|
|
|
11:16 |
|
|
show
|
4:32 |
welcome to the course.<br>
Thank you for considering adding a CMS to your web app as one of the courses that you're going to study.<br>
Now, let's dive right in and talk about data driven pages.<br>
And CMS Page is understanding the difference between these two things will show you the value of this course and what you're gonna learn.<br>
During most Web applications we build in pyramid or other frameworks like Flask and Jingo.<br>
These are data driven Web APS, and what I mean is the page always looks the same, no matter what thing you're looking at.<br>
Here, for example, is Pipi.<br>
I might be I don't warg and we're looking at the AWS seal I package the command line interface were working with AWS in this page.<br>
It's always gonna look like this, but little elements will be filled with parts of the data from one or more tables from the database.<br>
For example, here we have the name of the package and its version.<br>
Here we have how to pip install name of package.<br>
Over here we have whether or not it's release is the latest release.<br>
And when that was, here's a little summary that comes out of the database.<br>
Some details about links and information, the project description, all of these things.<br>
No matter what package I look at, it's always gonna be little cookie cutter stuff that fills in these pieces of information.<br>
Another example might be Amazon.<br>
You go and you had a category, then you pull open item and it showed you a picture and has the reviews in the price and that kind of stuff.<br>
Those are the data driven world.<br>
They're very, very structured.<br>
They're HTML template is all built around having this little holes where you plug in the data in.<br>
It's the data that varies.<br>
On the other hand, in the much more freeform world, we have things like WordPress and medium and other sites.<br>
Jumla, you name it.<br>
There's a bunch of these that are much more.<br>
I'm going toe log in, get a text editor.<br>
I'm gonna type information that's going to create pages and blog's and articles and all that kind of stuff for reward press.<br>
We could come here, we could log in and we would get something that looks like this is my personal blogger, WordPress here and notice.<br>
It's not just a block.<br>
It has pages.<br>
It has a navigation.<br>
It has Bobo's.<br>
Of course.<br>
Here's some of the pages, and if I want to go edit him like, for example, that contact Michael one.<br>
Unlike a data driven app, I don't go and start editing source code and redeploy the website.<br>
No, I can go and pull this up and set the title and right arbitrary HTML.<br>
And here and notice on the right of a bunch of capabilities toe change the layout to change the URL toe publish or not unpublished this page and so on.<br>
And then eventually, once I write and publish it, you can see here is the page that you saw in that editor.<br>
This is very different than the data driven world.<br>
You basically have a freeform editor that creates all of this content.<br>
But the most important thing is sometimes you want this behavior from the CMS, and sometimes what you want is that data driven behavior, most e commerce or other types of abs along those lines.<br>
There the data great driven kind.<br>
They've got categories, they've got details and so on.<br>
But you probably want a little bit of this.<br>
CMS stuff as well.<br>
And the big challenges.<br>
Should we create our site in a CMS like WordPress?<br>
Or should we create our own data driven site and just suffer the deficiencies or require that developers set up the landing pages and stuff like that?<br>
And what we're going to find in this course is that it doesn't have to be either or we're gonna take our pyramid Web.<br>
Apple will have data driven pages and CMS pages.<br>
The data driven pages will be powered by the database with their very close structure.<br>
As you see over here, the other pages will be more like landing pages, marketing people support people can log in into a very rich editor that we're gonna add, and they're going toe just right content that's going to generate our site.<br>
But the important thing is the CMS side of this story over here on the right will still have the capabilities of our website, for example, noticed in the top.<br>
This site will still know that were logged in.<br>
It will still have access to a lot of the functionality that is this rich Web application that we built, so it's not like, well, half of the site is now this weird, disjointed CMS thing.<br>
And the other half is the proper Web app know they're the same thing, and we're just gonna learn how to add this cool seem s capability that's gonna be high performance.<br>
Has rich editing all sorts of cool capabilities plugged that into our existing data driven web app without interfering with what's happening there, but adding this great capability that non developers can contribute to the content of the site.
|
|
|
show
|
4:38 |
So what are we gonna cover during this course?<br>
One of the specific lessons and chapters we're going to start by focusing on routing how we describe and control which your URLs or Web site responds to.<br>
And what part of our Web app those Urals our map to?<br>
You'll see that routing is the very center point of the CMS capability.<br>
Not super complicated, but it's going to be in this one place after all the data driven stuff has happened.<br>
Or we're gonna lock in and grab onto the euro and get a chance to decide if this virtual idea of a page or a redirect or something like that belongs to our CMS or it really is just a bad request and it's a four a four.<br>
So we're gonna talk about routing specifically around how we add the capability to add CMS requesting basically catch every single request of the site.<br>
Then we're going to start from an existing app.<br>
The ideas were taking a data driven Web app as I showed you in the beginning, and we're going to add the CMS functionality to it.<br>
So we have a rich, powerful German Web app that we've already created, and we're going to do a quick tour of that.<br>
So you're able to understand it and work with it and completely know what we're working with as we start building on top of it there won't add to core CMS capabilities.<br>
First is we're gonna create some kind of redirect service, something like Billy.<br>
So, for example, if you were to go to talkpython.fm/ YouTube, that's going to redirect you over to YouTube with some huge, terrible girl that I honestly can't remember.<br>
It's like 20 random characters.<br>
So what we'd like to do is one of the features of our CIA masses.<br>
Have the ability have simple, short, memorable your l's that we can share on social media that we can put in other places and to say, like signature of an email, something like that.<br>
And then it will actually take you to the real page, either somewhere else on the site or somewhere even external.<br>
So we're gonna take our first step into the CMS world by adding this redirect feature to this app and then more in line with Brian what you're imagining.<br>
We're gonna add basically the capabilities of WordPress to our site.<br>
And what I mean by that is the ability to create arbitrary landing pages with rich formatting with a rich editor.<br>
Control the or Els determine whether or not their public or hidden those kind of things.<br>
So we're gonna have these redirects, and then we're gonna add these pages now.<br>
Actually, having them displayed in our site is pretty straightforward, but having the admin section to properly work with them and edit them, that's gonna be a lot of what we're gonna focus on Chapters three and four.<br>
Of course, we want to save this content to the database.<br>
Up to this point, we're not actually gonna worry about the database, which could be used like bake in memory structures that will stand in for the database.<br>
But eventually we're going to say, Let's stop for a minute and store this into our database using sequel alchemy.<br>
I'll show you how to do that.<br>
We also have an appendix on sequel alchemy.<br>
If you're not familiar with it, you can check out the appendix, but we don't go over it in the course proper.<br>
Each team l is, ah, decent format, but It has a lot of problems.<br>
It's hard for people to make sure they make no mistakes.<br>
They close every opening Div as a closing div and so on.<br>
So for the most part, we're gonna leverage mark down.<br>
But we're also going to see that we can bring in little bits of HTML.<br>
Avi need fancy formatting like a giant image that spans the top of the page or something along those lines.<br>
We also want to have a rich editor.<br>
We're gonna need a really nice editing experience, both for beginners who are not familiar with HTML a markdown, but also something with cool hot keys and highlighting and color hence and what?<br>
Not for people who know what they're doing but just wanna have a much better experience.<br>
So we'll see that we can bring in some really powerful back in editing tools for our pages.<br>
And then we're gonna bring in a library that lets us reuse parts of mark down within other pages.<br>
It's dramatically, dramatically, faster.<br>
You'll see.<br>
We'll get, like, 100 times speed up by going from standard mark down to this advanced markdown system and so on.<br>
So we're gonna use this other library that take some of the ideas here but makes them very high performance, more reasonable and just gives new capabilities to our whole CMS.<br>
One reason mark down and HTML.<br>
And finally, we're going to add a little bit of logging to make sure that we get good visibility to what's happening in our application.<br>
And so this is what we're gonna cover.<br>
I think it's not super hard to build, but it adds an incredible capability to our Web application that's gonna pay off for years and years as other people can log in work with our Web app.<br>
In a lot of the pages that were creating or managing, don't require developers to go change code and then redeploy it.<br>
That's just more like WordPress.<br>
You log in and you edit the page, edit the redirects, and off they
|
|
|
show
|
1:26 |
So what do we expect that you know, when you take this course, Obviously, beating the right expectations means you're going to get the most out of it.<br>
You'll be able to fall along everything.<br>
So we assume that you know, Python.<br>
This is not a beginner Python course.<br>
So it starts with an existing Python Web application, and we used Python to add a bunch of cool features to it.<br>
So we assume that you know, Python.<br>
What we're doing is not massively Advanced Python.<br>
It's not meta classes and all sorts of crazy programming, but you do have to be able to program in Python able to fall on.<br>
Of course, this is about the Pyramid Web framework, and we're taking a nap written in Pyramid in extending it.<br>
So you have to have a little bit of knowledge about pyramid again.<br>
You don't have to be a complete expert, but having a tiny bit of experience will go a long way, and then the core Web foundations, HTML and CSS.<br>
We use HTML.<br>
We use some CSS styles, but we don't really talk about them.<br>
We talk about some of the more advanced features we talk about some form validation and some of the things like that, how we create some forms and we could submit them back to our site For our CMS admin side of things.<br>
We use a little bit of styles.<br>
None of these air super intense again.<br>
But we don't start from scratch with us.<br>
We assume, you know, pyramid a little bit.<br>
We know you have some decent working capabilities in Python and that you're somewhat familiar with HTML and CSS.<br>
Other than that, we cover most of things you need to know.<br>
We do.<br>
You seek welcoming, but we haven't appendix that start from scratch there if you need to learn.
|
|
|
show
|
0:40 |
finally let me introduce myself.<br>
I I'm Michael Michael Kennedy.<br>
I'm the author of this course as well as a couple other things that you can follow me over on Twitter, where I'm at M.<br>
Kennedy.<br>
I'm the founder and host of the talk by Thunder Me podcast.<br>
I also in the co founder and co host of the Python Bytes podcast.<br>
Both of these, I get a great view into the Python ecosystem, some of the experts creating the tools that we're talking about here.<br>
So it gives me a good perspective on what to recommend and whatnot Teoh.<br>
And also, I'm one of the principal authors and founder of Talk Python Training.<br>
This is me.<br>
Welcome.<br>
My course.<br>
I'm really, really excited to have you here.<br>
I know you're gonna have a fun time, and I'm looking forward to the journey together.
|
|
|
|
5:27 |
|
|
show
|
2:05 |
it's important that you follow along in this course and that you, Brian the code and explore these ideas on your own computer.<br>
In order to do that, you got to make sure your computer is set up to run all the code and work in the way that you're going to see us working during the course.<br>
So that's what this chapter is about.<br>
Would you be surprised to hear that you need Python for a Python Web course?<br>
Of course not.<br>
But specifically, you're going to need Python 36 or higher these days.<br>
That's pretty common.<br>
Most systems have had bite on 36 for a while.<br>
It's been out for a couple of years, but if you have 35 or lower, some things might not work.<br>
Some of the syntax that has been introduced is really nice and will probably end up using it things like f-strings and so on.<br>
You want to make sure that your Python 36 so you can go to Python dot org's Get that?<br>
How do you know whether you have Python or private on what version of Python do you have on macOS and Linux?<br>
You can heip Python three dash capital V Not lower case Capital V, and it'll output the version Something like this.<br>
It will say Python 381 on windows.<br>
Depending on how you installed Python, you may be of the type Python three dash capital V, but not every way you install Python A Windows has that feature.<br>
So you might have to say Python bash Capital V.<br>
Now, depending on your path is set up in which versions of Python you have installed you might have pipe on two and three and whichever one appears in your path burst is the one that's gonna run here.<br>
So you could say where Python on windows and I'll show you all the things got installed.<br>
You can adjust your path to have the right one.<br>
So three it is great.<br>
If 39 is out By the time you're watching this or some version down the road, that's fine.<br>
Newer is better.<br>
No problem there.<br>
Just make sure you have 36 or above.<br>
Finally, if it turns out you have an older version of Python or you don't have Python and you need to get it well, this visit real Python dot com slash installing Dash Python.<br>
They've got a list of how you could install Python and the preferred ways of doing so for all the different operating systems that would check out that article if you need
|
|
|
show
|
2:16 |
If you're going to follow along, probably the best thing to do is use exactly the same tools that I'm using during this course.<br>
And I'm gonna be using the editor PyCharm.<br>
This by far, in my opinion, is the best editor for Python in general and really, specifically, for data driven web apps because it has awesome database tools, really good web support as well as Python itself support.<br>
So I recommend that you're going to use PyCharm for this course The best way to get PyCharm is to get the JetBrains Toolbox App, because then it lets you automatically choose between different versions, rollback versions If you need to.<br>
It will auto-update for you and things like that.<br>
It's a free little extension.<br>
You might have to create an account, but then you could just install things.<br>
Now PyCharm has two versions, It has the Community Edition, which is great for regular Python code and the Professional version, which is actually what's needed for web development.<br>
The database tools and the Web tools are only included in the pro version.<br>
So your choices here.<br>
If you already own PyCharm Pro good use it If you don't, there's a trial.<br>
You can use the trial.<br>
If you've already used up your free trial, you can buy PyCharm Pro by the month.<br>
It costs $9 for regular users per month, so you could pay $9 once and while you're taking this course or if you're a student, you get half price so $4.50 for a month And if you have an open source project, you can get it for free Visit the site under buy and their special offers and individuals and monthly payments and all that So the point is, it's either gonna be gotten for free or very, very cheap, like $4.50 a month if your student and so on.<br>
However, if for some reason you don't want to use PyCharm, the other editor that I recommend is Visual Studio Code.<br>
So Visual Studio Code is really, really nice.<br>
It's just not as nice as PyCharm, in my opinion.<br>
But if you do get it, make sure that you install the Python extension It's the most popular one, so it should be right at the top of the list of extensions here.<br>
But you're gonna want to click that little tab and then it'll open up this thing.<br>
You can install Python because you're gonna have to have Python Of course, in order for you to do stuff with it for the Python code All right, so that's the story with editors I would recommend use PyCharm professional.<br>
If for some reason you can't or don't want to do that Visual Studio Code is a great fall back.
|
|
|
show
|
1:06 |
To work with this project.<br>
To take this course and follow along writing the code, You're absolutely going to have to go and get the starter project.<br>
This is a non trivial, data driven Web application that we're adding a CMS to.<br>
So unless you want to go and create the whole thing, Or you know, maybe all along but add it to your own app.<br>
If you wanted to follow along exactly, you really want to go over here and get the code, download it and have it locally to start working from.<br>
And as we work in Chapter three and four and five, you know, take the starter code for three and work it over until it's what it should be in four and then to five and so on.<br>
So you want to go to the GitHub Repo here on the screen is also listed in your course page, your student page and the course training site.<br>
So you just click to GitHub repo right there, and it'll take you straight to the GitHub repo, So that's the easiest way to do it, but make sure you either clone or download it as a zip file.<br>
Also star it and even consider forking it to your own account so that you have it saved forever.<br>
All right, So don't forget to get the source code.<br>
We're actually gonna see how to do that, coming up soon in the next chapter
|
|
|
|
14:09 |
|
|
show
|
2:28 |
Before we dig in all the exercises and code that we're going to write, and the concepts that we're gonna cover around adding a CMS to our Web app, let's talk about the application that we're going to start with It doesn't really make sense to start from entirely a brand new application for this course The idea is you already have this application that's like something like amazon.com or something Where it's driven by the structure of the application plus the database.<br>
So you may have, like catalogs which have items for sale that each have a details page.<br>
Those are very structured on what's in the database.<br>
But of course, our goal is to add on these more free-form writing WordPress style capabilities to that application without completely switching over to something like WordPress.<br>
So what we're gonna do is we're going to start with the application that is that data driven Web app, but has no CMS capabilities.<br>
So in this chapter, we're gonna check that out.<br>
As Python developers, we've all visited pypi.org at some point, I'm sure.<br>
This is the place that you can go over here and find all the different projects that you can use in Python.<br>
So pyramid, for example, is listed right here and currently it's 1.10.4.<br>
So this application is exactly that style, right?<br>
So we come over here, you find very packages, and these packages each have a very clear structure.<br>
They have this release history They all look just like this here, right?<br>
So they're very, very data driven.<br>
Now, let me show you a slight variation on this.<br>
Check out this page.<br>
Looks pretty similar.<br>
There's a slight different in the font width, the boldness of it.<br>
But basically this is the same site.<br>
We can come down here and we can pick one of these and go and see there are all he details about them and whatnot.<br>
But notice this is running locally here.<br>
This data driven application, which is a clone of PyPI is what we're gonna work from.<br>
So what's the data driven part?<br>
Well, we've already seen some of it, So we have the landing page that shows us all the packages and then when we go to the packages, there's details about the packages.<br>
We also have users or we can log in or we don't have an account yet, we could register and so on.<br>
All right, so we'll have, like, an admin page and account page and all that kind of stuff once we create an account in log in.<br>
So this application has none of those features that the CMS might have, but it has all the data driven stuff.<br>
So this is the application that we're going to work with.
|
|
|
show
|
5:35 |
Well, you saw our PyPI clone running.<br>
Now, let's look inside and look at the source code and see how it's built.<br>
This is a pyramid web application.<br>
We're not gonna talk about the foundations of Pyramid, assuming that if you're taking this course, you're at least somewhat familiar with Pyramid.<br>
We actually have a whole course where literally we build that PyPI clone in pyramid called "Data Driven Web Apps with Pyramid".<br>
So if you really want to dig in and you're completely starting from scratch, that that might be a good course to check out.<br>
Over here, I'm just gonna show you what we got going on because we're going to start from this code, and we're gonna start extending it and working with it.<br>
Now, we brought this '.bin' folder and this just has a couple of little utilities that we'll use to, like, load up the initial data into the database.<br>
It's probably already been done for the one you're working with, but if not, then you can use that.<br>
Here's where it gets interesting.<br>
We have our controllers.<br>
This is where our view methods go.<br>
So, for example, we go over to the packages controller.<br>
We clicked on one of those packages like '/project/pyramid' that we saw.<br>
This is the code that runs.<br>
Now, This is a pattern I love to use.<br>
It doesn't appear in many, many web apps, but I think you'll appreciate it.<br>
I use this concept of the view model that will exchange the data.<br>
That is necessary to show, basically render the HTML.<br>
Okay, so a lot of the work is gonna happen here, but we're gonna handle this request.<br>
We're going to basically repopulate the data.<br>
If we weren't able to find a package, we're gonna return 'Not Found'.<br>
Otherwise, we're going to return the dictionary to this 'details.pt' which is over here.<br>
Like, right there.<br>
Notice the controllers have names like packages, and then the templates have directories for those controllers.<br>
and then files HTML files for the view methods.<br>
Really nicely structured there Let's look at that view model real-quick again Same structure We have the models.<br>
Then, we have the controller name.<br>
Then, we have some kind of naming a package details view model, And what it's gonna do is, it's just going to do a little bit of base work with the request.<br>
And then it's going to get the package name that was passed over.<br>
Try to use the package name to get the package from the database.<br>
Set up some information that has to be shown like, what's the latest version and the releases and so on.<br>
And if it's able to find a package, it's going to populate that from the package and it's releases.<br>
Of course it has to have a release, or we're just going to say there's no releases All right, so that's how we're showing this content.<br>
And what else do we need to talk about?<br>
We're going to be using SQLAlchemy.<br>
So, for example, here we have the SQLAlchemy class that's stored into our database for that package, and it has things like an ID, Created Date, Summary, and a Description Homepage, Doc URL, Package Installation URL, the Authors and the Releases in a relationship.<br>
So we're gonna be working with these SQLAlchemy classes, and we can query those.<br>
And the way that we generally work with them, if we go back here notice we have this package service that has some cool methods, like 'Find Package By Name', 'Get the latest releases count', 'How many packages There are' 'How many releases are there for a given package' And then just give us all the packages.<br>
We can check this query out really quick.<br>
We're using type hints to make this nicer Now we're gonna create a DB session, and then we're just going to go and do a query So this is standard SQLAlchemy Create session and you say I want a query the package.<br>
I want to filter by the package ID is the name.<br>
That's the way we set up our models of the ID is the name.<br>
Then we only want one of those or we want to get 'None' back if there's no match for that package name So first is either going to give us the one and only one that matches or it's gonna give nothing back.<br>
And that's pretty much it.<br>
We also probably want to look at the routing really quick because that's gonna be super important.<br>
So the main start up for the whole app is in this '__init__' here for the package.<br>
So this method runs, and It's gonna come in here.<br>
It's going to set up some things that are included, like the template in language here It's going to set up the SQLAlchemy database.<br>
And then it's going to set up the URLs that are running our Web app, and that's pretty much it.<br>
This 'init routing' stuff is gonna be really interesting.<br>
And we're going to spend a lot of time in the beginning getting this extended for our CMS.<br>
So you noticed that we have a static view.<br>
We've got some routes, like when you just visit the website, it gives you the home view.<br>
If you visit '/about', it gives you that For the packages, we have a couple of things.<br>
We could go to '/project/package name', with or without the little slash on the end and that's going to go to the method that we've been looking at You can also get the releases for a package So project, the name that's passed and then releases.<br>
And then we have some stuff around 'log in', 'log out', 'site map'.<br>
We have those kind of things.<br>
We don't have it really set up yet, but we're gonna have some admin routes where we can basically go and manage our CMS and other stuff behind the scenes, and that's about it.<br>
Here's the database setup.<br>
It's just a simple SQLite database, so you don't have to have a server.<br>
Just really keep it as simple as possible You can change this bit here to talk to real databases like Postgres, MongoDB or whatever it is All right, well, that's a whirlwind tour of our Web application that we're going to be running, and you can see right here it looks just like PyPI.<br>
not exactly, It doesn't have to be 100% clone, but good enough that we have this idea of Here's our main page.<br>
Here's our data driven list of packages.<br>
Here's the details for the packages.<br>
This is the part we've been exploring just now.<br>
That's how our web app works.<br>
And this is what we're gonna use is our starting point to build from in this course
|
|
|
show
|
6:06 |
Before we move on from this topic I want to show you how to get this code up and running because we're gonna have different versions of this Web app and getting it from GitHub and then getting it configured so it'll run correctly is something you have to do a lot in this course Let's do that Now we're over here in the GitHub repository.<br>
I'm gonna copy the base URL from the top for a sec.<br>
I'm going to need that.<br>
Now if we go over here and see each chapter has starter code.<br>
And basically, the way it works is this is the code I just showed you.<br>
Over here, this is the code that we're gonna have when we're finished with chapter four.<br>
Right now it says starter code.<br>
It's a copy of the previous one.<br>
But that's because we're on Chapter 3.<br>
We're going to Chapter 4.<br>
At the end of Chapter 4 this will be the final version of Chapter 4.<br>
Then there'll be a 5, which will be the final version of Chapter 5 and so on.<br>
So, depending where you wanna or to jump around and the course you can seek through here.<br>
So what we're gonna do?<br>
You wanna clone this somewhere and I'm just gonna put it on the desktop.<br>
I don't like to keep stuff on the desktop.<br>
You can see it's nice and clean, but just for this example.<br>
We're going to 'git clone' this and it's a huge long name So I'll just say 'CMS Course' or something like that, All right and then we can go into our CMS course.<br>
Here.<br>
And here, well Surprise, the same structure.<br>
Now notice in each one of these, there's a PyPI folder.<br>
That's the top level project folder.<br>
So this is the thing you want to work with and I have this cool little extension that will let me just open command prompt here into this folder.<br>
So what we want to make sure is, when we look that this 'setup.py' is where we're working and we're in the PyPI folder it has that And I point that out because there's sub PyPI folders as well.<br>
That's just how it works with this package.<br>
So what we're gonna do is we're gonna come over here and create a virtual environment, like so.<br>
Then we're going to activate it Now, on Linux and macOS, you say 'dot' and then 'bin/activate' On Windows, you would just say 'venv /script/activate.bat'.<br>
Basically, they avoid the dot Okay, so now we're close to getting it to run.<br>
There's a couple of things we have to do for Pyramid to make it run.<br>
Now, Pyramid is what's called a Python package, and that's how it's distributed.<br>
So we need to set it up so that it will actually know about itself so that it will run here and the way that we're gonna do that is we're gonna run 'Python setup'.<br>
We're gonna run the setup.py, and want to give it the 'develop' command.<br>
What that's gonna do is going to set it up and install the dependencies that we need, such as Pyramid and SQLAlchemy and so on.<br>
Alright, it looks like that's all working.<br>
We could do a quick 'pip list' and you can see all the things that looks like we're needing, chameleon, pyramid and so on are here.<br>
And also PyPI is installed locally right there.<br>
That just means it knows about itself basically.<br>
Our pip is out of date, but that's just the way these things work.<br>
We can upgrade it, but not worth bothering about now.<br>
Okay, so we've got it set up.<br>
We have our virtual environment active, and now we just want to see if we can run it When I ran 'Python setup.py develop' it installed Pyramid.<br>
Pyramid comes with a command called 'pserve'.<br>
Like that, and what we do is we give it the '.ini' the configuration file that we want to run and we want to run, develop.<br>
In production and out on the Internet, we would run production Here, we're working on it in development, so hence development.<br>
So let's hit it with this.<br>
Now, sometimes you get this weird 'This is not found'.<br>
Watch this.<br>
This is annoying.<br>
If we deactivate our virtual environment and then we reactivated and then we try this again Well, guess what it's found.<br>
Well, thanks Python for that inconsistency, but I'm kind of glad I ran into because if you run into that problem, you could see it's super easy to fix.<br>
And now, let's just copy this and make sure it's running over here.<br>
Here we go, Up and running.<br>
Everything's working.<br>
Great.<br>
The final thing, maybe you want to see how you get this into PyCharm.<br>
We're gonna go over here and take the folder that contains a 'setup.py' and drop that into PyCharm like so.<br>
On Windows and Linux, you have to say file, open directory, macOS, you can drop it on the middle dock icon there Notice it's already found PyPI, So that's good.<br>
We should be able to run something And if we go down here, we can find our code again.<br>
Yeah, that's good.<br>
One quick little trick we can do to make things work better in our HTML files We can go over here and say 'mark directory as resource route' So when you say, like '/static', it knows to look at this folder and it'll autocomplete, like out through there.<br>
That's very nice Okay, so this looks pretty much ready to go.<br>
Let's double check that it's using our virtual environment.<br>
And yeah, it looks like that is the case.<br>
Yeah, that's the one we created.<br>
Cool Cool.<br>
It doesn't always work, and if it doesn't work you can go to the preferences or settings on the other OS's Go to the project, project interpreter, should be listed over here.<br>
If it's not, you can 'Add', then click 'Add Existing' and probably find it for you.<br>
But it worked for us, so we don't need to do that.<br>
Click 'go' running just like before There we go.<br>
We have it working in PyCharm as well All right, so that's basically the process that you need to go through each time.<br>
One quick note is, don't reuse these virtual environments This is Chapter 3, you want one for the Chapter 3, one for Chapter 4, one for Chapter 5.<br>
because when you install the project itself as the package, it points over to that location where it came from So you don't wanna have it use the old code or part of the old code and part of the new code.<br>
It's very messy, so just make sure that you always use a new virtual environment for every chapter and just go through that process and double check that PyCharm, if you're using PyCharm, is discovering it correctly You can quickly come over here in the terminal and see that it has one active And ask 'which Python'.<br>
On windows you can type 'where Python' and it will show you which one that's using.<br>
Looks like this one is all set and we're ready to go.<br>
You should be ready to start building from this demo app.
