this works for basic thread safety and most of what you're doing.<br>
So we're going to create a lock and we're going to make sure we use the reentrant lock, not the one you cannot reenter maybe you want that, you probably don't though.<br>
And then we're going to do our potentially-unsafe operations using a context manager, so with that lock and then in that block we're going to do things that we don't want other threads to see it's like a little privacy window for your data.<br>
Remember, at the beginning we talked about that temporarily invalid state and that's effectively unavoidable in our programs, that's just how programming works for languages like Python.<br>
So make sure you do them here, so other threads can't come and see them, and also remember everywhere you're interacting with any of those data structures you have to take that same lock, otherwise you might get into trouble.<br>
We saw we mostly fixed our application by taking the lock in the do_transfer() part, but we overlooked putting the lock in the verify accounts.<br>
We got away with it, but not really, it would have gotten us eventually, probably, at night on a weekend when we're going to get woken up or have to leave a party to go fix some bug that happened on the server or something weird like that, right?<br>
So, you don't want that, you want to make sure you actually write it all correctly first, so just make sure any data structures you work with in there, if they're used elsewhere also take a lock in those locations.<br>
That's basic thread safety in Python.
|
|
|
|
12:29 |
|
|
show
|
1:02 |
So far we been primarily focused on using parallelism and while we're waiting on external services or doing other things like that.<br>
We're not trying to take advantage of the processors that have all these cores.<br>
We're just trying to make our computers do more typically talking to external systems.<br>
And that's great, that's a really, really common probably the most common reason people use parallelism.<br>
But with these modern CPUs, you probably do want to take full advantage of their computational power.<br>
So that's what we're going to focus on in this chapter.<br>
That means we've jumped our divider line.<br>
We're no longer in the do more at once section.<br>
We're now trying to do things faster.<br>
As in, run a particular algorithm faster on a given piece of hardware especially multicore, multiCPU type of machines.<br>
So we're going to focus on multiprocessing a particular module which saw just a little bit of a cameo in the previous chapter.<br>
Multiprocessing is very similar to the threading programming model except we'll see that with multiprocessing each operation runs in an entirely separate Python process.
|
|
|
show
|
1:52 |
Remember at the beginning when I showed you that CPU graph that had a whole bunch of CPU cores that were all black and just one of them was really busy?<br>
What we're going to learn in this chapter will let you max out your computer and put all the CPU cores to work assuming you have a ton of computation to do.<br>
So, here's another Python program running and this one happens to be doing way, way more work.<br>
And we're going to use the multiprocessing technique which is the same thing I used to generate this picture.<br>
So, what's the fundamental idea here?<br>
Remember the GIL.<br>
The GIL was the thing that actually prevented our Python code from scaling across multiple threads.<br>
Sure, if that Python code is calling something down to the network layer or is calling something over to a database it'll release the GIL and while it's waiting we can do other stuff.<br>
But computationally, one Python interpreter instruction gets to run at a time, that's it.<br>
And the GIL is blocking those.<br>
So, here you can one process it's running.<br>
It has actually three threads but only one of them is allowed to go 'cause the GIL is blocking the other two.<br>
And, of course, this cycles around and it switches.<br>
How do we get that cool picture worth all the green all the work being done?<br>
Well, we don't let the GIL see the work.<br>
In fact, we're just going to kick off a bunch of processes.<br>
And, yes, these are Python processes and they each have their own GIL but they don't interfere with each other just like one program doesn't interfere with another.<br>
And in that regard, we can basically ignore Python's GIL because every single bit of work we're going to spawn off from what would have been a different thread is now going to be in a dedicated process.<br>
So, this can all happen in parallel.<br>
And you'll see the multiprocessing library is really great at making this fairly transparent and especially exchanging the data so that we can call the process wait on it and get the data back as if we just almost called a function, it's great.<br>
This is the picture to keep in mind for this chapter and we're going to go write code that does this next.
|
|
|
show
|
4:55 |
Here we are in our multiprocessing demo chapter.<br>
It might look familiar, actually.<br>
Remember this?<br>
Computed and computed_threaded?<br>
Where we did this math, especially the computed_threaded.<br>
We figured out how many processors we had and we said we're going to take this math function and we were going to run it across all of these operations, but we're in fact going to break it into a bunch of segments and have it work on each independent section.<br>
We saw that with the threads, that was super underwhelming.<br>
Let's just really quickly review that.<br>
I'm going to call this function called do_math() and it's just going to do a bunch of wasted computational stuff for a certain period of time.<br>
So the details aren't super important but our goal in this section is to stop using threads and start using multiprocessing.<br>
Okay, so let's just take this threaded example carry forward with it, so we're going to say compute multiprocessing, set that one to run.<br>
And it'll do threaded stuff for a moment doesn't matter, we'll come back to it.<br>
So our goal is to replace this thread stuff so right now what we're doing to our threads is we're creating the threads, and then we're starting them and then we're waiting on them.<br>
So what we're going to do is stop using threads and we're going to just focus on multiprocessing.<br>
Now we're not actually going to need this instead, what we're going to do to make this a little bit simpler is we're going to create this thing called a pool, so I'll call.<br>
Pool is going to be a multiprocessing.pool we can set a couple things in here.<br>
For example, we could set how many processes we'd like to use, now if we don't see any if we say nothing is going to use processor count actually.<br>
So we can just leave it like this that's probably what we want.<br>
You may want to constrain it to have fewer processes than it has processors, and similarly you might have even more.<br>
So what we're going to do is we're going to go to the pool I'm going to called a function called apply_async.<br>
Here we go, and what does it take?<br>
We have to pass the function, so it's a little bit annoying that the signatures different.<br>
Do not know why, but we don't have a target we just have the function that's not named.<br>
So we say do_math, and we'll call it and then we have the arguments.<br>
Which is, again, going to be that.<br>
And that's it, so this is going to actually start to work, we don't need to call stark.<br>
And how do we wait, well, we're going to say pool.close to tell it that no more work is coming, so when its processed all its work it can quit.<br>
And then we're going to, just like we did on all of the individual threads, we're going to join on this.<br>
Clean up on the formatting there okay, I think that that actually might do it.<br>
Not sure we could do anything different.<br>
What did we do?<br>
We didn't put our threads in the list and then managed the list, we're just calling pool.apply_async, we're using the number of processors on this machine by not specifying any particular number here.<br>
Let's go, let me run the threaded one one more time so just to, let's run the single threaded one.<br>
Just see how it goes, remember it was around 7.5 seconds.<br>
7, 7, 7, how is our multiprocessing going to do compared to this?<br>
Let's give it a shot.<br>
It's running, it's done.<br>
Yes, that is what we wanted.<br>
Is it as fast as if we had multiplied it or divided it by 12, a factor of 12 x increase.<br>
I don't think so, let's find out.<br>
No it's about five times faster.<br>
We are starting separate processes and all of that.<br>
Still we've seen a dramatic, dramatic increase in performance, we went from 7.8 seconds to 1.4 seconds, and you saw how much code that actually took.<br>
It's a lot of talking and explaining and so on we're actually turns of rewriting this loop it's ridiculous right?<br>
We created a pool, did a calling thread and then start, we just called pool.apply_async.<br>
Pretty much the same arguments and off to the races we go.<br>
Let's just look at this really quick.<br>
In my little glances program.<br>
Okay, here you can see not a whole lot's going on.<br>
CPU is around 6%, this is not going to run long enough for interesting things to happen.<br>
So I'm going to make it a little bit longer ten times longer, so we can run it for 10 seconds and see what happens.<br>
Now if we watch, what's the CPU usage?<br>
Woo, it's 96% of the entire machine, 99.<br>
Remember I'm doing screen recording that probably knocks out one of the CPU's right there.<br>
And look at all of these Python processes.<br>
Heres the multiprocessing happening.<br>
So they're all running and they're cranking along and then boom, they're done.<br>
They're all finished and now we're just down to my one little Python app that's sitting here or something to that effect.<br>
So there we go, it took 14 seconds because we made it 10 times as much so it's pretty much a linear scale right there.<br>
Awesome, awesome, awesome.<br>
So a multiprocessing really quite easy to use.
|
|
|
show
|
1:21 |
Let's review the core concepts around running our code in parallel on multiple processes using Python's multiprocessing.<br>
So, we're going to start by importing and creating a pool instance, and here we decided we're only going to let it create four subprocesses 'cause we're only going to ask it to do four things in parallel.<br>
So if you don't pass that processes equal four it's just going to pick the number of CPU cores you have a use that as the underlying process count.<br>
Okay, so then we go to pool and we say apply_sync() and we give it a function in arguments and then we can just tell it no more work is coming.<br>
And then do join, lets us just block kind of like when we join on a thread we join on this pool and it waits 'til all the work is done and then it continues.<br>
So we start all the work by saying apply_sync() and then we have to call close() and then join().<br>
I didn't make that super explicit but the docs say you should call close() and then join() don't just join() or you're probably going to wait a long time something to that effect.<br>
So here's the overall concept for doing parallel work actually skipping around the GIL by entirely sidestepping this GIL concept altogether and just going, well fine, if you're going to have a GIL we're going to have a single process for each effective line of execution as if they were threads but we'll let the OS handle the details.<br>
The trick is that the arguments get passed and we'll also see that you can get data back from these.
|
|
|
show
|
2:19 |
So this multiprocessing is great if we're going to kick off a bunch of work and have it be done.<br>
What if we need an answer though?<br>
What if we need to get back some kind of result from all of this work?<br>
How do we do that?<br>
It turns out multiprocessing has a pretty good answer.<br>
Let's have a look.<br>
I'm going to call this a task here and what we're going to do is we can actually capture the return value of a variable that we can put them all in to.<br>
I'm going to pin it like that and then when we're done, we can also print out our results.<br>
We can go to these tasks and we say t.get() Notice we can pass a time out.<br>
It will let us know whether it's ready.<br>
We can wait on it, we can know whether or not the response was actually successful.<br>
Like the execution was successful and so on.<br>
I'm going to do a get() and we'll print that out.<br>
We're going to get, well, right now nothing back because do_math() returns nothing.<br>
But let's try and make it do something interesting.<br>
So here we're generating a bunch of numbers.<br>
Let's go over here and have an average set that to zero and let's say the value is that, so we'll say average going to add the value and we're going to divide by the number.<br>
We want it to return, just make this an integer the average right there.<br>
This is not really a meaningful number we're computing, but we're going to return that value from each block of the run that we're working with.<br>
Let's go ahead and run that, then I'm going to go to something called the get() function.<br>
That will return the value, returned on line 40 there.<br>
Let's run it and see what happens.<br>
Doing all the work like before and boom, look at that.<br>
Those are the answers.<br>
Here are our results.<br>
I got those back from the various functions that ran.<br>
Of course we got them back in the order that we started them, not in the order in which they finished.<br>
Because we start item one, put it in the list.<br>
Start item two, put it in the list and so on.<br>
Then we just, when everything's finished we go through all the items first from the list second in the list and get the results.<br>
Correlate those back really clearly.<br>
This is the first block, the second block and third block of data that we're working with.<br>
That's how you get results back or even understand whether or not the operation was successful when using multiprocessing.
|
|
|
show
|
1:00 |
Let's wrap up this chapter on multiprocessing by talking about exchanging data.<br>
So we've seen that we start the work by saying pool.apply_async() give it a function, and some arguments.<br>
That's the first aspect of exchanging data so we can pass in these arguments, 0 and 100 in this example.<br>
And we're going to capture the results and then after the work is done after the pool's been joined and closed and all that kind of stuff we can go to the results and we can even check if it were successful and then we could call result.get and that's going to give whatever the return value of from do_math() work.<br>
And those values that can be exchanged they're pretty rich.<br>
Basically, anything that can be pickled which are most things, but not all things Python those things can be created and passed in or returned from these various functions.<br>
So we're passing the arguments we captured the results and hang onto it and then when all the work is done we just call get() to receive value from the function that we ran in multiprocessing.
|
|
|
|
14:27 |
|
|
show
|
1:51 |
We're going to touch on a theme that we're going to actually hit several times throughout this course unifying these different APIs.<br>
We've worked with threading and we've worked with multiprocessing but we saw that each API is different.<br>
It would be better if they were not different.<br>
If there was some way to just flip a switch and have automatically the same API do one or the other even better if it could figure out which to do.<br>
We'll get to that later.<br>
For now, we're going to come back to this place and straddle this middle line here.<br>
We're going to say, maybe we want to use threads they are more lightweight, typically and they have quicker, easier access to the entire memory space of any particular program.<br>
It is the same process and so pointers and memory and variables, all that kind of stuff are perfectly shared.<br>
Maybe though, we want to somehow take advantage of multiprocessing use separate processes, get around the GIL things like that.<br>
It would be nice if this decision was a decision we made and not an entire API that we worked with.<br>
That's what we're going to talk about in this chapter.<br>
Here's what we've done so far.<br>
For our multithreaded example we created a list of threads we called created thread objects.<br>
We set the target pass the arguments and said they were daemons.<br>
And then we started those threads and we waited on those threads.<br>
It was fine, nothing too hard about that.<br>
For multiprocessing we used a Pool.<br>
We called apply_async() and then we closed the pool and we joined on it to block like we are in the last line there.<br>
These are doing effectively the same thing.<br>
Granted, one is running threads one is running multiprocessing but that decision shouldn't be massively different, right?<br>
We could see the function parameters and what not are similar but they're definitely not the same.<br>
So what we're going to do is actually talk about something that will unify this.<br>
So let's go see that in the demo.
|
|
|
show
|
2:21 |
Let's look at a new program.<br>
Here we are in our execution pool section of our GitHub repo and I have created a new program and I have it all set up.<br>
It requires two particular packages requests and Beautiful Soup.<br>
What we want to do is we're going to use either threading or multiprocessing to implement this.<br>
And, what we'd like to do is make this as simple as possible to switch between those.<br>
So we're not tied deeply, deeply to the API.<br>
It's more of a decision of we're using the API and now which mode do we want it to work in.<br>
So, we're going to look at the synchronous version and then convert it to one we can toggle this mode.<br>
Alright, so we've got a set of URLs here and the goal is we're going to go to those URLs and get the title that comes in.<br>
Actually, we're going to get the H1.<br>
So, whatever the visible title is not the head part of the HTML.<br>
So we've got this function called get_title() And see we're just straightforward looping over those and we come down here.<br>
It's using requests, now we could use asyncio but the point is we're going to get to that later.<br>
There's actually a second step farther down in this course where we unify that as well but right now what we're talking about only applies to the older parallel techniques, so threading and multiprocessing.<br>
Alright, so because of that we're using requests and not aiohttp.<br>
We're going to suck down this HTML, feed it to Beautiful Soup and tell Beautiful Soup to go through the DOM and find the thing that's called H1.<br>
There's a little bit of weirdness around where the title is set for some of the pages and then it just gives back the text of that H1 and we call that the title.<br>
Let's run it and see it in action.<br>
It's getting the title from Python.fm which is Talk Python To Me, and Pythonbytes.fm which is The Python Bytes Podcast.<br>
Google has none, I think it's just an image or something funky like that.<br>
Real Python is Real Python Tutorials and training.talkpython.fm is Talk Python Training.<br>
Okay, so that you can see is sort of running kind of quick but this is the perfect example of where something might be really nice to apply parallelism.<br>
Like we saw in the asyncio chapter we're really just waiting on these web requests.<br>
We're not actually doing tons of work.<br>
So this is a good candidate for threading but it also may be a good candidate for multiprocessing.<br>
This is the app that we're going to work with and we're going to convert it to use one or the other of those two parallel techniques.