|
|
|
|
28:46 |
|
|
show
|
3:03 |
In this chapter, we're going to put one of the most fundamental elements in place for our CMS.<br>
The ability to capture an arbitrary number of different URL requests over to our website, determine through a database or something else if we want to tell the user, "Hey, there is a page here" or not.<br>
This won't depend on the structure of our website or any given files.<br>
It's just going to be a place to catch all the extra stuff that doesn't already get addressed and map somewhere.<br>
And then we can decide do we want to show them a page maybe redirect them somewhere or just tell them that "page doesn't exist".<br>
And the core concept for that is routing.<br>
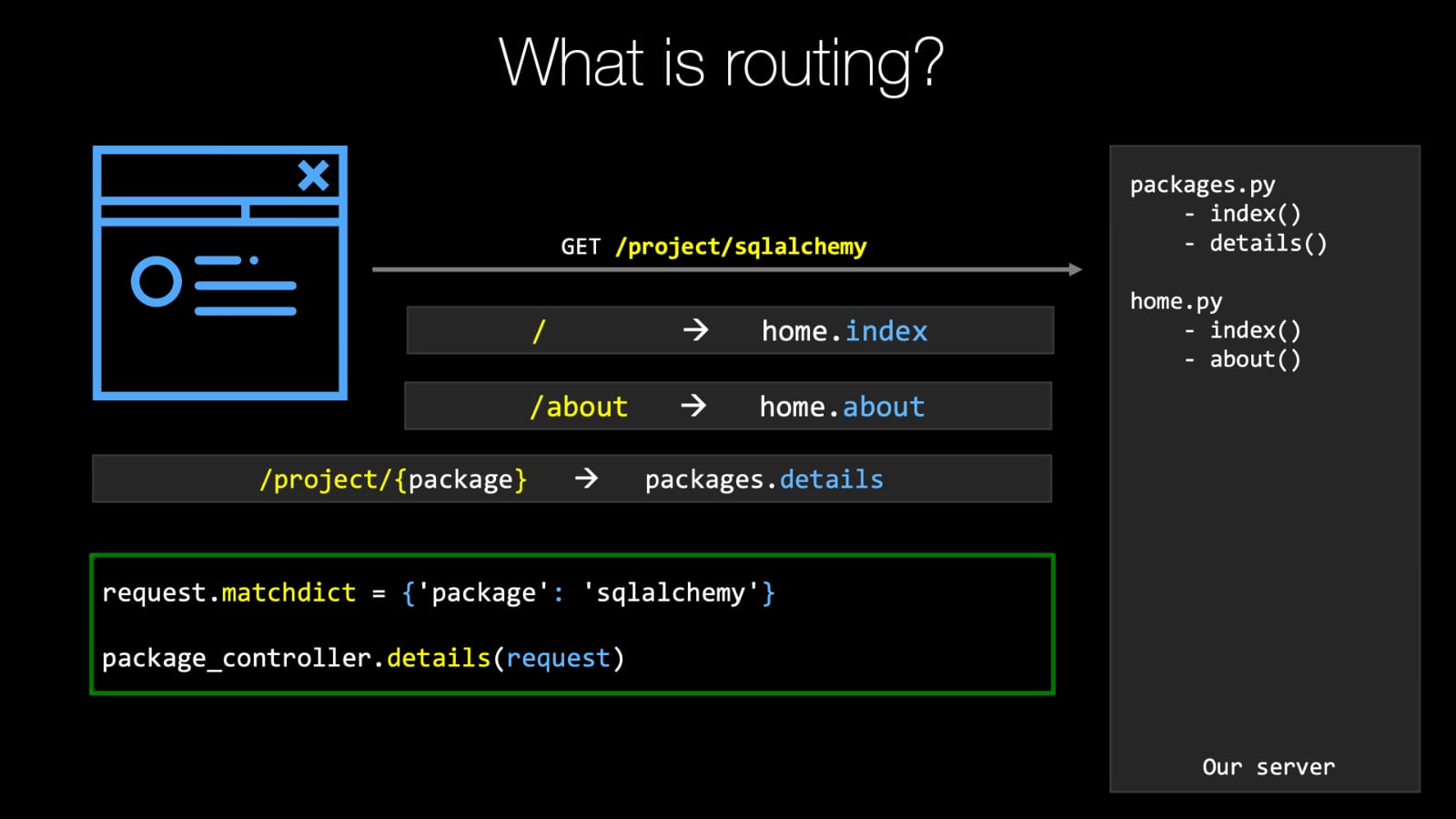
So let's review, super quickly, what routing is.<br>
On the left here we have the blue web browser.<br>
This is representing the user, visiting your web site.<br>
On the right, we have this grey box.<br>
This is our server, and it has two Python files, which define the behaviors for packages and for the home, just sort of the general top level stuff.<br>
In packages you can go to 'index', which is a list of all the packages or you can specify given package and get its details.<br>
And home, you just get a '/' that goes to the index and '/about' or something like that would maybe go there.<br>
We could decide what the URL is.<br>
So with this set up The user is going to make a request to our server.<br>
We're going to do a get request for '/project/sqlalchemy' and within our Web application, we've specified many different routes.<br>
And what's going to happen with the server is it's going to go through and it's going to say, Does this match?<br>
Does this match?<br>
Does this match?<br>
So it's just going to go through its list and say, "Well, we have a route that says for '/' show 'home/index' does, '/project/sqlalchemy' match that?<br>
No.<br>
Well, let's see what else there is.<br>
Oh, we have this one '/about', and that's going to go to the 'home/about' behavior.<br>
No, that doesn't match this pattern either.<br>
Now we have another pattern that '/project/<some variable piece of data> called package.<br>
Does that match '/project/sqlalchemy'?<br>
Why, yes, It does.<br>
So what we're gonna do is we're gonna say the value of 'package' is 'SQLAlchemy' and we're going to call the view method 'packages.details' We do that.<br>
we're gonna have pyramid set up what's called a 'MatchDict', and in here we're gonna have the key being the variable name in the route package and the value of that key being what was passed in the URL, SQLAlchemy.<br>
And we're gonna take that request which is set up along with the MatchDict like this and bunch of other details.<br>
And we're just going to call that function.<br>
Well, Pyramid is going to call that function and pass the request object which has been pre-populated like this auth.<br>
An whatever that method does.<br>
it's going to do, You know, likely it pulls that information back from the database.<br>
It fills out some HTML and it sends that back to the user.<br>
This is the general idea of routing, how it works in our website, and we're going to see how we can fit into this world so that we can add our CMS routing to, catch arbitrary URLs and then just decide that those either represent virtual pages in our website or we can say they don't represent anything
|
|
|
show
|
4:09 |
Let's look at just a few examples that might appear in our Web application One of the things you have to do is you have to tell it you're a bunch of files you were allowed to serve up.<br>
Now, in our world, we have a static folder, and it has things like CSS files, images, JavaScript.<br>
Those kind of things.<br>
Those are not determined or created by Python.<br>
They just have to lay there and be sent back as part of the HTML that is created by Python.<br>
So what we're gonna do is I want to set up a static view.<br>
It's going to be called static.<br>
It's going to map to the static folder, just '/static'.<br>
And then we're going to say, This is good for one hour.<br>
The max age is specified in seconds.<br>
So this is one type of route that we might have, a static route.<br>
More commonly, we're going to specify this more general type of route.<br>
They all have names in pyramid.<br>
The names have to be unique because we refer to them back in other files.<br>
We say this method handles the home route, so we just give it a unique name here and we refer to it elsewhere We're gonna say home is going to be just '/'.<br>
Now, you might not type '/', but this just means if you request the website without any other URL stuff, right.<br>
Like 'talkpython.fm' would map to this.<br>
We're also gonna add one for '/help'.<br>
So we want maybe our users to build to get help using our package site.<br>
So '/help' is where they would go.<br>
These two so far are just static.<br>
They don't have any variable data or any of flexibility in them.<br>
Right?<br>
I can type '/help', and I get this page.<br>
If I don't type '/help', I don't get this page.<br>
I'm also not communicating information through the URL.<br>
It's just show me the content for help.<br>
We can extend this further, like we saw for package, and we can add our URL that in the URL has some data.<br>
So here we say the route name is 'package' and it has to be '/project/<Something something without slashes in it>'.<br>
Like 'sqlalchemy'.<br>
Like 'pyramid'.<br>
Things like that.<br>
So we're going to say there's this route and it has to match this pattern a '/project/something' and that something should be a variable, also called 'package'.<br>
Finally, we can also have some constraints on these routes.<br>
So here's one.<br>
If we say we want to get the popular packages, I would like to be able to say '/7' and get the seventh most popular package on PyPI.<br>
'/1' are the most popular one.<br>
So what we can do is we can say this is not going to match slash anything, right?<br>
It would match '/help', potentially if it appeared before, because that's '/<something>' Just the value of 'num' would not help.<br>
That's not great.<br>
So we can specify a custom predicate test, if you will.<br>
There's a lambda function, and it says I would like to go to the URL that's been specified.<br>
This info of match, I'd like to get the value for 'num' whatever is passed in, and if it's not there, just return the empty string, and I want to make sure that this is a number.<br>
So this is our way to say only '/1' '/7' '/7000000'.<br>
Those would all match this route.<br>
But '/help' or '/about', those won't match because 'about' is not a number.<br>
So you can see you have a lot of flexibility?<br>
And another thing to keep in mind is when you specify these, you want to go from the most specific to the most general.<br>
Remember, from our example before, the way it works is pyramids gonna go through this list of specified URLs and say, Does this match?<br>
Does this '/project' or whatever we specified?<br>
Whatever the URL is.<br>
Does it match 'home', which is '/'?<br>
No.<br>
Does it match '/help'?<br>
No.<br>
So next one doesn't match '/products/sqlalchemy'.<br>
Yes, that's a match.<br>
And the reason you wanted to be most specific to most General is the general ones will almost always match everything, especially in the CMS world.<br>
You're going to see that the URL pattern is going to match literally everything.<br>
So the stuff that has other purposes needs to appear before, or you're going to end up with just everything going to that general match.<br>
So it has to go from most specific to most general as the tests come through.<br>
That way, the specific ones can still catch the things that they're supposed to, and if they don't, it's gonna fall through to the more general stuff as you go.
|
|
|
show
|
4:06 |
Before we start adding our CMS content and our CMS routes to our website, let's just quickly review the routes that are already in place.<br>
Now I like to organize my projects more than is specified by various frameworks.<br>
So here you can see in our main method, we've got our includes, our sublibraries, optional libraries that get included, like chameleon.<br>
Over here, we've got our database initialization and then our routing.<br>
In newer versions of Pyramid, if you create a new project, it'll put this routing into a separate folder, and then include it kind of like this.<br>
That's fine, but I don't think we really I like it just this way as well.<br>
It's totally good.<br>
So down here, let's look at what we got.<br>
There's quite a bit going on, isn't there?<br>
So we have the static route here, and it's at one hour.<br>
Just give you a sense of my real websites.<br>
It's at a year, and we do some techniques to make sure the URL changes if underlying content that shouldn't be cached any more changes.<br>
So this is kinda gonna small, but that's okay.<br>
Here we have, I like to group them by controller you could tell already I like to use a lot of organization here.<br>
So here we have 'home', which has various methods like 'home' and 'about', and our templates have 'home' and 'about' our view models have something like that about page doesn't have a view model, right?<br>
So same thing here we have home or have some names 'home' and '/about'.<br>
Slash in about.<br>
And let's go over here and look how that ties back.<br>
So over here we have our 'home index' and then our 'home about'.<br>
We could just call it 'index' and 'about', but I decided to call it this.<br>
And you could see the route name right here, 'home' and 'about'.<br>
And if for some reason, this was different, like if I put a '2' there and try to run it, It's going to crash and say we looked for a route called 'about2'.<br>
Apparently in the entire 'init_route' method, The whole startup of the app, You didn't ever register a route called 'about2' So, that's how these tie together.<br>
You can see that it's pretty picky that those were actually valid.<br>
What you put there.<br>
We also happen to be saying we're using this.<br>
These various templates here and then returning a dictionary to those templates.<br>
Just standard pyramid stuff.<br>
So let's go back and look at some more.<br>
We have the package controller.<br>
This is for the various packages, So if we pull this up, you'll recall.<br>
We go and click on one of these.<br>
notice it's 'project/aws-cli'.<br>
If this was sqlalchemy, is that in our short database?<br>
It is.<br>
So you can see it pulls it up to this bit right here is passed over to that method.<br>
And the way it's done is, we say it's '/project/<SOME VARIABLE>'.<br>
We'll grab that we call it 'package_name'.<br>
Now, One thing that's annoying about Pyramid is whether or not the slashes on the end matters.<br>
So I've added a second route to say if they put the slash, same action, do the same thing.<br>
Here you can see one that has a constraint.<br>
So this actually can appear first because it's the only one with numbers in the front, so I could go over here and put '1' and see the most popular package Where as the website doesn't really pull it back It just says the 1st, 2nd, 6th, and so on.<br>
But it's not catching things like 'about' because of this constraint here.<br>
Okay, so we got that we got a package, details, some release details.<br>
And then down here, we have our account for log in, and register, and so on.<br>
One other thing let's look at the account bit right here that you work with and specifying a matching these routes.<br>
I talked about the URL matching the pattern.<br>
That's true but also the http verb.<br>
Are you just doing a request to a page which would be a GET, or are you submitting a form back to that page which would be a POST.<br>
So we can also distinguish between these two methods here on whether it's a GET or a POST, in addition to having the same route.<br>
I guess that will come up somewhere as we work on our CMS.<br>
Technically, the CMS as a consumer of it will probably be only GET.<br>
As we work on the admin section to edit our pages and whatnot, of course, we're gonna need a have both of these in place.<br>
All right, well, that's pretty much it for the routing that we have in place here I think we're, yeah.<br>
I think we're pretty much good
|
|
|
show
|
6:57 |
Sometimes life is full of irony and this is one of them.<br>
We've talked about all of this routing infrastructure and all of these routes that we've added.<br>
And you think, Well, this is what's here already know how much more do we have to add and work with our CMS?<br>
Well, it turns out we're only gonna add one single route for all of our CMS.<br>
And that's because the way the CMS works is it says all the stuff that didn't match any of these, just give that to me.<br>
I'm gonna take that, have a look and see if I can work with it.<br>
So it'll basically pass through our CMS method and the method is going to decide That URL you gave me, Does that match a page or some kind of redirection or something like that?<br>
Or is it something that I don't know about.<br>
It's not in my database and there is no record of it.<br>
So just go back and tell them that the page doesn't exist as if there was no CMS section.<br>
So what we're gonna do is, we're going to come in here.<br>
We're gonna have a CMS route.<br>
Now it's super important that this goes at the very end because, as I described it, The CMS route, It's gonna catch every single request period except for the ones that are preceding it.<br>
But if it is in the beginning, that means everything.<br>
So we're gonna go down here.<br>
We're gonna do this 'config.add_route()' like so, and we can call it CMS, 'cms_request'.<br>
Let's call it a request.<br>
That's what we're going to call it.<br>
Now, we've seen that over here we can have static, and we can also pass in variables like that.<br>
But what we're gonna do instead is we're gonna pass in something a little bit different and we're gonna use a star, and that just means match everything And we need to give it a name.<br>
We'll call it 'subpath'.<br>
So an example of what subpath might look like.<br>
This might be '/home', let's do this.<br>
'/company' '/history'.<br>
Right this could be a URL that we come up with, and when we pass it over That's gonna be the value of subpath.<br>
We'll have to figure that out there actually think it might be.<br>
We're gonna see I think it might come back as a set a list of 'company' and 'history' for when you ask for a '/company/history'.<br>
We'll see in a second.<br>
I'm pretty sure that's the case.<br>
But what we're gonna do is we're going to say I would like to put a pattern that's going to match everything.<br>
And then we need to take this and apply it just like we had over in these other controllers Like here, We need to apply it to one of these So just for a little quick start, I'm gonna copy that.<br>
And let's go and create a new Python file.<br>
I'll call this CMS controller, as in model view controller pattern.<br>
And let's go over here and say hi to the view config which we're gonna need to let PyCharm do a little import statement at the top, Thanks, PyCharm.<br>
You don't need this.<br>
Just 'return response', which is gonna come out of pyramid And 'body="Hello CMS"'.<br>
Here we go.<br>
So what goes here?<br>
This will be CMS request.<br>
We're not going to have a render for the minute.<br>
And let's do it like this.<br>
We'll put this down here.<br>
Comment that out.<br>
Great.<br>
So what we're doing is we're going to say, move over so it doesn't get greyed out on you.<br>
There we go.<br>
So we're gonna have this route come to.<br>
Do it like that.<br>
We're going to pass in the request, which at the moment we're not using, but we will, very soon.<br>
And we're going to say 'Hello CMS'.<br>
We're not using any of the data that's getting past.<br>
Let's see if this works.<br>
We might need to do one other quick change here.<br>
All right, so this is still working.<br>
All these were not taken over.<br>
Let's say 'Hello World'.<br>
Tada, look!<br>
Now we type whatever we want.<br>
Anything up here, it doesn't matter.<br>
All of those are matching that pattern.<br>
Now, we obviously don't want to just say 'Hello World' to anything on the Web site.<br>
That's silly, but this is the first step.<br>
Let's go a little farther and have it take that information that's passed over, get it out and do something with it.<br>
So we're gonna go over here and say sub path, go to the request Now, what can I do on the request?<br>
I don't know.<br>
Looks like nothing because, Well, PyCharm's unhelpful here.<br>
So we go over here and say this is a request and specify a type from pyramid.<br>
Ah, that's better.<br>
We go the dictionary that contains the stuff from the URL and say, Give me the subpath.<br>
Let's just print out really quick what is the subpath and what's the type of subpath.<br>
Run that again, switch over here do a quick request.<br>
All right, so it's a tuple.<br>
I almost had it right.<br>
I said it was a list.<br>
It's a tuple.<br>
So these are the things that are separated by the forward slash right?<br>
It slash on the server?<br>
Then 'hello', then slash 'world' and slash anything "!".<br>
So we probably want to get the URL and the way we'll get the URL is from this subpath.<br>
We can come over here and say Use this cool little string function.<br>
Say, given a string, I would like to take a bunch of items and use the string to turn them into other strings.<br>
Stick those this item in the middle stick the slash in the middle like they join on subpath.<br>
And that's a print out, we don't need to print out, Say 'hello world'.<br>
'Hello CMS' you requested and let's put your URL in here as a little f-string like so.<br>
Right.<br>
Again.<br>
What are we giong to get now?<br>
instead of 'hello, CMS'.<br>
If we did it right, it should be requested, this.<br>
All right, let's see.<br>
There it is!<br>
Hello, World, anything?<br>
Beautiful.<br>
Beautiful.<br>
Beautiful.<br>
So it looks like we've got this URL mapped over to this CMS method, and now we just look at the URL and decide.<br>
Do we have content to show them for that?<br>
Yes or no?<br>
This is gonna be the foundation that'll hook into this data driven web application.<br>
For the most part, it doesn't go to the CMS, right?<br>
We're over here and log in.<br>
We can register.<br>
We can go view some stuff about packages, those are, all the strict data driven, structured pages.<br>
But then, if we want to go say '/donate' well, we could create a CMS page that talks about donations.<br>
We want to talk about help, here's the CMS page that's gonna, you know, provide users help.<br>
Over here we have featured products.<br>
In featured/projects.<br>
We can use our CMS to start adding features without going and recreating very structured things in the database that are, you know, not very helpful.<br>
These are one-off pages like, Here's the featured projects.<br>
Or here's the help page or something like that.<br>
The hook to make that happen is in place.<br>
The requests gonna come in here, we're gonna figure out.<br>
Well, what do we want to show them for this URL and then send it off?<br>
It sounds simple.<br>
There's a lot of cool stuff that we're going to do to make this really, really nice and fast and easy to create these pages.<br>
But this is the shim.<br>
This is the seam in our application where we can reach in, and then we plug in our custom code that we write that will effectively be our CMS.
|
|
|
show
|
4:34 |
Well, our simple little CMS view method here is fun.<br>
We can request anything on the Web site, and it will give us back, you know?<br>
Hello, CMS, you requested whatever URL you requested.<br>
That is not very practical, however, is it?<br>
So let's build something better than this.<br>
Now, if you look over in the services folder subpackage, notice there's one for packages and there's one for users.<br>
And what is happening over here in these files is either all the requests, all the logic around, accessing the thing they describe.<br>
So access and users.<br>
Here's how many users air in the system is creating a new user years validating their password Here's logging them in and so on and so on.<br>
So let's create something like this for the CMS.<br>
That'll be where we talk to the database to look or what pages or other things we might want to work with are there.<br>
So I'm going to add another Python file called cms_service, And in the beginning we're going to do two very simple things.<br>
We'll have a function, so do def.<br>
It's gonna be get page, and we'll have the URL here, which is gonna be a string and we're just gonna return a dictionary for the beginning.<br>
I have that.<br>
Now another thing that's really, really helpful that we're gonna have is The ability to do redirects to make a request and send somebody somewhere else.<br>
So I'm gonna go and add get redirect.<br>
So if we wanted this to say well, I'd like you go to '/news'.<br>
and that actually goes, you know, just some complicated URL either on our site or entirely somewhere else.<br>
So that's where the idea is we can use our CMS for redirecting the other places and keeping track of those requests in addition to just having pages Now, if you look over here in this DB section, I've added a little bit of fake data.<br>
These pages, they have a title and a contents.<br>
So I'm just gonna grab this eventually that's gonna go into a database and be more proper.<br>
But let's just go over here and start with our fake data.<br>
So what we can do is we can go to our fake data and has pages, and We can try to get by the URL.<br>
Se we'll say the page is this.<br>
If it's not there is just going to turn nothing.<br>
So return the page like so perfect.<br>
this one Lets just do 'return None'.<br>
All right, so let's see if we can get the age to come back over to our CMS controller.<br>
so instead of doing all of this business, let's go and see the page is going to be CMS service.<br>
Import that and say, get page, give it the url.<br>
I'll say, if not page to raise http, I think it's like this.<br>
Not found.<br>
perfect.<br>
Otherwise, let's put the message of here something better We'll, say title, and we don't really have a view, a better way to show them this.<br>
We'll, say content just just show you that hey something's coming through.<br>
We'll say 'page.get(title)' 'page.get(contents)' if that's what we really called it.<br>
title, contents, Super.<br>
Oh, and I just noticed that I probably want to change this.<br>
The way we're requesting it.<br>
this is not gonna work.<br>
I was assuming that was a dictionary, and it's just a list.<br>
So let's put this in as a dictionary where or the key is the URL.<br>
That way we could just ask give me the value or the URL.<br>
We ask for 'company/history'.<br>
We get this, we ask for a 'company/employees'.<br>
We get this.<br>
We ask for something else, we get nothing Okay, I think we're gonna be good to go.<br>
Let's see what happens now.<br>
I go here and I slash Ask for '/ABC'?<br>
None type has no attribute.<br>
Okay, I need to work on that What about 'company/history'?<br>
Okay, great.<br>
Well, I think we did something wrong here.<br>
Let's see what's going on.<br>
Oh, have it backwards, If the page didn't come back, it's not found Let's try this again.<br>
But now I should say, not found.<br>
And if we have 'company/history'?<br>
Here's the company history.<br>
Awesome!<br>
And then, what was it, employees?<br>
Yeah, our team.<br>
And if we don't have the s, Obviously that's not a page that's specified so doesn't exist.<br>
Now, we're a long way from making this look nice, but here we're simulating going to the database based on URL were passing along.<br>
We're either getting nothing or we're getting something back from the database and we're rudimentarily communicating that back to the user that says it's not found, or giving them, like a really basic view of the data.<br>
So we have this kernel, this beginning of our CMS forming right here.
|
|
|
show
|
1:40 |
Let's quickly review the routing needed to add this custom CMS method, which is going to be the entry point to handling all the CMS requests.<br>
Now we saw that we can go config that around to control the way your URLs are mapped to different parts of our web application.<br>
We give it a name, and then we give it some kind of pattern to match.<br>
And the trick here for the CMS one in pyramid is say star subpath.<br>
That means match everything Just give me any URL that could possibly be typed into the website and I'm gonna handle it Now, obviously, if this goes first, here's the only page, the only request, only method that's gonna run on your site.<br>
So this one needs to go at the end.<br>
But it's kind of the one that catches the ones that are missed by all the other more structured parts of your website We're gonna map that over to a method with a view config.<br>
When I say the route name is CMS, which we put at the top.<br>
We're gonna give it away to render it itself to a page.<br>
We'll talk more about that later and we've got some method This one called a page.<br>
and here we get our subpath as a list of the pieces separated by the slash.<br>
But what we're storing the database is just a string that is the entire girl So that's what this little joint statement does.<br>
Then, we go to our CMS service, get us the page and hand it back to that template to show it to the user.<br>
And this is the basics of how do we get started handling requests for this arbitrary URLs on our website.<br>
And that's the key to making this CMS thing work.<br>
And just remember this route the top piece must go the very end of all of your route definitions because it matches everything and the matching happens from top to bottom, So this had better be at the bottom
|
|
|
show
|
4:17 |
Well, we're making really good progress with our Web app here, but notice if we go to something that doesn't exist, We get this underwhelming 'page not found' 404 status code error.<br>
Now it turns out having a better 404 page can be helpful and can even be a great way to catch users and help them find the thing they're looking for Check this out.<br>
Here, check out the 11 best 404 pages, and I love these really creative ones that you might go and find.<br>
So here.<br>
""Error 404.<br>
I find your lack of navigation, disturbing", right.<br>
Here's one for hootsuite that talks about how you Congar find what you're looking for.<br>
is an old school looking one.<br>
That's kind of fun The Lego 'oh no!<br>
Something's' come unglued'.<br>
Over at Talk Python, we have one that's kind of fun.<br>
Course it's a podcast and you're supposed to plug in your your ear buds and listen But if there's no page, well, maybe there's just empty air.<br>
Headphones here, something like that.<br>
So what we want to do is we want to add something fun to our site rather than this.<br>
So really, really quickly, I'm gonna show you how to do that.<br>
Why is this relevant?<br>
Well, because over in our CMS thing, right, we're catching everything and then for stuff that doesn't exist or saying it's not found right?<br>
So we want to kind of build out what happens in this section to make it slightly nicer.<br>
So I've come up with something fun that I'll go and share with you in a second.<br>
Image and whatnot I created.<br>
So here is the image that is the logo of PyPI, right.<br>
This is their logo.<br>
So I thought I'd be fun if that kind of looked broken.<br>
So what we got to do is we basically have to just say write a view method here, a special one that's gonna handle when there's a 404.<br>
We're gonna go over here or something like this.<br>
This will be 'not found'.<br>
And I'll just put it in this utilities controller and what we want is a not found view config like that.<br>
And the route name will be, let's put 404.<br>
And that this will be, I already dropped it over here 404.pt.<br>
There we go and for this, We're gonna go set the response, its status equals 404.<br>
Like that.<br>
And it turns out that we're going to need to give a little extra information over here.<br>
So we' ll say, go and get this thing called our view model or view model base.<br>
and then we'll just say, give me the dictionary.<br>
Not that one.<br>
Like, so.<br>
the reason we have to do this is there's some information like the logged in user ID Whether or not that set or not, that has to be communicated to the outer shell like the navigation and stuff And it wants me to pass the request, though it can go check the request for a logged in user.<br>
Things like that All right, well, with this little change.<br>
Run this.<br>
It doesn't love it.<br>
Oh, yeah, the 404 route name.<br>
I don't think I need to set a route name here.<br>
It's just '404'.<br>
Okay, cool Cool Now let's go try this again so we could still go around our site, right?<br>
You can see it's still working, but if we hit something like 'donate', which doesn't exist now, let's refresh the CSS.<br>
Now we get this cool page like this, "We just can't find that page, sorry".<br>
Head back to the top of the site and then here's this logo kind of broken and spilled out on the page.<br>
That's fun, right?<br>
So let's go and this one also was a 404 right?<br>
So now let's get this cool 404 page.<br>
Maybe I should put the word 404 in here.<br>
I don't know.<br>
but it seems decent, because as we work with these different pieces.<br>
We're gonna wanna have some kind of better response than just know that that blank text message.<br>
anyway he would were able to use this cool 404 page and all we had to do was add a 'not found' view config and say, here's the HTML for it.<br>
And because the HTML uses this paired layout which ask questions like down here, is there a user and as that user and admin those kinds of things, it has thio have like a little bit of bass detail that comes from the base view model So instead of recreating that, we just passed it along.<br>
Easier to make the site work that way, keeps you logged in and whatnot.<br>
Yeah, I think that's really fun, let's go play with it one more time.<br>
Yeah.<br>
I'm sorry.<br>
We just can't find that page.<br>
Here's our cool 404 page.
|
|
|
|
1:13:52 |
|
|
show
|
1:42 |
We're going to add a cool little feature that turns out to be pretty simple but very useful and a great building block along our way towards a richer, full featured content management system in our Web app and that's redirects.<br>
So what are we talking about?<br>
We want to be able to use short little URLs that redirect to a much longer, more complicated one either on our own website or external websites.<br>
We'll use it for both So, for example, over here at Talk Python, the podcast, website, maybe you want to talk about our Python for Absolute Beginners course.<br>
So we get enter, talkpython.fm/beginners on that site.<br>
Internally, it knows about this you're on it says they were going to send that over to this much longer URL.<br>
training.talkpython.fm/courses/explored/beginners/ some great long URL that's on the end of that that's faded out in Firefox there So this is the kind of feature that we're going to build into our CMS into our Web app now you might think, OK, this is pretty simple we're gonna keep track of just like slash beginners and the destination rural and that's it and it's done Yeah, the actual act of doing the redirect is simple However, we're gonna also do our first pass at a really important aspect of our CMS And that's having a backend admin section where people who want to edit stuff about the CMS in the database can log in and create things like the's redirects They can type it in Hey, if somebody types '/beginners' go over to this place and keep track of it, that's gonna be really important for allowing people to create an edit CMS pages We're gonna start with the simpler idea first because it'll give us a good foundation to work from
|
|
|
show
|
4:51 |
We have some of our CMS working here Remember, we have this super simple fake page structure that will let us look up a page by URL and either say it's not found or return the contents Let's check that out real quick.<br>
So over here we could go to 'company/history' Here's the company history without much formatting, or the 'company/employees' But if we don't go to the right place.<br>
We go to somewhere that doesn't exist, This one.<br>
We get this 404 page.<br>
So what we want to do is to be able to put in other things Like maybe we have a YouTube channel or Instagram or something like that You could just type 'YouTube' and it'll redirect you over to our YouTube place.<br>
Except for it's not.<br>
You can see clearly it's still are cool little 404 Not found page.<br>
That's what we're gonna do in this really quick example here.<br>
We can get started with that.<br>
Now over and our fake data, we do have two redirects that we can pull from Imagine they have already been created in the database.<br>
We're going to talk about storing them properly in the database shortly, but for now, we're just gonna get him from here We have a short URL, 'courses' So it will be like going to our website '/courses', and it's gonna redirect you over to all the Talk Python training courses If you type '/bytes', it's gonna take you over to the Python Bytes podcast over here.<br>
Now, let's see how this works We're gonna need to actually implement that in our CMS and this is really really simple.<br>
So we can just go over here and say 'fake_data.redirects.get' whatever the URL is.<br>
You know, we should be a little bit careful here.<br>
Maybe we wanna do some normalization on the URL and we probably should up there as well.<br>
So we'll say if url we'll say url == url.lower() So in case, somebody types 'Bytes', we don't care.<br>
We want to treat the same as 'bytes'.<br>
If they haven't have, like, a space or something, we don't care We're gonna strip off the space is gonna make it lowercase and then go ask for it.<br>
We should probably do that up here as well.<br>
That'll make it a little more normal or canonical.<br>
You don't have to exactly get the case right and whatnot.<br>
And then over here in our controller, well, there's some stuff going on, right?<br>
We're generating the little sub-url from the list of elements out of our subpath URL route that we created.<br>
So that part's already done and we're getting the pages, and it's gonna turn out to be real similar over here.<br>
We can say redirect.<br>
And we'll just say like this.<br>
'get_redirect' and give it the URL.<br>
However, this is not exactly what we want to do.<br>
We got a kind of reverse this a little bit.<br>
So if we find a page, we just want to return that page.<br>
When I go over here like so and if we get to the end, we're going to say there's nothing here, but If there's a page, we want to return that page.<br>
We'll work on that to make it much nicer soon.<br>
If there's a redirect, we just want to send them somewhere.<br>
So how do you do that with Pyramid?<br>
Well, we can just return, We don't need to raise this one.<br>
But we can return http_found rather than not_found so we can import that here.<br>
Like that from pyramid exceptions.<br>
And what we put here is the URL So we say 'redirect.get_url'.<br>
Now let's look at our data again.<br>
We're getting this thing back.<br>
We've gotten it by its short URL.<br>
That's those things were the same, And we want to send it to where the destination is.<br>
The name is just for us to.<br>
Keep track of and know what we're up to.<br>
All right, so try to get the page.<br>
We got it?<br>
Send the page back.<br>
If there's no pages whatsoever, see if maybe there's a redirect for it.<br>
If there is, send them there.<br>
If there's no pages and there's no redirect, we have no idea what they want.<br>
Tell them the page is not found.<br>
Let's give this a try Over here we have our YouTube.<br>
That's still not going to work, which is expected.<br>
That's what we want.<br>
Let's go over here to our help.<br>
Also not working.<br>
Let's go to one of our CMS pages, company history.<br>
Okay, good.<br>
One of the things that should work is bytes.<br>
So this should take us to the Python bytes podcast over at Pythonbytes.fm.<br>
Woo!<br>
Look at that!<br>
How cool.<br>
So all we had to do is go over here and type, it went away when I hit Enter.<br>
But type r/, whatever our domain name is, 'pypi.org/bytes'.<br>
That's our little demo, that we're making at pypi.org.<br>
So we just put this on here.<br>
We're going to go along, and it's going to find that redirect and says, Okay, well, the '/bytes' short URL.<br>
Where is that supposed to go?<br>
That is supposed to go to this location.<br>
So we're going to return this redirect response instead of a text HTML response.<br>
And here we go.<br>
We're over here.<br>
Perfect!<br>
Let's try the other one, courses.<br>
There's the talkPython training one.<br>
Cool.<br>
And if we go to any other.<br>
Nope, we still just get our 404.<br>
All right, well, we've added this cool redirect feature, but like I said, there's actually a lot more to it than just this.<br>
It's gonna be fun to build on it and make things nicer and more dynamic, we can edit them, and so on.
|
|
|
show
|
5:49 |
It looked like we had our redirect working really well.<br>
We've got our data now, granted, this should be more dynamic and we should be able to build it out and edit it But assuming that we we're gonna get to that, we can go and ask for the existing redirects These two here and it will take us over somewhere else So are we done?<br>
Well, not quite.<br>
We're not carrying all the information forward that we could Let's have a quick look So over here, we can go to '/bytes' and it's going to take us to Pythonbytes.fm.<br>
Super, that works.<br>
Great!<br>
However, let's have another look.<br>
What if we want to communicate to Python Bytes, that this is part of a marketing campaign Or that the source came from us or any other information that they should process.<br>
Some sort of information from the user and send it back somewhere else?<br>
That's usually done with this thing called a query string.<br>
So often the URLs you'll see question mark a whole bunch of variables.<br>
That.<br>
So let's just suppose this is a marketing thing we want to promote Python Bytes.<br>
We'll say utm-campaign that's used often by Google and other sites.<br>
And then we said it's going to be equal to 'pypi-ad'.<br>
Maybe we ran an ad on PyPI and it's gonna go over to Python Bytes.<br>
We want to tell Python Bytes, Hey, here's somebody that came from the ad you ran.<br>
Now let me copy that because we're gonna need it again.<br>
What happens if I hit this?<br>
Yeah, No, we're not communicating that information over.<br>
Notice it's just the plain URL.<br>
What do we do?<br>
We're throwing it away.<br>
So what we'd like to do is come up with.<br>
So if we have it like this, we go there.<br>
We want the destination to also carry that forward.<br>
Alright, so we're going to make sure that this URL does that.<br>
So what do we have to do?<br>
Well, the first thing we can do is, over here.<br>
We're going to say if there is a redirect, we're going to send it over somewhere.<br>
Let's put, destination_url or something like that.<br>
It's gonna be this here...like that.<br>
Now we're gonna also check for the query strings.<br>
We're going to say 'if request.querystring' this comes out as just this part of it.<br>
'events' something that was passed along Then were going to update our destination to be the destination, question mark, the query string.<br>
Like so.<br>
So we're gonna do that little check here, make sure that there's something going on, Alright.<br>
If there is a query string, we're gonna do this.<br>
We don't want to always append the question mark.<br>
Only when there's a query string.<br>
All right, let's try it again.<br>
Remember our goal is to end up with this.<br>
From...<br>
There we go.<br>
We want to use this utm campaign.<br>
This is our query string.<br>
And let's just put one more up here just so we have all the data, you know, sort of the general case because we could have multiple variables with multiple values So we'll have 'utm-source=fake-pypi'.<br>
Let's do those.<br>
Okay.<br>
So when I try to get over to pythonbytes.fm, that.<br>
Here we go give it a shot.<br>
Yes, look at that.<br>
Beautiful!<br>
It worked exactly like we hoped.<br>
Better question mark, key equals value, Ampersand key equals value.<br>
Let's just test one more thing.<br>
That was working.<br>
But now, will it still work if we don't give it a query string?<br>
Will it like put the question mark or other weird things that shouldn't do?<br>
Nope.<br>
If you give it just '/bytes', it takes you to pythonbytes.fm.<br>
If you give it a query string, it carries that forward.<br>
All right, well, now the redirection side of our CMS is pretty close.<br>
Another thing that we might want to do.<br>
We're not doing the moment, but we might want to do is record that we've received a redirect request.<br>
so something that's really helpful is if I've got some URL and I share it on social media.<br>
How many people have clicked it right?<br>
If I say Hey!<br>
Go check out the special post we've done or this episode we've done.<br>
I would like to know how many times people clicked on that redirect to follow it over to that destination.<br>
That might be really good for advertisers if this was an ad.<br>
You can do reporting to them.<br>
If it's social media, I could know what of my social media campaigns are working well.<br>
All those kind of things So doing something along the line where we actually store the fact that this request happened.<br>
Maybe the ip address of the user where the request came from.<br>
So we can say by country.<br>
Here's the people visiting the different campaigns and so on.<br>
We're not doing that right now.<br>
I don't know if we're gonna get to that later or not.<br>
I haven't quite decided yet.<br>
But this is really, really valuable to just be able to use these tiny, short little URLs to go to something much more complicated.<br>
Let me run that out with a one more example here.<br>
So we go over to talkpython.fm, and we go to '/YouTube'.<br>
So this is one of these redirects here.<br>
I don't know why I don't want to keep it, but there it is.<br>
So if we go here?<br>
It's not just 'YouTube.com/Talk Python'.<br>
No.<br>
We go here, It takes us to this really, really ugly url.<br>
So this lets us over at Talk Python say you want to go check out our YouTube channel, all you gotta type is not even this right?<br>
You don't say that.<br>
You say 'talkpython.fm/youtube'.<br>
The reality of where that destination is, is quite unpretty.<br>
It's like this huge gross url that you would never expect anyone to type in.<br>
But tell them the type talkpython.fm, sure.<br>
That's useful.<br>
And over at Talk Python, we even use that down at the bottom Like here's our YouTube channel Oh, no.<br>
We put the full one.<br>
Sometimes we do put shorter things in here for stuff and sometimes not.<br>
So anyway, having this nice little URL that we can use here that will take you somewhere much more complicated is valuable for a bunch of reasons.<br>
And now our CMS has that built right in.
|
|
|
show
|
1:11 |
Quickly review doing a redirect with our CMS.<br>
Because the way the URL routing works, the way the CMS works is everything gets sent to the one final route.<br>
We give all the data driven routes, like here's a package or here's the popular things or here's the user log in.<br>
But after that's done, it's like here is the one place where the URL Request gets the final say before we just say, "not found".<br>
So we're gonna check and make sure that there's not a page that we want to show first.<br>
If there is, we're gonna show it.<br>
But then we're going to say, well, no pages.<br>
Let's see if there's a redirect.<br>
So we're using our CMS service to get that.<br>
Now it gets it from fake data.<br>
Later it'll get it from the database.<br>
But this code doesn't change, and we'll say, If there is a redirect, let's quickly make sure that if there's a query string, we also pass that along.<br>
But we can adjust that destination URL.<br>
And then we just say, http found, here's the URL, Go!<br>
And that's up to Pyramid to just take that and do the magic that's done inside of http to tell your Web browser to go to that new destination.<br>
Finally, if you get through the pages and the redirect and neither of them are there, we're just gonna return http not found and show our cool not found 404 error page.
|
|
|
show
|
2:02 |
Now, before we move on, let's take our code that we've written and make it better make it easier to test and make all the different parts that we work with more focused And we're gonna do that following this thing called a 'view model pattern' Now the website, the data driven website, has been using view models all over the place because that was how it was built But we just started from there and we had it on the CMS thing So you might not have noticed this idea of a view model So what is this?<br>
Well, it's most useful when you're accepting user input You have an HTML form.<br>
People are filling it out.<br>
They hit, save.<br>
It goes back to the website.<br>
That data has to be synchronized back to Python.<br>
You know, what do they type into the form?<br>
Are all the required fields there?<br>
Maybe there's conversions.<br>
They typed in a string.<br>
You got to convert it to a number or a date or something like that.<br>
So the idea of the view model is we're going to take what would otherwise be a really complicated and long method here.<br>
This is like our CMS requests that we were just messing with, and as we add more validation as we add more logic, this just gets longer and longer and it's more complicated and it's harder to test.<br>
So what we're gonna do is we're gonna break it into two things.<br>
The view method that actually handles the requests that works with the Web Framework.<br>
Works with pyramid, returns the responses.<br>
And then this thing we're calling the view model.<br>
This is what we're gonna build.<br>
This is a separate Python class that knows what data should be exchanged, what is valid, what is invalid.<br>
What is the logic to do all that stuff.<br>
So instead of having that long, view method all in one, we're gonna have a view model That it's created by the view method.<br>
It gets all the data and validates everything and then it comes back and just helps the view method do its magic.<br>
Also, this is gonna help with testing if we want to write tests because it's easy to test the view model outside of the Web framework.<br>
It typically doesn't need much in terms of what's going on there, Whereas maybe the view method is much more complicated.<br>
Gotta start up the website, the Web app, and get it all up and running before it can actually do its thing
|
|
|
show
|
5:26 |
So here's our a few method, and it's getting kind of long and unwieldy.<br>
It's not too bad, but we're not doing that much validation yet.<br>
You'll see.<br>
Like I said, when you're in this edit mode where people can type a bunch of stuff in and then it has to be synced back and it has to be validated.<br>
This could be four or five times long as this right here.<br>
This is a more simple case, but still it's valuable to explore this idea of view models and clean this up nonetheless So let's do that.<br>
Over here.<br>
Just like we have our controllers organized and our templates organized.<br>
We have our view models organized.<br>
So we're gonna create one for the CMS controller Create a folder called CMS.<br>
Now we could just create a new Python file, start typing, but I find it much simpler to start from an existing one.<br>
So I'm just gonna copy this and paste because you'll see there's some stuff that's common all over.<br>
So we'll have CMS request view model and first thing that I'll do is change this CMS request view model.<br>
And all of these derive from the view model base.<br>
And here you can see that we're passing information that it needs along, and then we're going to set some properties fields.<br>
actually over here So what is it that we need to work with?<br>
Well, we need to have a page, and we need to have a redirect, and that's pretty much it.<br>
So let's actually copy all of this and come over here and drop it for a second.<br>
So can set the sub path like 'self.' that'll store it on a class.<br>
We can also store the URL.<br>
And to get it back here, we got to say, 'self.subpath' and 'self.url'.<br>
Now this we have to import Luckily, if we hit alt + Enter, PyCharm will just write it up here at the top for us.<br>
That's nice, and I also need to important this from Pyramid, like so.<br>
We don't exactly want it to...<br>
well I guess we don't have to do that here.<br>
We are not going to do that yet.<br>
Let's just hang onto the page for a minute And the way we wouldn't do that store it on this view model class and same for the redirect.<br>
Let's go a little bit farther for the redirect.<br>
Let's say we have a redirect URL.<br>
And the beginning is gonna be 'None' but if there's a redirect, it needs to say 'self.' I have self.redirect.url is going to be this.<br>
So and that's just going to stand in for our little destination thing.<br>
So we're gonna see if there is a redirect.<br>
The url is this because we're going to need to modify it, like so.<br>
All right, so what do we get?<br>
We're gonna go over here and we're gonna create one of these things and give it a request.<br>
And it will automatically figure out there's a page or there's a redirect.<br>
And if there is, it's going to set up the right URL for all that.<br>
So let's go and get rid of this We're going to create one of these view models.<br>
I'll just call it vm.<br>
And when that's gonna be CMS requests Noticed PyCharm is not helping.<br>
If hit ctrl + space, It doesn't help, but if I hit it a second time, it will actually import it automatically here and create that so it's pretty awesome.<br>
And we got to pass the request through If you're unsure, you hit 'cmd + p' or 'ctrl + p' and it'll tell you a request goes there.<br>
and then it's super easy, we say if vm.page, we want to return one of those responses.<br>
So we got to write that again.<br>
Response body equals whatever we had Like this, I'll just say dot, dot, dot.<br>
And we'll say If the VM found a redirect, one of those is here, then we're going to return it to the redirect URL like that.<br>
Otherwise it's not found.<br>
So, first of all, this is cleaner than what we had before.<br>
We can come over here like this and go to the local history and see the difference.<br>
You can see there's quite a bit more going on.<br>
But what's really nice is that we can take one of these and test it in lots of interesting ways without having to go through this whole routing infrastructure or trying to call,you know, creating one of these, or basically getting access to calling this route function The other thing is, as I said before, if we were accepting Maur user input, we could have as much validation in here is we want and then check the few pieces of data that we're interested in and go.<br>
We'll see that as we work on the admin side of our request redirect backend of the pages and the redirects.<br>
All right, well, last thing to do is see if this actually worked.<br>
We don't need to import that anymore.<br>
Let's go and run it and see if our page works.<br>
But we come up here and we can try our company history Just make sure that the works and yeah, it sure is.<br>
It doesn't have the body part, but that's fine, because we didn't type that back.<br>
And if we go over here and find one that's missing.<br>
No, we still get our 404 And then finally,if we do our bytes.<br>
Like that.<br>
Yeah, it looks like everything was refactored quickly changed on the inside, but not in its functionality Let's just double check that, if we do the bytes with the query string, we still get there.<br>
Yeah, we sure do over at Pythonbytes.fm slash the right information there.<br>
Awesome!<br>
So now we've refactored the logic of this over to this view model, and now we just check.<br>
If there's a page we've got to do a response.<br>
If there's a redirect, we send the http status code for redirect, otherwise we send them not found.<br>
That still belongs here but all the other parts about getting the CMS page or the redirect and building the query string URL, all that belongs down in this view model We don't have to think about it in our view method, Love it.
|
|
|
show
|
1:20 |
We started this chapter by taking a couple of pre-greeted fake database backed redirects and wiring them into our CMS Now, if we type '/bytes' that takes us over to the Python Bytes site.<br>
If we type '/courses', that takes us over to the courses at Talk Python Training, We even saw how to carry on marketing extras like utm source and other query string information that we might want to pass along over there Well, that's all good, But really, what we need is a system in place so that we can edit and create these redirects.<br>
We'd like to be able to be sitting on our computers and say, "Hey, I'd like to have another redirect on our site." Log in and without You're messing with the source code without touching the database.<br>
Just start typing on the website and have additional URL redirects happen.<br>
and ultimately we're gonna use the same technique for CMS pages, which will let us edit the content of the site directly.<br>
But we're gonna focus on redirects first because they're simpler.<br>
So this is what we're gonna build something that looks like this.<br>
A little back into admin section that only admin users get access to.<br>
And over in the section, we're gonna have two things: were gonna be able to list and edit redirects and list and edit pages.<br>
As I said in this first chapter just redirects.<br>
But that's where we're headed, Okay?<br>
And we're gonna get started by building this page right here.
|
|
|
show
|
7:11 |
here we are in our project.<br>
Now what we want to do is actually Crean Admin section and over in our controllers area we have our CMS thing that handles the pages in the read Rex.<br>
We have stuff about packages and home and so on.<br>
But what we need is a whole new section.<br>
So I'm gonna create one of these in the easiest way is to just copy and paste, in my opinion, so does it say admin controller.<br>
And this is going to be admin home, something like that, and we'll give it a template.<br>
So we're gonna organize our template over here.<br>
We're getting need a new directory called Admin, and this is going to be index speak consistent.<br>
Either call them both home or both.<br>
Index will say admin index and admin there.<br>
Okay, so this is going to map over to this index function.<br>
We're going to call it admin Index.<br>
You can imagine it.<br>
Something like slash admin in the euro will get to that in a second.<br>
And we're gonna have ah template over there that's gonna show it now.<br>
We don't need much of this.<br>
First, it will be able to just return an empty directory.<br>
Our entry dictionary that's going to be haven't no data, but we're actually going to need a little bit of information about like who the user is and stuff like that.<br>
So we'll expand on that.<br>
It's super important that we don't let anyone, just anyone, access this.<br>
So we're going to do something like I have a functional say Validate is admin and we want to pass the usual.<br>
How do we get the user?<br>
Well, the easiest way, it turns out, is to create one of these view models, this view model base and give it the request.<br>
Why is that?<br>
Because if we go into RV model base, you can see that it has all this stuff for managing the user, whether or not the user exists going and getting it from the logging and cookie and things like that.<br>
So that's great.<br>
We're going to just be able to go over here and pass in the user.<br>
VM validate is the user Now.<br>
That's right.<br>
That really quick, you'll type annotation.<br>
That's gonna be a user now.<br>
What's the easiest way to do that one.<br>
We could return a value and then check it here and then send them somewhere else if they're not allowed.<br>
Or we could just raise an exception down here if it's not right.<br>
So let's say if not user, if we took out the user they have.<br>
This is admin and property, which weaken set in the database.<br>
So if they're not, first of all, if there's not a user logged an or if there's your user log jam, but they're not an admin, this is not OK, so we want to raise.<br>
They're like that.<br>
Say you don't have access this section and that's it.<br>
We just need to make sure that we call this everywhere.<br>
Now.<br>
Some other parts of the website also need access to this user and other information.<br>
So we're going to return the dictionary of that now here we can put and it turns out we can, you know, pull back information about some of the redirects or some of the pages how many pages there are, and so on.<br>
But we're not really going toe put that we're just gonna have to links on this page that will take you in to, say, edit the CMS pages or edit the read Rex.<br>
We're pretty close.<br>
There's two things missing We could write runnin it and you'll see the first one right away is that admin Index is not set up over in our routing.<br>
So let's go do that here.<br>
I called already had one in here called Admin home.<br>
So we just want to go to slash admin.<br>
I'll say index.<br>
Okay.<br>
These I guess we're left over from when I was fiddling with the site earlier.<br>
But these were the Urals that we're gonna need, and I'll just leave them here because But this is what we're gonna need.<br>
We need first half slash admin like that would run this and it's going to come across.<br>
Okay, let's log in here and logged in and notice it.<br>
Says admin here.<br>
The reason that is when I logged in before.<br>
If we go check out the users down at the bottom, here I am.<br>
Here's my account and I went had set that this user is an admin.<br>
If I take that away, I pushed those changes back to the database.<br>
Watch if I hit refresh this admin section appear goes away.<br>
But let's just see what happens if I try to go to slash admin for three Forbidden.<br>
Okay, that's because I'm not right now and admin.<br>
Let's go put me back as an admin.<br>
Refresh it.<br>
It comes back.<br>
And now, while it tried to get us there, right, this is the other thing we gotta fix is we need to write the h t mail that you saw in that last page.<br>
But, well, you're validating access to our admin section, so that's pretty cool.<br>
The last thing is just really quickly to throw together a bit of ah, template.<br>
That'll sort of set stage for going down that section So what do we got here?<br>
Let's just take this super simple about and throw it in here and call it Index This is gonna be admin home.<br>
We have a couple of actions that you can do.<br>
It will be able just have maybe two dibs with some hyperlinks.<br>
B slash admin slash redirects.<br>
That's one.<br>
And the other one will be pages again.<br>
We're not doing that just yet.<br>
We can't do that in a bit.<br>
We saved that.<br>
Come over here and refresh.<br>
Now we have control or site.<br>
Maybe don't want the self centered, but not a big deal.<br>
So here we go to our redirects.<br>
Here we go to our page is these are not created yet, obviously for four.<br>
Sorry, we can't find that page, But these were the two main things you're gonna be able to do from our site So we're gonna set it up so that you can come here.<br>
Let's just one quick final thing Throw in an admin CSS.<br>
You already have an admin CSS with some things set for us so that we can have, like, a cool little block that stuck in the center of the page and so on.<br>
So we come down here and say, Put these two together.<br>
See, this is an admin, Matlock.<br>
Let's put these and do some linked lists like that.<br>
These will be the things we can dio.<br>
The other thing we have to do is over here.<br>
We have to include that CSS file into our site.<br>
So we want the static.<br>
CSS has to be admin like that.<br>
They were doing.<br>
We go.<br>
I guess we want one more little change to her.<br>
Yes, as here text align is left great and maybe also four of this piece as well.<br>
That was supposed to be in there.<br>
Perfect.<br>
That's our little admin section that we got for our site.<br>
The two things you can do.<br>
Are you gonna go visit the redirects and the pages?<br>
They don't exist yet, but our progress through the rest of this chapter is going to be built out ability to add, edit and control these redirects just from this page sitting messing with code or the database
|
|
|
show
|
4:09 |
If you look at this code, it looks pretty decent, right?<br>
We've got our index method and we're' validating the user, and we've got this.<br>
Now it turns out that this is going to require checking permissions on many different places.<br>
And I want to just show you a slightly better way We can write this If you prefer this over what I'm about to show you Just leave it.<br>
It works great But what I would like to do is I would like to take the validation out of the function here And I would like to put some kind of decorator like safe 'permissions.admin' or something like that and put this up there and say.<br>
This entire function always, always, always requires that the user is an admin and put it up here like this To me, it's a little easier to check the permissions air set this way, and you know this won't be here anymore.<br>
This will just be gone It would just write the regular code, and because this decorator is up here, it's going to do the check Turns out that that's pretty straightforward to write.<br>
Let's go over here and create a new file called permissions.<br>
Write a function called admin.<br>
Now decorators are weird If you haven't written them before.<br>
So what we have to pass is a view function We're gonna pass that in, and then what we're gonna do to create another function that adds some behavior than calls this view function and return that So it's kind of him in line replacement of functions, this function that we're going to write this checker method I don't know what you would call it checker function, It's going to have the same signature as the view function Look over here, that is, It's going to take a request just like this And we can make this explicit or not.<br>
Just mostly this is for us to remember, So in here we're going to return the value calling the view function, bypassing the request Let's write this really quick like so.<br>
Then the goal of this, this decorator here, this admin thing is to just pass back the function,that's going to be called, not call it Okay, so it passes it back, then Pyramid is gonna call this function, which is going to do some validation and then call this view in.<br>
So this is where we add our validation.<br>
We're gonna need to check the user and again, Using that view model that knows how to do all that magic is probably the easiest.<br>
So gonna say view model base do our double control space to get the magic happening.<br>
Pass the request over And we'll say 'if not vm.user or not vm.user.is_admin'.<br>
Then we're gonna do the same thing.<br>
We're gonna raise an http forbidden like this import that we could give it a message like you must be an admin.<br>
Something like that.<br>
You must be an admin to access the section and actually, this should work.<br>
So we can come over here, hide that away.<br>
We have to import this there other than we should be golden, actually So we're gonna go up here, put this decorator on here, it's gonna take this function and replace it with this outer function that does the validation plus calling itself.<br>
Let's give it a shot, we come over here.<br>
We have our admin section there and notice the admin thing here as well.<br>
Here's a regular page.<br>
Still working here's an admin page allowing it.<br>
Why?<br>
Because my user is an admin.<br>
Let's go see.<br>
Here we go.<br>
We already got that open.<br>
Let's go make me not an admin.<br>
Push that to the database.<br>
Now, if I hit refresh, it should check on I'm no longer a user.<br>
Well, first Let's see over here that my admin permission went away.<br>
See it?<br>
It's gone from here.<br>
If I refresh this, it should not let me in And just like before, It doesn't.<br>
As many times as I want.<br>
No, no, no, you don't get to go in unless you're an admin.<br>
Leave that to the database.<br>
Try one more time.<br>
Hey, look, I'm an admin, I'm in.<br>
So this is this alternate model that I'm going to use, all the things that require admin access, Or you could extend this for what other types of checks you want but if it requires admin access, I'm gonna put this decorator on it rather than doing it throughout the rest of our CMS admin section.
|
|
|
show
|
7:12 |
Next up on our CMS is we want this link to work.<br>
No, no, no, not 404.<br>
We want to see all the redirects So we're going to implement this /admin/redirects, Let's go over here and duplicate that real quick.<br>
So this will be admin, Remember, already have these here.<br>
So let's go see what we call them.<br>
Just redirects.<br>
Gonna be /admin/redirects like this, and we'll call that redirects as well Go and work on the template first, I guess.<br>
So Copy/Paste Call that redirects.<br>
Here will say redirects, and for each one of these, we're going to list all of them.<br>
Let's first actually put the ability to have a new one.<br>
So we'll have a little linked to admin add redirect, I guess we'll call it.<br>
I'm not gonna write that first, but might as well put it in the template.<br>
And then over here, we need to have, all of the redirects.<br>
So have ah list element a nd inside of our element, we're gonna have a couple of things We're going to have a button to test it We're gonna have a button to edit it when have the short URL and then the name So let's go here and put a button.<br>
This will be admin/edit/redirect We're gonna need to put something in here.<br>
We'll have edit.<br>
Let's do test first, do edit second.<br>
Put something in there.<br>
How do we know where the URL is, where we're gonna test it to go?<br>
But for the test, let's have it open a new page.<br>
The target equals blank, that will open a new tab for us.<br>
Over here, we're gonna edit it, and then we're gonna have a span, couple of spans.<br>
Let's put the names.<br>
Put the url and then the name.<br>
So how do we know what pieces go in here?<br>
What we're gonna do is we're going to make a copy of this for each redirect in the database, and we're gonna pass it over and use this colon repeat, You want to say 'r for r in redirects:' I'm gonna pass all the redirects over here, and we're gonna clone this and use the data from here, so it's gonna be to get the value out of it.<br>
so in chameleon, you say that.<br>
You say r.short_url Oh, no!<br>
That's going to be just url.<br>
Let me copy this one.<br>
We'll need this in a sec.<br>
It'll be r.url I'm gonna start with short_url but it really needs an ID.<br>
We'll give it that in a little bit.<br>
I guess we could just...<br>
Yeah a short URL is gonna be what we're gonna give it for now.<br>
That is the short url, and then this will be its name.<br>
Let's go look at the data real quick.<br>
When this service, we're going to this fake data.<br>
But it has a name, a short URL, and a URL and this is going to be what counts as the ID.<br>
All right, Well, actually, that looks pretty good.<br>
We go back over to our admin thing.<br>
We need a redirect list view model which doesn't exist yet, so we're gonna go and create one.<br>
Let's put that away for a sec.<br>
Now it's time to add one of these admin sections over here.<br>
And again, the easy thing to do is copy and paste.<br>
This will be a Redirect list view model.<br>
And now here's where we got to put the stuff that we want to have access to in that page.<br>
Will say self.redirects And we said there this thing called redirects.<br>
It's a list or a collection of redirect objects.<br>
and the way we access our redirects is through the CMS service.<br>
We'll say all redirects.<br>
Now, obviously that looks like an error doesn't exist yet, so we can have PyCharm write that.<br>
And let's go in and tell it that this returns a list of dictionary.<br>
So this is actually pretty easy.<br>
We have our fake data redirects that we're using.<br>
We can't return that because that's like a little bit too high level.<br>
It has the keys and then the dictionaries.<br>
What we want is just a list of these so we can return that.<br>
Like dot items or, sorry, values.<br>
There we go.<br>
That's what we want and that should return a list of these.<br>
Let's give it a shot maybe it's gonna run.<br>
Over here.<br>
We go to our admin section.<br>
I might have not put myself back as a admin.<br>
One sec.<br>
Oh, no!<br>
That's not at all what it is.<br>
Hold on, hold on, hold on.<br>
This was worth running into this error in pyramid.<br>
It happens a lot.<br>
I'm not used to running into it because in my websites, I've extended some of the pyramid functionality to catch these errors.<br>
What went wrong here?<br>
Well, we never got to that, but that doesn't really matter.<br>
What happened is, notice when I made a copy of this, I changed all this stuff.<br>
I changed this stuff.<br>
However, What I did not change his index, and it replaced that function Which means the base just /admin is gone.<br>
Yikes, I hate that pyramid doesn't check for that.<br>
So we're gonna have to rename that and try one more time.<br>
Yay!<br>
Admin is back!<br>
Now, the big question is, is our other section redirects back?<br>
Yes!<br>
Look at that.<br>
There it is.<br>
Now, this is super super cool.<br>
It's really close to what I was hoping for We got our test button.<br>
Let's test this.<br>
It should open a new tab to Talk Python Training.<br>
Notice the bottom.<br>
The URL looks like it's probably gonna work.<br>
Yes, perfect.<br>
And this one that goes to Python Bytes well it should go to Python Bytes.<br>
Yeah.<br>
It looks like our little test is working our edit won't work yet because we haven't written that section.<br>
We're not allowed.<br>
We have implemented editing.<br>
We'll get there shortly, but it looks like it works.<br>
I'd like to change the way this feels a little bit here.<br>
Let's go over to this and we're gonna just give this a few CSS classes.<br>
So we'll say classes of button, 'button-'...<br>
Uh for the test what kind of button do we want?<br>
We'll give it a green button to test it And edit it we'll give it a button, buttoned-danger.<br>
Maybe we'll make these small as well.<br>
Little bootstrap there, Cool.<br>
Now we got our buttons Still works.<br>
Of course, nothing changes about them.<br>
This also is not super clear that this is a forward slash So let's make that obvious.<br>
What that means like, forward slash here.<br>
Cool.<br>
And then also we'll say this is class equals link.<br>
Something like that.<br>
And in our CSS for our admin we'll go down here and say '.link {font-weight: bold;}' like that.<br>
There we go.<br>
Now it stands out a little bit.<br>
I'm pretty happy with this.<br>
This isn't super cool looking, but again, it doesn't really matter.<br>
Alright, this is just for us to be able to manage our website.<br>
So this is great.<br>
we can go here to our admin section, go over and see all the active redirects on our pages.<br>
We could do cool stuff like if there was tracking and like this one's been clicked 1000 times and this one 500, whatever.<br>
But we're not doing that here, right?<br>
Things we could extend it as, but we're not.<br>
And then we can test it.<br>
That already works.<br>
And a little bit of what's left is to just edit this right?<br>
The ability to, like, pull up those details, change the name into the URL.<br>
Stuff like that.<br>
Cool Cool.<br>
All right.<br>
Well, it looks like our redirect admin section is coming along well.