|
|
|
show
|
6:45 |
Now you're familiar with the program in its synchronous form let's make it asynchronous.<br>
And that let's me introduce an entirely new module that is built into Python.<br>
So these two are external packages but what we're going to work with now comes with Python.<br>
So import concurrent.futures and actually we want to get something out of it we'll say from that import Future.<br>
So this Future thing here this is a class that's going to represent some asynchronous computation.<br>
It's going to be the return value of starting one of these asynchronous operations and it doesn't matter if it's a process or a thread that it represents.<br>
So that's a really great thing.<br>
We saw that we have this concept of a pool one of these multiprocessing pools before.<br>
And the idea of a pool for either threads or processes is really great.<br>
They take a little bit of work to spin up and get started.<br>
It'd be great if they could just run and then we could assign work to them that they pick up and go with.<br>
So that's the general idea here.<br>
So we're going to say from concurrent.futures.threading or rather thread, import ThreadPoolExecutor.<br>
Now, I can say this and just leave it like this but let me add a little bit as PoolExecutor.<br>
So that'll let us reassign what this type means.<br>
That's going to be really handy.<br>
So what we're going to do is we're going to go create one of these kind of like we did with the process pool in multiprocessing.<br>
So down here, instead of just calling this work let's assign the work to be done.<br>
So we'll go like this and we're going to use this in a context block, a with manager so we'll say PoolExecutor() as executor.<br>
Okay, create a variable like that and we're going to work with it.<br>
Then we're going to do all this work here like so.<br>
This line, instead of doing this we're going to come over here and say f that's going to be a Future we're going to say executor.submit().<br>
The work that we want to submit is we're going to tell the function, that's the f in it's going to be that and the args is a *args so we can just pass them one after another, which is pretty handy.<br>
So we'll just say url.<br>
Alright, that's pretty cool.<br>
And then we can't now print out the work just yet.<br>
We'll do that in a little bit.<br>
Like before, we may want to get a hold of these answers after they're done.<br>
So let's go over here and say work, it's like this and work on f is this future.<br>
Okay, so, that's it.<br>
We're going to kick off all of this work maybe do a little print statement like waiting for downloads.<br>
Just so you know we've already started all of the work.<br>
And then when it's done we're going to leave that with block on line 28, between 28 and 29.<br>
There's not really, I guess there's like kind of the end right there, huh?<br>
When we leave that with block everything's going to be great.<br>
We're going to be ready to roll.<br>
Here we go, executor.<br>
Let me spell that better.<br>
Alright, so then we can just print out what we did before.<br>
Say for so for f in work: and then we can print almost what we had here but instead of title we have our future and we can say go to it and it has a result.<br>
Notice it has all sorts of things, right?<br>
It has cancel, cancel done, whether there's an exception whether it's running, all kinds of great stuff add a callback when it's finished.<br>
But we're just interested in the result which we could give a timeout or not.<br>
So that's going to print out the titles.<br>
Well, it's going to whatever get_title() returns and right now it's returning the title.<br>
Okay, so, here's our pool executor.<br>
Looks like it's ready to go.<br>
I think we've got everything going and we aren't doing any print stuff.<br>
We're going to add a little trace here just so we can figure out what's going a little bit better in just a second.<br>
But let's just run it and see if it works.<br>
Running.<br>
Guess I'll watch the titles and bam!<br>
Look at that!<br>
Now, our formatting wasn't so great.<br>
Let's put this down here.<br>
Actually, I'll leave it here for you like this.<br>
You can uncomment it.<br>
And let's put that down here just so we have a printing out.<br>
And we're going to put a proper end on it.<br>
See, if we get them all at once and then all of the results come back.<br>
So make it a little bigger, maybe, so you can see it run through it's entirety.<br>
Now let's run it one more time.<br>
Getting all the stuff waiting done.<br>
So, start the work, waiting, done and then here are the answers.<br>
We don't get one back from Google, remember.<br>
Now, we're not tying these together.<br>
It would be great if we had a way to figure out what the url was.<br>
Oh, and I noticed we could probably improve on that a little.<br>
If we could figure out what the domain was and print it here.<br>
But we could do it it'd just be a little bit changing the return value which I don't know that we're going to mess with.<br>
But would be nice to see.<br>
Nonetheless, this is working.<br>
The question is where is it working?<br>
What thread is it running on?<br>
Or is it even a thread?<br>
Is it maybe another process?<br>
So, let's go over here.<br>
I'm going to add a little debugging.<br>
I'm going to add a little debugging here.<br>
Now, I'm going to import something inside this function.<br>
Not normally recommended but it's just a temporary sort of trace diagnostics thing we're going to comment out so it doesn't clutter up the rest of the file.<br>
I'm going to import multiprocessing.<br>
'Cause we actually need that.<br>
So we can say, and get the current process.<br>
So we'll say p = multiprocessing.current_process() And then we can use that process to make some statements about this.<br>
So we can say getting title form that and we can list out the process ID and the process name and we already have the url.<br>
So let's go down here and wrap this format a little bit and this is easy pid and p.name, okay.<br>
And let's just tell PyCharm everything's cool.<br>
Okay, so let's run it one more time and just see what we get.<br>
You can see we're getting all of these titles and got some sort of race condition on our endline that's okay though.<br>
So we got all of this coming through and you'll notice the process is all the same.<br>
It's always 66203 for the moment.<br>
Won't be the same every time but it should be consistent for a run, right?<br>
And it's main process.<br>
So that means this get title is running on a bunch of different threads in the same process.<br>
That's not surprising 'cause we came over here and we said we're going to use the ThreadPoolExecutor, right?<br>
Pretty cool.<br>
And we can make this a little more explicit.<br>
Make this a, mark that as a Future that's why I import it, so.<br>
Make sure the auto complete works.<br>
Sometimes it does, sometimes it doesn't.<br>
This will be sure to help in your editor.<br>
Just that requires Python 3.6, so be aware.<br>
I think this is working for our threaded version.
|
|
|
show
|
1:47 |
So you've seen that we've taken our little app that goes against these titles from these URLs using threads via the ThreadPoolExecutor to do all the work.<br>
So we want to switch from maybe using threads to using processes, using multiprocessing.<br>
How much work is that going to be?<br>
Watch this.<br>
We're going to go over here and say, you know what?<br>
We're going to go from process, ProcessPoolExecutor.<br>
Now because we imported it as an alias down here, this line on line 19, doesn't have to change.<br>
Before we added line five, that meant create a ThreadPoolExecutor.<br>
Now we've changed what that means now it means create a ProcessPoolExecutor.<br>
I'll go ahead and comment this out even though, technically it'll work the same.<br>
Now what happens if we run it?<br>
Once again, let's make that bigger.<br>
So it's running.<br>
You can see the same basic process.<br>
We kick off all of the work.<br>
We wait for a second to get all of the results.<br>
Beautiful, and we do it all in parallel.<br>
Notice now though, now the process ID is different.<br>
The process ID is different for each one of the these and it says process name is fork process one fork process two, fork process three, and so on.<br>
Even though we're calling across these processes we're able to get a return value back by just getting access to the result.<br>
So run it one more time.<br>
Boom, quite nice, right?<br>
So look at that.<br>
To create the process pool edition instead of the threaded pool edition we change line four to line five.<br>
That's it because we can use this base API that is this executor API, and these futures that come back regardless of what type of work they're doing, it means we can use this same API for multiprocessing and for threading.<br>
Pretty awesome.
|
|
|
show
|
1:43 |
So we've seen the threading API and the multiprocessing API are not the same.<br>
They're basically isomorphic.<br>
You could map from one to the other pretty easily but they're not the same.<br>
It would be nice if they were actually exactly the same then we could switch between one or the other.<br>
And that's what we've just seen.<br>
Enter the executor.<br>
Over here we are using the ThreadPoolExecutor which allows us to create a with statement.<br>
And inside that with statement we can execute a whole bunch of asynchronous work.<br>
When you leave the with statement, the work is done.<br>
Basically the with statement blocks while this is happening.<br>
Notice this is not like the pool in multiprocessing which you had to make sure you closed it and you joined on it and you had to do those in the right order.<br>
This is a little bit simpler.<br>
So we've got this pool here and we're creating an instance of the executor and that's where it's going to run.<br>
And then we just go to the executor and we submit work passing the function to run and the arguments that we're going to pass to it.<br>
This comes back as a Future which we're keeping track of in a list and then we can look at all the results when we're done with all the work.<br>
You could look at them along the way and things like that but that's more complicated and we're just not interested in it right now.<br>
A really simple API cleans up everything and I think it's one of the better APIs we have around threading in Python.<br>
And the big benefit which we've been hitting on here is that we can choose our implementation.<br>
This one uses threads.<br>
If you don't like threads, change that one line from concurrent.futures.thread import ThreadPoolExecutor concurrent.futures.process import ProcessPoolExecutor And because we used an alias it makes it even simpler for our code to not change except for on that one import line.<br>
Beautiful.
|
|
|
|
33:03 |
|
|
show
|
1:32 |
In this chapter, we're going to talk about libraries that are built on top of async and await.<br>
And I'm not talking about just libraries like uMongo that let you use async await with Mongodb but libraries that are specifically built as frameworks for creating asynchronous programs that themselves use things like asyncio and async and await.<br>
So, there's a bunch of these out there we're going to cover a couple of them more as an example of a few great libraries you could use not an exhaustive list of all of them, of course.<br>
Now, I could either gray pretty much everything out or I could line up almost everything.<br>
As you'll see, we're going to touch on many of the things before.<br>
So, we're definitely built on top of async and that's going to let us do more at once.<br>
One library were going to work with, unsync actually works with multiprocessing threads and asyncio but it's primarily an asyncio type of library.<br>
And trio is built entirely on asyncio.<br>
With these two libraries, you can both do more at once and do them faster.<br>
But the reason their in this course is because they let you do these things more easily.<br>
They let you coordinate them better they put a unifying API on top of them they simplify things, stuff like that.<br>
They both add their own special capabilities so it's not like we're doing two takes on the same thing.<br>
They're actually quite different in their goals and what they do.<br>
I think you find unsync and trio to be excellent additions to the core libraries you're already familiar with from earlier in this course.
|
|
|
show
|
4:31 |
Before we get to the programming details of these additional libraries let's talk about why we might need them at all.<br>
We have async and await.<br>
We have threads.<br>
Isn't that good enough?<br>
Well, it depends on what you are trying to do.<br>
Yes, it's good enough, but it can be better as we all see.<br>
So what are some of the shortcomings of the various aspects that we've worked with so far?<br>
Mostly around asyncio, but also around threads and processes.<br>
One of the things that's annoying about asyncio is you have to have an event loop in order to execute an async function.<br>
Remember what we did is we created a loop, and then we queued up a bunch of work in it and where we created some coroutines and we said run to completion or something to this effect.<br>
And we waited on that loop.<br>
And it's not that hard honestly, but if you have a deep architecture: some function, calls another function, calls a library which called another function, how do you take the loop you have to create at the outside and pass it deep down to the inside so async functions down there can run?<br>
If you need to coordinate across those things this can be really not so easy.<br>
Alright, you end up passing stuff around or having weird global variables that, depending on how things are working, may actually not even work.<br>
This is a shortcoming, and we'll see if one of the libraries we talk about fixes it.<br>
So this is the shortcoming, and each of the libraries we're going to talk about has a certain way to address this.<br>
Asyncio.future is not thread-safe.<br>
Now, that may sound weird to you, but remember asyncio doesn't actually use other threads.<br>
It's like an event loop on a single thread so it's not thread-safe.<br>
But if you want to mix it with threads, that would be better if it were, right?<br>
On the converse side, we have concurrent.future.<br>
Remember this comes back from the ThreadPoolExecutor or ProcessPoolExecutor?<br>
When we queue up work, that thing cannot be used with async and await.<br>
It cannot be directly awaited which is annoying.<br>
Wouldn't it be great if I could get one of those back and mix it in and await on it?<br>
Well, you can't.<br>
Future.result is a blocking operation.<br>
It's generally good.<br>
If it's not done you want to get the work back.<br>
However, if you're doing this in an event loop you could actually clog up the event loop and if somehow there's a loop you somehow create the future which is running the event loop and then you call a block on it on another slice of those tasks running there you will deadlock your event loop.<br>
Not great.<br>
On the other hand where future.result is a blocking operation asyncio.future.result will actually throw an exception if you haven't completely waited for it to be done.<br>
So, depending on which type future you have it doesn't behave the same, that's also hard so we'll see of unifying stuff happening here.<br>
Async functions, as in async def - that's a function name always execute in asyncio loop.<br>
They don't run in threads.<br>
They won't run in multiprocessing mode.<br>
None of those types of things.<br>
However, may we have some work, and some of it is based on asyncio, but other parts of that work that we're trying to do altogether might be computational.<br>
Or maybe it's working with something that talks to a database or network, but that library doesn't support asyncio directly.<br>
It would be nice if we didn't have to completely have different API's and ways of working with them if we could unify that.<br>
Well, cancellation and timeout are tricky things than threads and processes.<br>
Thread local storage, which we have not talked about does not work for asyncio concurrency.<br>
So thread local storage is kind of like a global variable but each thread has its own copy of that data.<br>
Each thread has its own values for that global data.<br>
Imagine something like Flask.<br>
Flask has a global request object, and each time a request comes in, you can just access it out of thin air in your view method.<br>
And it has the value of that particular request.<br>
And that's fine if it's single threaded.<br>
You can just set that value, do the function call and then unset it.<br>
But remember, asyncio has only one thread for all these interwoven operations.<br>
So thread local storage no longer means what it used to mean.<br>
Well see, none of the libraries here directly address this but further down the line when we get to the async web stuff that's one of the problems that's going to have to be addressed.<br>
Testing concurrent code can also be tricky.<br>
These are some of the shortcomings that the libraries we were talking about will help us address and they also bring their own cleaner programming API for certain things that they're built for: coordination, parent/child tasks, things like that.