|
|
|
show
|
2:29 |
Before we get to writing the code, actually edit our redirects, or for that matter, are pages as well, I want to review this design pattern, this concept that you may be familiar with, but you might not be.<br>
And it's super nice for how we organize your code.<br>
I still see lots of Web apps out there not explicitly using this and they're way harder to understand and work with because of it.<br>
So the idea is we're going to use this get post redirect pattern to edit our things.<br>
How does that work?<br>
Well, we have our server, and we have our database.<br>
Out there somewhere, there's a user who wants to talk to our site and the assumption here, is they're going to edit one of these redirects.<br>
Or they're going to create an account or something like that.<br>
They're gonna register for an account.<br>
So the first thing that they need to do to get started is they need to see that page that has the form.<br>
Like we're gonna register.<br>
So what is your name?<br>
What is your email?<br>
What do you want your password to be?<br>
Things like that.<br>
So they're gonna do an http get request against the server for '/accounts/register', and that's gonna show the form on their page.<br>
And then they're going to say, Well, my name is Michael and my email addresses michael@talkpython.fm and so on.<br>
And they edit that locally, and then we're gonna save that back.<br>
So to do the save, their going to do an http post back to the same url.<br>
The server's gonna look at that and go, "That means they want to save stuff.<br>
Let's validate it.<br>
And then if it works, we're gonna save it".<br>
And then finally, instead of leaving them on this page, they've just registered.<br>
They've just created an account What do we want to do?<br>
Probably send them to '/accounts' or some sort of welcome page They're going to send them a redirect request an http found as we've already been doing to '/ welcome' Welcome to your account!<br>
Here's what you gotta do to get started using our service.<br>
So it's a 'get, post, redirect' that is very typically the way that this works.<br>
If for some reason the data doesn't validate, they're going to stay on Step 2-3.<br>
They're gonna get a message that you have to edit it again, post this back again.<br>
And then eventually, when it's valid, they move on to the redirect stage.<br>
This is how I think of it.<br>
I get the form.<br>
I edit the form.<br>
I save the form, and I go on.<br>
This is actually a well known pattern mentioned on Wikipedia, but they have it wrong in my opinion.<br>
They call it post, then redirect, then get.<br>
Well, what are you posting?<br>
You got to start to get the thing to actually post.<br>
So anyway, they call it post, redirect, get, but it's a very well known pattern around organizing our code and the way that we process people editing data on the web.<br>
So we're going to use this for our admin section, of course.
|
|
|
show
|
2:10 |
It's time to add redirects dynamically as an external user, not just typing in the source code of our website.<br>
That's how, of course we want people to work with it And we're gonna use one of two of these URLs here.<br>
In the beginning, we used add to add new ones, but eventually you want to edit them.<br>
So we're either gonna go to /admin/add-redirect to add a new one, or we're going to go to /admin/edit-redirect and then give the ID to edit that.<br>
Those obviously don't exist yet over here.<br>
So we're gonna write them.<br>
Now, these are going to require a slightly different styles.<br>
So I'm going to put a little divider here.<br>
We'll call this add redirect.<br>
Why such a divider?<br>
Because we're actually gonna have two functions.<br>
They're both gonna kind of look like this.<br>
So we'll clone that.<br>
First thing, let's go and say add redirect.<br>
And then the route is add redirect.<br>
And what are we gonna put here?<br>
It turns out that adding and editing are going to be identical.<br>
So let's just say this is going to an edit redirect.<br>
But we want a different url so we're not gonna change this or this.<br>
But it turns out the same form works for both, so we don't have to write it twice.<br>
That's cool.<br>
Now, to follow the get, post, redirect pattern, sometimes you'll see people say, if request.method equal do get such and such else do such and such.<br>
You should never do that right.<br>
That makes it super complicated.<br>
Don't do that.<br>
What we're gonna do instead, as we're gonna go over here and use the web infrastructure.<br>
Say method equals get like that.<br>
And this is going to let us hook into that.<br>
And this function will only get called if it's a GET.<br>
So because of that, we need to have different names of more than one function.<br>
We already ran into that error.<br>
We're going to have one like this, and then we're gonna have one for POST.<br>
And this is gonna be called post too.<br>
This one handles showing the form.<br>
This one handles processing the user data submitted when they save the form.<br>
Oh, and I forgot, this is request method, not just method.
|
|
|
show
|
6:05 |
We're gonna go and add our form or our HTML over here, and this one's probably good.<br>
Here We're gonna call it for admin, I'm going to say add new redirect.<br>
But of course, we're gonna need to change that to sometimes they add redirect, sometimes not.<br>
Yeah, Let's actually put that inside this admin block a bit there Then what we're gonna do is we're gonna have an HTML form.<br>
The action is just gonna be this page, but the method is going to be post west post And in here we're gonna put standard editing elements that you'd have in a form.<br>
So when having input type equals text and I want to give an ID of name and then it's kind of infusing a name of name what does that mean?<br>
Name is the data submitted back to the website This is going to be the value because we need name short url, long url and so on.<br>
So name equals name.<br>
Yeah, that's weird, but that's what it's gonna be.<br>
Class, we'll, say form control.<br>
that's from Bootstrap.<br>
I'll give it a placeholder.<br>
Now, this is the text that's in there that says what you want to put.<br>
Say name of the redirect.<br>
If you hover over it or use some kind of screen reader, you can get what the title is, maybe more or less the same as the placeholder.<br>
But remember, if you pre-populated this, the placeholder won't show.<br>
So duplicate that there and then we also want to set the value, and the value is currently going to be empty But it is what we're going to pass in now This is important In two times This could be the redirect that we're trying to edit later when we get to editing, but very likely if there's some kind of error like we didn't fill out this field correctly When we want to send that information back, we don't want them to have to re type the whole form We want a roundtrip that so they don't They keep the values they typed the first time.<br>
So we'll put that in like this.<br>
Finally, we can say this is a required.<br>
That'll help getting that filled out there.<br>
Well, we don't do that for a few more He's one for the short URL Here we go We have that as the URL We need one more thing, here.<br>
We also want to pass around hidden ID.<br>
Now it turns out we could get away with this most the time, certainly for adding, but when you're editing, especially if you're changing the short URL, you need some way to know which thing to go back to.<br>
It gets really tricky, but down in the bottom, I'm gonna put an input 'type=hidden'.<br>
Call it, redirect-id.<br>
We only need to show this one.<br>
I'm going to say, tau ':' condition, if there is a redirect id.<br>
So we can omit it that if there's nothing here.<br>
Let's wrap this around.<br>
There we go.<br>
we also might have an error message It could be that you hit save, and maybe this URL already exists, You can't create it So there's gonna be some kind of error message We'll have a little section that will just share the outside class error message.<br>
We're only gonna show this if there is an error.<br>
We're gonna pass that back, and the text is going to be just the text of the error.<br>
All right, well, that's pretty good.<br>
Let's get some room to look at this big beast.<br>
So we're having our.<br>
Add a new redirect.<br>
Here's the form submitting back to the same URL So whatever we got from GET or sending it back with the POST.<br>
that's the get, post, redirect pattern part of it We'll have the text for the name, the short URL, the destination URL If there's an error, we're gonna show that, and I guess we can't really do this without a button.<br>
That's going to submit our form.<br>
Create redirect and we'll give it this class of 'button' and 'button-danger' to make it a nice red button.<br>
All right, well, this is looking pretty good.<br>
Let's go back and look at our controller.<br>
See how we're doing.<br>
Here's our redirect for adding add, one for get add one for post.<br>
Let's just do, we don't want this view model anymore.<br>
We need to do an edit redirect.<br>
Now again, this is add, but the edit and the add are gonna be basically the same.<br>
We'll do that here.<br>
Right, this is going to let us edit it.<br>
We don't need all of them, but we're gonna need some pieces of information.<br>
Whatever you saw me type here like URL, short URL, so on.<br>
We need all of those over here.<br>
Okay, great.<br>
I think that's probably what we need.<br>
We also need error.<br>
It could be empty.<br>
If there is no error, but it needs to be there.<br>
The way chameleon works, the template in language, it will crash if it doesn't see these elements.<br>
So we're going to create one of these over here.<br>
Which we gotta import and then we're gonna send back those values to that template.<br>
Woo!<br>
I think we might be ready.<br>
Let's give this a shot.<br>
Go to our admin section.<br>
Put redirects.<br>
Add a new redirect.<br>
Oh, yeah, there it is.<br>
And it's required.<br>
Yeah Okay.<br>
Well, that's a good start.<br>
It actually making more happened than you think.<br>
It's doing the local validation.<br>
So it's not submitting that back.<br>
Great, so that's working pretty well.<br>
Let's go and actually do this part as well.<br>
You can just do print.<br>
We can just send back the request dictionary that was sent over.<br>
So the view model captures all this data from the form and from the URLs and so on.<br>
And it'll show it there.<br>
Let's just see what's up with this.<br>
It won't let us submit until we fill it out.<br>
So let's say we want to go to Talk Python rather than Python Bytes.<br>
So we'll just say Talk Python.<br>
We'll give that for the name there.<br>
Fill this out.<br>
something like, We want to go to a slash just say type talk and then I'll take us there.<br>
And then, of course, talkpython.fm.<br>
This is not gonna work, We're gonna try to create it and says.<br>
You know, we're just we would have but let's see what we got.<br>
There's a bunch of stuff captured from various places that don't matter.<br>
But this is the part we care about.<br>
The name is Talk Python.<br>
The short URL is talk and the URL is that.<br>
Perfect, It looks like everything is working
|
|
|
show
|
3:03 |
says the last thing we need to do is somehow have this view model, validate and grab that data.<br>
So here's what we're gonna do.<br>
We have a method called restore from How about this process form poster, Something like that which doesn't exist and will say if vm not error return VM not to dict.<br>
So if this were to set the error here, we're gonna return that and show it.<br>
So let's just do that real quick.<br>
And he would just say self done.<br>
Error equals test error that rerun it.<br>
Now if I hit Refresh, it's going to show.<br>
First of all, notice all of the data went away.<br>
How frustrating.<br>
Fix that in a sec.<br>
It Reese tend here who test error.<br>
Okay, that's cool.<br>
We got our test error back.<br>
Didn't let us go by The other thing that we need to dio it's We need to get all of this data back.<br>
So in this view model that has a sinkhole to request dicked, it was really long to keep writing that.<br>
So I'm gonna go over here and say d equals that so we can say, Do you not get short or ill?<br>
and was gonna do that for the rest of them are going to get the u R l.<br>
And here we're going to say, if not self does short girl just add a little validation, give you a sense it might need more, but we'll get going here.<br>
You must specify a short euro.<br>
Another one that might happens would say, If CMS service don't get redirect from self dot You're all this would be the case where you try to create a new one for one that already exists in the air would be already exists or something like that.<br>
We contest that in a minute.<br>
So this is going to do to nice things is going to allow us over here Notice these Never refill themselves.<br>
They're gonna start doing that now.<br>
And let me just set on more time, self dot There equals hold tight just to make it stop for a second and still have these air conditions.<br>
So I try to submit the page again and it says hold tight.<br>
But look, now the data is coming along so I can change this to you.<br>
Talk to and the data goes back and forth, which is super helpful because we don't have to keep typing that.<br>
But let's get this little fake air handling out of the way.<br>
And we started.<br>
And that would work.<br>
Except for it would create the redirect.<br>
And then the last thing to do is to actually do the get post redirect.<br>
Not the one Lucretia, but just take him somewhere.<br>
So we're gonna say return http found and where we want them to go slash admin slash redirects.<br>
So we just created a new redirect.<br>
Let's show them a list of existing ones.<br>
All right, let's do that.<br>
So this put bites for a second.<br>
So that'll do our validation.<br>
Redirect with bites already exists, but not talk.<br>
No, no.<br>
So talk should work.<br>
If we hit this, it should take us to our list.<br>
Does perfect, however, didn't create it?<br>
That's the final final thing, right?
|
|
|
show
|
2:11 |
But let's go over here and put this CMS service.<br>
That create redirect.<br>
So we've gotten a post back, We validate the data, we're gonna do the thing, save it, and then do the redirect.<br>
So this will be a `vm.name`.<br>
`vm.short_url`, `vm.url` Yeah, I think that'll do it.<br>
Create that function.<br>
`name, short_url, url`.<br>
Great.<br>
Well, if we go over to this thing, we're gonna have a database for real in a minute.<br>
We're just going to stick something that looks like this in there.<br>
So let's go back.<br>
I'll have a data, woops.<br>
I say data equals this.<br>
So this thing is the short url, the ID.<br>
Let's just put by for a minute.<br>
We'll figure that out a second.<br>
This is gonna be the url we'll be also the short url, and this will be the name.<br>
And in here, we're just gonna go to `fake_data.redirects`.<br>
Our port url is going to be...<br>
Actually, we were had it.<br>
Let's just do it like this.<br>
It's goign to be data.<br>
There we go.<br>
That's what we want.<br>
And that will put it just while it's running into our fake database.<br>
And then, you know, when we get to a real database a little bit down the road, this will be working great.<br>
So come over here.<br>
Refresh it.<br>
Add in a redirect.<br>
Now we gotta do it again.<br>
Talk Python.<br>
Talk CMS.<br>
Talk Python.<br>
Okay, this should work.<br>
When it saves it back to the database, just temporarily in memory, it should show up in our list.<br>
Let's give it a try.<br>
Oh, yeah, There it is.<br>
Check it out.<br>
Courses, bytes, and this, and check out the url.<br>
talkpython.fm.<br>
There we go.<br>
Let's add one more.<br>
Just for fun.<br>
Google, g, google.com.<br>
All right, so if we type Go up here and open up a new tab type just `/g``.<br>
Look where we are.<br>
Beautiful, very, very cool.<br>
So it looks like our ability toe create these new redirects is great.<br>
It's working just fine.<br>
The only the last thing to do is edit it, but truthfully, we're basically done with that.<br>
We just need a very, very small change to keep track of the original data.<br>
And we're done with this whole redirect admin section.
|
|
|
show
|
4:01 |
we have our add redirect working, but it's time to edit as well.<br>
Because what if we make mistake?<br>
What if we want to change our minds?<br>
So for over here in our admin section in the redirects, we click on Edit.<br>
Well, ah, 404.<br>
And what we're trying to go to is '/admin/edit_redirect' And the ID of that object.<br>
Okay, well, that's pretty easy.<br>
We should build to do this.<br>
We've already done it for adding we should be able to edit it.<br>
There's actually not that much difference.<br>
Now noticed over here.<br>
We have an edit re direct route already.<br>
And it's going to be that one that we saw pass along is gonna come through is the redirect I d that we've already kind of been working with.<br>
So let's go and work in that here.<br>
Now I'm going to do something terrible and make it better.<br>
Terrible thing is, I'm going to make an exact copy of this and just repeat it and rename a few things.<br>
We're going to name that to 'edit'.<br>
And why is this terrible?<br>
Well, all the code, the order hiding down here is gonna be an exact copy in both places.<br>
That's not great.<br>
But there's so much similarity that let's just start this way and I'm gonna improve it.<br>
So here we go.<br>
Edit, and edit.<br>
Edit.<br>
Take that away from both of them.<br>
Actually, you don't need that would process.<br>
bit anymore.<br>
Over here, instead of 'create', we're going to call 'update' the redirect, and we need to give it one more thing at the beginning.<br>
The redirect ID.<br>
Because we need to find it by the ID and then make a change to it.<br>
Okay, So what's going to write this function first?<br>
Gotta write, Write them somewhere.<br>
So, yeah, redirect ID names.<br>
short url You're all these are all good.<br>
So how are we gonna find the one by ID?<br>
Let's go look at our data real quick.<br>
The each have an idea that gets set here, so it's not gonna be very efficient when we get to the database.<br>
It's gonna be a lot better, but we just do this And we'll just do a quick little sort here.<br>
Going through all the items.<br>
So we'll say, 'for k, v in big_data_redirects.items()' So this will give us the key, which will be the short url, and the value, let's change that to 'r' for the redirect.<br>
Now, on that item, we're gonna have the ID.<br>
So here will say, 'if r.get(ID) == redirect_id' And redirect is going to be just that thing.<br>
That's perfect.<br>
And we can break out of our loop.<br>
Super and then down here instead returning 'None' we'll just return 'redirect'.<br>
Alright Well, that looks pretty good.<br>
You could even give it a little test down here in a Python console.<br>
Actually Let's do this in two parts here.<br>
let's have the get_redirect_by_id.<br>
That's this one here will say get_redirect_by_id.<br>
'if not redirect: return'.<br>
just out of here.<br>
There's nothing to do.<br>
Otherwise we're gonna say redirect of name equals name and just do it for all of them.<br>
There you go.<br>
That should do it.<br>
We're gonna get it back, make those changes to it and just stick it back in the database, the "database".<br>
Our little in memory thing that we're working with until we get to storing this in the database better.<br>
All right, Now, let's go over here and restart this.<br>
We'll get it by ID.<br>
We have a one.<br>
Look that.<br>
Perfect!<br>
We have a two.<br>
There it is our bytes.<br>
Do we have a three?<br>
No, we don't.<br>
Give us nothing.<br>
Excellent.<br>
Okay, so it looks like our little get that is changing.<br>
So perfect.<br>
We're still calling up here.<br>
Update by ID.<br>
This should work pretty good.<br>
Now, surprisingly, that might be all we got to do for this part.
|
|
|
show
|
6:01 |
Let's go over into this and write this bit of code again.<br>
Now, in the add case, there's no data initially provided.<br>
But in the edit case, remember, the URL is passing over the ID of the redirect we want to edit.<br>
And that means we can write this or maybe that rather and this will be self.request_dict.<br>
So this is going to give us the ID if we're editing one.<br>
Otherwise it's going to give us none just like we had.<br>
And here we can say, if 'self.redirect.id' then we want to set some more values, right?<br>
We want to get the id and 'self.redirect'.<br>
I guess we could go and just get this.<br>
Let's say CMSService.get_redirect_by_id.<br>
Let's make sure we're checking that this, if it's empty, redirect by id.<br>
'if not redirect_by_id: return None'.<br>
Alright, if we pass and nothing, we expect nothing back.<br>
Just so we don't have to check it.<br>
Here you will get the redirect and we'll just say if there is a redirect, we want to actually copy those values over so they can start from seeing those values and then edit them.<br>
So this will be short URLs and the others are going to be similar.<br>
All right, get those And the redirect url, redirect ids are already set.<br>
Perfect.<br>
Think this actually might already do it?<br>
There's a few little things we're gonna have to touch up later to make it perfect, but this is really close.<br>
If I got it right.<br>
Well, let's go over here.<br>
Go to our admin section.<br>
View the redirects.<br>
We've seen we can already add them.<br>
Let's go ahead and just add test...<br>
Oh, I'll add my little talkPython one back.<br>
Right.<br>
Here it is.<br>
Let's suppose we can edit it.<br>
All right, Well ah, didn't totally work.<br>
We have our edit redirect five here.<br>
why is this not coming up?<br>
Good time to check out our debugger isn't it?<br>
Make sure that's hitting the right one.<br>
Yeah, it's coming here and you see, here is the URL.<br>
Everything looks fine with that.<br>
Redirect ID?<br>
It's five, okay.<br>
You know what I think?<br>
I think it's something super tricky.<br>
Watch this.<br>
It's going to be frustrating.<br>
Okay, so we come in here.<br>
If we look at this, you can see there's ID but notice there's no quotes on the 2.<br>
There's just the value 2.<br>
More relevantly, if we go further.<br>
You know, we just look at the redirects.<br>
Expand it.<br>
The items all have numbers, not strings.<br>
So what we're doing here is we're comparing a number to a string which is never okay, Never gonna match.<br>
So let's just do it like this.<br>
Alright, I think we should have this working.<br>
Now, let's go and do it again.<br>
Over admin, let's just edit one that exists now, so it's edit courses.<br>
Oh, yeah.<br>
Look at that.<br>
There's the courses.<br>
This will be, I'll put talkPython courses, for example, that should when I hit, 'create'.<br>
Notice, this is one of the little things we gotta work on.<br>
It will push that back to the edit should change this, let's see.<br>
Oh our validation is kicking in.<br>
Yes.<br>
So let's go and lock that.<br>
Down here we're saying if we're trying to create one, then we got to check that it already exists.<br>
We should say, 'if not self.redirect'.<br>
And this maybe like that.<br>
so 'self.redirect' What could say that's the best way to make this clear?<br>
We also need to say this if there is a redirect and it doesn't exist, redirect with URL was not found.<br>
So if they're trying to create a new one, we need to check for one like it already existing.<br>
If we're trying to edit an old one, it had better already exist.<br>
Okay, let's try this again.<br>
Resubmit our form.<br>
Maybe it'll work this time.<br>
Yeah, it does.<br>
And check it out.<br>
It's edited right there.<br>
Let's edit it some more.<br>
Let's just put all those classes.<br>
Oh yes, we need to dio slightly different tests over there.<br>
Let's just edit where it goes.<br>
Question mark equals true or something like that.<br>
Alright.<br>
Now, if we test this or even look at the bottom, we've edited it.<br>
Beautiful, beautiful, beautiful.<br>
Send us over there and the title is perfect.<br>
We're able to edit that.<br>
The one thing that we saw was that we're not yet able to edit this.<br>
We're somehow not relying on that ID, which doesn't change ever.<br>
Enough!<br>
And so let's do this will say 'get_redirected_by_ID(redirect_ID)'.<br>
That's the one we want and what probably should say down here with ID whatever it is.<br>
All right, Last chance.<br>
Let's see if we can edit that URL that short euro in our thing.<br>
Otherwise it's working.<br>
OK, here's the redirects.<br>
So let's make this course is exclamation mark and, ironically, we'll call this "classes".<br>
and we'll edit this as well and say question mark final equals Yes.<br>
All right, can we change it so that we can redirect through '/classes'?<br>
Woo!<br>
It's looking pretty good.<br>
Here's the final euro, but let's the real test is typing '/classes' up here isn't it.<br>
'/classes' Ready?<br>
Course it works.<br>
Beautiful, our little CMS backend, while it took a little bit to get it up and off the ground.<br>
Maybe took a few minutes.<br>
This is the same thing we're gonna do for pages.<br>
This is like the blueprint for everything we're going to do in the rest of the class in terms of our admin backend.<br>
But we're going to extend that, of course, with rich editing and all sorts of cool stuff.<br>
When we get to pages, but there it is.<br>
We were able to go over here.<br>
Go to our admin, and now we can edit our classes.<br>
We could even put it back to courses.
|
|
|
show
|
1:01 |
Now I give you '/courses' that works.<br>
Reduce slash classes.<br>
Oh, it remembers and remembers the redirect too bad.<br>
Oh, you know, it's not that it remembers.<br>
I believe we're not deleting out the old one, but don't worry about it.<br>
You know, it's it's not really that big of a deal.<br>
I guess we could go in and just fix it really quick, couldn't we?<br>
Go and find the short url, that was originally there.<br>
We can remove that from our database using that command right there.<br>
Whatever.<br>
It's current.<br>
short url is, take it out and then we're gonna put it back in right here with its new one.<br>
Let's go through that one more time.<br>
So we'll go over here, edit this Change it to classes Now courses doesn't work, but 'classes' still works.<br>
Put it back.<br>
Classes should no longer work.<br>
Nope, but you know, of course, here we go.
|
|
|
show
|
2:15 |
before we call this officially finished and put all the redirects aside, let's check out one more thing.<br>
There's something that's not amazing.<br>
If I add a new redirect says, add new redirect, create redirect that school.<br>
But when I edit one, however, I get to add a new one and created weight that save and change of this one.<br>
So let's update this page two.<br>
Very based on whether we're editing or creating one, it turns out this is super easy.<br>
We just have to put in place over here.<br>
We say add new redirect.<br>
So what we're gonna do, we can put one of these little chameleon string testy things that weakens you Assume, say, add new, if not redirect I D.<br>
So we don't have a new i d that specified.<br>
Remember, this is the edit case we're gonna say, Add new else.<br>
We're gonna say, Edit the redirect.<br>
Yeah, let's see if that works.<br>
You hear this should split to edit at it.<br>
Redirect it does.<br>
And if we go and have new one, here's an ad, a new one.<br>
If we go and edit at perfect, we need something like that for create as well And you know what?<br>
It's the same bit of HTML our little test.<br>
They're gonna put this in this instead of add new is gonna be re eight, and this is gonna be save, save redirect at it.<br>
And if we go over here and create a new one, been a creator, redirect and add one.<br>
Maybe even we could change the color.<br>
That's totally possible.<br>
But more just gonna leave him read for both.<br>
Yeah, there we go.<br>
We've cleaned up this page over here this page so that it's a little more meaningful.<br>
Even put the name up here.<br>
Say we don't have title, do we?<br>
We have name.<br>
Here we go.<br>
Edit the Python bites, redirect or we come over here and edit the courses.<br>
Redirect.<br>
I'm not sure if I love it or not, but I'll leave it there so you'll have that flexibility now.<br>
I think this is pretty much done.<br>
You can even see are cool little title that we put in there working for the hover when we don't have it empty so you don't see the placeholder.<br>
Great.<br>
All right, Now our little editing CMS thing is
|
|
|
show
|
3:43 |
one final cleanup before we move on to the next chapter.<br>
Remember when we wrote this add_redirect piece here?<br>
We then turned around where he said, We're gonna just copy the exact code and make minor changes like change the name 'edit' here and here and then other change went from 'create' to 'update_redirect'.<br>
Otherwise it was the same, and that wasn't great.<br>
So let's go through and clean this up really quick.<br>
So let's look at this one.<br>
Now there's this part which is identical to this part.<br>
Remember, it's the view model that handles a lot of the setting things up and loading the data.<br>
If there is a redirect that was passed to be edited and so on, there's nothing going on here.<br>
But I'm not going to do anything with these two because they're already only two lines of code.<br>
It's just going to complicate things to try toe centralized those.<br>
But let's go and write a function that does this.<br>
I'm gonna copy this part here, and I put it down the bottom.<br>
We're going to create a function and it's gonna be called add or edit redirect, and it's gonna take a request which is a request, and we're gonna drop that here.<br>
This is gonna work fine for this one appear, cause I literally just copied it.<br>
But down here, we want to do same thing.<br>
Let me just, we're gonna call update.<br>
All right, so we're gonna do the same thing here.<br>
We're gonna return whatever this generates either an error or some kind of redirect or something.<br>
So how do we address this fact that we have?<br>
Sometimes there's a thing being edited, and sometimes there's a new one.<br>
So what we're gonna do here is we're going to say 'if view_model.redirect_id' So If there is a redirect ID than that means we're in this 'cms_service.update(redirect_id)' We could just check for this.<br>
It might be a little safer.<br>
ID and then all these when you spell it right.<br>
That, else we're gonna do this and that's it.<br>
So this way we can have the same basic logic where we redirect them to how we handle all this stuff, and we don't have to have that code duplication.<br>
is it, Major no.<br>
Is it better?<br>
Probably a little cleaner Now it's only even potentially better if it actually works.<br>
Let's go running and just make sure this works.<br>
Over here, we're gonna view our redirect and we want to be able to add one and then edit one.<br>
So let's add our Google one 'G'.<br>
This will be https.<br>
Google And that's cool.<br>
We can test that it works.<br>
Let's see that.<br>
We can.<br>
Now can we edit one?<br>
This is the other side of the story, put an exclamation mark here.<br>
And let's just change that to not HTTP Google has this exclamation mark And if we click on test, well, we can't really tell.<br>
But if we go and edit it again now the S is gone.<br>
Beautiful.<br>
So it looks like that works One other really, really quick thing when we test it, we're actually going directly to the URL here, as you can see.<br>
What I would like it to do is actually really, really test typing in '/courses' or '/bytes'.<br>
So let's do that also.<br>
All right, here this is super Super fast.<br>
So here's the test button.<br>
And right now the url is the full url, but we want is the short url.<br>
We need to put a forward slash So let's go back and refresh.<br>
Notice this is '/g', ' /bytes', '/courses' But if I click, it works.<br>
All right, well, those redirects and this little redirect cms backend, I think its in a great place.<br>
And it's gonna be a really solid foundation when we move on to work with editing and creating pages.
|
|
|
|
33:22 |
|
|
show
|
3:39 |
Well, I'm pretty excited because we've come to the chapter where we really get to focus on what you probably consider as the core feature of a CMS, or content management system.<br>
that we're plugging into our Web app here.<br>
But what are we talking about with these CMS pages?<br>
Probably the best way to understand it is to compare them to traditional data-driven pages.<br>
And I will just look at an example, and then I'll make sense of these two for you if If you're not sure what I'm talking about.<br>
Here's one page from our website.<br>
We can go and dig into the details about a package.<br>
This one is the AWS CLI, the Amazon Web Services command line interface.<br>
Here's another one where we're getting help.<br>
We haven't created this one yet, but we're going to create this one pretty much as-is.<br>
This what you would get if you click that help link in the top of the navigation?<br>
At first glance, they look kind of the same, right?<br>
They have the same shell.<br>
The CSS style is definitely the same.<br>
Things like that.<br>
However, they're very, very different.<br>
One on the left is a data driven page.<br>
and what I mean by that is in the database, there are multiple entries or models that have certain pieces of information.<br>
and the job of this page is to, in a very structured way, pull out the specific version of that model from the database.<br>
So, in this case, pull out the AWS CLIs settings and fill them in all over the place.<br>
Like right here We have the name of the package and the current version that's shown on this page, and we have the command to install that package.<br>
Here we have whether or not it's the latest version?<br>
And when that version was released.<br>
So we pulled the package details from the database and a list or collection of releases from the database.<br>
We also have the summary of the package.<br>
Here we have a bunch of links that will take you say over the project description or the release history Or where you can download files from this all has to do with this particular package.<br>
There's links at the bottom like you can barely barely see homepage down there.<br>
That's of course, set in the database.<br>
And there's the description as well.<br>
Everything about this is just, I'm gonna have exactly this structure, but vary by the piece of data that we're getting back.<br>
A good example to think about this also might be Amazon, right?<br>
Like I'm looking at a book that looks the same for every single book.<br>
It just happens to have different details filled in.<br>
On the right.<br>
The CMS page is very different.<br>
It's probably stored in the database technically, but for all purposes, it's just a blob of text that's dropped on the page This "Hello", this "help with PyPI", "do you need help installing the package?".<br>
That whole section, there's no structure.<br>
It is, here is the text boom.<br>
Whatever they typed in its that.<br>
This is great for landing pages, for these help pages, for other parts where people just need to write informational stuff on the Web.<br>
But it's not exactly structured with a whole bunch of different things coming out of the database like this one on the left is.<br>
So you might ask, Why do I need to put that in the database?<br>
I could just create static files.<br>
I could go and create markdown.<br>
There's even whole things like Pelican, that will actually go and from a bunch of static files generate these Web pages.<br>
That would look like the thing here on the right.<br>
Well, that works for the core bit.<br>
But there's also other dynamic things.<br>
Notice we still have the fact that you're logged in or you're not logged in, whether or not you're an admin.<br>
There's a lot of stuff going on that still needs the smarts, needs the behavior of our data driven Web app.<br>
It's just this page.<br>
Why do we need to go write source code to create it?<br>
We don't.<br>
We should be able to just log into an admin section, type some stuff out, and now we have a help page on our website.<br>
So that's what we're gonna focus on in this chapter.<br>
Building the thing on the right.<br>
Basically, the white part of the right page.<br>
It should be a lot of fun.