|
|
|
show
|
2:22 |
Unsync is the first library that we're going to look at that adds additional behaviors unification, or simplification to async and await in Python.<br>
Unsync is created by Alex Sherman and on the project page, it talks about why he created it and what he's tryna do.<br>
And I highlighted a lot of those already.<br>
So, he talks about how it's inspired by C#'s implementation of async and await using the task parallel library which actually is much nicer than Python's.<br>
Lot of stuff about Python is nicer than C#.<br>
C#'s async and await is actually better.<br>
So, the way that we're going to use Unsync is we're going to just use a decorator on top of a standard async method.<br>
Then we can work with it using simplified techniques that Unsync makes available for us.<br>
So, for example we can do fire and forget or we can do blocking calls that unify thing between asyncio future and concurrent future.<br>
Things like that.<br>
So, really, really nice.<br>
And they also introduce this concept of a different type of future for that unification called an unfuture.<br>
We're going to look at this through demos mostly.<br>
I'm not going to go anymore through their page or their documentation stuff but I do want to show you one thing.<br>
So, let's go over to their GitHub page.<br>
GitHub project.<br>
Two take aways here.<br>
One, great it's on GitHub so you can work with it and it's also on PyPI so you can pip install it.<br>
However, there's not that much traction around it right now.<br>
There's only 41 stars at the time in this recording anyway.<br>
In general if you have a project that doesn't have that much attention that is not that popular it's probably a warning sign.<br>
You'll probably say, mmm, nice but I'm not ready.<br>
You know, get back to me when it has 500 or 1000 stars.<br>
I sort of have that feeling as well and I'm not sure how much I would depend on Unsync.<br>
But, think I would.<br>
Depends what I'm building but I'm pretty sure I would and here's why.<br>
If you actually did look at what Unsync is.<br>
If you go, here's the entire implementation of it.<br>
It is only a 126 lines long.<br>
It's only doing a tiny bit of work but what you'll see is that slight reframing of the API in this 126 lines of Python makes it much nicer.<br>
I mean, it's just delightful.<br>
So, to me I would just say maybe make sure you fork this and just so you have it just in case but I think it's worth it.<br>
I'll show you the API.<br>
You can decide but it really is pretty special.
|
|
|
show
|
4:22 |
Time to write some code with Unsync and see how this simple, 126-line package is going to add some incredible power and a really wonderful API right on top of everything we've learned.<br>
And it's actually going to bring a lot of what we've worked on already together so it's great.<br>
Now let's begin by looking at the application we're going to write code for.<br>
Nothing we're going to do in this video has anything to do with unsync yet.<br>
We're going to do that in the next video.<br>
Here we have three files one called nosync, and that means it has no parallelism whatsoever one called presync and that one is going to use pure asyncio and then there's this thesync.<br>
It starts out using the same as presync but we're going to convert it to the unsync API.<br>
What we're going to do in this one is we're just going to call these functions and we have three, sorry four categories of functions here.<br>
We have one called compute_some.<br>
If we go to compute_some you can see it's doing math and it prints computing at the beginning, that's cool.<br>
So this would be a CPU-bound operation.<br>
Quick quiz, what is the best type of parallelism to apply to this one?<br>
asyncio, threading, or multiprocessing?<br>
Multiprocessing, right, to do anything CPU-based.<br>
Now we're going to download_some we're going to download_some_more.<br>
Let's go look at those two.<br>
In download_some, we're using requests and in download_some_more, we're using this.<br>
Now what we're going to imagine here is that when we convert it over to the presync one we'll see that for one of these we're going to imagine that we don't have an API that is async-enabled but it does HTTP requests under the hood and it's internally using requests.<br>
We won't actually be able to await it and it won't really take advantage of its powers when we use it with asyncio.<br>
The other one will have, actually aiohttp as its client and will be properly awaitable.<br>
So one of these would be better done with threads and the other would be better done with asyncio.<br>
Alright, now finally, we're just going to wait and this just puts our thread a sleep for a while one millisecond a thousand times, roughly one second.<br>
And again, we could easily do this with asyncio we've seen asyncio.sleep and we can await that, that one would be perfect.<br>
So this first one we're going to run has no parallelism and let's just see how that goes.<br>
It's computing, computing, computing alright, it's downloading, and downloading more then downloading and downloading more it does that a bunch of times.<br>
Now it's waiting, now it's done.<br>
How long did it take?<br>
9.62 seconds, alright, we'll freeze that so we can come back to it.<br>
Let's look at the presync one now.<br>
All we've done is basically taken as much advantage of asyncio as possible so if you look at the functions down here we have an async method computing but because it's computing we can't really do anything but wait there's no awaitability here.<br>
Async is not quite the proper API, as we'll see.<br>
Now this one, this download_some actually is, you know, is internally like, you got to use your imagination right internally this part actually uses aiohttp client and we can then, you know, surface its async abilities and this is a proper async option so downloadings have happened great.<br>
But this one is the one we're imagining does not have an async API so threading would help it but asyncio noticed there's no await keyword here actually there's no help, alright?<br>
This is just as if we called it in serial.<br>
Finally, waiting, that one we used asyncio.sleep this one's good.<br>
So let's run this one and we'll see some things get better like download_some, and wait_some but compute_some and download_some_more those, no good.<br>
Alright, that'd be a no benefit.<br>
So we got computing, see, just as slow.<br>
Downloading a little bit better waiting, way better, so it's an improvement.<br>
Notice it's about twice as fast from 9.62 to 4.93 seconds.<br>
Alright, so that's what we're going to start with.<br>
We have this program we're going to start with this presync mode which, alright, okay we're going to pick one of the three APIs to use.<br>
Let's pick asyncio.<br>
And that is probably the best one for the parts it took advantage of but it is not the best one for, say the compute one, or the requests based one.<br>
So we're going to see that with the unsync API we're going to simplify how this works and we're going to apply the right type of parallelism at the right place each right time.
|
|
|
show
|
5:54 |
Are you ready to use unsync?<br>
Let's go import it.<br>
From the module we're going to import a decorator that we need to use.<br>
Now, let's just see a couple of things that are, let's say, annoying here.<br>
So first of all we have to create the loop and like I said, it's fine when it's all right here but if you have a tiered application and different layers of your app need access to this loop all the sudden that's annoying that this exists.<br>
Why can't there just be an ambient asyncio loop that is the event loop for this thread, for this program?<br>
Boom, there is now.<br>
Second, why do we have to call create task on this?<br>
Can't we just call this function?<br>
Like, why can't we call these functions like we can regular functions?<br>
We can, that's what we're going to do.<br>
So now we're capturing our tasks and if we didn't actually care about the return value or waiting til everything was done we don't need to do that.<br>
But we do want to wait til they're done.<br>
So we don't need to create the loop call, you know basically add this work into the loop and then wait on it there.<br>
But we do want to, actually, wait before it so it's done, right.<br>
We saw how we did this with threads.<br>
We said t.join() for t in threads.<br>
So we're going to do something similar.<br>
We'll get our value.<br>
And this we're just going to call the results.<br>
Remember in unsync when we talked of like the beginning, this a blocking call until it's done rather that some kind of exception that it's not done.<br>
So this line will basically make everything wait and then we can print it out.<br>
So this is step one.<br>
Basically we're removing all the junk that we had to add for doing asyncio, right?<br>
Remove the loop, remove the adding the work and so on, and we're just going to wait kind of as if they were threads, I guess.<br>
Now this is where it gets interesting.<br>
So we're going to go and we're going to add this unsync decorator.<br>
Here, here.<br>
Any of these functions we want to treat this way we're going to add unsync to them.<br>
Now, this is how the rules work.<br>
If the unsync decorator is applied to an asynchronous method it is going to run an ambient you don't have to create it but it will be there asyncio event loop.<br>
This is all good.<br>
We don't have to do anything to make this work.<br>
This will make it run in an asyncio loop.<br>
This one, however, it's not really an async method is it?<br>
It has the word async here, so we could mix it in into our API, but there's no await.<br>
So let's take away that, cause it's not really meaningful to have it be that.<br>
We can still apply the unsync decorator to it and what that means is when unsyc is applied to a regular method it will run it in the background as well but on a thread, not on a asyncio loop.<br>
Async method, asyncio loop.<br>
Regular method on a thread.<br>
Similarly, this one async.<br>
No other comments no other values passed.<br>
Run this on asyncio exactly as it should be.<br>
Now finally, here we have another sort of fake not useful async method, so turn it back to this.<br>
Running it on a thread, does that help?<br>
No, we've already seen no, that does not do anything.<br>
It just makes it more work.<br>
So unsync has a great way to deal with this.<br>
You say, this one, this operation is CPU-bound.<br>
When you say that, it's going to say "Ah, here's a regular method.<br>
I would have run it on a thread but it's CPU-bound, so we're going to run that on multiprocessing." That's it.<br>
Multiprocessing, best option for that one.<br>
This one, can't remember which it is, sorry.<br>
That one's async, so that's going to run asyncio.<br>
That one does not have an async interface so we're going to run that on threads but cause it uses network it'll still release the GIL.<br>
And that, again, asyncio.<br>
Let see if it works, let's run it and see if it does any better.<br>
Damn, look at that.<br>
Sweet, let me make it bigger and we'll run it again.<br>
So, run it one more time.<br>
All that's going at once, all of it.<br>
All the computing all the downloading some of the downloading on threads some of the downloading on asyncio and all the waiting on asyncio all at once.<br>
And then we just had to wait for the computation to be done and for the downloading bits to be done.<br>
So let's look at the output.<br>
Started out with 9.6 seconds cause there was no parallelism.<br>
That was bad.<br>
We added what we knew, what we chose what we thought might be the best option for this particular situation.<br>
Said, "OK, so let's try asyncio." We have a lot of that in play and that's really the most efficient if we can use it.<br>
So let's try that, we got just under 5 seconds.<br>
We threw unsync where each method knew about its internal implementation the best way it could be run and we got this beautiful 1.3 seconds.<br>
Really, really nice.<br>
That's unsync in a nutshell.<br>
There's not a whole lot more to it.<br>
We basically import the decorator and we just call the functions.<br>
We don't care if they're async not async, whatever, we just call them.<br>
They all return these unfutures which we talked about at the beginning and then you can get the results and wait on them and so on.<br>
And then we just indicate here's a CPU-bound up regular function, here's a not CPU-bound async function.<br>
So, asyncio.<br>
Here's a regular non-async function so threads, again, async, regular function, asyncio.<br>
And that's it.<br>
I think this is a beautiful simplification of this whole API and it brings it all together in a really, really great way.
|
|
|
show
|
3:10 |
We've seen mixed mode parallelism.<br>
It's something you could easily run into.<br>
Do you have to do some work where some of its computational and some of it is based on I/O either explicitly through asyncio or just because it's talking to a network or a database or something like that?<br>
How do you put that work together?<br>
That's not super easy and that's why we started talking about unsync because it solves this problem exactly.<br>
So, here we're not using unsync.<br>
This is the asyncio style and we're going to create event loop.<br>
Again, that event loop is actually hard to get ahold of and pass around if you're passing this through tiers of your application or down into another library or something like that.<br>
So it looks like no problem here but it can actually be a challenge in your architecture.<br>
Then we're going to create a bunch of tasks so we can't just call compute_some or download_some_more because those don't return values those return coroutines, OK?<br>
So we've got to create a task from them and queue them up like that using loop.create_task.<br>
But, more importantly, where should these run?<br>
Compute some, give it obvious names, kind of giveaway names but compute some is CPU-bound.<br>
Download some more uses asyncio.<br>
When we wrote this we decided, hey, some of these functions can use asyncio, so let's go that way.<br>
Let's just go and do this work in asyncio.<br>
And for the green ones, download_some_more and wait_some that's a good choice.<br>
But download_some, that one is implemented in requests it's API is.<br>
So there's no way to really take advantage of it here.<br>
It's just going to block things up.<br>
Effectually that part becomes a serial thing, not parallel.<br>
Similarly for the compute_some, it should be run probably in multiprocessing.<br>
But how should we know that, as the caller of the function?<br>
Maybe we didn't implement it.<br>
Maybe we're using it from somewhere else.<br>
How do we know?<br>
That's, kind of, not great.<br>
So we have to make this decision, how shall we run it and actually, truly mixing together is not super easy, either.<br>
And then finally we have to create this loop we got to use the loop and call run til completed at the end and gather up the tasks and so on.<br>
And that's not great.<br>
So let's see how unsync solves that.<br>
We have that top block where it says tasks.<br>
That's the entire previous slide.<br>
Well, that and the list comprehension to block but it's not up to us where we're calling it to decide how our code runs.<br>
It's up to the implementer of that function.<br>
Who wrote that function, they decide where and how it runs.<br>
So the compute_some, that one's going to run multiprocessing.<br>
Download_some_more, asyncio, download_some on a thread.<br>
We don't know or care about that really at all.<br>
It's just going to work, as far as we're concerned.<br>
There's some future, it's running, when it's done it's done, do it the best way that you can.<br>
And the way we indicate that is we have either regular or async methods.<br>
So, like, compute_some and download_some those are not async.<br>
One of them is just regular unsync and that means run on a thread.<br>
The compute_some is unsync and CPU-bound which means run in multiprocessing.<br>
And that just happens automatically above when we create that list of tasks.<br>
We don't know or care about that it's all transparent.<br>
And finally, at the bottom, we have an async method that is unsync, that means run on the ambient hidden, asyncio event loop.<br>
Beautiful, right?
|
|
|
show
|
1:11 |
The next extra library that we're going to look at that builds on asyncio and makes it better and easier and simpler is Trio.<br>
Trio's goal is to produce a production quality, permissively licensed async and await native io library for Python.<br>
So it has a bunch of things for work with networks and so on, but it also has really great support for just coordinating anything built on top of asyncio itself.<br>
So where Trio really shines is it tries to focus on making coordination around asyncio simpler.<br>
They want to make it easy to do the best right thing with asyncio, so what's interesting is this is a framework built entirely from the ground up that integrates with async and await, but does not directly use asyncio.<br>
So like asyncio.get_event_loop, that is not part of this whole framework, it's something similar and in parallel to that and you actually have to use a bridging library.<br>
Something called trio-asyncio in order to actually use things built on the asyncio event loop.<br>
I think you'll find Trio an interesting library that could work for certain circumstances and types of apps you're building.
|
|
|
show
|
1:01 |
Our goal with Trio here is to take something we've already done and make it simpler and actually make it do even more without any complications at all.<br>
You guys remember the producer-consumer, here we are again.<br>
It's a simple application and there's a really nice example I can show you here with Trio.<br>
So, here's the synchronous version, we've seen that.<br>
We've taken the synchronous version and we've upgraded it to use asynch I/O.<br>
So, we get the event loop.<br>
We create all the tasks.<br>
We turn them into a single task.<br>
We wait for them to run.<br>
This is okay.<br>
One of the things we didn't really talk about is cancellation.<br>
What if we're going to say, run this and if the user chooses to cancel, or we're willing to wait, say up to five seconds but not longer, then we're going to bail and cancel all the tasks and things like that.<br>
So, we'll see that with Trio this more advanced scenario becomes super easy.<br>
But our first job is we're going to take this app and we're going to convert it to use Trio, and a little bit like unsync, you're going to see that some of the challenges and ugly hoops you have to jump through just go away.