|
|
|
show
|
5:25 |
so far with our CMS route method, our view method here.<br>
What we've done is we said, we use your cool little view model idea our view model pattern that's working super well and we're just going to double down on that.<br>
But we said If there's a page, we're just gonna do something super silly like, Say, here is the title.<br>
If there's a redirect.<br>
We're gonna redirect them.<br>
If there's no page and no redirect, we just say, "Not Found".<br>
But what we want to do is what you just on that last picture, a beautiful page that looks like it belongs with the rest of the site.<br>
So how do we do that?<br>
Well, that's more or less this thing I commented out over here.<br>
So we're gonna specify a renderer.<br>
And instead of doing this, we're going to save 'view_model.view_dictionary' This is close, except for we want this to be CMS, and we want this to be something meaningful, like Page.<br>
Why my calling "page" and not CMS requests like the others.<br>
Well, we're only using it for the page scenario.<br>
This one, we're not using it.<br>
And this one "404" we're not using it.<br>
So page, it's gonna be in my world.<br>
Now, let's go and create that over here.<br>
You don't have a folder yet, but we will shortly.<br>
CMS And then remember the easiest way to get one of these because they're not just from scratch pages, but in fact, they are based on this shared layout template.<br>
We want it to look like just just so we're gonna do a copy in a paste and call this page.<br>
Now, I'm gonna add one quick little CSS class here because this one we wanna have some space have padded.<br>
And actually, I'll show you what that does anything about first.<br>
So we're gonna look at real quick without the padding.<br>
Kinda bad, actually.<br>
If we go to about...<br>
Ah, it's centered, so you can't really tell, but basically.<br>
Stuff goes to the edge.<br>
It goes right to the edge, which is not amazing.<br>
So we're gonna put this little padded thing in here and it just has a little more room.<br>
Most importantly on the sides.<br>
Like I said, you can't really see it this moment.<br>
Okay, so we're gonna put that into our page template over here and then in this section, What are we gonna do?<br>
I just want to put the entire blob of text that makes up the page.<br>
Right?<br>
Well, let's do it like this.<br>
How do you put text in pyramid?<br>
You say whatever the text value is.<br>
So let's look at our view model because it tells us what is passed over.<br>
So right now we're passing a page.<br>
If you look at pages, they have a contents.<br>
Looking at our fake data for the moment, we have a contents.<br>
However, as we grow this thing, we're going to actually want to maybe have the content store to something like markdown and then generate HTML.<br>
So I'm gonna have a 'self.html = None'.<br>
And then if they'll stop page something like that, where we get the contents and set them to this HTML because this is going to get really interesting and more powerful as we go.<br>
Just kind of looking ahead.<br>
So what do we have to do over here in our little page template?<br>
We have to put HTML all right, and we probably also want to set the title and were not able to do that yet?<br>
Notice.<br>
We've got these cool little extra sections in the shared layout that weaken drop in notice right here.<br>
We're defining a slot for additional CSS.<br>
Let's go do one for the title up here.<br>
We'll call this 'htitle' or something to that effect.<br>
And if they don't fill it out, this should be there.<br>
Otherwise we can have that go.<br>
All right, So, over here.<br>
We can actually put the title.<br>
Remember we have to specify the title.<br>
Let's do it like this.<br>
That way we don't have to put title they can just put the words down here.<br>
So let's just say we had this.<br>
We had title, I believe, for our page.<br>
Let's have a quick look.<br>
Yeah, title.<br>
So we can just set it up there, maybe even make it something like this 'PyPI:TITLE OF OUR PAGE'.<br>
We don't need to send any of this, but this one, we're going to have page title.<br>
Is that what I called it, double check.<br>
Yes.<br>
Okay.<br>
This is looking pretty good.<br>
Let's go over and make sure we're using it.<br>
We're using it.<br>
Let's give it a run and make sure everything's working.<br>
We come over here we had two.<br>
These company history and company employees.<br>
It didn't love title did it?<br>
What was wrong with that?<br>
Well, where does title live?<br>
Over here.<br>
It's not called 'title'.<br>
It's on the page, right so we can say 'page.title'.<br>
Remember?<br>
Only gonna be in this page if there's on this template.<br>
If there's a proper page, here we go.<br>
"PYPI: Company History".<br>
Super and then details about our history.<br>
And then we probably want to even go and put the title again up here.<br>
Let's put like a "h1" like that.<br>
Here we go.<br>
Beautiful.<br>
Company history.<br>
Let's go to employees, our team, details about our employees.<br>
This is looking pretty good right?<br>
Now we don't have anywhere to click.<br>
Like if I click on help.<br>
That doesn't exist yet, sadly, but you can see our CMS.<br>
It's controlling the title, putting this in here and then this is just gonna be arbitrary content, not a big fan of it being centered, So we want to work on that in our CSS.<br>
But basically this is off to a really good start.<br>
There's a few things we're gonna need to keep changing, as you'll see, as we get into it.<br>
To do real stuff, but we're off to a good start showing our CMS content
|
|
|
show
|
4:20 |
Really quickly, I added a couple of CSS styles here.<br>
That 'h1' should still be centered, but that the main content of the page to be aligned left.<br>
If you look over here now, this is probably what we want.<br>
Everything centered is going to be super weird.<br>
So this is gonna be left-aligned and we can style the elements within here as needed.<br>
Okay, so that's off to a good start.<br>
Now, when you look at this, this is not super interesting.<br>
Employees, same.<br>
It's like a sentence that just lays it out on the page.<br>
It's not really content.<br>
But what I want to do is just like maybe let's write a little bit of content for this page so you can click on '/donate' and have something there.<br>
so for now, until we get to editign, let's go and just go to our fake data and add another one of these over.<br>
So this is gonna be the url, 'donate'.<br>
This is the same, 'donate'.<br>
The title will be "Donate to the PSF".<br>
And for content.<br>
I want to put something more real.<br>
So I'm gonna use, let's get rid of that that'll thing there.<br>
I'm going to use one of these literal strings like this and so we can have it look just like so.<br>
Now it's not amazing.<br>
Obviously not going to build out our site like this, But for now, let me just put this in here.<br>
So we're gonna strip it off so it doesn't have those bases there and there.<br>
But otherwise, we have some built in HTML, and it's gonna be awesome, right?<br>
Let me just rerun this.<br>
We go back, we make a request.<br>
The CMS service will ask the fake data for the donate data, and it will be there now, so it shouldn't 404 like it has been.<br>
If I refresh, it should be amazing.<br>
We should see that content we wrote.<br>
Yeah, hmm, that's amazing.<br>
It it does look pretty amazing to me.<br>
I did notice we probably should drop this by that part.<br>
What do you think about this?<br>
You're loving it out there.<br>
What happened?<br>
Well, pyramid and chameleon tried to protect us from users injecting data into our site.<br>
When would that kind of stuff happen?<br>
If I had a user forum and somebody said, "Hey, I'm going to type an answer or even a question" "I'm gonna go type it out." And normally you let them type HTML or something like that, and you show it and it's great.<br>
But every now and then there's gonna be some evil person that says, Well, let me put in a angle bracket JavaScript.<br>
Some thing to take over the page, right?<br>
Something nasty that's gonna like, look at your cookies Or do cross site scripting or something along those lines or even on the same site.<br>
So chameleon and pyramid Try to protect you from that.<br>
They won't let you put raw markdown in there unless you explicitly say so.<br>
So we're gonna do that here in a second below its get rid of this bit.<br>
We already have the HTML, the head, the title in there.<br>
Okay, so over here, we can say I know what I'm doing.<br>
This input is safe.<br>
We can say 'structure:'.<br>
That means don't protect us.<br>
Just dropped straight in the page and let it do its thing.<br>
It's part of the HTML structure that we need.<br>
If we go over here and I saved it, hopefully I did.<br>
Ta da!<br>
There we go!<br>
"Did you know you can actually donate to the PSF?<br>
Here's their link." Click on it.<br>
And now we're over there.<br>
We could even have that open in a separate page.<br>
That's pretty cool, right?<br>
So this is working.<br>
The only caveat, the only warning is you cannot use this for user generated content.<br>
So remember, the idea for the CMS is not to let users write your site, but let you say, implement this page or this page without going and writing more source code.<br>
You just go and log into the admin tool which we're gonna build shortly.<br>
Type out the details and hit save.<br>
And now you have a donate page that everyone on your team can manage.<br>
You obviously trust people that work at your company to not hack your own website.<br>
If you can't trust them to not hack your website, they shouldn't work for you.<br>
Hey, that's just how it works.<br>
You always put logging and tracking and who's done what as well in there.<br>
So this works out great for internal systems, but be very, very careful about doing this kind of thing For external ones You can use something else like markdown.<br>
We'll get to some things that will kind of sort of work.<br>
Or if you want to let people from the outside work on this.<br>
But for now, the way this is working and this particular version of the source code.<br>
Don't let other people edit that because this is open do script injection, all sorts of badness.<br>
But it looks good, doesn't it?<br>
Looks like it's working now.<br>
It's not a super amazing right, but it is taking proper markdown with things like hyperlinks and whatnot and rendering them just like a real site would.
|
|
|
show
|
1:41 |
Well, there's a lot of build up to something that was actually pretty straightforward.<br>
But again, we're going to start here and build and build and build.<br>
Here is how we're rendering the CMS page.<br>
We have a couple of things we're doing.<br>
We want to set a "H1" header that has the title of the page and we want to show structured content that is HTML that is not escaped and looks like eight small stores.<br>
But that actually makes it part of the page.<br>
So we're gonna wrap that in a div just a partition and doesn't really have any effect I suppose.<br>
When we say "structure:html" and that's gonna render that the one caveat.<br>
Remember that structure tag?<br>
That means this cannot be used for user-generated content.<br>
Someone could come along and type some malicious code, and you're just saying please put that malicious code right on my website.<br>
You don't want to do that, so remember.<br>
people who edit this or have access to the CMS when is working like this must not be given.<br>
It must not be given to untrusted people, right?<br>
So, in generally, the purpose of this site that's going to work great.<br>
But I just want to really, really drive that home because I don't want you to get in trouble.<br>
Have something go wrong with your site by not realizing what's happening here.<br>
Well, this is basically what we also added a little special chameleon section that lets us inject the title into the top of the page as well.<br>
And use that if you want, or you want the page to be the same.<br>
Leave it alone for SEO and just use your navigability right for creating bookmarks and whatnot.<br>
It's a good idea that explicitly set the proper title at the top of your page as well.<br>
You can add that in.<br>
But here's the essence of what we did to render CMS pages within our site.<br>
wrapped in the data driven stuff like the account log in status and so on.
|
|
|
show
|
3:49 |
Well to work with those pages, we definitely don't want Teoh change some weird fake data thing or even type directly on the database.<br>
We want to have a rich admin section kind of like we had for redirects, but honestly, much better with a proper editor where you can do cool formatting and hot keys.<br>
And you've got, like, toolbar buttons to help you form at the code and all kinds of good stuff.<br>
So we're going to create an admin section for pages just like we have for redirects.<br>
But because we've already done it for redirects, we should be able to blaze through this pretty quick.<br>
So let's go over here and we're gonna have...<br>
First we had redirects.<br>
Now we have pages.<br>
Again make sure.<br>
Double Triple Quadruple make sure the admin permission requirement is on there.<br>
And this can be pages.<br>
So we wont to go down here and this should be 'page.list_view_model'.<br>
We're gonna get that by making a copy of this one.<br>
We're going to call it page page_list.<br>
And guess what?<br>
Instead of request.redirect(pages) and this will be 'all_pages'.<br>
It should be super similar to the one we have all redirects.<br>
We're going to just come down here.<br>
But our create a list of our not redirects but pages and values.<br>
And that should pretty much do it for this one, I think, other than it needs the pages list view model.<br>
and Pages.<br>
Here we go.<br>
You can import that correctly.<br>
Return it and as long as we have this template...<br>
We don't have it yet, but we will in a second.<br>
Add page.<br>
Add new page.<br>
You don't need a test instead of a test we went to visit and let's look really quick over here at our fake data.<br>
Have a URL to go visit.<br>
So that's what we're going to need here.<br>
So we can save visit instead of.<br>
This will be url.<br>
That looks good.<br>
Edit.<br>
Edit Page doesn't exist yet, but it's going to be Page ID.<br>
We can just use the url, I believe, for this one.<br>
Eh, we'll keep it at ID.<br>
It makes life better, and then you just do the title.<br>
That might do it.<br>
Really there's not a whole lot more going on.<br>
We've got our admin section into the shared layout.<br>
Let's go find out.<br>
Go to our admin, we have view redirects which, of course, still seems to be working And view page.<br>
Fingers crossed.<br>
No name error redirects.<br>
Where is that?<br>
Somewhere over here.<br>
We have a redirect still.<br>
Oh, yeah, There it is.<br>
You'll probably noticed it.<br>
And I didn't So we'll say p in pages.<br>
Save that and refresh.<br>
We have r, or should I call it p, I could call it r, but that would be wrong.<br>
dict attribute has no object, no attribute 'id' That is fine.<br>
We need to go and put those in here.<br>
We did that for the redirects.<br>
It's going to be easier to change of the url of a page instead of trying to use that.<br>
So let's go over here and just put a quick...<br>
Every one of these has an id that's gonna be one.<br>
Be too.<br>
And three.<br>
Now, we should be in business.<br>
Let's give it a shot.<br>
Tada!<br>
There we go and check it out!<br>
Here's our company history.<br>
Our team and our donate to the PSF and we could visit it.<br>
That should actually work.<br>
Shouldn't it.<br>
We could visit our team and visit the donate which of course, is the same as clicking right there.<br>
Okay.<br>
Edit.<br>
Probably not gonna be amazing yet, is it?<br>
Add new Page?<br>
No, but we do have this ability to list and see them and even visit the pages, so that's a really good start.
|
|
|
show
|
10:20 |
Now that we can list the pages and we have the UI to edit and create new ones.<br>
Let's make that possible.<br>
Again, it's gonna be basically a clone of what we did for the redirects.<br>
So I'm gonna just start by copying those and adjust Will say edit page remember the edit template was used both for adding and editing.<br>
And down here, we're going to change this from redirect.<br>
Anyone have a page ID.<br>
Go and just work our way through this and then name.<br>
This would be title because pages don't have names.<br>
They have titles.<br>
So this will be page.<br>
Okay, good.<br>
Ah, the name this we can make this the title.<br>
Title of the page.<br>
Okay, there's the title Just gonna keep going.<br>
The short url is just gonna be url cause there's no other concept for these.<br>
So url.<br>
Like that and this last one here is not gonna be one of these.<br>
Instead, it's going to be a text area.<br>
This is the multi-line type of input that we can have and this is gonna be contents.<br>
That's what it's called id contents as well.<br>
Columns make this wider, say 50 rows and the value is going to be structure of contents.<br>
There we go.<br>
We want to pre populate that with this.<br>
And actually, we want to be even a little a little more careful about how we do that.<br>
Because otherwise we have, like, spaces and stuff in there.<br>
Like this, so exactly the contents of the page are always going to be what...<br>
What's gonna show there, And this will be page ID create or save Page and one more bit with Paige.<br>
I think we're close, actually.<br>
Okay, so I think this template is probably done.<br>
The other thing that has to match up with this carefully is going to be the view model.<br>
So remember, down here we have a 'edit_redirect' view model.<br>
We're gonna have an edit page.<br>
It's gonna be similar.<br>
We have url, we have title, page ID.<br>
Page ID So 'get_page_by' Maybe I'm gonna pass over.<br>
Remember that allows us to maybe change the url as we're going and so on.<br>
So we're going to get it back by this ID that we're going to put in there.<br>
And there's no errors.<br>
Finally, we just need to adjust this little bit.<br>
This will be title.<br>
I also need contents.<br>
Here we go.<br>
All right.<br>
Super.<br>
And then we're also gonna have to reverse this down here like so.<br>
We'll test if they're trying to create a new page when one already exists without url.<br>
We'll, say "a page with that url already exists." Woo!<br>
finally, if there is a page, but it doesn't exist by that ID you have to create it, not edit it.<br>
Almost there.<br>
We haven't written this have we.<br>
So let's go ahead and write that function.<br>
Where's our 'get_redirect_by_id'.<br>
It's going to be basically the same, So page ID, pages, page ID.<br>
Make that a page, and I think we'll be set.<br>
We're not going to call this "r" though.<br>
That's kind of wrong.<br>
Call that page.<br>
Here we go.<br>
All right.<br>
I think this may actually work.<br>
Ah, one more thing, though.<br>
One more level of putting the pieces together.<br>
That's how the Web works.<br>
It's got all these different elements.<br>
So let's go and do an add page and add redirect.<br>
I'll put them both...<br>
I'll put them near the top.<br>
Let's give him some room.<br>
I can work on them here.<br>
Add page.<br>
Page.<br>
I'm just going to basically replace redirect with page.<br>
Alright, So that does this one.<br>
Now I got to do the post side of things We're going to have an add or edit page.<br>
Here we go and let's take away this edit part for just a minute.<br>
I'm going to work on this Just like before.<br>
We're gonna have an exact copy.<br>
So let's just do this is to be edit page view model and let's see page ID.<br>
You an update page contents and same thing here.<br>
Let's do at page and we'll go back to the pages.<br>
Well, that's a lot.<br>
Ah, lot of stuff, right.<br>
But it's just same basic template, but obviously not going to be the same HTML.<br>
So we're gonna need to change it.<br>
Alright?<br>
So update page, we're now we're gonna say page equals get page by ID page ID.<br>
We should probably raise an exception.<br>
What were we doing up here.<br>
Yeah, we're just returning as well.<br>
So we could do better error handling, and maybe we will.<br>
But now it's going to set the various value.<br>
So age page, title, url, contents, and we probably want to clean this up a little bit as well.<br>
We'll say 'for not url'.<br>
Something like that.<br>
Then we could say 'url = url.lower().strip()' Remember, don't worry about casing.<br>
If contents == content.strip() we don't want to lowercase this one.<br>
This is the real typing contents.<br>
But we don't want to have, like, spaces and stuff at the end.<br>
All right, I think that's a pretty good And let's do the same for title.<br>
You might want to require title, but nonetheless.<br>
We can put it like this and yeah, that's a good start that lets us update the page and then create.<br>
Let's go and just see the create over here.<br>
I want to create with a title, url, and contents.<br>
Still we're gonna put the I'll just put a random number here, Random.<br>
Rand-int didn't really matter what this is, but it needs the number, right?<br>
So url, title.<br>
It's gonna be title, contents, contents, And there we have it.<br>
We're creating pages We're updating pages.<br>
Kind of flew through that without too much summarizing what I'm doing and what not because it really is just the same.<br>
But I didn't want to just say, "Oh, I copied everything."" So I wanted to have you see it created.<br>
So hopefully that was a good balance for you.<br>
We're gonna see if it's working now, aren't we.<br>
We go to our admin.<br>
Go to our pages.<br>
And this one should work.<br>
This one?<br>
Not yet.<br>
We got a tiny, tiny bit more for that one.<br>
Ah, content?<br>
Not yet.<br>
So what is the challenge there?<br>
Over at our edit page view model.<br>
We never set 'self.contents = None'.<br>
We're setting it there.<br>
But only in the case it was Page.<br>
Right.<br>
So let's try again.<br>
One more time.<br>
Oh, yeah.<br>
Pretty good.<br>
Pretty good.<br>
And this one, you don't really want it to be.<br>
'None' for contents, do we?<br>
I guess we want to put empty ''.<br>
We probably empty for all of these.<br>
One more time.<br>
Here we go.<br>
Let's put instead a placeholder for this one, and then we'll be in good shape.<br>
There you go.<br>
That's the contents of our page.<br>
And we should be able to create one.<br>
Let's go and just do a real simple on this will be simple test.<br>
All right, if everything is hanging together, this may work.<br>
No!<br>
Ah, my random int it made a long ways, but the random int.<br>
We got to put 5 to one thousand.<br>
Dumb.<br>
Let's try to submit it again then.<br>
Tada, check it out.<br>
Now a simple test if we visit it.<br>
Yeah, that's Ah, simple test.<br>
I don't think we got the contents back did we.<br>
So really, really quickly.<br>
We should check that we're doing that.<br>
Edit page.<br>
Nope.<br>
We sure are not.<br>
All right, now, I think we're gonna be in business.<br>
We could say you can't create a page without having contents, but let's just create one more.<br>
Test 2 Alright let's give it a shot.<br>
Test 2.<br>
View it.<br>
Yes, There it is.<br>
Looks like our page is working perfectly.
|
|
|
show
|
4:08 |
Now that we have adding new pages in place.<br>
It should be really, really quick to edit new ones.<br>
Okay, so over here we have add Page.<br>
Let's do edit page.<br>
Edit, really important that you don't forget to change that right there.<br>
It's gonna be the same template stuff there.<br>
This is gonna be edit page, page.<br>
Alright, it's gonna add or edit, and yeah, looks like that might actually do it.<br>
Let's give it a shot.<br>
Come over here.<br>
Admin.<br>
Wiew the pages.<br>
Let's create one that we can test.<br>
A test, test.<br>
"This is to be tested" All right, fingers crossed.<br>
Here we go.<br>
Ho!<br>
Sweet.<br>
It's not really that surprising that this works because, you know, we got it working in the request, the redirect one, and here's kind of a cool one but nonetheless, this is pretty cool.<br>
Now remember, this is, for the moment, pure HTML.<br>
So every time you want a line break, you got a little HTML bits here, but we can have some fun with it.<br>
Thing one Thing two and thing three page with this id was not found.<br>
I was feeling so good about us.<br>
So good about our chances here.<br>
Well, let's go back to admin and see what's going on.<br>
All right?<br>
Something is not working here, So let's go and dive in and back real quickly.<br>
I said get page, but it's just a breakpoint and have a quick look.<br>
Now, remember, because we restarted it.<br>
It's gonna lose that page.<br>
I gotta recreate it first, and then we can go to debug.<br>
What's up with it?<br>
Luckily, I copied that.<br>
So we create that and this one right here...<br>
Change that to a four.<br>
Oh, I see.<br>
So whatever is happening, this is just not making it that far.<br>
Let's go up a bit here with that breakpoint and try again.<br>
Alright, so something's happening along the way.<br>
Alright, it's in the view model.<br>
Whatever the problem is, it is in the view model.<br>
So where do we have that?<br>
Yeah, eight one...<br>
Ah said this string thing again.<br>
We're gonna find out.<br>
We got the page, and then.<br>
There it is.<br>
You see it, folks, it's not redirect by page by ID.<br>
Alright, start over.<br>
This is gonna work.<br>
Make sure I copy this again.<br>
Okay.<br>
Go to our admin.<br>
View our pages create a new one.<br>
We'll call it "Test".<br>
So we'll start out nice and simple and let's go at it again, and this time put our nice content with HTML.<br>
You ready?<br>
Woo!<br>
It looks like it might have worked.<br>
And of course it did.<br>
There it is.<br>
Silly little mistake.<br>
There's a ton of redirects to changed the page all over the place.<br>
And I unfortunately missed that one, but nonetheless do we have it?<br>
We have got this cool page.<br>
We can go over to our admin section and go.<br>
You know what?<br>
We didn't really want this to have that line break there.<br>
We just wanted to have, like this and then these.<br>
First one is going to be bold.<br>
So we can do this </strong>.<br>
And now if we visit that page Boom, There it is.<br>
We have this live website we could just go in and edit stuff.<br>
It's beautiful, except for when it's not because editing this is really error prone.<br>
So we're going to come up with a much better implementation foer our editor.<br>
But for now, it's working really, really well, isn't it?
|
|
|
|
37:06 |
|
|
show
|
1:06 |
For a long time we've been using our fake database, which is transient.<br>
It keep stuff in memory, but every time you restart the app, it goes away, and it's not a real database.<br>
So we're going to fix that in this chapter.<br>
What we're gonna do is work on saving pages and redirects and maybe even other information to a database.<br>
We're going to use SQLAlchemy SQLAlchemy is an ORM or object relational mapper, and it's by far the most popular way to talk to databases using Python.<br>
It's been around for a long time.<br>
It's very polished, and it's actually what we're already using for most of the website.<br>
Remember, you saw we have these packages that were listed there make it big in the details.<br>
We even talked about the difference between data-driven pages and CMS pages.<br>
All those data different pages are already handled with SQLAlchemy and already stored and managed in the database.<br>
So what we're gonna do is actually just add on to our existing database model, so we'll start by doing a quick tour of the data model as it is, and then we'll add the few extra things we need to store pages and redirects in our
|
|
|
show
|
1:36 |
Are you new to SQLAlchemy?<br>
Have you not used it before?<br>
Need to learn it.<br>
No problem.<br>
So in this course, we're not focused on learning SQLAlchemy.<br>
We're not teaching you all the things from scratch, just like we're not teaching the Pyramid Web framework or CSS or a bunch of other things.<br>
However, being able to work with the database and SQLAlchemy is super important.<br>
And if you can't do it, it's gonna be a big problem.<br>
So here's what I've done.<br>
Instead of adding on a big section as part of this course Where you need to work your way through SQLAlchemy in regardless of your experience.<br>
What I've done is I've taken the lessons that we had from our data-driven Web App course, where we literally built the first part of this application, the data driven part and we talk about SQLAlchemy.<br>
In that course, there's two chapters in there.<br>
One called Modelling Data with SQLAlchemy and the other is called using SQLALchemy And what I've done is I put that in this course, so you have access to it already and its in the appendix.<br>
If you need to learn SQLAlchemy, pause this chapter.<br>
Go back to the course page, find the modeling with SQLAlchemy c hapter and get started there.<br>
This is actually the exact project that we're using here.<br>
So in that course, we built from absolutely nothing up to what we started with with this course.<br>
We build that entire PyPI clone, including the database.<br>
So the appendix literally talks about building the data at the database access layer as we're using it.<br>
So it's the perfect appendix for what you need.<br>
That said, if you already know SQLALchemy.<br>
We're not doing anything crazy.<br>
You don't need to go and watch that, but if you need to learn it, it's there.<br>
Be sure to take advantage before you move on.
|
|
|
show
|
3:22 |
Now it's time for us to get started writing our pages and redirects into the database and using it as a more permanent place in this silly, fake thing that we've been using all along.<br>
You see, right here we have our Pipi I database that we're going to be using.<br>
So let's just do a quick tour of the A couple of the existing sequel Alchemy classes and just see everything fits together.<br>
Then we can jump right in and start writing our page and our redirect classes to put in the database.<br>
So here's something we've been working a lot with the users table, and it's modeled over here by having a class that derives from our sequel, Alchemy Base.<br>
Zell sequel Alchemy works great.<br>
One of these things, and everything that derives from it automatically gets managed by sequel alchemy.<br>
I'm using this plural lower case convention for the table names or not, calling it Capital User.<br>
But because it contains many things in the database for Collenette users like this.<br>
From here on out, it's pretty straightforward.<br>
We have a auto incriminating i d.<br>
We have the name email, someone gullible, some or not indexed for things like email if you want to find a user by their email address but some passwords and what not going on here?<br>
Here's our Boolean is admin.<br>
People who have this set to true are allowed to get to our CMS management section.<br>
If it's not such a true, you don't get there and you can see by default.<br>
New users are created as non admissions or sets how it should be.<br>
So this one's pretty straightforward.<br>
We're going to build something like this for our page over here may be the most complicated thing we have is our package.<br>
The package is complicated because it has a bunch of information on it.<br>
Here.<br>
You gonna like Home Page Docks and package or L.<br>
But it also has a fairly complicated relationship over here with an interesting default sort option and all sorts of stuff.<br>
We've got this relationship over to, like the releases of the package and so on, and that's pretty much it of these air, the classes that we're using.<br>
The other thing you've seen, probably as we've been going around, is a single devi session, and the DB session gets initialized to connect to our sequel Light Database sequel Light is nice because you don't need a database server.<br>
You don't need to set it up.<br>
It's automatically comes with Python.<br>
You probably wouldn't use it for rial for large applications, but for our simple little example, this is the easiest thing.<br>
So we just set this up in it, creates all the tables and gets everything set up.<br>
And then whenever we want to create a session, Duke were right to the database We call this function.<br>
It has basically this cool little change that it makes to make it easier to work with data after we insert it.<br>
And that's about it.<br>
All we have to do is create another class like this.<br>
Users we're gonna create a page one or a redirect one and set this up, and then it will be good to go.<br>
One other thing to notice.<br>
There's a lot of places that need to see to know that all these classes are exists.<br>
So we have this all models thing and we're just going toe every time we create some item that's gonna go into the database that we have to put another entry for it right here so there could be a page one release one.<br>
Probably some other stuff we do later.<br>
We also have Ah, limbic over here.<br>
An Olympic is for database migrations.<br>
As you change your database structure or your classes so they match.<br>
We're not gonna talk about that.<br>
It's here.<br>
You can play with it, but it's beyond the scope of what we're interested in.<br>
We're just going to create something like this and throw it into the mix and start working with pages and redirects in the database.
|
|
|
show
|
5:14 |
now, in order for us to save our pages in a redirected data to the database, we have to do basically what we're doing here with users.<br>
We have to create a class it has to derive from sequel Alchemy Base given a name in the database and give it thes field slash column descriptors from sequel alchemy.<br>
And as usual, the easiest way to build something similar to this is to make a copy.<br>
So control C Control V and want to call this page ager pages everyone else's or also the file is the poor won.<br>
The class name is going to be the single thing cause it represents one of them.<br>
But in the database again, we'll make it plural because the database holds many of them.<br>
Now let's get a bunch of that stuff out of here.<br>
We'll start from scratch.<br>
So we have two types of data that we're gonna put in here some alcohol kind of admin, auditing database management type, and then the a central core data of the page.<br>
Let's do the coordinator.<br>
First we have the URL.<br>
We'll figure out what it is in a second, and we're gonna go over here and have the title of the page and the contents of the page want to set.<br>
Those just wants us to add another line there.<br>
So we have that, then over here, any time I work with a database, it's very common to want to know, you know, when was that thing that's in there?<br>
When was it created?<br>
And maybe even who created it would have a created date.<br>
I'm not gonna set the value of just yet in the Cree 18 user.<br>
No, Maybe we should actually set this up with a foreign key relationship over to the users.<br>
But I kind of want a history of, like, you know, the email or the name of the user that was here.<br>
There's this tension.<br>
If we have this relationship a foreign key, it has to always exist to a real user.<br>
So what if you delete the user after the page was created and it gets complicated, so I'm not gonna create a relationship just gonna put like, some information so we can track them back down now for the URL is gonna be a sequel.<br>
Alchemy column as they all are.<br>
So I guess I could that for all of them.<br>
And this woman is gonna be a sequel.<br>
Alchemy String.<br>
So we're gonna have a string for this one, and actually same or those and this one as well.<br>
This one is gonna be a date.<br>
Time.<br>
All right, that's off to a good start.<br>
Now we have to think about another couple of options here.<br>
Do we want to query the page by the contents?<br>
No, never.<br>
We just want to get the page.<br>
And here the contents.<br>
We don't want we re by the HTML or anything like that.<br>
Same for the title.<br>
So these don't need indexes, but it's very likely.<br>
In fact, the primary way we're going to get a page back is to say they tried to go to this.<br>
Your l do we have a page for that girl and because we want to make queries by frequently, we're going to set an index here.<br>
This can make with lots of datas could make it 1000 times faster just by adding that little bit there.<br>
It makes it slower to write them, but it's very slow that we're creating pages and is very frequent that we're reading them to show users.<br>
Similarly, probably we don't care about Phil Dream by the user.<br>
Maybe we dio Probably not.<br>
We can always had that later.<br>
But this one you're not gonna query by date time, But we might wanna in our admin page show the newest created pages first.<br>
So over here will have an index.<br>
True, because if you order by on index, that's also much faster.<br>
Now, down here, we can say whether or not these air required, but it's a notable is false be a little bit explicit about that one.<br>
This one obviously is required with that.<br>
Maybe the contents were not required in the beginning.<br>
Now, for the date were not putting that.<br>
Instead, we're gonna put something else.<br>
We're gonna have a default value, cause, like the i D, which is auto incriminating here means we don't have to set it.<br>
We just save it without setting that value to get set by the database.<br>
We want to do the same thing here, so we're gonna set the default to be daytime dot date time dot now and be very careful if I hit enter notice it puts the parentheses here and it calls it.<br>
That would be basically setting the default to the time that the program started.<br>
We don't want that what we want us to give it a function the now function so that whenever a new record has entered, secret alchemy will call the now function at the time it was entered.<br>
Okay, so it's super easy for the editor send you down the wrong path.<br>
In that case, well, that looks like we're probably good.<br>
I think we're ready to go and create our tables here now.<br>
The final thing to do in order for sequel Alchemy to know about the page object is we have to go over to our all models here and included though super easy, which go over here and we just say import pages now all that does is it.<br>
Make sure that this file is imported into the process before we go to sequel alchemy and say, create all the tables instead of their relationships and things like that.<br>
It's possible that we don't have to do this, but under certain circumstances it's definitely required.<br>
This makes it work for the Web app as well as for the Olymic migration extensions and auto generating migrations.<br>
And what not So we definitely want to make sure that it's in here at super easy to do.<br>
But it's also easy to forget.<br>
Just we add something new.<br>
We added in here, and that sort of derives the rest of the app to know about it.<br>
All right, that's it.<br>
I think our page class is ready to go.