|
|
|
show
|
4:53 |
So we'll begin this Trio exploration by just duplicating this.<br>
So we'll copy and then paste it back here and I'll call it prod_trio.<br>
So let's go over here and again I told you this is not built on asyncio and actually it's not even compatible with it without that bridging library so we're not going to do this.<br>
We're not going to do that stuff so let me comment out and we'll delete it in a minute.<br>
So, instead of having a asyncio queue, we'll have Trio.<br>
And notice there's a pycharm warning saying this initializer this constructor takes a parameter that we're not passing it and that is the capacity has to be set.<br>
The capacity's job is to say remember when you tried to put stuff into the queue?<br>
Down here, we were seeing await putting items into the queue.<br>
Well, how do you know when it's just going to put something in a queue versus we want this to stop filling up the buffer and stop producing items?<br>
Well, that's what this capacity is.<br>
This is how many items can be put into the queue before it blocks when you call put.<br>
Let's say 10.<br>
Okay?<br>
And then all of this stuff, we're going to take all of this and we're going to simplify that dramatically.<br>
So the primary construct that you'll see in Trio is this thing called a nursery.<br>
The nursery spawns children tasks and you know, that's the idea there.<br>
So what we're going to do is we're going to convert main into an async method.<br>
It's going to take one more adjustment for this to actually work, below but we're going to convert that to an async method and we're going to say async with trio.open_nursery() as nursery: And then recall we want to run that twice and then produce so what do we do?<br>
We say, first, we spell nursery correctly and then we say nursery.start_soon().<br>
Now it doesn't give you auto-complete which is kind of annoying.<br>
So we could do, just do this real quick.<br>
Complete.<br>
We could import this and then start_soon start, start_soon, cancellation scopes, all sorts of stuff.<br>
So, we'll go in there and what goes in here and we pass a function and then a *args and a name as a keyword argument if we want.<br>
So and that's pretty cool.<br>
We're going to pass this and just the name.<br>
There's the function.<br>
And then we pass argument one, argument two and then if we want we can have the name for debugging purposes, Producer 1.<br>
We're going to have another one, do it again.<br>
And then we're going to have this processor this consumer, and this is 40.<br>
There we go!<br>
Well, now what else do we have to do?<br>
That's it!<br>
We're actually done.<br>
So here's how it works, and let me get rid of this 'cause this is just so you could sort of see the auto-complete list.<br>
What we do is we open a nursery within an async with block, so this awaits here.<br>
And then we kick off all of these tasks.<br>
So start_soon queues them up and internally these could themselves write code like this that would open child nurseries and they would also basically become child tasks or we could pass the nursery and those could also spawn more that are sort of independent of these and so on.<br>
So we're going to kick all of this work off and then this with block will not be exited.<br>
We won't get past line 18 here until either it all completes successfully which will be probably the best case or one of them gets an error in which case any still running ones get canceled and then we exit the nursery.<br>
Or we can do timeouts which we'll talk about later.<br>
All right so, this looks a lot simpler, right?<br>
Don't have to do this, all these weird hoops we're jumping through, we don't have to do that.<br>
Now, again, we converted from a asyncio queue to a Trio queue, so we got to do that down here.<br>
And we don't asyncio.sleep, we trio.sleep.<br>
But other than that, pretty much all the same.<br>
Don't need that, okay.<br>
Let's run it and see what happens.<br>
Oh, yeah, did I tell you there's one more thing to do?<br>
RuntimeError.<br>
What does it say?<br>
Main was never awaited and we exited right away.<br>
So down here in order to run this coroutine which is now it is a coroutine we just need it to say trio.run in a synchronous context like this.<br>
Now our app can run.<br>
So it should operate pretty much the same as it was before.<br>
Well, in fact, basically exactly the same as the asyncio edition.<br>
And there it is!<br>
Pretty much exactly the way the asyncio edition ran.<br>
There's a few things that are simpler.<br>
Up here we're not really taking full advantage of Trio because of all of the networking capabilities that it has for like writing our own server and stuff like that.<br>
But, you could check out the docs.<br>
They have a cool, like, network TCP echo server if you want to see how that's done.<br>
This is pretty simple.<br>
I'm not sure it's simple enough to justify switching from asyncio to Trio.<br>
But, I'll show you some more features of Trio that make it really powerful.<br>
Maybe do make that switch worthwhile.
|
|
|
show
|
1:56 |
So we converted from asyncio to Trio and we saw things got simpler this async with block.<br>
The nursery concept is quite simple.<br>
Let me show you how we can use that for even greater benefit.<br>
I talked about cancellation.<br>
Now watch this.<br>
Let's suppose we want this to run for either five seconds and finish successfully or if it goes past five seconds we're going to cancel all the work.<br>
OK, even all the child tasks that maybe those processes themselves kicked off.<br>
How'd we do that?<br>
It sounds complicated, right?<br>
Watch this.<br>
With trio.move_on_after, let's say 5.<br>
How about that?<br>
Let's see what happens here.<br>
It should run for a little bit.<br>
Do some generating, do some producing, some consuming and then it should cancel.<br>
So this line should print out in just about five seconds.<br>
Let's find out what happens, it's working, and it's working.<br>
Five seconds are past, and boom.<br>
We ran out of time.<br>
We're done.<br>
We canceled them, straight away.<br>
How cool is that?<br>
So if we make that less work, two, two, and four something like that, should be able to produce all the work and just finish early.<br>
No cancellation, 2.42 seconds.<br>
But if it takes too long, this cancellation kicks in and off it goes.<br>
So these interesting coordination concepts like to have this block only run for so long with some sort of time out, also if this thing kicks off child tasks and then you decide to cancel it or time it out or something like that or this one has an error.<br>
Even those get canceled if they're still running.<br>
There's really interesting stuff that happens around this behind the scenes that does happen in normal asyncio, definitely doesn't happen in threading or multiprocessing that makes this a really nice coordination framework.<br>
And that's Trio, like I said there's actually a lot more to it.<br>
You can build really interesting things from the ground up.<br>
But I think this is enough to give you some inspiration and some ideas to go explore it if it's useful for you.
|
|
|
show
|
1:16 |
Let's review our core concepts around Trio.<br>
Trio is independent async await capable library that is entirely independent of Python's built in asyncio library.<br>
That whole loop of structure and underlying things has nothing to do with Trio.<br>
So Trio is it's own thing from scratch.<br>
And the reason it's like that is they want to make sure they have complete control over how stuff executes, the cancellation, the error handling all of those types of things.<br>
So here's a general use case, I'd like to go an generate some work and consume some work with the producer consumer style and I want to maybe even let those pieces kick off sub child tasks and so on.<br>
And I'd like to either do all the work and finish successfully in five seconds or I want them to be canceled if they have still pending work.<br>
So we just create one with block for the move on part that's the time out and then the async with block.<br>
One's async, one is not, be careful there.<br>
The async with block to open the nursery kick off all the work and either that's going to block until it's finished, it's going to block until you cancel or it's going to block until one of them has an error in which case it'll cancel all the running and not yet started tasks.<br>
It's a really simple coordination concept around async work.
|
|
|
show
|
0:55 |
Before we move on from Trio, I just want to point out Trio-async, and I did throw this out at the beginning when we talked about Trio, but I want to make it super clear if for example, you want to write in Trio but somewhere you want to use, say, aiohttp client we've seen how awesome that is and that's a totally reasonable thing to integrate.<br>
Or maybe I want to use the async library that talks to Postgres.<br>
Well, for sure, the aiohttp client will not work inside of Trio's async methods.<br>
You'll get some kind of error that it's not the right kind of event loop.<br>
It's not an asyncio event loop, it's a Trio event loop and they can't deal with each other.<br>
If you want to use those libraries in code that you write based on Trio, you have to use this library to create adapting a layer of asyncio event loop over the Trio's event loop.<br>
Just be aware that you're going to this if you want to use any external libraries that are built on top of asyncio.
|
|
|
|
31:38 |
|
|
show
|
1:20 |
I opened this entire course when we started talking about async as concept of why we really wanted it by talking about web applications.<br>
Web applications are either calling a database calling some microservice or external web API or doing just a little bit of work to send that HTML back to the browser.<br>
But most of the time, they're waiting.<br>
And so web APIs are really one of the key places that asyncio just shines.<br>
So what we're going to cover in this chapter is we're going to talk about building websites particular APIs with Flask and we're going to make those async as in async and await.<br>
That puts is back in my favorite place the top left, asyncio.<br>
Like I said, I really, really like this.<br>
Unsync sort of amplifies it across the different areas but asyncio really, really awesome and we're going to apply this technique to find all the places our web app is waiting and just set it free to go do more stuff.<br>
Do more stuff at once and be more scalable.<br>
This means instead of paying fifty dollars for a server or a set of servers we're scaling up to we might be able to spend ten and get even better response times just because instead of having a whole bunch of systems waiting and queuing up threads and blocking and things like that we'll just interweave all of this asyncio just like we saw in the beginning.
|
|
|
show
|
1:31 |
It may have been awhile since you're seen the opening async chapter where we talked about synchronous execution and response time and why that is versus asynchronous execution.<br>
As I've said before this is how we opened the course but just to remind you we'll go through this super, super quick we have three requests that come in.<br>
They each take the time that the green box with their name on them takes so request one and request two take awhile request three not so long.<br>
We want to know how long does it take from the outside how long does it appear for this processing take to the client.<br>
If we have a single threaded synchronous set of executions in our web app.<br>
Well, response one looks pretty good about the same time we, I guess, expect it to take.<br>
Response two however, is pretty shabby.<br>
And if you look how short request three is it turned out to be like five times as long as it should have taken because it didn't get a run for so long it's all queued up.<br>
If we can take the places where our web app is mostly waiting on a database waiting on a web service waiting on a file system all those things and wrap it up in asyncio we can take this graphic and make it way better.<br>
Looks more like this.<br>
We can start processing request one as soon as it starts waiting and request two comes in we immediately can pick it up.<br>
Similarly, when we get to three the first two are waiting again on something like a database we just hand out that response right away.<br>
So it looks more like this.<br>
Yeah, you can't actually make them go faster but in terms of latency well, things look a whole lot better.<br>
This is the type of system we're going to build right in this chapter using a Flask.
|
|
|
show
|
5:01 |
Let's talk about the web app we're going to build.<br>
It's already created as a Flask app.<br>
It takes a while to build and I don't want to spend all the time doing that just diggin' into Flask.<br>
It's not a course about Flask per se.<br>
But we're going to take a Flask app and we're going to make it asynchronous and we're going to implement all of the things you have to do to go from the traditional synchronous style to asynchronous which is going to be pretty awesome.<br>
So I want to introduce you to it and then we'll start programming the async transformation it's going to go through.<br>
So there's actually two web apps here Cityscape API and ACityscape API.<br>
Right now these are both the original serial version.<br>
This one we're going to transform into the asynchronous version.<br>
So I'm going to leave that there for you to have as a record.<br>
This is the one we're going to work on.<br>
So let's just go through really quick.<br>
Now I don't assume that you know Flask like I said but we're not going to go into too much of the details.<br>
You'll see enough that you'll be able to take it away and if you learn a little bit about Flask then you'll be able to adapt this, no problem.<br>
Maybe the best way to introduce you to it is to actually see it running so let's start it real quick, open it up.<br>
And it says we can use this API, sun/zipcode/country is one of the APIs so let's put that in here.<br>
So zip code, might be 97227 if you could type the 9.<br>
And the country code would be something like US or your country and you can put your postal code in there.<br>
And you hit this, and what we get see it took a second 'cause it really went out to the Internet to another service a couple services actually and it figured out what sunrise and sunset in and around Oregon is.<br>
I don't know exactly where that is, but which where this zipcode is but it's pretty close to me and this looks about right.<br>
So sunrise at 6:48 a.m., sunset 7:30 p.m.<br>
We can also ask for the weather.<br>
It'll give us all sorts of details back about the weather how much cloudiness there is.<br>
What's the humidity and pressure.<br>
The moderate rain apparently is something happening right there so, pretty cool.<br>
So we can basically ask for sunrise, sunset and we can ask for weather.<br>
That's what this API does.<br>
Now let's see how it goes about doing it.<br>
So this app.py, this runs when everything starts up.<br>
This creates our Flask app so here's our Flask app.<br>
And we've used this concept called a blueprint a Flask blueprint, to take the sort of HTML view stuff and put it in one file and the API bits and put it to another file.<br>
So it let's you separate our apps.<br>
I really like that pattern.<br>
And then it just goes and it sets some values out of config files that live over here.<br>
Then it calls run.<br>
So that's pretty straightforward.<br>
Let's just look at the API bit over here.<br>
So for example let's look at the sun it's more complicated.<br>
So you give in a zipcode and the country as strings and we have to call this function to actually get the latitude and longitude.<br>
That is actually what's required for the sun_service that we use say given any spot on the globe what is the sunrise, sunset information?<br>
So these services right here this one, and this one those are implemented over in the service section so we have the location_service for example.<br>
Sun_service for example.<br>
So I'm going to hide away this cached data 'cause we're not using it right now.<br>
This is only if you want to do performance testing we'll talk about that later.<br>
So we're going to go in and we're going to use requests we're going to go and just get a call and we're just going to do some json parsing here.<br>
And then we have to convert from UTC to local time just so things make sense to you in that location when you look at it okay?<br>
So this is it.<br>
How are we going to add asynchronous into this?<br>
Well this function right here could be async theoretically, except for well see, Flask does not support any async capabilities whatsoever, at all.<br>
We'll talk more about that in a moment.<br>
There's actually an interesting piece of the documentation and some interesting news around that as well and depending when you watch this that may or may not be still true but Fall 2018 Flask definitely does not support any form of async.<br>
So we're going to somehow find a way to make this function async and then we'll be able to implement that in aiohttp client style as we did before, same for this.<br>
And then we can await those and instead of having this method just block while we're talkin' to that service block while we're talkin' to that service both of those times, when they're blocked will let other requests come in and maybe process the weather request.<br>
Or a different send request, things like that.<br>
This is our app that we're going to start working with and this is the app we're going to use for our demo.<br>
Like I said this one is hangin' around for you to just have as a record.<br>
This one right now is synchronous but it's going to be converted to an async enabled, Flask-like, Flask-based API but it won't actually be a Flask.