|
|
|
show
|
2:48 |
while we're at it, let's go ahead and add the redirect class as well.<br>
And again, copy paste is the way to go.<br>
And this turns out to be even easier.<br>
So we look over here and say, Read I Rex redirect singular green ir lower case and all this stuff actually is exactly the same.<br>
So or not, it could even change that We have Ah, you Earl.<br>
And we also have a short URL in our redirect Onda.<br>
We don't have a title.<br>
We have a name.<br>
The name is required, but we're not going to search by it.<br>
The URL is required, but we're also not going to search by.<br>
This is the destination.<br>
Nobody's going to say I want to find all the redirects that might go there.<br>
Maybe maybe you will probably not eso You can add that index later, but for this one, this is super important.<br>
This is when you come and hit like slash bites or slash company slash history.<br>
We want to quickly get back and see if there's a redirect just to know if there is get that record back, though this is the one we need.<br>
The index on this.<br>
Nothing.<br>
Nothing changes about this one up here, so I think we're good on the class.<br>
And again we gotto bring it into all models here like So Now let's look at our database real quick.<br>
Oh, here we can look at it on.<br>
Do a little refresh notice.<br>
There's no re Durex and there's no pages.<br>
But when we run this, your A D V session is going to import all models.<br>
And then in this global in it, it's going to call sequel Commie base metadata create all because these derived from sequel Commie Base and they're not in the database.<br>
When we'd run it, it should create this.<br>
So let's just to restart.<br>
Graph didn't crash.<br>
That's a good sign over here into a refresh.<br>
Check that out.<br>
We got are two tables over here in the database, and they're exactly like you would expect.<br>
Here's a short your l.<br>
And that little blue thing means that hasn't index.<br>
Here's our index for that.<br>
And what?<br>
Not the same for pages, so it looks like this was created correctly in the database.<br>
One quick note about the required fields, like the notable, were using sequel light For the moment, I don't believe sequel light supports the concept of no ability or not.<br>
No ability.<br>
So it you won't see that actually show up in the database.<br>
But on MAWR official riel database servers like Post Grass or my sequel or Microsoft Sequel server something like that, you should see the nal ability showing up there.<br>
All right, well, were ready.<br>
Our database is now ready to store these pages here and the reader X there.
|
|
|
show
|
6:03 |
Now we have our redirect sequel.<br>
Alchemy!<br>
Entity, Class created.<br>
I think we're ready to start using it.<br>
Now.<br>
We use this cool pattern of having services that isolated, accessing and talking to whatever type of data or dealing with the data structures for the most part.<br>
And so what that means is we have four functions over here.<br>
Get a redirect all redirect, create a redirect, and then get one by I.<br>
D.<br>
Owen also update.<br>
So I guess that makes it five.<br>
We have these functions, and all we have to do is rewrite these for the most part, and we want to touch any other part of the program.<br>
The only caveat is we didn't go and create a class.<br>
We had dictionaries here, So there's gonna be a very, very small thing.<br>
We have to change for that to work, you know, like the replaces always say dot get title, just say dot title when we switched to these classes.<br>
But other than that, we won't have to change how our program works at all, which is awesome.<br>
But let's say this returns a redirect year, and actually it returns an optional redirect reason.<br>
Optional is we don't know if the euro you're asking for exists in the database, so you might get nothing or you might get the one redirect you ask for.<br>
The other thing we're gonna do here is all of these data accessing parts are gonna have exactly the same thing when increase this session, which is going to be a one of these.<br>
It's equal alchemy sessions and the way we do as we say, DB session that import that got create, then later we're gonna say session dot clothes or even when we're making changes commit, then we're gonna return something.<br>
So it here going to say the redirect is equal to something.<br>
I'm going to return the redirect.<br>
That's pretty much it.<br>
This is gonna be the pattern that we're going to go for all of these.<br>
Someone good in here.<br>
Make that plural reader Rex redirects create one of these Return of the redirect Singular.<br>
Okay, Super.<br>
Now we also need our create session.<br>
And hey, while we're on it, let's do it more here.<br>
Okay, So let's just right.<br>
The top one here were coming in getting the Ural on normalizing it.<br>
That's great.<br>
Now we have to do this query.<br>
So the way we talk to the database and sequel alchemy as we say, session dot query of the thing we want to get We want to get redirects.<br>
Then we went to filter where the redirect dot What are we asking for by your URL so short your l double equals, what would pass as euro?<br>
This will give us potentially many of them back all of them.<br>
And have this Our model is we only have one.<br>
And maybe maybe we should have gone over here.<br>
We should have actually said unique equals.<br>
True, That would be good, right?<br>
So we should probably add that, But when I got to do some migrations and I'm not gonna mess with it but in yours but unique it go through because there should be only one.<br>
So this will basically be one or zero away.<br>
To say that it's equal alchemy is to go to the end and say first.<br>
Okay, If you knew there was gonna be one, you could say one.<br>
But if they ask for your old, it's not there, it's going to crash.<br>
So first and that's it.<br>
We're now talking the database getting are redirected back here.<br>
Well, let's take this idea and just keep going.<br>
Okay?<br>
So it'll be redirects, and it's gonna be a list of redirect.<br>
We say session query of read Rex.<br>
And maybe we just wanna give them back newest and first or something like that.<br>
We could order by redirect Thought it'd date.<br>
That will give him oldest to newest ascending.<br>
So we want deaths ending like this.<br>
Beautiful.<br>
All right, so that's written.<br>
I hope you see these air.<br>
Not super hard to convert, are they?<br>
Well, don't hear this one.<br>
Takes a little bit more.<br>
We're going to create a redirect.<br>
We're gonna set his values.<br>
Not set the i d.<br>
But redirect dot your URL equals your URL direct, not short.<br>
Your l equals you Got it.<br>
We're just gonna keep going like this name like so.<br>
And then we're going to go to the session and say, had the redirect to the database and then commit those changes and give it back, and that's it.<br>
Perfect.<br>
Now we come in here, we could say on these we could say strip, tell them what they are.<br>
I can see that our strings.<br>
This one is not strip, not lower one is strip.<br>
But when a short locates the name, just make sure there's no whitespace, no spaces or tabs or anything stuck in there.<br>
Now you might want to add a little test for these.<br>
They could crash.<br>
Technically, the editor should check if these air coming in as none and not allow it.<br>
But that's not a runtime thing.<br>
That's just a suggestion that we should probably put testing here.<br>
But for now is gonna leave it like that.<br>
We do have the required stuff on the view model side where we make sure that those things are all set that they're required.<br>
So it's pretty, pretty safe assumption.<br>
Now hear, this is quite similar coming in.<br>
We're gonna get the i d.<br>
Now this is gonna end up to be an integer like so.<br>
And instead of going through and doing this loop, well, guessed it.<br>
We're going to do something like this.<br>
Get it in.<br>
The redirect is gonna be session.<br>
We re a redirect when a filter it I want to say the redirect dot I dy Biggs to the redirect idea that we passed in not first.<br>
That's it.<br>
We're going to tell this one.<br>
It gives back an optional redirect, which, of course, it does.<br>
Well, these air close.<br>
Let's work on this one here in a second the update, but it looks like the rest of them are in pretty good shape.
|
|
|
show
|
6:15 |
now that we've updated the CMS service to use our redirect class from sequel alchemy rather than just dictionaries from our fake data source, this is gonna take a little tiny bit of cleanup.<br>
So let's go try to run it, and it'll just tell us where it doesn't work.<br>
So Goater admin section click on Reader X in How we didn't get any back.<br>
Wow, how interesting.<br>
Let's actually look over there and see what's going on because I guess we gotta let's just try to add one.<br>
I will add a new redirect.<br>
The name of the redirect is, Let's say the short your l is just gonna be talk, and it's gonna just take us to talk.<br>
Walk, crash.<br>
Well, looks like we're not setting of the right information that's creating user.<br>
Okay.<br>
Great.<br>
Well ah, it was not exactly the part Expected a break, but is really good that it did, because that means we're not setting all the data we thought we needed to over here.<br>
Now we want to In addition to adding that information, we need to add user name, which is a string so we can find out where we're calling that by just saying find usages, which is right there.<br>
You remember this is making sure that we have the permissions to call it, which means we must be logged in, right?<br>
Our view model already has a user, and then we can Let's pass, maybe have the email like that.<br>
Either name or email you get to pick.<br>
You were gonna create it.<br>
Now with this extra information mean that looked like that was gonna work.<br>
Let's give it a try over here and resubmit the same data.<br>
Oh, you know, it's great to pass it in.<br>
You still have to set it.<br>
Onda.<br>
We call that email didn't way or we passed email.<br>
Okay, great.<br>
Try one more time.<br>
Luckily, the brothers holding on, let us submit it again.<br>
Who?<br>
Look at that slash talk first.<br>
Redirect.<br>
We edit it.<br>
No, this is ah where we're going with this sort of thing.<br>
So we're coming over here, and this is all the places that we're doing dot Get So let's go over here to this redirect, and it knows I'm pretty sure.<br>
Yeah, it knows it's a redirect object, which is great because we told this one.<br>
It returned an optional redirect.<br>
But now we can just go there and say short.<br>
You're actually this is nicer.<br>
It just requires a change.<br>
So here there's just not euro and dot name.<br>
And then, yeah, I think that might actually be it.<br>
This getting is not from the data visit from the submitted form, which still has to be a dictionary like this.<br>
All right, I think we might be ready.<br>
Let's go and try to edit it.<br>
Yeah, the Rio first redirect are quite felon and talk, and then this.<br>
We haven't yet written the part where we're actually going and updating this.<br>
We're gonna do that.<br>
But let's go and see if we can do our listening.<br>
Now you are listening.<br>
It's not pages.<br>
Our redirects actually works.<br>
Great.<br>
Okay, So super super.<br>
Let's go and write that last little part here about updating the redirect.<br>
Now we have this cool trick.<br>
We got the redirect using a function we already wrote, and then we just made changes to it because it was in memory.<br>
Now, remember, we're closing the session and we don't really have access to the session when we call it this way anyway.<br>
so we kind of got a do it from scratch.<br>
Let's go over here and just take this.<br>
So number here will say session dot clothes do it like this will be a little bit nicer.<br>
Try finally session dot Close.<br>
There we go.<br>
Maybe we should do that.<br>
Up here is well for some of them, but whatever, we'll leave it now Over here, we want to set the values.<br>
So we get our session back when I say redirect.<br>
What are we passing in?<br>
Name equals name dot Strip Put your l lower.<br>
That's trip and what's left.<br>
You are all no.<br>
In the lower cases, Maybe this one matters.<br>
Then we just say session dot Commit like that.<br>
You were okay.<br>
I think we're ready.<br>
So we're gonna come in here.<br>
I'm gonna get the redirect my i d.<br>
If it works great, we're gonna keep changing.<br>
Otherwise, we just bail out and close the session.<br>
Now we're going to make the changes, push them back to the database.<br>
All right.<br>
I think we might be ready.<br>
Try to edit one of these.<br>
Let's edit add a new when it edit it, But say this is gonna be Python bites and this will be a fight, all right of him?<br>
Great.<br>
Maybe we said, Oh, you know, that was supposed to be bites.<br>
So let's go over here and change it to bites plural.<br>
And it's exclamation mark just to show some stuff.<br>
It's changing home now.<br>
Final thing to do with our reader, Rex is to see if we go to slash bites.<br>
It goes somewhere already.<br>
Test it.<br>
No, this is one last thing.<br>
So let's see where this went wrong.<br>
It's again.<br>
We're just thinking of the redirect as a dictionary, which it no longer is.<br>
So this is your el I think that might be it wasn't a lot to it, but let's go now try bites again.<br>
it looks like our redirect stuff in the database is working.<br>
Great.<br>
Go to admin.<br>
Get of you.<br>
Redirect.<br>
We saw that we can edit it, and when we test, it goes, and I guess, Final thing.<br>
Let's just go look at the data base.<br>
Make sure it's in here.<br>
Super cool.<br>
Check that out.<br>
So we've got our i d one r i D to created date is basically now used to creating user Michael at talk by Thunder FM.<br>
Short your l.<br>
Here's the name.<br>
Yeah, this is great.<br>
We're now storing this in the database, which is, of course, the way we want to do it.<br>
Just wanted to focus on building the redirect infrastructure and admin section and all the ideas before we got to this.<br>
Well, it's great that we're here.
|
|
|
show
|
4:13 |
we saw it was pretty seamless to move from redirects being dictionaries under this fake data place over to actually storing redirects in the database.<br>
In fact, it was kind of as amazingly easy, which I think is great.<br>
It speaks to the patterns that we're using as well as to the power of sequel alchemy.<br>
Well, it's the time to do the same thing for pages.<br>
So we're gonna go over here and have an optional page that we want to return from here, which is the class that we wrote.<br>
It's gonna be really similar to work on these five methods as well.<br>
So again, we're gonna say session equals db session not create, and then session dot clothes.<br>
And I decided I do kind of like that.<br>
Try finally pattern, cause it lets us write things like this Instead of getting the page and returning it down here, we could just say return whatever this will save return session.<br>
Not queried, not of redirect but off page filter Where the page out?<br>
What are we looking for?<br>
The euro equals the past in your oral.<br>
First has it.<br>
Now we're getting the page out of the database.<br>
Isn't that ridiculous?<br>
All right, so let's do the same thing here.<br>
We're going to get all of them, create session, want to close it, and instead of saying first or even instead of doing a filter, we're gonna dio and order by pages Do created date dot Sending again and let's say not all.<br>
So we're sure that we get them back.<br>
When were we doing up here?<br>
In our list dot Aulas.<br>
Well, just to be sure looks like it was working, but nonetheless, it's always good to be explicit.<br>
Okay, so here we're getting all of the pages or getting a single page.<br>
This one is gonna be really similar to the one that we had were getting by euro.<br>
But instead of Korean by Euro, we're just going to say I d is I d and must be explicit about the types appeared.<br>
That's not gonna be an integer.<br>
And it's gonna return an optional page.<br>
Cool.<br>
Now an update.<br>
Remember, we got to get the page, but we can't use this one cause the sessions close so we won't be able to commit it back When I say get the page is like this And if there's not a page or not the URL we'll get out of here.<br>
So I will say you are l You were great.<br>
And then and go basically do this part on the inside.<br>
Laura Casey or l set the contents to strip set the title of the Strip and we're gonna update it.<br>
But not like this one to say dot title Got your URL and dot contents and he would just say session dot Commit.<br>
We're almost there.<br>
Now go and copy this.<br>
It's gonna be actually similar down here.<br>
We want to set all of these things.<br>
So instead of checking for this, we're gonna trim those back.<br>
We're going to create a new page here.<br>
Page equals page like that.<br>
Set the title, and we got a say session dot add page and commit.<br>
We're not doing any tests and returning, so we don't really need this.<br>
Try finally thing Super.<br>
It looks like we're gonna be in to create a page Now, remember, it's not gonna work exactly right, because in our view, models we still have to update.<br>
If you think so.<br>
Let's just jump over there and fix that up as well over on page.<br>
Noticed the type hints are already telling us They're already helping us here.<br>
So let us find all the little errors, which I just love those.<br>
So you're l title contents and then page list?<br>
No, it doesn't look like it matters.<br>
It does look like we can clean that up a little, but nothing really to change there.<br>
And then, yeah, I think, Hey, we might be in good shape already, other than we don't need some of these things.<br>
Super.<br>
Well, I looks like we've updated our CMS toe work with the database for pages instead of our fake data.
|
|
|
show
|
4:15 |
with the CMS service updated in the view models in place, we might be able to just have this work not 100% sure about that.<br>
But let's give it a try.<br>
So in a way, those pages go to admin.<br>
All right?<br>
I've tried this view pages, Nothing broke.<br>
Let's add a page.<br>
Now, I'm gonna go borrow some of this from our fake data that we had appear One of them waas donate.<br>
We had donate and donate to the PSF when we had those contents.<br>
So it's this one's gonna be just donate.<br>
And we had these contents we wanted to put in there.<br>
So let's put him in there.<br>
See what we get repaid.<br>
Fingers crossed.<br>
No.<br>
What do we miss?<br>
Creating user not passed along just like we had before.<br>
So no problem.<br>
Let's do that really quick.<br>
So create pages will be user email and let's go and set the types on all of these.<br>
Say it returns a page.<br>
Let's return the page.<br>
There we go.<br>
Technically, we're not using it.<br>
I also noticed this is a great out are not using that yet pays creating user equals user email.<br>
Now how we should be able to do this.<br>
Except for we're no longer calling it correctly here.<br>
This is gonna be VM not a user dot email again because this is only called by these ones that require admin Means you have to have a user.<br>
Don't need to check for that.<br>
Should be there.<br>
Can we create that?<br>
Page Will donate.<br>
Exist?<br>
Yes.<br>
Donate exists.<br>
And let's test it.<br>
No, no page attribute Has no get All right.<br>
Almost there.<br>
Almost there.<br>
I guess we didn't check in that part of our the models, do we contents?<br>
Yeah, I think that little little tiny change there might be all we needed.<br>
There it is.<br>
Check it out.<br>
Now.<br>
We're over on our site.<br>
We go to donate, get a donate to the PSF.<br>
Here is the content you can inspect element on it and it looks just like what we have in our database.<br>
How cool is that?<br>
So we have our website up and working.<br>
Let's go and go to the pages.<br>
Let's add the other two pages just so they're still around.<br>
There are fake database and this one company history details about company history and I have the employees as well, which we're gonna call our team details about our employees.<br>
Cool.<br>
Now we should be able to go to those pages.<br>
And just like before, company slash history comes up with us and our team as our team open the top.<br>
Our team right there, details about our team.<br>
And, of course, the most important one we click on.<br>
The Donate gives us the right thing.<br>
Finally, unless your seat in the database course it's gonna be there, right?<br>
But let's go open that up and here they are, created them again.<br>
Creating user is me.<br>
There's all the details you would expect.<br>
And there's even the contents of that one, which, you can see is like got the little new lines, their line breaks in it all the kind of stuff that we would hope that it has.<br>
Perfect.<br>
We're now over in the database using sequel Commie as we should Be, and it's to celebrate.<br>
Let's go and delete that sucker right there.<br>
Ah, let's view the usages so or technically not using it, but it's still imported in the CMA service.<br>
Get rid of that reruns.<br>
Safe Delete.<br>
Okay.<br>
Yeah, I think we're ready.<br>
I don't know why I did it and already deleted.<br>
That's what that was.<br>
It's just gone.<br>
They're cool.<br>
We're no longer using fake data.<br>
Everything is stored in the sequel light database right there.<br>
We already had a ton of data in there, Remember, we had.<br>
If we go over here like all of these things are already stored in there like Boto three and all the details about it, those were stored in there.<br>
But now, in addition, we have our redirects and our pages also stored in the database.
|
|
|
show
|
0:56 |
Let's quickly review how to insert an object into the database with sequel alchemy.<br>
It's pretty easy.<br>
We've moved the ability to create these sessions or in sequel Commies Nomenclature, a unit of work over to this DB session class.<br>
All we have to do is call, create, and it sets everything up just the way we like.<br>
We create one of the objects we want insert.<br>
So we want to insert a page.<br>
We just created a age variable, which is the new page.<br>
We set the things like title in the Euro and the contents and make sure that you normalize them like that.<br>
The euro's lower case that makes a lot easier and so on.<br>
And then finally, we're going to add that to the session and then commit the session.<br>
That's it.<br>
Now this pages in the database and we can start going quarry to increase for it.<br>
Like give me the page by its URL.<br>
Or if you knew the i d.<br>
You got it back right set by the database.<br>
When you get it back, you could work with I D.<br>
And why not?<br>
That's it.<br>
Secret alchemy is pretty awesome, isn't it?
|
|
|
show
|
1:18 |
once we have objects in the database.<br>
Well, hell, we want to get them out, and getting them out is pretty similar to what we have already done.<br>
So here we're gonna again create a session and then the end, we're gonna close it.<br>
But we want to make sure that the euro is also normalized the same way as what we put into the database with a lower case and stripped your l.<br>
And then we just say, session dot query of the object we want to get.<br>
So page the type name, then we filter, but in one or more constraints, so page dot your URL is equal to the earl they passed.<br>
And because we want either one or none were going to say dot first and I'll give us if there's any records of the 1st 1 I get, which should be unique.<br>
And then otherwise we'll just get none and say, you know, there was no page with this, your l and then finally used this.<br>
Try finally block to close the session to make sure that it's cleaned up and gone.<br>
Everything's nice and put away.<br>
Now.<br>
When we run this code, it's going to convert this to the database query language Select Star from pages where page or L equals Do some parameter where the parameter is.<br>
Of course, what you pass in in this case were saying Maybe it was company slashed history for the value of the girl that got passed over.<br>
That's it.<br>
We can now go and do queries for pages from the database.
|
|
|
|
16:37 |
|
|
show
|
3:18 |
well, the CMS that we built so far with our pages and read Rex.<br>
I think it's a big success.<br>
We've come a long ways we can create these really cool pages.<br>
We can create these redirects that allow us to have short little euros to send people to either other parts of our site or to external sites.<br>
But there's a problem.<br>
The problem is with HTML.<br>
You might think I want a website.<br>
Websites are written in HTML, so I have to write HTML for my CMS.<br>
Well, no, actually.<br>
So here's some HTML and this is the HTML for this page here.<br>
We wanna have this cool helpage that when we click on the help it says, Here's how you get help with Pipi.<br>
I do you need help installing Pip?<br>
Do you have the right version?<br>
Do you have permissions?<br>
Here's the instructions on what the each time we had we thought would create this page.<br>
But what it actually created was, Oh, this.<br>
What the heck is this?<br>
Why are all the words so big after it says have Pippa installed question mark, Look carefully.<br>
You can see there's something wrong with the closing tag for that age, too.<br>
So here's the problem with HTML.<br>
If something goes wrong, even just a little bit, we forgot a less than angle bracket left symbol here, character here, just one.<br>
The rest of the page is broken, and not just the page that contains the content we wrote.<br>
No, this is even the additional stuff that the site might generate right, for example, the footer and other things.<br>
The whole site is broken.<br>
And while this may be fine for Web developers, if we're kind of right content on the Web and let non developers work on it, I mean, that's one of the huge benefits of these.<br>
CMS is we can give it to marketing people or editors or authors and say Here, just go right that page right this landing page or write this marketing content.<br>
We don't want them to have to get this exactly right.<br>
And even if you are a skilled Web developer, you probably also don't wanna have to get this exactly right.<br>
So do we dio well marked down to the rescue.<br>
As a developer, you probably have heard of Mark down by this point, but just in case you haven't been living in a cave under a rock or something.<br>
It's this format that lets you write in simplified text but then is transformed into HTML and other formats.<br>
So here we have on ordered list.<br>
Do you have pip installed?<br>
Is pip the right version?<br>
Do you have permission to install it and so on?<br>
And what's great about this is that we don't have to close the tags or anything like that, kind of for bold and stuff you do.<br>
But for the most part, things don't go either wrong at all.<br>
Or if they do, they go much less wrong.<br>
Then otherwise, now, look into this.<br>
You might think I can't hand this to a marketing person or a business person who's not a developer.<br>
That's gonna mess it.<br>
This looks crazy.<br>
Well, is that where we are for now?<br>
But as we go through this course as we integrate marked on and we're also gonna add a rich editor that supports hot keys of, bold its control or command to be what I was highlighted, that's bold.<br>
You want to make it a header.<br>
There's a hot key for that, and there's also a toolbar at the top.<br>
So we're gonna have a really nice editor to create these market on pages and then turn them into that page that we really wanted to build at the beginning.
|
|
|
show
|
2:33 |
here we are in our next copy of our source.<br>
Good.<br>
Here.<br>
You can see it's chapter eight mark down and templates.<br>
So it made a copy of what we had from chapter seven, and we're gonna start working on it from here Now.<br>
Quick admin note here.<br>
I've changed this around a little bit.<br>
So that were now pulling the requirements about txt file which didn't exist.<br>
Created one in and using that for their requirements.<br>
I just find it, it'll be easier to have stuff managed, especially with tools like depend about and whatnot.<br>
So we're gonna do this, Maynard.<br>
No major change, no functional change.<br>
But we now have a requirements that takes t we're gonna use as we're gonna need to start adding yet still more libraries to this whole app.<br>
Okay, so for this one, let's just enter some markdown content will just get this started so that we could actually turn it into something if we want it.<br>
So we're over here.<br>
We're automatically logged in from our cookie.<br>
We're gonna go to the admin section, go to the pages.<br>
We don't yet even have a slash HelpAge.<br>
Sorry.<br>
We can't find that page So let's go create it, though.<br>
Out of page to be getting help with high P I your l is gonna be help in the contents of the page.<br>
Well, here's where we write mark down So we just say something like this.<br>
So here are a few tips in and mark down.<br>
If we want on ordered list, we just put a star.<br>
So do you have pip installed?<br>
Now we can also make stuff bowled by putting double stars.<br>
We could make stuff look like code in line if we put these little back ticks.<br>
So that's like right above the tab button.<br>
So here's a nice little bulleted list.<br>
And then if we want headers, we have each one's like this h twos, h threes.<br>
I'm gonna go for H two because this is going to be the H one.<br>
So we'll just dio you have pip installed and so on now actually wrote that whole thing out.<br>
So let's not, you know, diet the whole thing in.<br>
I just want to talk a little bit about Mark down.<br>
So here we go.<br>
Here's our page.<br>
Awesome.<br>
Let's go get some help.<br>
Yeah, that's exactly what I was hoping to build.<br>
It's beautiful, right?<br>
This is really an improvement.<br>
No, this is not an improvement.<br>
Obviously, we can't just throw markdown into the page and have that work.<br>
We have to transform it.<br>
So we're gonna talk about how we're gonna do that in the various options.<br>
We have to make that happen.<br>
Do we have the content?<br>
Now?<br>
We just have to go over here and teach our site how to transform that over to what we want over to HTML.
|
|
|
show
|
2:04 |
now really, really quick.<br>
There's one thing we have to address that when we moved from our fake data over to the database, we didn't quite get right.<br>
Look, if we go over to this page here and we try to edit it, it's gonna be great.<br>
We could just edit the page, right?<br>
Yeah, not so much.<br>
Well, what is the problem?<br>
The problem is this four here and says air binding parameter zero.<br>
Probably an unsupported type.<br>
And it's where page idea is equal to something.<br>
Look at our Pedro, quick.<br>
So our pages here, the i d.<br>
Is an integer.<br>
Now we're comparing that over here when we go to our view model and we say get page by i d and we're passing over the page i d And it's supposed to be an integer great.<br>
And then we do this like so however what you'll see right here This this is actually coming back as a string and Python PyCharm just wasn't able to see this mismatch.<br>
If I tell it explicit what it is, it can say.<br>
Oh, no, no, no.<br>
You actually can't do that.<br>
I don't know what you're thinking.<br>
If I put into your not doesn't.<br>
It doesn't know.<br>
So we need to convert this to an integer, which is problem.<br>
So let's say it and let's just put minus one or something.<br>
So in case there is no value, we're not going to get something that will crash.<br>
Trying to be converted to an integer It just come back is minus one, which never exists.<br>
All right, let's just try that again.<br>
Oh, no, There's still one more problem.<br>
Let's go.<br>
Actually, check this out.<br>
We made another mistake here.<br>
Where pays ideas equal to I de nu Nu Nu.<br>
This is not the function that has nothing to do.<br>
This I d.<br>
Here we go.<br>
Let's try this.<br>
My good.<br>
Now.<br>
Yes.<br>
Alright.<br>
Sorry about that.<br>
We got this working and consider just skipping over that and fixing it.<br>
But the same time, I do want to let you know if you run into that problem.<br>
What?<br>
What It was.<br>
Let's just make sure that we can also edit a redirect.<br>
Yeah, it looks like fine without oh, notice of the page that it are.<br>
Redirect.<br>
Yep.<br>
Looks like we can edit the redirect.<br>
No problem.<br>
Okay, great.<br>
Well, it looks like our admin is now working once again.