|
|
|
show
|
1:51 |
I made a statement that Flask does not operate in the async world.<br>
It does not support asyncio and there's no capabilities or way to turn that on.<br>
We cannot have async def view method.<br>
It just doesn't work.<br>
So I want to highlight a piece of the documentation in Flask 1.0 and then actually give you some news.<br>
If you go to docs1.0/design you'll see this block in there somewhere.<br>
Design decisions in Flask it says ...<br>
However Flask is just not designed for large applications or Asychronous servers.<br>
Flask wants to make it quick and easy to write a traditional web application, period.<br>
Flask will not support async, that's what it says right in the design decisions.<br>
It's not intended for asynchronous servers.<br>
So what the heck is Flask doing in this course?<br>
Well, two things, first of all, we're going to have something that's very, very much like Flask.<br>
It's compatible with Flask but does support asychronous servers perfectly.<br>
Second I actually recently spoke with David Lord who is in charge of Flask these days.<br>
I interviewed him on Talk Python, the podcast and I asked him about this.<br>
I said, it says this right in the docs.<br>
He said, yes, but.<br>
He says that but we're intending to support asynchronous at some point.<br>
Maybe it's going to take a year, maybe even two years but they're going to support it.<br>
So there may be a point where you're watching this video and you can just put async def on those Flask methods and magic is going to happen but at the time of the recording, like I said, 2018 fall, this is not an option.<br>
It does not support it and it's still a couple years out.<br>
Actually the guy that's working on the framework that does may be collaborating with the Flask folks to make this happen natively in Flask.<br>
Okay so no async for Flask, maybe just not yet.<br>
Anyway that's the news.
|
|
|
show
|
1:06 |
You saw the design decision Flask is not intended to support async and currently it doesn't maybe it will at some point.<br>
So what do you do?<br>
Give up?<br>
No, you can go use this thing called Quart.<br>
Flask, Quart, Bottle, things like that.<br>
So Quart is a Python web microframework just like Flask it's based on asyncio and it has very good compatibility with Flask.<br>
What does that mean?<br>
It means has the same API as Flask it means even the extensions you can install into Flask are compatible with Quart.<br>
So if you have a Flask app, chances are you can tweak it a tiny bit, make it a Quart app and then it becomes asyncio enabled.<br>
That is our goal, our goal is to take our work in Flask app that we saw previously and convert it to Quart and that conversion will mean a little bit of stuff to change the framework.<br>
And then, more work to actually reimplement our services that call external services in asyncio capable ways.<br>
We already have done that once or twice so it's not a big deal but we do have to go through those steps to do the conversion.
|
|
|
show
|
1:30 |
Our goal is to convert this working Flask app into a Quart app, and it turns out because of the very high compatibility between the two APIs it's not that much work.<br>
So let's go over here and add take out Flask and put Quart.<br>
We're going to make sure we pip install those requirements.<br>
Alright, great, we've got a bunch of things installed here.<br>
So, how do we do this conversion?<br>
Well, here's the rough rule of thumb.<br>
You see the word Flask, you convert that to the word Quart.<br>
If it's lower case, it's lower case quart.<br>
If it's upper case, upper case Quart.<br>
Alright, so let's try Quart here.<br>
And we go over here and we say this .Quart.<br>
Yeah, looking good.<br>
Okay, this file is converted.<br>
That wasn't so painful, was it?<br>
With these two views, let's go fix this one.<br>
We're going to import Quart and we're going to say Quart blueprint, that's the kind we want.<br>
And here we're doing a Flask response so we're going to do a Quart response.<br>
Also we have the city API, similarly Flask, Quart, Flask, Quart, Flask abort, Quart abort.<br>
Flask jsonify, Quart jsonify.<br>
You guys get it.<br>
Am I done?<br>
Let's try.<br>
Ho ho ho, it is working.<br>
Seems pretty good, let's try this one.<br>
Yeah, still working.<br>
That wasn't too hard, what was this?<br>
A couple of minutes?<br>
We've converted from Flask to Quart.<br>
Granted, larger applications, more find and replace but not too bad.
|
|
|
show
|
4:39 |
Now that we've converted our framework from Flask to Quart everything's working but that's not really any async magic right?<br>
These methods are not async def they're just def regular methods.<br>
And most importantly the reason they aren't is we can't await this, we can't await that.<br>
There's no reason for them to be async because they don't do async stuff.<br>
So we got to start at the lowest level to enable this so let's go down to this location_service.<br>
And here we're using requests but remember the way that we actually do this for async is we do this with aiohttp client.<br>
If you didn't get that check out the very first chapter where we talk about asyncio in case you're skipping around.<br>
How does this work?<br>
Well first of all we have to have that as a requirement here so we're not going to have requests any more we're going to have aiohttp.<br>
Now that's fine on its own but we also want to add things like aiodns and cchar.det for better performance there.<br>
PyCharm thinks these are misspelled just tell it it's not.<br>
Alright once again let's run our requirements install 'cause we now have new requirements.<br>
Excellent, everything was installed successfully.<br>
So with that out of the way we can now reimplement this using aiohttp client.<br>
So we'll say async with.<br>
Import that, aiohttp.ClientSession() as session and then async with session.geturl() as response.<br>
So we don't do that line and those need to indent and we're almost there.<br>
Now notice there's a little hint that something's not quite right.<br>
Look at this get here.<br>
Coroutine does not have a method called get.<br>
Well that's not what we wanted.<br>
Previously this was the dictionary and it was a return value that.<br>
Just like in the previous section we have to await maybe not that much await.<br>
Await that, there we go.<br>
Now what we get back is a dictionary and we're good to go.<br>
So this almost works and the reason we didn't get a little more help from PyCharm there was we hadn't yet said this an async method itself.<br>
Alright so this looks pretty good.<br>
Let's just go and do it up here.<br>
Actually, that's the only one in this service.<br>
Let's go do the next service.<br>
The other one we have to work with is our sun_service and again this is going to be aiohttp.<br>
We get this stuff happening.<br>
We can indent it so that this can come out of the async part.<br>
And this we need to make into a little variable that we can await to get it and then we can call get.<br>
Perfect so, unless I mess up the indentation somewhere this should work.<br>
Oh and async.<br>
That's fine, that's just CPU bound.<br>
Alright it looks like this might be working.<br>
The final step would be to actually test it here.<br>
We haven't tested if we try to call this function it's going to get, it's not going to work right?<br>
Because this is not two values you can unproject it's a coroutine.<br>
So final step to make this all work we come down here we can go to this and just double check.<br>
Yes that's an async method even though PyCharm is not helping us we have to await to get the two values back so we can project them into this yeah unpack them similarly here.<br>
That's it, we have an end-to-end from top-to-bottom bottom-top, how you like it.<br>
Async method, so async view.<br>
We await the various operations each of those are async methods that can be awaited using things that we're already familiar with like aiohttp client.<br>
Now the big test.<br>
After all this craziness, does this still work?<br>
Let's find out.<br>
So the thing we changed was the sun API.<br>
Let's try this one.<br>
Boom look at that.<br>
Now you probably won't see any performance difference.<br>
Remember those big green boxes and the response time?<br>
The green boxes didn't get shorter they took exactly the same amount of time.<br>
We're still waiting for those two services to do their thing but the key difference is the thread that runs the web server is now free to take any other request and work on it while we're waiting.<br>
Previously they were just blocked.<br>
But now it's golden it can just let everything go and it's really beautiful.<br>
The fact that this is still working means that now if we start testing it for load do some sort of load testing or scalability tests we should see better results.<br>
With a few caveats that we're going to get to in just a minute.
|
|
|
show
|
1:33 |
Although I trust you can take the sun example and adapt it to the weather example let's go ahead and do that together.<br>
So over here we're going to say we have an async method.<br>
And again, this right now is a synchronous function.<br>
Let me just go over here and grab some aiohttp client.<br>
And we're going to re-implement this again, not request.<br>
And not response like that but like this.<br>
And this.<br>
Good?<br>
One more thing, async.<br>
Okay, so now this is an async method using async with and async await.<br>
And here, we should be able to go to this function and we don't get the data back, we have a coroutine.<br>
If we await it though, we get the data back.<br>
Alright, I think that's done it.<br>
Let's just test the weather as well.<br>
So there's the sun but if I change that to weather yep, also works.<br>
So it looks like we've converted from an entirely synchronous Flask based API over to Quart and what does that take?<br>
Maybe, maybe 15 minutes, probably less with me talking and explaining, poking around.<br>
If I just put my head down that could've been a 10 minute job, easy.<br>
Granted, pretty toy application but not entirely a toy app, right?<br>
It is calling other services it does have some reasonable structure with the blueprints and the config files and all that kind of stuff.<br>
So it's non-trivial even if it's somewhat on the small side.<br>
Hopefully you see this as pretty straight forward and pretty easy to do.
|
|
|
show
|
2:37 |
Let's review converting from Flask to Quart and going from a synchronous view or controller function into an asynchronous one.<br>
So, if you're not entirely familiar with Flask the way it works is we have these apps.<br>
This is a Flask app that we allocate and then we apply this decorator to set a route and it's just a URL and the data that gets passed on the URL, things like that.<br>
Of course, you can see we have a regular def sun a regular function so there's no asynchronous happening here.<br>
We're going to implement our viewer controller method put the logic here, and in this case we're using some other services.<br>
We don't want to just cram all that into one place we want to be able to reuse the ability to say convert a ZIP code and country into a lat and long.<br>
If we put those into their own services these themselves are also synchronous and what we get back is a dictionary called sun_data, and in order to show that to the API consumer as json we have to call flask.jsonify and boom we've received a web request we've interacted with some external services converted that into a dictionary that is converted to json and that is the heart of an API.<br>
And this is how you do it in Flask.<br>
With that in mind, how do we do it in Quart?<br>
Well, it's very, very similar.<br>
Again, we have the app.route, but remember the app here comes from a Quart app being created, not a Flask app.<br>
Then we add an async decorator or async keyword, rather, for this method.<br>
So we have an async def sun and that allows us to use the await keyword.<br>
Then, we take that same logic that we've hopefully upgraded to async capable by making get lat long and for today both async methods themselves.<br>
And then we can await those results and this is the key to the performance that Quart is going to unlock.<br>
While we're waiting on get_lat_long while we're waiting on for today instead of just going, well, we're busy so just process and request, don't bother us can't do more right now, we're all blocked up.<br>
Most of the time, what does this method do but wait on those two services and adapt, you know convert time zones a little bit?<br>
Not much, so this is really all our website does is wait on these services.<br>
And so why don't we make that waiting productive?<br>
Do the await here and allow other async methods to run while we're awaiting these.<br>
And that's exactly what we're doing with Quart and finally we call it quart.jsonify and quart.abort so I'm to return our data that we got back.<br>
Once the dictionary converted to json, boom now you have a more scalable API with very little effort to make that conversion.
|
|
|
show
|
2:00 |
So I said that now you have better scalability.<br>
You have better performance.<br>
Do you take my word for it?<br>
I wouldn't.<br>
I didn't actually.<br>
I said, okay, I'm going to convert this to Quart.<br>
Now, unless I see an improvement I'm actually going to not even cover it in this course.<br>
Spoiler alert, it's going to be better.<br>
But, how do you know?<br>
You want to do proper load testing.<br>
So, here's a tool called wrk, and it describes itself as a modern HTTP benchmarking tool.<br>
And you can see the URL right there at the bottom.<br>
So, you can go get this and install it and then use this to test your web app.<br>
Well, how do you get it?<br>
If you happen to be on macOS you're in luck.<br>
You can use Homebrew.<br>
If you don't know what Homebrew is, check it out at brew.sh.<br>
It's really awesome.<br>
That's the way I manage lots of things like Python and Node and all those types of things on my machine.<br>
MongoDB, for example.<br>
Install them and upgrade them with Homebrew.<br>
So, wrk can also be installed with Homebrew.<br>
brew install wrk.<br>
Boom, done.<br>
Now I know the stats on OSs that people use to work with Python.<br>
OSX, as they have here, or macOS same thing, combine it, and it's been renamed basically is a very small percentage.<br>
Even though it might appear that, you know go to a conference, everyone has a Mac I think it's like 15 to 20%.<br>
So that leaves a whole bunch of other folks who may want to use wrk.<br>
How do they get it?<br>
Well on Linux, on Ubuntu, you can go and check it out and compile it from source.<br>
I don't really like that answer.<br>
I don't really like that as an option but it's better than you don't get it.<br>
So, you can check it out and compile it.<br>
On Windows, the answer is a little bit less good than that not so good answer.<br>
And that is on Windows 10 you can get wrk because you have the Ubuntu Subsystem on Windows which you can turn on and then you can get wrk source and compile it there.<br>
Okay, so these are your options you have for the other OSs.<br>
But you don't actually have to run this.<br>
You can just look at the numbers that I'm going to show you in the next video and you can basically do the takeaways for yourself.<br>
But if you want to try it for yourself then here is a tool that I used and here's how you get it and install it.
|
|
|
show
|
3:16 |
What we're talking about with this wrk benchmarking tool is otherwise what's known as load testing.<br>
Let's hit the server with as much traffic and as many concurrent users as we can.<br>
Just keep ramping that up until it fails.<br>
Well, it turns out the way we've implemented this is we're not talking to a local database and then just sending responses.<br>
We're basically orchestrating external services.<br>
So by load testing our code we're going to end up load testing those services.<br>
Alright, the harder we hit our service the harder we're going to concurrently hit those services.<br>
Now either because those services can't take it or because those service just have built in rate limiting to not let you do that much processing that many concurrent requests, they're going to fail.<br>
And that is going to make it seem like our app is failing but it's only because we're hammering the external services they either can't take it or don't like it and then they fail on us.<br>
So that's a problem.<br>
How do we do load testing with these external services without getting into trouble by hitting them too hard?<br>
Well, you may have noticed this measured latency in seconds and if used cache data.<br>
That by the way is set right here.<br>
I'm not going to turn it on it doesn't matter right now but you can turn it on when we do the load testing if you want.<br>
You're going to need to turn it on or you're not going to get the right numbers more or less.<br>
So how did I come up with these numbers and what is this doing?<br>
So I ran some simple repetitive tests against this over and over and over and figured out how long does that operation right there take?<br>
One time it took this long and one time it took that long and you can see all of these numbers that's how long it took for this to be done.<br>
And I said okay well that's pretty representative at least from the West coast of the US.<br>
So lets just record those numbers and for load testing purposes we'll be able to go and actually just simulate those.<br>
So if we say use cache data we're going to simulate calling that thing.<br>
We're going to randomly pick one of the real measured latencies and then we're going to return some fake data just something I grabbed somewhere near Portland.<br>
I'm not sure exactly where that is.<br>
So if you're doing any sort of load testing you have to go into the config file you're using and set use cache data true or it's just going to freak out and you're going to end up load testing datasciencetoolkit.org which is not really what we want to do please don't do that to them.<br>
And it turns out it fails anyways so it wrecks your test, not great.<br>
If they're not explicitly rate limiting you maybe what they should be doing is also using asyncio and things like that.<br>
But anyway, you'll see this in each one of the services.<br>
So the lat long service has it the sun service has just some hard coded sun data.<br>
Exact same thing, here's the measured latencies.<br>
If you turn on this it just uses the asyncio friendly sleep and then to simulate the time that it takes to return the fake data.<br>
I want to make sure you're aware that because we're depending on these external services for load testing, you don't want to load test them you want to simulate what it would be like in a real system.<br>
Now granted you may not want to actually depend on them if they can't take your load testing in a real one but this is a toy course demo, right?<br>
No harm here.
|
|
|
show
|
3:33 |
Are you ready for the grand finale?<br>
Let's compare how our app performs when it was based on Flask and then how it performs now that we've converted it to Quart.<br>
So here's the command I'm going to use: wrk -t20 -c20 -d15s.<br>
And then I'm going to go hit the sun API.<br>
That one's the most complicated it does both location first and then the sun based on the latitude and longitude.<br>
So it seems like a good candidate.<br>
Now the t means threads I believe so 20 threads, 20 connections for 15 seconds pound away on this thing as hard as it can.<br>
Now let's see what kind of results we get.<br>
I still got 20 threads, 20 connections it says right below and it gives us some stats.<br>
Average latency 1.34 seconds, not great max is a little bit higher.<br>
Since we were able to do 71 requests in about 15 seconds it's okay, but notice that red line.<br>
That kind of sucks.<br>
65 requests timed out almost 50% of the requests we made timed out.<br>
I don't know how you feel about reliability but for me, if my app can only handle half the requests it's receiving and the rest are timing out or failing there's something badly wrong with that web application.<br>
What's one way to deal with this?<br>
Well besides rearchitecting a cache and things like that we can get more machines, we can get a bigger machine we can scale out, we can get a load balancer all sorts of crazy infrastructure solutions.<br>
That's one possibility we'll see another one in a minute.<br>
And notice the overall one here is 4.72 requests per second but remember half of them are failing with timeout that is not super amazing.<br>
This was our original app.<br>
What do we get with Quart?<br>
Ooh, a couple of things are better.<br>
First notice the red line is gone 0 errors, 0 timeouts.<br>
Now the latency for each request is about 944 milliseconds.<br>
Remember that green bar, we can't make it faster.<br>
This async stuff does not make it faster it just means you can do more stuff while it's happening.<br>
So we have 20, effectively 20 independent users hammering as hard as they can.<br>
Now that doesn't mean there's 20 real users alright, that's 20 aggressive, mad users requesting as hard as it can.<br>
Like a regular user may be, when they're on your site does request every 15 to 30 seconds, something like that.<br>
So this is a much, much higher load then say 20 actual users.<br>
But nonetheless, that's sort of what we're hitting it with these 20 threads.<br>
So notice all the timeouts are gone we can do 311 and look at that 20 requests per second, each request takes about one second.<br>
That's as fast as it can go with this many threads and connections, right just each thread is getting served as good as it could.<br>
So that's a really, really good thing.<br>
So you can see we've done much, much better on exactly the same hardware.<br>
We've ended up scaling much better.<br>
Our requests are not that much faster, right it's not ultra fast or anything like that.<br>
We can do so much more of it because most of what we're doing is waiting and while we're waiting we'll just go and start another request and wait on it to get back from the service.<br>
Things like that, right?<br>
So a final note here if you do this yourself and you just type Python app.py or run your app you're going to get something disappointing with Quart.<br>
It's going to look more like this.<br>
It's not going to look like what you want.<br>
Why?<br>
Because if you just run it regularly you're going to get a WSGI server a serial, not a synchronized server.<br>
You need to run it on Hypercorn so we'll talk about that next.
|
|
|
show
|
1:41 |
So when we talked about the performance and profiling and load testing previously, just the previous video I said you have to run on an ASGI server.<br>
WSGI, traditional Web Service Gateway Interface that's how Django, Pyramid, Flask, all of them work.<br>
They're all based on this.<br>
Basically the underlying web API that integrates these frameworks into the server those are serial.<br>
So there's no way to do asynchronous programming or execution for those frameworks at all.<br>
So in order to actually get the scalability and to actually execute our code on asyncio event loops you have to use what's called as ASGI server.<br>
An Async Service Gateway Interface something to that effect.<br>
So you can use Hypercorn.<br>
Hypercorn comes when you pip install quart you get Hypercorn, this is an option.<br>
It says you don't type run.<br>
You know, don't like just run this here.<br>
What you're going to do instead is you type hypercorn module name and then app name that you want to run, okay?<br>
Also lists some others down here, Uvicorn.<br>
We talked about uvloop based on that, right?<br>
And some of its capabilities.<br>
So you can see Hypercorn is pretty awesome.<br>
I believe it's based on Gunicorn much like Uvicorn is as well and I honestly don't know enough about them to like help you decide between one or the other but this one looks like it has more features.<br>
That seems good.<br>
Make sure if you do any load testing or you do this in production that you run it on an ASGI server or you're basically going to get exactly the same as what you had with Flask and if that's what you're getting you might as well keep the more well-known well-tested API, right?<br>
Be sure to use one of these servers.
|
|
|
|
30:37 |
|
|
show
|
1:31 |
It's time to take a different perspective on performance and parallelism inside of Python.<br>
So far, what we've done is we've stayed entirely focused on our Python code in the constructs within there Asyncio, threading, multiprocessing and so on to add parallelism.<br>
And, that's a really good place to be.<br>
I would recommend you spend most of your energy and time there.<br>
It turns out we can also integrate with extra libraries especially in C, and as you probably know C can do anything.<br>
Our operating systems are generally written in C so C is super low-level these days and is very very good at performance and parallelism.<br>
So there might be reasons to think about writing C code and integrating that with our program.<br>
So, here we are and do things faster.<br>
This has two factors that multiply your performance in really interesting ways.<br>
One, even if we don't do any parallelism you'll see that converting certain parts of our program to C will make it go way, way faster.<br>
You'll also see that we can escape the Gil in C which means that we can go even faster.<br>
So we can do basically what we do with multiprocessing but in a single process and do that faster as well.<br>
So there's this double multiplying effect of our performance.<br>
It's not that I would say jump at first but if you have any really performance critical system you might think about some of the techniques in this chapter.
|
|
|
show
|
1:45 |
When you talk about Python in performance it's really interesting because Python code itself is kind of slow compared to languages like C#, Java, definitely C++, things like that.<br>
So, you say well this code is slow.<br>
But you can actually write a whole bunch more functionality with way fewer bugs really quickly.<br>
And then you can try to make it faster.<br>
A lot of the stuff we talked about with parallelism it lets us do many things faster and if you're waiting on other systems, perfect.<br>
Maybe though, you're working with something computational.<br>
You might bring in some library like NumPy for data science or numerical computations.<br>
And that really mixes up the performance because the internals in NumPy are written in C.<br>
And it's highly optimized.<br>
So, maybe you're version written in C would actually be slower than Python's version using NumPy.<br>
I don't know.<br>
This is a hypothetical, right?<br>
Another way to think about this is certain parts of your Python code are really critical and most of them aren't.<br>
So, if you think about SQLAlchemy there's a little tiny internal bit that is written in C that goes really, really fast and then the rest of it you'd do in Python.<br>
But that's not the slow part.<br>
The slow part is actually not in Python, its in C.<br>
So, this Python, C integration is really interesting and really important.<br>
Now, you may be thinking, Micheal.<br>
I either don't know C or C++ or I hate working in C and C++ that's why I'm a Python developer.<br>
Fine, I'm with you.<br>
It's been a long time since I been a professional C++ developer.<br>
A really long time.<br>
What we're going to talk about here is actually how we can take advantage of this performance and integration that we get with Python's great compatibility with C without actually writing any C code at all.<br>
Sounds perfect doesn't it?
|
|
|
show
|
3:00 |
Okay, okay I hear you.<br>
You either don't want to write C, you would rather avoid writing C, or you don't even know C.<br>
Great, you can still write really awesome code with your Python knowledge using something called Cython.<br>
Now, Python officially is known as its internal runtime what's called the interpreter sometimes is known as CPython.<br>
That's because the interpreter, the runtime is implemented in C but you take regular Python code and it is interpreted on top of it.<br>
Cython is unrelated to CPython even though they differ by only one letter.<br>
Cython is an optimizing static compiler for the Python programming language.<br>
And what does it compile to?<br>
Well, it first compiles to C and then C compiles to actual machine instructions for your operating system.<br>
It's as if you had written C code but the syntax you had to write and the libraries you get to use are Python.<br>
It's beautiful and it makes writing C extensions for Python as easy as Python itself and you can bet it actually has some threading implications along the way.<br>
So, why would we do this?<br>
Well, writing C, we already talked about some of the advantages there but calling them out explicitly we have, you can write Python code that at any point can call back and forth between native C or C++ code.<br>
So if you want to do any integration with other C code or bring that into your system, guess what?<br>
You can do that in Python back and forth.<br>
Not with some weird integration layer but just as if you were using that library directly.<br>
You could easily take Python code and convert it to high performance C code by just changing it a little bit by adding static type declarations.<br>
You get integrated debugging, so you can debug from Python to Cython to C and back.<br>
That's pretty awesome.<br>
You can interact effectively with large data sets.<br>
Cython actually comes from the computational numerical analysis side of Python and the mathematical spaces and so on.<br>
So it has good support with things like Numpy which also, as I said, has big parts of it in C.<br>
So why do you need to filter all of that data through Python to get it over to the Numpy C stuff?<br>
Just work directly here and you can get some really good performance.<br>
Because Cython can interact with the libraries from CPython, you can pip install some random library and use that.<br>
All of the magic and power of CPython's ecosystem is available to your what is effectively C code in Cython.<br>
So that's pretty awesome.<br>
You want to use requests from Cython, no problem.<br>
Finally, you can integrate natively with existing code.<br>
Is there some C library that you would like to use but you want to write in Python and how do you link those together?<br>
Or do you have some big application that is written in C?<br>
Well this is a really easy way to bring that into Python.<br>
So these reasons and more are why you might be interested in Cython.<br>
There's a lot to it but simple use cases pretty simple and we're going to get some really cool performance outcomes from it.
|
|
|
show
|
2:26 |
I'm guessing most of you have never written Cython code.<br>
You might not even know what Cython code looks like.<br>
Maybe if you saw it you could tell me okay, I think that's not Python, it might Cython but it turns out the language is slightly ever so slightly different.<br>
So, let's look at its syntax.<br>
And here's the example we're going to work with.<br>
We're going to do some computational stuff here.<br>
The function is called do_math.<br>
It takes a start and the number of times it's going to increment from there.<br>
And we've seen this before when we did our threading and our multiprocessing.<br>
It's just a silly math function that does useless math but it lets us do performance testing and parallelism testing and things like that.<br>
It's using Python 3.5's type annotations.<br>
So, up there we have start:, num: and so on but of course we could omit those and things will still work just the same.<br>
Right, so this is pure Python, this is not Cython.<br>
I'm going to show you this function converted over to Cython.<br>
You ready?<br>
Keep your eye on it.<br>
There's the Cython.<br>
There's Python.<br>
There's Cython.<br>
Two changes, one, we have more type annotations so start in the argument there is no longer an integer it's a Cython int.<br>
In Python, in CPython, integers and numbers and stuff they're still basically objects on the heap.<br>
They're not allocated on the stack as four bytes or eight bytes or whatever the size of these are.<br>
They're actually allocated in the heap and there's pointers, and that really slows down math and adds a lot of overhead.<br>
So we can explicitly say that start and num are Cython integers and that means they're going to be allocated on the stack in C.<br>
And then we have three local variables which we had before but we didn't explicitly say the type.<br>
Here we're saying explicitly that's a cython.float.<br>
cython.float, cython.float.<br>
And then, we're doing our while loop exactly the same.<br>
So that's the only change.<br>
We've done a little bit of type annotations and we're using a more high performance square root.<br>
We were using math.sqrt before which is Python's standard library.<br>
Fine, and that would still work in Cython but it turns out to be slower and it prohibits one of the techniques we want to apply later.<br>
So we have this libc.math that actually has sqrt and a bunch of other math operations that you might want to do.<br>
So we're going to use Cython's built-in more high performance math operation.<br>
That's it.<br>
I'll flip back and forth a couple times for you one more time.<br>
Just notice, just a few more type decorations and a different square root.<br>
Pretty sweet, right?
|
|
|
show
|
5:36 |
Where else would you start with Cython other than Hello World?<br>
And for our Hello World I want to decouple things just in a little bit.<br>
Over here we have our Hello World folder in the Cython part of our GitHub repository.<br>
And what I want to do is create some extra library this library we're going to Cythonize going to convert it to native code through Cython.<br>
So we'll call this the greeter.<br>
Going to have a method called greet.<br>
And what do you think it's going to do?<br>
Somethin' to this effect.<br>
And that's pretty straightforward right?<br>
And we're going to import that over here and call it.<br>
Now right now, if I do this import greeter, and we'll say somethin' like this.<br>
The greeter we can greet with their name.<br>
So far there's nothing to do with Cython at all.<br>
Let's run the program and see what happens.<br>
What is your name?<br>
My name is Michael.<br>
Hello Michael, and then I printed out the response which actually is None.<br>
There we go, that looks correct.<br>
So what I want to do is convert from using Python to Cython.<br>
Convert from using interpreted code to native code for this.<br>
So there's two steps to do that.<br>
First thing, we're going to call out a pyx file.<br>
Notice it's got like a big C with a Python icon right there in the middle rather than a standard file with a Python icon on it.<br>
So let's see, does it still run?<br>
No there's no greeter, not yet.<br>
So how do we make the greeter?<br>
There's two steps.<br>
First we have to compile it and then we just use it.<br>
In order to do the compilation we have to install Cython so pip install cython and have a setup file.<br>
So let's go and make sure we have a requirement file.<br>
And it's going to be cython.<br>
Great, Cython is installed and we have to tell PyCharm it's not misspelled.<br>
That's a little annoying but, no big deal.<br>
So in here we're going to write a simple little bit of code.<br>
We're going to import setup and we're going to import from Cython some build tools so we'll say from distutils.core import setup.<br>
It's kind of like we're creating a package like a Python package but this is just a tiny bit different.<br>
Then we say from Cython.build import cythonize.<br>
It's all we have to do then we write or we call setup like so and we say ext_modules=cythonize() and then we give it the file name, so greeter.pyx.<br>
Okay everything's good now we have to run this so let's go over I've already opened a terminal here with the right virtual environment activated.<br>
So now what we have to do is, let's actually make sure our Python cache is empty as well.<br>
So what we need to do is we need to run Python setup and then we have to give it a special command build_ext --inplace.<br>
Again this assumes you've installed into the active virtual environment, Cython.<br>
This is a good sign, we have greeter and now if we look here we have greeter.cPython 37 on Darwin.<br>
Darwin is the platform name of macOS.<br>
Alright let's just try this again.<br>
What is your name?<br>
Oh wait a minute, that didn't crash this time my name is Michael.<br>
Hello Michael, how cool is that?<br>
So we're using Cython.<br>
How do I know?<br>
Well let's go over to our greeter and print somethin' like this, running from and we'll put out the file name there.<br>
So most modules you can just say __file__ like this.<br>
Now we need to recompile.<br>
That did not compile but that may, here we go.<br>
Now if we run it again, there's Michael.<br>
Michael and we're running from big long thing here but notice this we're running from that compiled output right there.<br>
That is native code.<br>
How do I know?<br>
Well let's look at the intermediate here.<br>
Notice the scroll bar.<br>
That is a lot of C a lot of C right there, wooo!<br>
Let's go and look for Hello.<br>
Like here you can see some of the string literals that we are using that got pulled out as static constants in C.<br>
That's pretty awesome right?<br>
So that's it.<br>
We have our temporary C output and we have this .so file in this build directory all of that stuff is just produced output from this to run it.<br>
Source files include just our program that's going to use the model and notice this Python code did nothing to say hold on we're doing weird Cython stuff so go import a Cython thing so just know there's a module called greeter.<br>
We're going to import it and if we go here it has a greeter.<br>
then the auto-complete it's gone but it has a greeter.greet okay?<br>
And we also have a setup that simply calls setup sets the ext module to cythonize the particular Cython modules that we're going to use and that gets compiled with this command line right there.<br>
And notice if there's no changes it sort of caches the output so it only builds what's changed.<br>
Alright well, hello Cython.