|
|
|
show
|
6:36 |
we've seen our page looks pretty awesome, doesn't it?<br>
No, it doesn't.<br>
We have to convert this to HTML.<br>
How do we do that?<br>
Well, you definitely don't want to go and try to convert it yourself in Python.<br>
There's many libraries, and of course, there's a great library here as well.<br>
So let's go over to our requirements, Doc here.<br>
And let's put in one called Mark down to.<br>
There's a couple of different mark town libraries we can use.<br>
But this one didn't work Well, I'll just go and let pie term install that Now.<br>
Over here, we've got our HTML is just the page contents.<br>
That's not really what we want.<br>
We want to do a little bit more than that.<br>
So what we're gonna dio is we're gonna add a function.<br>
It's gonna add a function of this thing for the moment.<br>
We're going to do something pretty different later.<br>
But for now, I'm just gonna do it here, converge, do mark down.<br>
And I guess we could say returns a string over here.<br>
We're going to write the code to convert it to mark down, and I just say it's gonna be nothing and it's going to take wouldn't pass it over to take some contents here So we can say itself dot convert to mark down and will pass over the page contents.<br>
It's going to take that and convert it well from markdown over to HTML.<br>
And it might not surprise you that were going to use mark down to the using marked down to is pretty easy.<br>
In fact, we could actually do this in one line.<br>
We could say, Actually, this is not we want to call it when you call it MD text or something like that.<br>
It is not yet.<br>
HTML.<br>
We're gonna go over here and we could just say HTML equals Mark down to all marked down.<br>
We give it the text, we can pass some extra features to turn on.<br>
We're gonna not do that for the minute, once a safe mode.<br>
But now I'm going to say true later.<br>
We're gonna want to really relax that a little bit, and then we just return the HTML and I think this is just complaining.<br>
That could be static.<br>
I don't really want it to be started for the moment.<br>
All right, let's give this a shot that one change up here where we said, instead of just trying to show the contents, were gonna take the contents and convert them to mark down and then show them that would be great.<br>
It's gonna break the other pages, but right, that's I think that's OK.<br>
We'll deal that a second, right to see if it works.<br>
00 that is so sweet.<br>
Now, you might be wondering maybe why these Look, you know, like this Red Code thing here and this looks like that and what not?<br>
It's cause we've already added some CSS styles to render code in a certain way.<br>
So it I can't remember if I added it or if it came included.<br>
But either way, if you have code blocks, then the CSS styles are already there is not some sort of magic that did that.<br>
But otherwise, this This looks really good and there's no way for us to break our page because, you know, worst case may we could leave something bold farther than we intended, but for the most part, this is it.<br>
This is really, really good.<br>
I think this came out great, and you could see that It's super, super easy to dio to convert this over Now.<br>
There's a lot of things we need to do.<br>
We're not done.<br>
It might look Oh, like Oh, yeah, we're We've done this and it's great.<br>
And now we're just ready to call this section done.<br>
But there's a couple of things that we want to focus on in order to get this to work better.<br>
First, we're going to need a proper editor, right?<br>
Even as somebody who is an expert in marked down, it would be nice if I could highlight this and hit command be.<br>
And instead of having my bookmarks show up, actually turn that into bold like right, This for me, right?<br>
Also, especially for people who are new, having the rich editor with the toolbar, that would be really helpful.<br>
Another one that's not so obvious is the general performance.<br>
Now, if we look at this, this small amount of mark, that might be fast enough, but let's just have a look and see where we are.<br>
We'll do just this one, so we make a request here.<br>
This page is rendering and 42 milliseconds that may or may not seem okay to you.<br>
But for example, if I go over here, this one is rendering in six milliseconds.<br>
If I go over to the admin one, this one is 8 10 8 this one at 43 starting to get long.<br>
Now it's only, you know, two pages.<br>
Let's update.<br>
That's just a little bit.<br>
Make it more realistic for a large piece of content.<br>
How do we prevent we're going to put this was a little trick here.<br>
They want to take this.<br>
I'm gonna have 20 times as much content.<br>
All right?<br>
That's just that's away toe.<br>
Put new lines.<br>
There's have 20 copies of this in Python.<br>
Now, if I hit refresh notice the bar here is longer.<br>
We go to help it.<br>
You can see it spinning for a second.<br>
Holy moly.<br>
Okay, let's go to inspect element and good or network and see how long it takes to go to help Half a 2nd 0 no, You did not just take that long.<br>
This is not gonna be OK, especially in high traffic websites.<br>
It's not OK for pages to load this slow and even on traffic sites that don't have a lot of traffic you still wanted to be super super quick.<br>
You wanted to be the eight millisecond variety.<br>
Not the half a second, So we're not done.<br>
But we do have all in place, I guess.<br>
One final thing that we could look at.<br>
Here, let me go ahead and take this off.<br>
Yeah, I'll leave this bit in for you, just in case you want to play with it.<br>
One of the thing that work on, I guess really quickly, is our other pages.<br>
Does this page look OK?<br>
Actually, beautiful.<br>
He it does.<br>
So most these other pages, they don't really have much of this one notice we have it in safe mode.<br>
So this one's not gonna work.<br>
Let's go ahead and just fix that one real quick.<br>
Edit this instead of saying all this HTML junk, we can just write it like this and mark down the way.<br>
We have hyperlinks as we take the content that we want to show the hyperlink text when put in brackets and we put the link we want to go to in following from disease.<br>
Here we go, David, There we go.<br>
All right.<br>
Working again.<br>
Now we have our site using marked down.<br>
That was pretty easy, right?
|
|
|
show
|
1:18 |
now the markdown were allowed to write in this section is actually fairly limited, marked onto supports, additional things like tables and larger code blocks and whatnot, which are not appearing here.<br>
So let's do a really quick addition to make this nicer, more flexible and honestly more powerful.<br>
So if you go look at the mark down to documentation, you'll see there are all these plug ins or these extras that you can have.<br>
And I'm just gonna paste a couple that we're gonna use here list that have different sorts of alignment, a better code rendering best code blocks and then tables.<br>
There's other things you can add.<br>
You can check it out, but these were the ones we're gonna add.<br>
We just go over here, say extras equals those values were passing in.<br>
And if we just rerun it, have a look, but or HelpAge.<br>
Now things look a little tiny, bit different, like, especially around the code.<br>
This part, if you have multi line blocks of code, this is gonna be much, much nicer.<br>
Let's just do a quick back and forth.<br>
Here's the old one.<br>
Here's the new one.<br>
We're not writing any tables here.<br>
But of course, tables would not have worked here.<br>
Tables will work over here for now and so on so we can extend the type of mark down that we can right from just basic marked down to these extensions.<br>
If we go in, enable some of these extras in mark down
|
|
|
show
|
0:48 |
Let's just quickly review how we render or convert Mark down over to HTML and this is it.<br>
This is all of it.<br>
Why is it so short?<br>
Because we get to use the awesome marked down to library.<br>
We don't have to write all the tricky work to do that convergence.<br>
So we just make sure that we install and then import marked onto.<br>
We specify the extras, the extensions to standard mark down that we want to use.<br>
Especially for us.<br>
It's fence code blocks in code friendly and tables, probably at some point.<br>
And then we just say, Go to the market onto Lybrand, say, mark down, give it the text, passing the extras.<br>
And for now, we're using safe mode equals true.<br>
That gives us our HTML and we just throw that in the page and boom, we have, ah, much, much nicer way to represent the content of our pages without the dangers of HTML and yet it looks like HC melon because it
|
|
|
|
14:01 |
|
|
show
|
1:55 |
so far, we've been able to write, mark down and have our website render it.<br>
I'll be a little bit slow, and we're gonna work on that soon.<br>
But what we couldn't do is edit it nicely.<br>
We had to write in just a silly text area thing in our Web page, and it knew nothing about the format.<br>
There were no hot keys like command be, wouldn't bold our code of We've selected something hit command be so we want to add that capability to our site.<br>
So the idea is we want to go from this basic text area like this, and this is already kind of advance.<br>
You can see it's like showing different sized fonts for the things and so on.<br>
But we want to go from just a text area to something like this, where it is actually rendering the text a little bit better.<br>
Where we have this toolbar and we have honkies.<br>
Of course, you can't see hockey's, but they're here, right?<br>
You can hit command, I for I, Tallis, ease or command be for Boulder control, your own Windows or Linux.<br>
So that's the goal of this chapter.<br>
Now, like many things either in Python or in general and programming.<br>
We don't want to build this.<br>
This is a lot of work we could we shouldn't.<br>
So what we're gonna do instead is we're gonna use an existing one.<br>
And I've chosen simple mde, simple markdown editor.<br>
That title seems kind of redundant there, I guess.<br>
But anyway, simple mt dot com That's what we're going to use now.<br>
Just this is not the only choice.<br>
There's a lot of markdown editors, but this one is simple.<br>
It has beautiful views.<br>
It has really nice features.<br>
It has the hockey's that I want and so on.<br>
So if you find one that's better, that you like better, that works better.<br>
That's fine.<br>
This isn't the newest or the latest or the greatest, but this one is really good and really well, simple, Hank, the name said.<br>
So we're gonna plug this into our Web app, and you're going to see the back end editing experience goes from not so great, even for people who know Mark down well to a really nice editor for even people who are not super knowledgeable about writing in
|
|
|
show
|
2:53 |
Well, let's go and stall.<br>
Simple, empty for a project.<br>
So I'm gonna come over here and notice that we now have a chapter nine rich editors section This is in our get help repo and what we want to dio e.<br>
I guess this lost his little mark as a resource route.<br>
Doesn't really matter, but also and at a bank for consistency.<br>
So what we want to do is we want to go over to our static boulder here, and we want to basically enable this website and specifically the static file section to be able to manage node Js models.<br>
Why no jazz?<br>
Well, because that's the way that we install it in the dependencies for simple Indy, which other ways as well.<br>
But that's probably the best one today.<br>
So let's go open this, I guess In Finder, for just a second over here, you can see that we've got our CSS and our images thes air the things we control.<br>
But we also want to let node manage some stuff here in the most, serve it directly out of a sub folder.<br>
So we'll just go into this folder here and again.<br>
It's this place and we're going to say in PM in it now, this in B m is the package manager.<br>
It's like pip off Python.<br>
If pip of note.<br>
If you haven't Mestre that before, and the reason we're creating a little package definition here so that will install the files here and what not otherwise they'll go a Tory user account, potentially.<br>
So we don't want that.<br>
So it doesn't really matter what we put for this.<br>
And now you can see we have a package dot Jason and it doesn't have much information in there.<br>
It's just like, here's the name of the project.<br>
We're not really going to use that.<br>
We're going to use the next thing that gets created.<br>
So now that we've done this, we can say in PM, install simple mde bash Dash saved saver thing right here.<br>
Okay, so we hit this.<br>
It's gonna do some work to go grab all those pieces.<br>
That was pretty quick.<br>
Now it installed five packages into the node models.<br>
If you look there, we have simple India, but we also have type O.<br>
J s marked the code mirror spellchecker all the libraries that simple MD needs to use to work.<br>
We don't have to do anything toe work with them.<br>
We're just gonna work with simple MD.<br>
But these do you have to be installed in around for things to work?<br>
Of course.<br>
So we come back here and now you can see why Tom automatically knows to ignore that.<br>
We have this locked file that talks about the versions of everything that got installed, most importantly, this one.<br>
But then it's dependencies as well.<br>
All right, well, we've installed simple Indy.<br>
And whenever we want, we can use this on any part of our website.<br>
And because node modules, if you go down here simple, MD dissed like that.<br>
These pieces, because these air subdirectories of static pyramid and nginx and however other ways that we happen to host it will lead us to serve these up directly.<br>
So this is the right place to store them without making changes to our site, to serve them from somewhere else.
|
|
|
show
|
1:43 |
If you've used no GS before to manage JavaScript dependencies, then this is no big deal.<br>
But let me just run through the steps of installing simple MD to make sure that you all can follow along now to get started.<br>
You need tohave in PM and note installed.<br>
We're not actually gonna run stuff with note, but having it there allows us to do in PM stuff, which is pretty cool.<br>
So you want to solve that?<br>
Once you have it installed, we need to create one of these package not Jason files to get no Jess in PM specifically to save the installed libraries in this location.<br>
Basically, you tell in P.<br>
M.<br>
This is the top level of this package you're managing.<br>
So install stuff into subdirectories year, not your user profile or something like that.<br>
We say in Puma Net we don't really care about the setting.<br>
So we just hit enter all the way through and yeah, it looks great.<br>
It creates that package, not Jason file.<br>
Finally, we say in PM, install the package dash, dash, save it downloads.<br>
You can see simple MD, but it also goes and gets four other libraries, so it added five packages from 862 contributors and then autumn for security vulnerabilities and found zero perfect.<br>
So we have a up to date.<br>
Simple MBE, then presumably is pretty safe.<br>
It's been somewhat checked, at least so we've got that installed and you can check by just saying Tree trimming the directories only four level steep and so on.<br>
And then you can see basically down here we have Simple MD, which has a debug, a dissed in the source code.<br>
We really only care about the dest part.<br>
That's all we want to work with.<br>
But it's easier to just let no Js and NPM manage it.<br>
So I'm just gonna let it install the other junk and tag along, and that's it.<br>
We have simple MD installed in our static folder and already to start using
|
|
|
show
|
5:48 |
Now that we've downloaded and saved simple mde here, it's time for us to start using it in our admin page.<br>
Let's go have a look at what we have so far.<br>
Look over here to our admin section and we go to the pages and we can edit one of these.<br>
You can see here's to mark down.<br>
That's pretty cool.<br>
Scroll down.<br>
But you know, if I highlight this and I hit command be well, my bookmarks show up.<br>
That's not amazing.<br>
And if I hit, interfere noticed.<br>
That doesn't say, Oh, we're going to continue this a Nordic bulleted list here.<br>
None of that happens.<br>
So we're gonna add that simple market on editor to this text area right there.<br>
That's what we're after.<br>
Now that's this page, the edit page template, and we're going to do two things we need to add the CSS.<br>
So remember there were styles like we saw the icons and whatnot for the site, and then we also need to add the JavaScript to make it be more full featured.<br>
So let's do the first thing here.<br>
Let's add some additional script here.<br>
CSS gonna go to static and now we're gonna go to Node.<br>
That's not do this way, is it?<br>
I try this maybe will give us some auto complete.<br>
Here, last static.<br>
Here we go.<br>
Knowed modules.<br>
And in here we have simple mde.<br>
And in here we have a dist.<br>
And in dist!<br>
What do we have?<br>
We have simple MD men CSS all right.<br>
And we want to tell PyCharm That's not misspelled, because you know what?<br>
It's not, and we go ahead and just change this to the styles.<br>
But I don't really like this request thing anyway.<br>
Rio Perfect.<br>
So that's the style and noticed this additional CSS thing from this shared layout.<br>
Now let's go look at that real quick, over and shared.<br>
If we look, you can see there's this section where we're sticking in this extra slot and I think we also want to say omit tag.<br>
It's true for this one as well.<br>
I'm not sure pretty sure that matters.<br>
Yeah, So when we say that there's thes additional CSS libraries there, No, here and similar to that at the bottom.<br>
This for the little editor.<br>
If we say true here, you know, make it nicer at the bottom we have an additional Js.<br>
So we're gonna put our JavaScript libraries there as well go including this A little bit.<br>
Probably easiest.<br>
And that's Js and this can be true.<br>
Just noticed.<br>
Like it gets a warning on.<br>
The editors want to put that away.<br>
It would be fine to just leave it that way, but the editor is freaking out, so let's keep it happy as well.<br>
Now this section we need to use the simple Js library.<br>
So we're gonna go over here and say there's a script and the source is equal to slash static node, Same thing.<br>
But for the JavaScript like that, we go now.<br>
We have that added and this is close.<br>
The next thing we need to do is tell Accrete one of these editors and pointed at the right section.<br>
So if you go up here and look, our text area has i d contents.<br>
Okay, So the money to go in here on a Cree Little script section and we're gonna say Let editor equals new simple mde.<br>
Now we can pass in some extra info here and the extra involved we can pass.<br>
There's a ton of different configurations we could override the hot keys but could override the icons.<br>
We can control what's shown on the bars and all kinds of stuff.<br>
But all we want to do is say the element that you're looking for that is the basically the editor gonna go get It's a document dot Get elements by i d.<br>
We'll put on tents.<br>
Ah, like that.<br>
Perfect.<br>
So contents, That's the text editor right there.<br>
So get it by 80.<br>
This might work.<br>
I think we might need to do a little bit more work to make this go, But let's go ahead and see if this is enough over here again.<br>
Let's go view the pages.<br>
Oh yes, look at that.<br>
Here's our cool little editor.<br>
We can take it full screen, weaken, do side by side, this trifle screen.<br>
There you go.<br>
Look huge editor, and then we pop it back out.<br>
We can go side by side.<br>
There's the written version, and here's what it's gonna render as Let's go over here and add one more bullet.<br>
If we enter notice that automatically puts that bullet point there and finally notice how If I put something like this, it'll find its tell me that's misspelled.<br>
They have fun and I want to emphasize have fun by saying command.<br>
I noticed it writes the star to make it italicized and even shows in the editor What it looks right.<br>
Like we could make this in h three by having to hurry by having three to go back to 21 right?<br>
So really, really nice editor here.<br>
It's not super super fancy, but at the same time, I think it really is quite nice.<br>
Let's put these back you go.<br>
I really like that side by side thing, though it helps really figure out what you're working on, right?<br>
Even synchronizes the scrolling.<br>
So there's a lot of these different types of editors out there.<br>
But look how incredibly easy it was for us to do that.<br>
And you can even get like help.<br>
If you're new to mark down, I'll give you help here.<br>
How easy was it?<br>
Well, to go from this really unhelpful thing to this, what I'd call pretty advanced editor.<br>
All way to do is in PM install simple MD Add the right CSS at the top of the file at the right script at the bottom of the file.<br>
And then finally we have to go and create a new instance of these simple MBE editor by pointing at the text area.<br>
So this is up here, then don't a text area with the right i d.<br>
And that's it.<br>
Now we've taken and created a beautiful editing experience for all of our users.<br>
Those who know Mark done really well.<br>
They can use the hot keys.<br>
They get the auto complete or like carrying on lists and so on.<br>
And for those who are new, you get an even better experience.
|
|
|
show
|
1:42 |
Well, I would say that simple mde lived up to its name.<br>
It's a simple markdown editor, simple, and it's usage, not simple in its capabilities as you so high.<br>
It's really quite awesome.<br>
Actually, Over here we're going to go to the page that we're gonna include the editor on, and we don't want to include this CSS style sheet on every part of our site that's just going to slow things down and potentially even override some styles that we're setting.<br>
What we're gonna do instead is we're going toe included on Lee on the pages that need this editor by injecting it into the layout template that shared layout page through here.<br>
We're adding a link to the CSS, and that's gonna be put at the top of the page that gives it its look and feel, and to give it the behavior it's going to have to have some JavaScript.<br>
So two things basically one we're going to include the simple mde JavaScript.<br>
This were putting in the bottom of the page just for performance reasons.<br>
Technically, it doesn't really matter where it is, but it the next line does required to be at least after the definition for the contents text area.<br>
But we're gonna include that down at the bottom here and we're gonna say creating new simple MBE editor and we're not gonna take any not to make any changes to the many, many defaults.<br>
If you go to the documentation at simple MD dot com, then go to their get home page.<br>
It's full of different things.<br>
You can dio We're not interested in doing that.<br>
We're just going to go and grab it and say, Go make this thing a whole lot better by making it a markdown editor don't get contents, which is our text area I d and load it up and off it goes, and that's it.<br>
Our website feels much, much more professional for creating and editing markdown content compared to what it must have been just before we headed this right.<br>
Going to be a lot better, and people are gonna enjoy working with it way more
|
|
|
|
33:08 |
|
|
show
|
4:22 |
the markdown system that we built renders pages beautifully and it looks like, Well, maybe we're done.<br>
Maybe you don't need to do anything else.<br>
After all, here's one of the pages we created, and honestly, that looks fantastic.<br>
I wouldn't change a thing about it, but there's a few problems.<br>
First of all, we saw for large pages pages that are maybe 10 times as big as this one.<br>
The site is slow, and you might think, Well, doesn't get that much traffic.<br>
It doesn't matter that much, but it does matter.<br>
There's been tons of studies that showing that even something simple, like ah, 100 milliseconds longer Layton see, contributes to something like 1% fewer purchases on e commerce sites.<br>
Now think about that.<br>
If you do a lot of sales, that's a huge thing.<br>
It also is now starting to be taken into account for S E.<br>
O.<br>
So if there's a site that's five times as fast as yours and you have about the same ranking, guess who's gonna be below.<br>
You're gonna meet below your site slow.<br>
Also, your users not gonna love it.<br>
You're gonna pay more for infrastructure to host it all of these things.<br>
So optimizing websites matter.<br>
We're not gonna use Cloudflare.<br>
I just thought this little quote or this little statement from them was nice.<br>
So I put it up here.<br>
Speaking of S e o, you could actually check how your site is doing if you have it hosted on the public Internet, for example, if you go to page speed insights from Google and you throw for example talk Python train in here, you can see we get 100 out of 100.<br>
And this is stuff coming out of the database with no cashing.<br>
Not really.<br>
You can do it.<br>
You can make your site super super fast.<br>
But if you want to rank high, you're going to have to put in the effort.<br>
And a lot of the stuff that we're gonna talk about in this section actually does this automatically more or less.<br>
You won't have to even think about it.<br>
It's just we're gonna use some libraries that make this happen, and it's gonna be amazing.<br>
So I do want to drive home the importance of a high speed site, a quick, fast responding site.<br>
It's good.<br>
There are so many reasons that's good for the users.<br>
It's good for you.<br>
Easier to host.<br>
You don't need so much infrastructure and it's good for S e O all those things.<br>
The other core problem I think we're going to run into on most sites is that content cannot be reused.<br>
That might sound a little bit weird, but you know where we're raising all sorts of stuff in our current site as it is that whole navigation bar across the top of the footer, the overall look and feel things like analytics we might put into that shared layout.<br>
We're using that everywhere.<br>
And so it's not unreasonable to think there should be parts of our mark down that appear in more than one location as well.<br>
Let me give you an example.<br>
Re use is actually pretty common.<br>
If you go over to the talk by the on training website, you Can you pull up various course descriptions and marketing pages that tell you about the course, whether you should be interested in and so on.<br>
Here's one for the Python for beginners.<br>
Now there's a bunch of stuff very specific to that course, right, What we cover, why you care about it, who should take the course and so on.<br>
But then there's this section here where it talks about subtitles and it says this course comes with subtitles.<br>
Here's a picture of a course with subtitles in our player and how it's gonna look.<br>
So if you want to take this course and you need subtitles Well, rest assured, they're gonna be here for you.<br>
This little section and actually the green section above is talking about streaming in high D.<br>
P I as well, and that shared in many places.<br>
But guess what?<br>
We have other courses.<br>
Here's the data driven Web APS course, and you know what it has.<br>
Subtitles So we have exactly the same mark down here.<br>
Talking about this course comes with subtitles.<br>
The right Python encode course also has subtitles in its lane in Page says yes, you might want subtitles.<br>
Yeah, 100 days.<br>
A Web Subtitles also Who?<br>
Here's the thing.<br>
What if I want to change the wording here?<br>
Should I have to go back toe every part of my site and re edit that somewhere in the middle of this marked on file?<br>
No, no, of course not.<br>
We don't want to do that.<br>
It's super air prone.<br>
We could easily forget one.<br>
It's a ton of work.<br>
What if we had 100 different pages instead of just 45 or 20?<br>
Right?<br>
That's totally reasonable.<br>
And yet it's not reasonable to go and rewrite that same better code everywhere.<br>
So with these markdown pages, it would be nice if we could get section and say this marked out actually something I could reuse in other parts of the site.<br>
So that's what we're gonna dio here as we're going to switch to a library that's built on top of Mark down to and does a whole bunch of cool things, including solving all these problems we've seen.
|
|
|
show
|
2:17 |
to solve all those problems that we talked about and actually do a whole lot more.<br>
We're gonna use this library called markdown sub template.<br>
The idea is that this lets us take standard mark out and treated like these more advanced template ing languages, Jinja or Chameleon from the Web.<br>
And we're gonna be able to plug that right into our website.<br>
So it's super easy ideas.<br>
We have some markdown content when I feed it possibly into a larger piece, right?<br>
This these pieces down here might be those subtitles in the high d.<br>
P I.<br>
And here's the overall landing page.<br>
Feed that in a pyramid number into our shared lay out our CMS page PT and then render it over to the browser.<br>
It is all sorts of cool stuff.<br>
It does the cashing.<br>
It integrates with databases with a little bit of help from us, and it even has cool extensions for logging and specialized cashing and so on.<br>
Okay, so what we're gonna need to do, he's good into this extensive bility section.<br>
Now, by default, it loads the contents from disk.<br>
And if you don't do anything you want to save marked on files to a file and have them rendered as if it were Seamus.<br>
Well, you're good to co that already exist.<br>
There's no problem.<br>
But what we need to do how is have it will integrate with the database.<br>
So if we come over here and look roll down a little bit, you can see that we have to do is just define some way to store our mark down in the database.<br>
And guess what?<br>
We've already done that it's called a page.<br>
We're doing that now, though, that's done.<br>
But then we've got to implement a few methods, like given ah path or your l give us the markdown from.<br>
Basically, this library doesn't know the connection string to your database or that you're even using sequel Commie.<br>
You could be using something else so it doesn't know how you're doing that, and basically, our job is to do a tiny bit of work to make that happen, both for standard mark down.<br>
And then we could have these imported shared elements that we could treat potentially differently.<br>
For example, you might not want to let people directly request the shared content, but only use it for stuff that's allowed to be imported, but not actually directly requested.<br>
Okay, so we're gonna use this library markdown sub template.<br>
So we're gonna put that into our project, do this little bit of integration here, and we should be good to go.
|
|
|
show
|
1:55 |
So let's get started using this markdown sub template.<br>
The first thing we gotta do is put it into our requirements ball here and let's tell it that it's spelled correctly and by charm, right away knows.<br>
Oh, this needs to be installed because its requirements file.<br>
So just go and hit that, See down here and wait for a second.<br>
And alright, super, it's installed and we should be able to use it.<br>
Then we're gonna come over here and we're not gonna actually use this markdown stuff.<br>
We're gonna import some other things.<br>
We're gonna import markdown sub template like that and down here and sit a saying self dot convert to mark down, which we no longer need to do.<br>
Good comment.<br>
That one out they sell thought HTML equals markdown sub template dot There's this thing called an engine.<br>
And there we can call get page are just going to give it some euro and potentially some piece of data.<br>
The or l is.<br>
Well, self doubt Euro and the data you can see the default is an empty dictionary.<br>
So we're not gonna pass any data but like you would see over here and say this section.<br>
World War You're like passing over the your L and passing over the title.<br>
The markdown sub template allows us tohave.<br>
Variables that are replaced with content were passing in.<br>
But that doesn't really match our use case here, so we're not gonna mess with that part.<br>
So this is all we have to write.<br>
Let's give it a try.<br>
It's not gonna work as well as you want.<br>
And there's a lot of things we still got to do.<br>
They're not hard, but there's a few more steps.<br>
Let's go look at help.<br>
nope.<br>
We haven't set up the storage engine.<br>
That's too bad.<br>
So that's the next thing we have to do is we have to basically create one of these storage engines either a built in one like the file based one, and configure it or we have to create a different one.<br>
A little extension for talking to the database turns out, is really, really simple, but we do have to do that, so that's what we'll have to do to get this working next.<br>
But we're actually pretty
|
|
|
show
|
6:46 |
next up to use this with our database, we have to.<br>
Either we could use it with file system and we got a set that up and give it a path and basically say, Here is your top level directory.<br>
Much like to say this templates folder is right here for that part of the site.<br>
Or we have to create a separate one that implements some other way to do things like, for example, the database.<br>
So we're gonna go over here and we're gonna create a classic drive rooms storage, which comes from a sub package and the one derived from sub template storage.<br>
And there's a few methods we have to override.<br>
So let's just go do that.<br>
Well, that's the template storage engine or something like that.<br>
And the way it works is gonna create a class.<br>
I copied this from the integration section, but let's just start here, and that's going to be imported from markdown sub template, and it's gonna go like that.<br>
We say Pass says, Look, this is an abstract based class, and we want to implement all the methods.<br>
So here's what we have to do in order for this to basically plug in to mark down sub templates.<br>
And there's two very similar methods here.<br>
This is initialized.<br>
Would it really need to know Is has the underlying database so db session as that thing as that thing been initialized and we go look at it, it has.<br>
This is initialized property, which is set you may.<br>
We should even you can maybe move that down the very, very end of this method here, right?<br>
But assuming that it's set up the connection and it's gotten all the way through those steps, it's initialized.<br>
So here we can just say return TV session do the session dot is initialized this one.<br>
It's not really anything to do here for this.<br>
We're just going to ignore that one.<br>
Just do a pass and this part gets pretty interesting.<br>
So here we have to go and write the code just to get one of those pages.<br>
And guess what?<br>
We already have the CMS service, right?<br>
And it knows how to get a page on.<br>
This template path is basically the standing for the euro, so we'll get her page and notice we don't return the page.<br>
We just return a string so we'll say, if not page in a return.<br>
None.<br>
Otherwise, we're in turn page Ott contents.<br>
Now it says it returning none.<br>
And this to be optional gonna go with.<br>
We're gonna change that optional of stir so it allows us to do that.<br>
Perfect.<br>
Perfect.<br>
Okay.<br>
And then this one, this one is going to be the same.<br>
For now, we're gonna add another feature to mark our pages as being shared or not shared.<br>
So this will allow us to do a query that slightly different.<br>
But for now, when you put this Okay, this is step one.<br>
Step two, If we go back to the documentation here is we need to go in, create one of these and then set the storage engine or the markdown storage.<br>
And that's going to happen over here in this section here.<br>
So let's add a in it mark down, But configure Guess not.<br>
Really?<br>
Sure.<br>
We're gonna need to use it, but that's fine.<br>
They wouldn't call this section here.<br>
We got a storage and say set storage, and we have to give it some store thing that we're gonna create.<br>
What is it?<br>
Well, that's going to be one of these sub template Devi storage things.<br>
Just like so and that's technically feels like it's all we got to do.<br>
All right, Well, we created this class and then we're just going to go here and set it.<br>
Think we're gonna run to a problem?<br>
Let's see.<br>
No, no, no, no.<br>
Is gay.<br>
It's working.<br>
Well, maybe this is gonna be great.<br>
Let's give it a shot.<br>
We come over here and with that it's working.<br>
However, it's not just taking the mark down and displaying it like it was before.<br>
In fact, it's doing in memory, cashing in a bunch of different work to make sure that this is as fast as possible.<br>
Let's go back and make this a super slow, a long thing like it took before we go over here to this engine.<br>
Yeah, I'm not really sure how we can how we can fake it to go in there.<br>
I actually maybe, yeah, yeah, Let's do this.<br>
I'll say Page equals that.<br>
And then page is not what you generally want to do, but equals pays that contents.<br>
20 return page.<br>
There we go.<br>
So now the page will be 20 times as long you go click on this notice right now.<br>
Yet this should be a little bit slow.<br>
Been spin, spin, spin.<br>
It was good.<br>
Really, really long here.<br>
But now watch.<br>
Go back.<br>
Instant!<br>
Instant!<br>
We got fast.<br>
It is you can you can even see the screen Refresh.<br>
Now I want to show you some numbers really quick about how it's better.<br>
But this thing this we haven't talked about this but this cool performance analyzing the bug, Tobar actually makes it hard to see the performance.<br>
So I'm gonna go and turn that off for a second.<br>
That's turned on right there.<br>
Let's run it one more time.<br>
No, over here.<br>
Inspect Element turned on the network.<br>
Say show only HTML and persist the logs across calls The first time I hit it, it's not gonna be cache and memory, so it's going to generate it just like we basically saw before.<br>
It's gonna take about half a second and there it is.<br>
872 milliseconds.<br>
That is some slow business.<br>
Compare that to 15 milliseconds for the home page.<br>
Quick, that is.<br>
But watch it now.<br>
Bam!<br>
Eight milliseconds.<br>
That's 100 times faster 67 more than 100 times faster to get this page, you can see all that content.<br>
Yeah, it's still totally there.<br>
All right.<br>
It's the same amount of work, but this markdown subsystem, one of its magical powers, is it knows how to cash these things and make him really quick and could even cash them to external systems like red ists or do the database or something like that.<br>
And you could look in the extension section, see how to do that same place where we're looking at for this database integration.<br>
Okay, so really nice, right?<br>
All we got to Dio is go over here, implement this one class, this class just more less delegates to our existing CMS service.<br>
Another win for using that, a p I or that pattern.<br>
And yeah, that's pretty much it over here.<br>
Instead of calling our own convert to mark down, we just let it do it itself.<br>
Say, give me the page and all the work you got to do to put that together, drop it in here and off it goes.<br>
And here you can see the actual marked down time that it took was 769 milliseconds.<br>
It 00 afterwards, right after it hits it the first time.<br>
It's super super fast, so this is a huge, huge improvement, and it's basically no extra work on our behalf.<br>
But it also has more features that we're gonna get to like that shared content and whatever that reusable pieces and so on.