|
|
|
show
|
1:11 |
Let's quickly review how we can use Cython to write native code, and then import it and run it in Python.<br>
So, all we have to do is create a pyx file this is the Cython extension by default and then we write standard Python code.<br>
It could be plain Python, like we have here in this top box or it could be specialized code like I showed you in the example where it talks about the types in terms of native Cython types and so on.<br>
And then we have to have a setup file so we import setup and we import cythonize and then we just call setup and set the ext_modules to include that one that we're working in above and then we just make sure we have Cython installed.<br>
So pip install cython, and then we run Python setup.py build_ext --inplace.<br>
That builds it, out pops a high dot platform name version name, et cetera, .so or depending on what platform of Git your on, you might get a different output there.<br>
And then you can just import high like you could any other module as if that was a Python file itself except for, now it's running native C code that's been compiled by being translated with Cython from Python into C.<br>
Pretty awesome.
|
|
|
show
|
2:46 |
Now that we know a little bit about Cython and how to use it, it's time to take the Cython power and apply it to concurrent parallel programming apply it to threads, and you're going to see how Cython first just speeds up the code, period because it's C and not Python and then breaks us free from the GIL so we can go even faster.<br>
There's just a handful of concepts that we got to learn to convert the code we've already written to extremely high performance C code.<br>
Now let's go back to this computed useless math thing that we're doing.<br>
Right here is our do_math, and remember, we have let me again put the little digit grouping things in here so you can tell more easily.<br>
We're asking this little math function to increment an integer and to do some square roots and multiplication and subtraction 30 million times.<br>
Now, turns out for 30 million times this is actually pretty fast.<br>
Let's run it.<br>
7.6 seconds.<br>
Yeah, that's good.<br>
I mean, we did 30 million things actually way more than that, so impressive but we can do it way faster.<br>
So this you've already seen, and we talked about this in the threading section in the multiprocessing section, and so on.<br>
So we said, well, if we'd run this in a threaded mode on 12 processors, remember how awesome this computer is?<br>
It has 12 cores.<br>
Maybe cores is a better word than processors.<br>
Doesn't really matter.<br>
It should get faster.<br>
Oh, about the same.<br>
I threw in a little factor for these so you could tell based on some standard, running this a few times how much faster or slower.<br>
So the threaded version's about the same.<br>
This one, do the multiprocessing way better.<br>
Yes, it's 1.79 seconds, 4.7 times faster.<br>
That is a big improvement.<br>
Can it get better still?<br>
So that's our goal.<br>
Our goal is to take this code.<br>
Actually, we're going to take the threaded version here the threaded version, and that's using 12 threads 'cause there's 12 cores, and it's trying to run it and we saw that this one actually was almost exactly the same speed as just the serial one.<br>
We saw with multiprocessing that we can get 4.7 times faster but why again is this threading one not helping us?<br>
It's not helping because all of the execution all the math work that we're doing is a series of interpreter instructions in CPython.<br>
The GIL tells us that one instruction at a time can run period, regardless of how many threads or things like that are running.<br>
So this is clogged up.<br>
It can't go any faster with threading but that's because of the GIL.<br>
What if we could use Cython to make this happen in C and break free from the GIL?<br>
Well, it'd definitely be on, wouldn't it?<br>
And it turns out we are going to do that next.
|
|
|
show
|
1:40 |
Now, we're going to take this program and make it faster by using Cython.<br>
And we saw in the threaded version we're calling do_math and that's not actually helping.<br>
But we did try to apply threading to the do_math operation and break it into segments to see if that would help.<br>
And with Cython it will.<br>
But let's just take a step back for a moment before we get into all that and say "How do I know where my program is slow?" If you're going to rewrite some part in Cython don't do the whole thing just pick the one little part that really needs attention.<br>
How do you know where that is?<br>
Well, if you have Pycharm Professional you can run a cool in IDE tool.<br>
If you don't, you can go look into CProfile and see how to actually to that in Python on the command line.<br>
But I'll show you how to just quickly do it in Pycharm Pro.<br>
Come over here and you say profile this is not in our parallel one this is just the plain one.<br>
Let's ask, where is it spending it's time?<br>
Well, here it shows you all the operations it does but check out the graph.<br>
Does anything stand out there?<br>
Is something maybe a little red?<br>
Let's go look and see what's going on there.<br>
Well look at that, we're spending 1.056 seconds on computed, and of all that time all but 2 milliseconds are being spent in main, all of those 1054 milliseconds are being spent in do_math.<br>
So if we're going to make our code fast we don't need to make everything fast it's just this one.<br>
Right?<br>
So if we navigate to source, well that's the function we knew we we're working with that's where it's going to be slow.<br>
In a real program, this is the type of thinking that you can go through.<br>
Show me where it's slow.<br>
What's the worst case scenario?<br>
Ask yourself the question "Could this be fixed by switching to Cython?"
|
|
|
show
|
2:19 |
Alright to make our math go faster we're going to go First let's go to the file we have named over here.<br>
Now this is an exact copy of the threaded version.<br>
Remember the one that's barely better at all?<br>
And it has this math part here but let's take this and put it somewhere else.<br>
I'll call it math_core, something silly like that, pyx.<br>
And in here we're going to put that and in order to make this work, we have to import math.<br>
So let's comment that out and come over here and say...<br>
We're going to import math_core and we'll do math a couple times.<br>
Let's run this one.<br>
Now we've done nothing with Cython.<br>
Actually it's not going to find it.<br>
It's just going to crash, there's no math_core.<br>
It would run the same speed as the threaded one if we hadn't compiled it, right?<br>
So this is not anything to do with converting it to Cython yet.<br>
This is just restructuring it so it's actually in a Cython file but we're not changing the syntax to really take advantage of it.<br>
So let's just rob from what we did before.<br>
We need a setup file, we know about that.<br>
So when I go over here And now we need a math_core, we know about that.<br>
And I've changed directory over here so now we can say, "Python, build and place again." Now, Now if I run it.<br>
We're going to run this on Cython, if it runs at all.<br>
I told you Cython is awesome cause it breaks free from the GIL.<br>
So this may go faster, actually dunno.<br>
I have no idea what's going to happen here when I run this.<br>
I think it will work.<br>
I don't know how much faster it will be.<br>
Let's find out.<br>
Huh, well it's faster that's cool.<br>
Remember we had a 1.07 factor.<br>
a 1.07 factor for the Python-threaded version.<br>
And now we got this version here that's faster but not that fast, why?<br>
Well, the GIL is actually still operating here.<br>
The GIL is still in place.<br>
So what we need to do is we're going to go and apply a technique that will explicitly factor our code into the part where the GIL is required and a part where there's no GIL required cause it's effectively C.<br>
If we indicate that using a Cython syntax well, then we're going to break free from this blockade that we have because of the GIL.
|
|
|
show
|
4:06 |
We're over here in our Cython file and we can see that it didn't speed things up that much.<br>
And I said that's because of the GIL.<br>
If we could just run this part in parallel like, that's where almost all the work is.<br>
Things would be golden.<br>
So let's try that.<br>
So we can come over here and there's a cool syntax in a context manager.<br>
We can say with no_gil:.<br>
Is that all it took?<br>
Like, are we free of the GIL?<br>
We just got to say no_gil?<br>
Not so much.<br>
Let's save this and then recompile it down here.<br>
Darn it, thought it was going to be so easy.<br>
Operation not allowed without the GIL on line 9, column 42.<br>
Line 9, column 42.<br>
So what are the rules with this no_gil?<br>
Well, the rules are you cannot interact with Python objects.<br>
You can convert them down and then use them in Cython but once you get to the no_gil section it's got to be all C.<br>
And right now that's a Python number type.<br>
So what we need to do is say, no, no, no this is a cython.int.<br>
We can import Cython up there.<br>
Now in pyterm it gives you this little warning but just ignore it.<br>
I believe we can get away with ignoring it.<br>
Got that, and again, up here, we got to do that for all of these values.<br>
We're good.<br>
Nope, we're not good.<br>
Cause I have that backwards for my default.<br>
There we go, now we're good.<br>
So we still have these little warnings but let's see what happens now.<br>
Error.<br>
Converting to Python object without a GIL.<br>
And where is this happening?<br>
1235.<br>
Oh, I made a mistake in the import.<br>
That's what's not working.<br>
So, a couple things.<br>
This is not regular import, this is cimport a Cython thing, and we're going to say .math.<br>
OK.<br>
Now, that should make it work.<br>
Look at that, it compiled, and now we have a math_core a new one, and all of this work which is where almost all the work is is now going to operate without the GIL.<br>
Let's try it one more time.<br>
Remember the speed-up we got, maybe it's still here.<br>
It is, perfect, 2.5 times speed-up.<br>
Can we do better?<br>
Give it a shot.<br>
Look at that.<br>
Oh my gosh.<br>
5,596 times faster.<br>
Not percent, times.<br>
Now, I want to caution you about one thing really quickly here.<br>
You might think, "Alright, what we can do is I can just treat this like Python." And in Python you don't think about numbers, very much.<br>
If we go over to our do_math, right you can keep making integers bigger and bigger, and bigger, and they can basically be as large as you have memory and patience.<br>
But, in Cython, these are C integers.<br>
Remember C integers are just 32 bit things.<br>
They overflow really easily.<br>
So if you tweak these number around too much let's actually take this number down a little bit just to make sure we're not overflowing the available numbers here.<br>
And I'll compare it against the serial one with the same amount, what do we say, 30,000?<br>
300,000.<br>
So let's run it one more time here.<br>
.09.<br>
There we go, that's more like it.<br>
So 56 times faster.<br>
I think we might have actually been overflowing that integer, which is not great and then when you do this is less than that all the sudden you increment it enough to overflow it and then it swaps around, right?<br>
If you're not familiar, if you overflow an integer it basically becomes negative, right?<br>
The next time you add a number to it add a one to it, instead of just getting bigger it flips to its smallest possible value which is like negative, I don't know, 65,365 or who knows what this turns out to be.<br>
OK, so this should be a little more accurate here.<br>
What you see, it's still a massive, massive speed-up.
|
|
|
show
|
2:53 |
Now, looking at this timing here I think the times are so incredibly small that the stuff we're doing around the edges is actually starting to show up.<br>
So, I tweaked things just a little bit.<br>
First of all, I'm still concerned these numbers might overflow, so I switched them all to float, okay, float, float, float and they're much less likely to do that there.<br>
Then over here, I said we're taking all this time to create the threads, and then then, you know, we had this time starting like way up here, so, I decided like let's create all the threads and then start them, and the second they're started, start the time, okay?<br>
Cause, now we're going to wait and then we're going to print out the time here.<br>
Because, I didn't see as much of a change between the serial version and the main one.<br>
So now, now, if we run exactly the same amount and we don't do this sort of, especially this stuff like getting the processor count, and so on.<br>
Now, if we run it, now we have a really, really sweet performance increase here.<br>
Let's actually add one more zero.<br>
Make that 3,000,000.<br>
One final time on this one as well.<br>
Get our new baseline number.<br>
So, 80, I'll put 80 here.<br>
Now, we can run it, and see what we get.<br>
Whoops, If you're on the same one you get the same number.<br>
Let's run the Cython line one more time.<br>
There we go, look at that, 2,000 times faster.<br>
2,000.<br>
2,200.<br>
That is so awesome.<br>
Let's just make sure that this parallelism is having some effect, so what if we go over here and we say only use six cores instead of twelve.<br>
That may make a difference.<br>
It's a little slow right?<br>
Actually, almost half but if we only use two cores?<br>
Three hundred, three hundred.<br>
So, you can see the fact that we're doing threading It's definitely getting faster and faster by using threading, I mean we still have zeros all across the board but somewhere in there are milliseconds, or microseconds, or something like that that we're we're tracking here.<br>
So, just wanted to, You know, we're going so fast that like, the getting the processor count and actually allocating the threads that really starts to impact our performance, right?<br>
And even if you say well, we're going to consider the starting of the threads, right, it's still four hundred times faster than the CPython version.<br>
Really, really a big deal.<br>
And I don't have my divide up there, do I still, no.<br>
Yeah, 416 times faster.<br>
500 that time almost.<br>
How hard was it?<br>
Well, we took the one function right here that was a little bit slow, and we're doing most of the work, and we converted that to Cython but most of our program, all the stuff that you've learned about, threading the regular methods, while, you know, for loops, everything.<br>
It's all the same, it's unchanged.<br>
We can use exactly the same program.<br>
We just took the one little hotspot and replaced it with a Cython implementation.<br>
It's really nice, isn't it?
|
|
|
show
|
1:24 |
Close out our chapter on Cython.<br>
By looking at this concept of the no_gil operation.<br>
So in Cython, you can go and say I want to create a block of code and in this block of the code, I'm telling Python I don't need the GIL.<br>
You can release it, during this section.<br>
Now, if we can just say that everywhere well maybe the GIL would just go away.<br>
But as we saw, that is not allowed.<br>
There are rules when use the no_gill.<br>
And one of them is, you cannot interact with CPython objects.<br>
So these numbers we work with they have to be pure integers or floats.<br>
In the C world, they can't be pointers back to the actual CPython version for example.<br>
And the place where that became a problem was we were using math.sqrt.<br>
It accepted a CPython number in which case we had to do a conversion from our integer or float into CPython.<br>
Well, that wasn't working, right?<br>
That wouldn't compile.<br>
You cannot do a conversion into a Python object in a no_gill block.<br>
So we had to do things like, use the libc.math and do a cimport for square root, and things like that to make sure we're staying in C land while we're there.<br>
But if you can do that you really can break free of the GIL.<br>
And we saw that made our code much, much faster and take advantage of the processors using pure threads in Python which is really quite awesome, isn't it?
|
|
|
|
17:58 |
|
|
show
|
0:35 |
Well, how about that you made it to the end and there it is, the finish line, you've crossed it.<br>
You now wield the dark arts of concurrent programming.<br>
It's great to have a skill of I now know how to write concurrent programs but I think it's even more important to have a wide survey of all of the options of concurrent programming and being able to choose between this type of solution versus that type of solution at the right time.<br>
And I hope that's what you've gotten out of this course.<br>
Let's go real quickly and review each of the major chapters that we covered and review what you've learned.
|
|
|
show
|
2:01 |
We begin the course by talking about why you care about asynchronous programming.<br>
We focus on two core areas.<br>
One, taking advantage of modern CPUs and the other is doing more productive things while we're waiting.<br>
On the CPU side I showed you this graph from Geoffrey Funk's presentation.<br>
It shows Moore's Law at the top but the part that we care about if we are not writing in current programs is that blue line.<br>
In around 2005, that's just flattening off and maybe even turning downwards for say energy conservation reasons.<br>
So, the only way to stay with the red line and not get sucked down on the blue line is to take advantage of concurrency.<br>
So, you want to follow that black line by leveraging the multiple cores.<br>
We saw that this machine I'm recording on now has 12 cores, so, if I write single threaded Python I'm getting 8.33% of the capability out.<br>
So, obviously that's important.<br>
Now what are the two ways that we can actually leverage this?<br>
Remember, the GIL means threads don't help or work.<br>
asyncio is single threaded anyway so it doesn't help at all so it's really down to multiprocessing or Cython's C-based solution of no GIL to break the Python threads free.<br>
If you want to take advantage of modern hardware you need to write concurrent code and it's the two main ways that I just talked about that will help you do that in Python.<br>
Maybe even more common than trying to make a single computation go faster is to just do more at the same time.<br>
This could be your web server or you're doing some sort of interaction with external systems like your web scraping or something to that effect.<br>
So we saw that with asynchronous programming we can take what is a long request but mostly a request that is waiting on a database waiting on a web service call or combinations thereof and turn those into times where we can stop working on that request while it's waiting and go handle the next one almost instantly so we saw that if we're able to leverage asyncio in our web frameworks we can do much, much more with the same hardware and the same web servers.
|
|
|
show
|
1:04 |
Open this course with a quote about what is concurrency and what is asynchrony in computer programming from Wikipedia, specifically to highlight that it's not just about threads.<br>
It's also about multiprocessing but it's also about things like asyncio that's cooperative concurrency.<br>
So remember, we have one main thread of execution we have a bunch of different tasks and we're going to break those tasks into little tiny slices.<br>
Here they look kind of coarse grained but imagine we're just way zoomed in.<br>
And we break the task into different pieces and we'll do a little bit of one, a little bit of other a little bit of another, and we interleave these while say the green task maybe is going to go talk to a database so while it's talking to the database we can run the first part of the pink task.<br>
We get a response from the database to want to call a webservice on the green.<br>
Well let's go try a little blue, things like that.<br>
So we're able to come along and just run all of these tasks by interweaving them, because mostly what they're doing is waiting on some external system, waiting on io.<br>
So this is the heart of asyncio and the async and await keywords in Python.
|
|
|
show
|
1:19 |
In contrast to the cooperative nature of asyncio type of concurrency on a single thread thread based parallelism lets the operating system decide when our code gets to run.<br>
We have a single process and that process has a main thread which may kick off additional threads spawn a couple additional pieces of work and then wait for them to complete and keep on running.<br>
And the important thing is it's up to the OS to figure out when a thread runs, not up to our particular process.<br>
Although the GIL does have something to say about it doesn't it, so here's the mental picture for threads.<br>
Here's the programming model, so we're going to start with the built in threading library.<br>
There's no external things to install here.<br>
We're going to have some function we want to run asynchronously but this is just normal Python code.<br>
It doesn't do any sort of async await or stuff like that, it's just code and instead of running on the main thread, we're going to run somewhere else.<br>
So given this, we'd like to create a bit of work that's going to run it so we set up the targets the arguments and if we want it not keep the process alive or be canceled more easily we can say it's a daemon thread.<br>
And then we just start it, potentially do some other work while it's running, or start other threads, things like that and then we're going to just wait for it to complete so we say work.join.<br>
Of course we can give it a timeout.<br>
We were just saying wait forever until it finishes.
|
|
|
show
|
2:16 |
Once you start working on threads, you need to be really careful about thread safety.<br>
One rule of thumb is share as little data between threads as possible.<br>
That's not always possible or even useful.<br>
At the heart of this thread safety problem is even normal functions, normal serial functions they have to take our program and evolve it from one state to another, and that often means changing different parts of our program putting those all into some new state.<br>
In going through that process, there's no way to avoid entering temporarily invalid states.<br>
So we have a function call, it's going to do a little work, it's going to change the state of one of our objects, do a little more work change the state of another one of our objects and it's done, going to make some final changes that make the entire system consistent again.<br>
So we start the function call, it goes through those transformations and then when we get to the end, everything is good.<br>
So what's the problem?<br>
Remember, the problem is in serial code well, there is no problem.<br>
But in concurrent code with threads, we could come along here, this thread could get suspended the other thread could come along and look at that red object and the blue object at the bottom and say, "Oh, this must be what "the values are," and go and run with it.<br>
Doesn't matter that it's put back.<br>
It's already used that to make a decision and it's off to the races to make a bad decision do something wrong.<br>
So we must make sure when our apps go through this temporarily invalid state, other threads cannot come and see it.<br>
We have to put up a little privacy wall.<br>
And so that's what thread safety is primarily about.<br>
So if we're going to do this, probably the best way to work with is what's called a reentrant lock.<br>
So import threading, create a lock based on an RLock.<br>
Remember a regular lock is not reentrant.<br>
That can be problematic, potentially.<br>
So we're using RLock and then we just say with that lock and then we do those potentially unsafe operations, and by unsafe I mean we're entering into this temporarily invalid state.<br>
And we don't want other things to see it so this with block, that's like our privacy wall for the data that we're manipulating.<br>
Once we get it all back in the right shape we can release the lock and other parts of our app can go and work with it.<br>
So this is all great.<br>
Remember the other thing we spoke about was if you're taking multiple locks at the same time if you take them in different orders you're going to end up in a deadlock, so you have to have some mechanism to take locks in the same order all the time if you're taking multiple locks.
|
|
|
show
|
2:13 |
If you're trying to do computational work you would like to take maximum advantage of all the CPU cores.<br>
If you open up your system information and look at your process usage you would like it to look like this if you're actually trying to do hardcore computation.<br>
However, remember the Python GIL.<br>
If we create multiple threads the GIL blocks all the threads except for one while it's running.<br>
And this is primarily to make memory management faster and easier for the single threaded, most common use case.<br>
But it does mean threads don't really solve the problem.<br>
So, what we're going to do to get around the GIL say you know what, we're not going to run more than one thread per process but let's just start a bunch of processes.<br>
Yes, they all still have the GIL but the Gil's not stopping them because they're all single threaded.<br>
So, multiprocessing is to take the concurrency and spin up a bunch of different Python processes feed little parts of work to them and then get the result back as if we're using threads or some other form of concurrency and this entirely sidesteps the whole GIL problem.<br>
So, this is the most fundamental, straightforward way to take advantage of multiple cores and modern hardware in Python.<br>
How do we do it, well, here's the code.<br>
Probably the best way is to use the multiprocessing pool.<br>
So, we're going to start by creating a pool and notice we say processes equal four.<br>
If you leave that empty, if you just say pool with taking the defaults, it's going to create as many processes or set that process count to as many processes as you have CPU cores.<br>
So, on mine that would be 12 which would probably be too many for what we're doing here.<br>
Next, we're going to start a bunch of operations with async work.<br>
Here we're processing a bunch of operations from zero to 400 and breaking them into four 100 piece segments zero to 100, 101 to two, 200 to 300, and so on.<br>
I guess maybe that should be 201.<br>
Anyway, you get the idea.<br>
So, we're going to break our work up into little bits feed it off of the different processes and then you have to call close and then join.<br>
Well, you should call close for sure.<br>
If you want join to work properly you have to call close first.<br>
So, this basically starts all that work and then says, we're not going to submit any more work now let's wait for what we have submitted to be finished and this is how you do multiprocessing in Python.
|
|
|
show
|
1:44 |
We saw that the API for multithreading and the API for the multiprocessing although the words sound similar and the actual behavior's somewhat similar the API is really not very similar.<br>
They're close, they're maybe isomorphic.<br>
I could convert from one to the other pretty easily.<br>
They seem to have most of the functionality that you might need on both but they're not exactly the same.<br>
That means in your code, you have to commit to I'm writing against the thread API or I'm writing against the multiprocessing API but it's not easy to switch.<br>
So enter the executor.<br>
Because it's not easy to switch when you use that API but there is a new, better way called the pool executor.<br>
So here we're going to the concurrent.futures module which is part of standard Python.<br>
It's nothing special you go get and we're importing the ThreadPoolExecutor and I'm giving it a name here, which is nice.<br>
Because that lets us choose our implementation.<br>
So if we write it like this we run our code below we're going to run a bunch of work and getting the titles by downloading from the URLs, we're going to do that on threads.<br>
But with a simple import change to the ProcessPoolExecutor we're now doing that same work on process pools.<br>
So this is really nice.<br>
It lets us use the same API and switch between multiprocessing and multithreading.<br>
Down here we're going to create a with block and extenuate one of these executors.<br>
We're going to submit a bunch of work and then when you leave the with block you don't leave it until the work is all done and so when you leave, you can go and get the data back from all the actions you've submitted.<br>
It's really nice, I definitely recommend something along these lines if you're doing threading or multiprocessing.
|
|
|
show
|
1:58 |
Once we covered all of the core built-in foundational concepts in Python for parallelism we branched out and said, well let's look at some extra libraries that let us do other things.<br>
The first one of those was unsync and the primary problem that unsync is trying to solve really has to do with this mixed-mode parallelism.<br>
Here we have a bunch of different operations, compute_some download_some_more, download_some, and a wait_some.<br>
The red one, compute_some, is CPU-bound that means it should be run in multiprocessing, but download_some_more and wait_some, those are asyncio-based.<br>
They would be bet and most efficiently run on an asyncio loop.<br>
download_some is implemented in a way that does not support asyncio, but it does interact with the network so threading actually would be really perfect for it.<br>
How do we run all those together?<br>
Well, it's means different APIs if we use all the foundational building blocks.<br>
But with unsync all you have to do is call these functions and you can wait on the results in a block that basically waits for the work to be done.<br>
And you specify through the unsync decorator and the method signature what type of method that it is and then unsync decides how to run it best.<br>
So the first one, we say it's unsynced but CPU-bound.<br>
Unsync says, "Great, we're using multiprocessing." The next one is a regular function so def not async def, just def, and so, unsync looks at that and says, "Well, okay, here's a regular function we can't run it on asyncio, so let's run it on a thread." Finally, at the end we have an unsync, async method so async def, and that means this one does support asyncio so let's run it on an ambient asyncio event loop on a background thread that we don't have to think about or worry about.<br>
All of that happens in just this little bit of code, here and it's beautiful.<br>
What's also nice is unsync is only 126 lines of code in its entire implementation so it's not some huge, massive library it just is a really clean API on top of all the foundational stuff we've already spoken about.
|
|
|
show
|
1:35 |
The next extra library we looked at was Trio and Trio's main purpose is to take this async and await world and put a little bit nicer coordination on it.<br>
So yes, it's easy to start some operation on an asyncio event loop but what about child tasks?<br>
What about weight and making sure that the parent task doesn't complete until its child tasks do complete?<br>
What if you have a whole bunch of work running and you get an error in one?<br>
Wouldn't you want to cancel the other work because you don't want to do it?<br>
Everything's broken, anyway.<br>
So, that's the job of Trio, is that sort of coordination.<br>
So, here's a typical use case.<br>
We're going to go and generate some data, and process data.<br>
We talked about this too You're probably tired of hearing about this producer consumer thing but the idea is we're going to open a nursery nurseries where we start these child tasks and the async with block won't finish until all the child tasks are done.<br>
One of them is errored, in which case we'll cancel all the others and it'll be done or as you can see at the top here, we've added a move_on_after block as well so we're only going to allow that nursery to operate for five seconds.<br>
If it's still busy, we're going to make it cancel all of its tasks.<br>
So, either all the tasks are done there's been errors, in which case an exception will be raised right here or the work has been canceled.<br>
So, a really nice way to coordinate parent child tasks, and timeouts, and things like that.<br>
Just remember, if you're using Trio it's separate and independent from asyncio so things built on asyncio, like aiohttp require that Trio-async bridging the library that I talked about.
|
|
|
show
|
1:18 |
Another third party library we looked at was Quart.<br>
Purpose of Quart is take the non-async web framework, Flask and make it an async and await-enabled framework.<br>
It does this by completely reimplementing Flask atop asyncio, but doing it in a entirely compatible way so even Flask extensions just plug into Quart and'll work just fine.<br>
So how did that go?<br>
Well, we added an async method definition here so instead of def sun, we have async def sun.<br>
We do all of our work against as much async operations as many async operations as we can, so we make sure we await those, and in these places our web server can entirely go and start processing other requests completely.<br>
Cause what are we doing?<br>
We're waiting for that web service, that location service or sun service to get back to us.<br>
So while that's happening, let's do the rest of the work.<br>
And then, we just return our data, in this case it's an API so we're going to return JSON data via quart.jsonify.<br>
Remember the complex algorithm of conversion here.<br>
You take the word Flask and you replace it with the word Quart.<br>
If it's lowercase flask it's lowercase quart uppercase Flask, uppercase Quart.<br>
And then you make as much of your libraries and your internals async enabled and then you just await them and use them, like this.<br>
It's beautiful.
|
|
|
show
|
1:38 |
We say that Python threads do not really add any benefit whatsoever if they're CPU bound so if most of their operations are actually Python instructions, not just waiting on a web service call or something on the network or file system that's because of the GIL.<br>
The GIL means in this Python process only one interpreter or instruction will execute at a time, it doesn't matter how many threads there are, which one's running one at a time.<br>
Okay, so that's the GIL.<br>
We saw that if it's Cython, we can rewrite our method in C because Cython takes Python and compiles it to C.<br>
And we can also use a nogil keyword which tells CPython, everything we're doing here has nothing to do with Python, it's pure C so it's just going to operate down here.<br>
You go let other stuff run and when this comes back we'll reacquire the GIL.<br>
So all you have to do is say with gil and then you do your computational work.<br>
It sounds simpler than it is though because you have to make sure that you're not interacting with any Python objects, you're going to capture all those values and then use them basically in C.<br>
And that's even down to the square root method.<br>
So we were using math.sqrt, but that was a Python method so it accepted a py object type thing and that was going to work in the nogil world.<br>
So we had to use the libc.math sqrt and remember we used cimport, not regular import there.<br>
But once we did this, I saw like 1,000 times improvement in our code, it was really, really worth it for what we were doing.<br>
So Cython wouldn't be the first thing I jump at but if its solution fits your use case it seems like a really good option.
|
|
|
show
|
0:17 |
I want to take just this one final time to say thank you, thank you, thank you for taking this course.<br>
I really appreciate your supporting my work and I hope you've learned a ton.<br>
Feel free to say hi online on Twitter where I'm @mkennedy.<br>
And I hope you go do amazing stuff with asynchronous programming in Python.
|