|
|
|
show
|
2:58 |
Now let's see about using some of this.<br>
Shared a reasonable content basically extending marked down, as is understood by this marked on sub template thing.<br>
If we come over here and let's just say, problem page something to that effect and to maybe we want to be able to let somebody cover and on the bottom of all these pages were right and say, Do you see a problem with this page?<br>
Send us a message or something like that, Right.<br>
So let's go over here and we'll just write that shared content.<br>
So what we're gonna dio as we're gonna put a maybe, each four.<br>
It would be something like, See a problem.<br>
So here's some basic text, and then let's even make this.<br>
Ah, hyperlink.<br>
So we come over here and put this is a link and the link is going to be H p s twitter dot com slash the psf except looks good.<br>
Maybe there's a space there.<br>
All right, cool.<br>
Let's give it a quick preview.<br>
It looks good.<br>
They go to the right place.<br>
May the Python suffer foundation.<br>
Good, Good.<br>
All right.<br>
So it looks like this is fine.<br>
Let's go and just save it.<br>
Now, let's suppose this our team and company history and maybe even the donate, but they all want to have this little section down at the bottom.<br>
Are we gonna do that?<br>
Well, now that this is in our database, it's super easy.<br>
If we go edit this, donate one down here.<br>
All we have to do is say, import the name of the little short girl it could even have.<br>
Slash is like this if that's what the Ural is, and then you could have stuff more after this if you want not gonna put that there.<br>
But if it made sense to put this in the middle of the page, it totally what's Let me copy this and save it.<br>
Now let's see that that shows up.<br>
Hit, visit, Boom.<br>
Look at that.<br>
Now.<br>
We might want us to be smaller, maybe centred and gray or something like that.<br>
We couldn't address that in a second, but that's pretty cool, right?<br>
And let's go back to the admin and put it in one more place.<br>
Go put us in the bottom of the company here and in the bottom of our team.<br>
There Now, if we go look at all these.<br>
Look at these three pages.<br>
They all have the same bit right there.<br>
Isn't that cool?<br>
So allows us to create little fragments.<br>
Now, what I don't like we're going to fix later is this page looks no different than these top level pages that are basically making up our site.<br>
So what I want to do is have a different section that shows thes shared things.<br>
We need to have a way to indicate in the database.<br>
This is a shared, reasonable piece.<br>
You shouldn't treated the same.<br>
So we're going to do that.<br>
But for now, let's just go and sort of see and appreciate how cool this is.<br>
All we got to do is write these little import statements which normal markdown doesn't support.<br>
But our library
|
|
|
show
|
3:32 |
well, our pages looking pretty good.<br>
But there's one thing I want to talk about and that's formatting this content.<br>
Or, to be honest, any form of content.<br>
If I want to put an image there and have it spanned the whole page exactly, regardless of the size of the image, the sides of your screen or if I want to have, like, let's say, if we want this gray and smaller tax or something along those lines.<br>
So let's go make that happen because landing pages or other sort of marketing pages are not super interesting if you don't have a lot of control over.<br>
So we wanna adjust the CMS pages, sometimes beyond what Mark down really wants us to dio.<br>
So let's go to this problem section now.<br>
It might first seem like, Well, what we can do is we can put this into a A divorce, some HTML container, and then on here.<br>
We could set a style, and let's say the style is gonna be color is grey font size is 0.7 p.<br>
M.<br>
That is 70% of the normal size.<br>
Now go ahead.<br>
This and we view our donate or donate has a look.<br>
It's gray.<br>
That's awesome, like we wanted.<br>
But wait a minute.<br>
What the heck just happened here?<br>
If we expect this element, you'll see that.<br>
Well, basically, what happened down here is this section not that section.<br>
This section here it got the styles.<br>
You can see the styles and HTML are in here.<br>
But then it didn't process the mark down.<br>
Right?<br>
This basically didn't get parts by mark down.<br>
But you can see the stuff of here.<br>
Did the little header.<br>
You see a problem?<br>
Pieced it.<br>
Let's go back and look this again.<br>
Here's the deal with this library.<br>
You cannot mix HTML.<br>
Let me rephrase that.<br>
You cannot embed mark down within HTML although you can't include it.<br>
So, for example, this got processed is marked down, converted to an H four just fine.<br>
This got pastors HTML just fine.<br>
But the stuff in here didn't to.<br>
You actually can put these little slices of HTML in here like if you want have an image, you can just put the image with some styles and put it in there and that's great and the rest can be marked out.<br>
But here's the thing is the stuff inside has to be standard HTML.<br>
Right.<br>
So here we gotta put like an h ref equals slash a And then we put the pieces go in there, right?<br>
So here's the body.<br>
Next, here's the euro that goes there.<br>
Even throw in a cool target equals like that to get it to go to a new tab.<br>
Let's update this.<br>
Go back and view our donate.<br>
Now watch.<br>
This should get fixed and it does super.<br>
So here.<br>
This is the markdown part of that reuse bit.<br>
And here's a little HTML fragment we stuck in there.<br>
Yeah, it doesn't look super good.<br>
Like the way it is on the page, but that's not really the point, right?<br>
It's just that weaken style this and get it to behave the way that we'd like.<br>
So here we have a hyperlink that opens in a new tab, Super easy to dio so you can do way more with these CMS pages, regardless of whether their shared like we were working on a shared section habit.<br>
It's not the fact that it shared its just the way the mark down the underlying marked down to library works does it want pars marked on within HTML fragments, So that's fine.<br>
You can do this for any page or any parts of the page, and you can put these little HTML elements in here and then you're good to go.<br>
You have all this content.<br>
Most of it's written in markdown, but these little pieces you can write in HTML have a little more control over how that small part of the page looks.
|
|
|
show
|
3:59 |
Well, we have this working pretty well from a functionality perspective, but not from an admin back in nice editing experience over here.<br>
When we go to our pages, I would like to see here are your top level pages and here is a piece that can be reused.<br>
And I'd like to see his little name and stuff like that in order for us to do that.<br>
Though, remember, this is all just a bunch of page objects in the database to seek.<br>
Welcome me.<br>
We need some way to indicate on that page object whether or not it's shared so we could go give that a shot.<br>
Being come down here and we can say is shared.<br>
It's going to be a Boolean who has a default value false.<br>
That seems totally reasonable, right?<br>
And yes, this is how we put it in here.<br>
Let's run the code and see how well this works.<br>
By refresh this page are we don't get a great air message here because we turned off on the bug Tobar.<br>
But it doesn't matter.<br>
Let's just go down here.<br>
And what is it going to say that that ah, it's doing some sort of query.<br>
No such column is shared.<br>
Yikes, that's not good.<br>
What's happening?<br>
Well, the database has this stuff in it and the way sequel alchemy works, it will generate new table.<br>
So if I made a new class, it would go and create that right away.<br>
However, what it will not do is it will not update an existing table.<br>
It won't add columns to an existing table.<br>
Do it's not gonna make this change here.<br>
In order for us to do that, we have to apply migrations and the tool for sequel coming to do that is a limbic.<br>
We're gonna do a quick little bit of work with Olympic.<br>
To make this change, go across this common this out for a second.<br>
So it's in sync to start now.<br>
There's some older migrations that we don't need to apply here, and I don't think they're properly in the database.<br>
We haven't been using migrations so far because we haven't needed them.<br>
And because we weren't careful, these were kind of out of sync.<br>
So I'm just going toe, save us some trouble and delete those two files, OK, and the other thing we need to do is make sure limbic is installed.<br>
So I put that here and weaken.<br>
Just pip the requirement, Steph.<br>
And get that to install Olympic.<br>
All right, Good.<br>
Now let's ask which Olympic good?<br>
It's the one out of our virtual environment that's very good.<br>
We're gonna need important that library, which is also registered in this virtual environment, do that's important that we can do that.<br>
And if you're on Windows, you can ask where Olympic, by the way.<br>
So let's just see if we can get Olympic Teoh.<br>
Talk to the database, we say Olympic upgrade head.<br>
That means just latest and basically says nothing.<br>
That's a good sign.<br>
We could come over here and we can put this back in, make sure we save it.<br>
And we can say a limbic revision.<br>
Dash dash auto generate with the message and is shared two pages seem s pages.<br>
Some like that.<br>
Alright, let's try this super so what it's done is it's gone and created.<br>
This file year, which has no downgrade, is fine.<br>
But if we upgrade, it's gonna go to this version.<br>
What is good and you can see right here.<br>
It's adding, the column is shared and said it to be knowable by default.<br>
All right, let's go and look at the data base.<br>
But our pages no is shared, right?<br>
Right.<br>
So the final thing to do that generated the migration, but it didn't apply a migration.<br>
So this Olympic upgrade head says, Take all the migrations you haven't here and applying to the database.<br>
Okay, let's go over here and see what we got.<br>
Refresh.<br>
Oh, yeah, There's a Boolean column and we can go back with our page now having this and run it and see what we get.<br>
Our page.<br>
It was crashing Works Great now.<br>
And of course, all the pages do as well.<br>
So what we need to do next is we need to go and update this to use that is shared property here and let's set it over
|
|
|
show
|
7:19 |
Now that our database supports this concept of a shared page and a standalone page, let's make that possible or visible in our editor.<br>
So all we really need to do is and one more field here, a check box that says Is it shared or not?<br>
And then just push that back into the view model and then have the view model pass it over to the CMS service when it creates or updates the page.<br>
So here we are in that page we're looking at right there.<br>
And before this text area, we're gonna start by putting a label on a check box.<br>
So we'll say input.<br>
I be cools.<br>
Check box name equals is shared.<br>
That's good animal.<br>
Do a label and it's gonna be four is shared like that.<br>
I'll just say something like shared content, nonpublic.<br>
Something like that.<br>
I say we're going to start by doing this because there is one minor change we need to make was going look and see how this looks.<br>
Well, that's weird.<br>
Like, why is that way over there?<br>
And if we look at it, why is it so super huge?<br>
See how it takes up the whole thing, and then so does, this is not quite because apparently it's display styles in line block instead of in line instead of block.<br>
But this one is really huge, and that's little bit weird.<br>
The problem that we're gonna run into is if you look over at the CSS.<br>
It says something like All the stuff in here is 100% across within the admin block.<br>
If there's a text eerie or input, it's 100% across.<br>
Now let's be a little more careful here.<br>
Let's go here and say within the form that immediately contains this.<br>
So what that means is here's a form and the very next item is either an input or text Eri and then this one We can just put it into a container to say, You know what?<br>
These need to be on one line like so let's give that a run.<br>
Ah, yeah, there we go.<br>
So we've got these nice and wide, all 100% across, but this thing right here is not causing this trouble.<br>
All right, well, this is good, but it's not being set Now.<br>
It turns out setting this check box in the community in trouble.<br>
It's a little bit annoying, actually.<br>
Really, really.<br>
Love the chameleon templates is Petey Files.<br>
I think they're super super nice.<br>
They're so clean.<br>
And what I really like about them compared to Jinja or Jingo is what you put in here is still valid.<br>
HTML, for example, this one will see this one here.<br>
This conditionally shows or hides the error message depending on whether there is an air.<br>
Right.<br>
Well, this is still validation, Mellick.<br>
This doesn't make sense, but it still pars is as HTML as opposed to Jinja, which has, you know, the percent percent full.<br>
if error close it off, you got to put an end if at the end I really don't like that style.<br>
But this one part right here, it would be better if there's a better way to do this.<br>
And I think it's also a limitation of the check boxes because what I want to do is I want to set the value you gotta do.<br>
You have to say check and it doesn't matter what you said it Teoh if it if this thing is here than its checked, So there's not really a great way to say, make this attributes appear or disappear Community that I've figured out maybe all got it.<br>
But so what we're gonna do is where it's going to say that someone say we have a checked one on like this, and then we're gonna be tal Cold condition is shared and they were gonna have one that's not checked.<br>
And that one's only gonna be visible if it's not shared.<br>
So it's sort of annoying to have this duplication.<br>
Only one will ever appear at a time because here's the condition and the not condition.<br>
But nonetheless, we do have Teoh address that now if we try to run it right away, it's not gonna work Super.<br>
Well, the reason is, if we go and refresh this, it crash.<br>
And again we turned off our deductible are so gonna look down here for the air.<br>
But the air is we're missing.<br>
This is shared here, So let's go over and work our way back up.<br>
It appears that we go over here to this edge it at a page view model, and then we have self dot is shared, equals, start false.<br>
And then if there's a page, will say self that is shared equals.<br>
Ah, self top page is shared.<br>
Remember that we already put in the database.<br>
We just need to carry it along.<br>
And then, of course, we need to do the reverse over here.<br>
We need to say self that is shared, equals careful.<br>
Gets little weird.<br>
They get It's shared.<br>
Is that what we want?<br>
What values does it have?<br>
Is it true or false?<br>
Like it probably really should be?<br>
No.<br>
Is it checked or not checked like you set over here?<br>
Check versus Not checked?<br>
No, the way this gets submitted to the form is it gets submitted back as either on or off.<br>
So we're gonna say it's shared.<br>
If the value get back, is the string on?<br>
OK, so it's a little not obvious going to just play around to figure that out.<br>
But let's give this a try.<br>
We probably can actually go and check these things over.<br>
We refresh this, we can now edit it.<br>
Ah, let's see that one says it shared.<br>
Is that what we want?<br>
Let's go back here.<br>
I did this one.<br>
Okay.<br>
This one is not shared.<br>
Yeah, This one's also not shared.<br>
Okay, cool.<br>
And if we check it off, we can save it back.<br>
But it's not getting pushed over to the database.<br>
So that's the next thing to Dio is over in our admin controller Over here wouldn't more calling Update Page.<br>
We need to have V.<br>
M.<br>
Bhatt is shared, and similarly, one more creating the page.<br>
We want to specify if it's shared, so let's go on.<br>
Add those two things and this should be the final step.<br>
But here's the Create Page one and the update page as well.<br>
It's good and put these type hints on here.<br>
There we go.<br>
And I guess we could go ahead and return the page just in case somebody wants the page that got updated back.<br>
All right, I think that I'll do it.<br>
Let's try.<br>
If we got everything right, we should now be able to edit whether or not our pages were shared.<br>
Okay, let's go back to the admin section.<br>
Viewer pages.<br>
Let's mark this one as shared and hit.<br>
Save if we look at it again.<br>
Yes, it's shared.<br>
If we go back here and look at this one not shared.<br>
If we update it good.<br>
Look at it again.<br>
Yep.<br>
Still not shared.<br>
Okay, it looks like that's working.<br>
We didn't do the create one, but that one will work as well, I'm sure.<br>
Now the other final thing like you can't tell looking this page summer shared and some are not shared.<br>
So we want toe.<br>
Also, distinguish that.<br>
Remember, what are the primary important things about whether or not we were looking or these shared elements is we want to not pollute our structure.<br>
It says here the pages that make up your site.<br>
We don't one of these little reusable bits in there because they don't really make up our site.<br>
Exactly.<br>
We want this kind of partitioned into two lists.
|
|
|
|
18:55 |
|
|
show
|
1:46 |
Let's talk about logging our CMS actions.<br>
There's actually two levels that we're going to cover first.<br>
Your site.<br>
If you're adding this to an existing site, probably already has logging.<br>
If it doesn't, I'll show you some cool log in libraries and how we're using them.<br>
And then you can plug into those.<br>
So here's the log from Talk Python Training that I talked about one out of him.<br>
We get all sorts of information about what people are up to, who has done what we could go back and look, you know, somebody sends us a message and say, Hey, I did this and it didn't work the way expected are or something like that.<br>
We go look in the logs and see what it was.<br>
They did So here There's a little bit of a a little bit of history of people using the A P I using the mobile APs on it looks like IOS.<br>
A couple of people on Iowa's here requesting some information by the courses, you know, like refreshing their list of courses or logging into their app or something like that.<br>
Right?<br>
So we have this kind of stuff going on in our Web app, presumably right?<br>
Presumably.<br>
If not, you can add it.<br>
But we also want to add this for the CMS to know who's taking the admin actions.<br>
And then the second layer Here is the markdown subsystem, the markdown templates, sub templates.<br>
That thing has its own logging, and we can extensively plug it into our file logging or whatever type of logging system we're doing.<br>
We can plug those in together so they make sure they go to the same place.<br>
For example, on training Doc, talk by thunder out of him.<br>
We have rotating logs that show you.<br>
Here's the log for that day, and then the next day it automatically creates a new file and puts it in there.<br>
Right?<br>
So we want to take the functionality from markdown sub templates.<br>
M plug it into that system so it's all unified in one place, or maybe even just turn it off because we don't want to see
|
|
|
show
|
1:02 |
There's a lot of different logging vibrators for Python.<br>
Python has a built in one.<br>
I don't really love how it works.<br>
It's kind of I'm not a huge fan.<br>
Let's just say that we're gonna be using this project.<br>
This package called Logbook.<br>
This is written by the same guy who created Flask, actually, and it will push notifications and messages to all sorts of fun things.<br>
So it's a really nice, simple logging thing that a log to like standard out like print.<br>
But it will also logged the files.<br>
It can even logged like messages to phones for, like critical errors or other other crazy stuff like that if you want to plug it in.<br>
So I've gone through.<br>
And I've actually already added this to our Web app because the point is not to show you how to do logging for a Web app.<br>
I'm assuming you probably have that, and if not, this is really simple.<br>
You can just take it and follow along.<br>
What we want to talk about is just making sure we're doing the Logging one and then two.<br>
We want to make sure that we want to plug in that mark down subsystem, logging into it and control it as you want it to happen.
|
|
|
show
|
5:39 |
here we are in our Chapter 11 copy of our web app.<br>
And I won't just take you on a quick tour of what we got to work with here.<br>
So I've added this logging function.<br>
Here's that initialize is logbooks over the top we've installed and then imported logbook.<br>
And then down here, we're just gonna go and sell logbook.<br>
Teoh, push to standard out.<br>
That's like the same is just doing a print when you go to production.<br>
If you really run this on real servers, obviously that's not gonna help you a lot.<br>
So you're gonna want to set this up toe log to a file.<br>
Just check out the logbook documentation.<br>
It's super easy to have rotating file systems while handling there.<br>
We're going to set that up globally once.<br>
And then any time you want, we could create one of these things and give it a name like APP or CMS or admin or whatever.<br>
So what about these little different levels?<br>
Right?<br>
Weaken set the level of our logging right now it's on log.<br>
Everything.<br>
But we could say Onley log like warnings and above.<br>
And then this notice would not actually appear.<br>
Okay, So that's one of the features.<br>
That's pretty cool.<br>
It wouldn't go down here when initialized just say, Hey, we initialize the logging and then for mark down, we're going to say what storage engine we put in here down to the bottom.<br>
We're gonna say how many Web routes we've registered and then what?<br>
Whether or not we're initialized in the database.<br>
This one we've also remember we had a print statement right here, and we've changed that to now log, this will right now go to print basically the same.<br>
But what's really nice is it will go to the file system when we if we ever switch it to that.<br>
So for over here we're just creating a DB session logger.<br>
We also have in the admin section, appear a seem with this should be called ad Mention it Rio.<br>
So we have an admin section down here and you'll see at the bottom when we're, say, working with a redirect.<br>
It'll say the user so and so is adding or updating a redirect.<br>
And then after it succeeds, it says they've added or updated.<br>
We're not really distinguishing right.<br>
Member of this function is used for both.<br>
And this is just trace.<br>
Like maybe maybe it should be higher notice.<br>
What do you think this is?<br>
People making changes through the site Traces?<br>
Probably a little low.<br>
Got the other one.<br>
Appears this trace as well.<br>
That's good, but that I also did some places where Trace makes more sense.<br>
Let's look over at our CMS controller.<br>
And over this one, we probably want to do the same thing.<br>
So we could say log equals log book.<br>
And we have to import that logger, and this one could be CMS.<br>
And then down here, we could just have a message for, say, log dot This one you definitely wanna be traced.<br>
Like every page we're going to tell you.<br>
This page was requested.<br>
Well, only in, like, super tell me everything mode and we want to see that That we could say, Ah CMS request Get the title or something like that.<br>
Greek for redirect for the short your l And then we could also get in here.<br>
Maybe make this a little bit higher.<br>
CMS request not found.<br>
Put the oil there.<br>
Okay, let's give this a shot.<br>
See how it's working.<br>
And I noticed what it runs Now we've got the date, the time, the level of the message.<br>
Loggins initialized.<br>
This order trades for the DB session, initializing right initial light that it's going to initialize and we'll see this even if you re initialize it.<br>
So that's why this trace but notice.<br>
Here's where we're actually connecting to once and only once.<br>
Here's the app starting up over here and then go to our admin section and now admin trace user impunity viewing.<br>
Advent home.<br>
They're viewing the page list.<br>
I go over here and edit it.<br>
Let's say make no real changes now these air notices the user impunity was updating the page.<br>
It was our team at this address, and then we're back looking a list That's pretty cool.<br>
And then finally, if we hit a page here like this, there's a couple of things that are cool.<br>
One.<br>
We're doing a Seamus Requests or this title this page.<br>
Maybe the euro should be involved, possibly.<br>
But notice here.<br>
This is from the markdown sub templates, and it's even though it has the square brackets, so it kind of looks the same.<br>
It's not the same right.<br>
It's not coming through this system And how can I show you that lets I've made it a little more obvious If we go down here to this logging thing, we don't set up this standard out longer notice.<br>
All those messages are gone.<br>
They're just going basically to nowhere right, logbooks like I've got a message nowhere to put it.<br>
So throw it away.<br>
Right.<br>
And if we go look at this page, notice these air still getting generated right to the ideas.<br>
Like if we set in that to a file, these would not go.<br>
That file is to just go to standard out.<br>
So So that's not ideal.<br>
What we want to dio also to forward it sort of round this out if we want to take the logging coming out of our markdown subsystem said it to a certain level.<br>
So we control that and then also put Push that out, too.<br>
Are logbook integration.<br>
But for starters, it's cool to just see that we've got super super simple logging integrated into our system.<br>
We just change it right here to go to a different place.<br>
Like to get it to go to ah rotating file or something like that.<br>
Pretty easy, huh?<br>
I love log
|
|
|
show
|
2:59 |
the first thing we might want to do with our markdown sub template library is Just tell it.<br>
Don't show me all these messages.<br>
I want you to just show me the really important stuff.<br>
So in order to do that, we don't have to do any integration or anything like that.<br>
We can come over here and import from markdown sub template just like we did storage, logging, and in this innit logging section, we can go down and we could say in de log, I'll get log.<br>
So then, MD log, we can just like before call these messages were not going to use this directly.<br>
As you'll see.<br>
We're gonna do a little integration with it, but we can set this now.<br>
This is a log level that's going to come out of not Harbour.<br>
But here we can set it to race error and phone aims.<br>
Let's just say let's just say we want to set it to error and let's put it underscores who were not little warnings about this.<br>
So now if we run this and we go look over to the admit lips with a click here, notice there's no message from it But maybe if we can get it to have some kind of error, let's go over here and just say this one has an import like that.<br>
And if we try to view that, let's see.<br>
Do we get any message?<br>
No.<br>
Still, it probably should give us a warning like a We couldn't find this thing right here, but anyway, if something goes too wrong with it, it'll got an exception or something.<br>
You should see some kind of message out here so you can configure the levels off that thing or just turn it off.<br>
You do what you want to see.<br>
Anything to say, logging off.<br>
You'll never see a message from it again.<br>
But there is probably good anyway, this is a nice way to control that.<br>
At least a first pass to filter out some of the messages.<br>
You don't want to come in.<br>
And while we're at it, if we want to just see notices and above, we can come down here and say Level notice And now let's go CR ap run notice.<br>
We see the notices, but we don't see higher.<br>
Let's see what we want.<br>
Yeah, we don't see the info stuff.<br>
So remember if this Waas info here before we said I'm not sure info is the right level, you see, Trace, right?<br>
I guess if we That's right, we had it.<br>
We didn't have anything that was said toe that level.<br>
So if we said this to trace, we should see trace and above, which is noticed and trace Perfect.<br>
We see that, but we don't want to see traces.<br>
Remember, You see a lot of stuff in this one.<br>
If you're over here and you're viewing a page and you look down here, there's a bunch of traces like you don't want to see that in production is even gonna slow things down.<br>
So you could go to notice or info.<br>
And now we can request the heck out of this page, and those are gonna be so set.<br>
So probably the right thing to do is like, set these two levels like this, but they don't have to be the same.<br>
They just can't be there.<br>
Notice this Didn't have a notice, does it?<br>
go with air info.<br>
Info is gonna be as close as we can get, I guess.<br>
Didn't notice.<br>
Here we go.<br>
Looks like it's all
|
|
|
show
|
5:38 |
Now, if you really care about this mark down sub template logging stuff and you're using some logging system, the only reasonable thing to do probably is to put them together.<br>
So let's just really quickly do that.<br>
And as we saw over here in our storage engine, what we did is created a class that drive from something in storage.<br>
Well, it's gonna be really similar over here or Logan, and there's a bunch of stuff we're not gonna need.<br>
So let's clean this up here.<br>
This is gonna be logging.<br>
I would have to import that.<br>
I did want to give us to help their so from markdowns, sub templates, import logging, I'll say logging sub template longer.<br>
It Let's get rid of all of this stuff here and for a moment, all right past.<br>
But what I really want to do is implement these four methods that we have to dio in order for us to rightto logbook just like we were over in all the other places.<br>
Like over here to do that.<br>
What we did is we created one of these little logs.<br>
I'm gonna do that up here as well, and this is gonna be mark down something like that.<br>
And you know what?<br>
This is super super easy.<br>
So we go look at this thing it's going to have when you create it, you're gonna have to pass over the log level and it's gonna store it.<br>
But we don't have to really do any defining different than that.<br>
So we're just gonna hang on to it like this, and then we'll just say really quickly.<br>
Now, the way it works is you need to check somehow whether or not you're at this right level.<br>
So it has a built in should log, and we're gonna give it Ah, a couple of things.<br>
We're gonna give it the level in the log level that were asking.<br>
Actually, it was a log level, however both so it knows what level it's at.<br>
And we're saying we're gonna consider to do a verbose logging.<br>
Should we do that?<br>
Given the level of your at the other thing, we want to pass along as text and you might wonder, like, what does the text have to do with it off the Texas empty?<br>
We're not gonna write a log message for that.<br>
It will say if not this return.<br>
That's gonna happen at each one of these.<br>
I don't really know of a better way to do that, Okay?<br>
And then we're just gonna really simply come down here and say log dot What's close to verbose?<br>
Swell trace When I go and put out the text, You the markdown longer here.<br>
Like that.<br>
What about this one?<br>
Also trace.<br>
What about this one?<br>
This is info.<br>
Logbook hasn't info level, and it has an air level.<br>
Okay.<br>
And that's it.<br>
We've now integrated are marked on September system with our logbook integration just like before.<br>
The only other thing we have to do is Member This part in the database where we initialize mark down.<br>
We came for the storage.<br>
We're gonna say log already ever logging here.<br>
It looks like we do.<br>
Yeah, right there were already in it.<br>
Already.<br>
Got that because we were playing with it before.<br>
Well, say logging, not get log.<br>
Sorry.<br>
Set log.<br>
And what do we want to set it to?<br>
That's it.<br>
Log engine.<br>
Oh, I didn't rename that leads.<br>
Ah, call it longer some like that.<br>
And we've got to import that and we need to pass in the level log level dot What level do we want to do it?<br>
Let's say we're going to do invoke.<br>
I always had the log engine and that's it.<br>
We could also mark down logging engines set to engine.<br>
Perfect.<br>
Well, let's give it a shot.<br>
See if this works.<br>
Okay?<br>
It's looking good.<br>
We have our notice.<br>
Notice notice here.<br>
Actually, when we got to go and set that back here, let's go to Trace just for a moment, just to make sure we see the messages.<br>
Okay, so let's see, We've set our markdown logging engine to sub template.<br>
Logger, if we make a request, notice a couple of things here.<br>
We didn't have to generate that page because, yes, it was already created.<br>
See?<br>
Oh, I made a mistake over here.<br>
You'll probably notice that you're like my go.<br>
What are you doing?<br>
This?<br>
We have to adjust.<br>
This level and that level have to match.<br>
So we say trace.<br>
I say info and air.<br>
OK, now, now we should see some subways request.<br>
That's again.<br>
Perfect.<br>
Check this out.<br>
So we've got an info level message from the markdown system that it generated this HTML.<br>
And then our controller also has this message here and noticed that it this part and this part these are all going through the logbook output.<br>
So this way, if we set up file logging or routine violence, whatever the messages coming out of the markdown sub template will also show up over there.<br>
So we visit any of these you should see.<br>
Now we're generating the markdown for this.<br>
If we visited again, or refresh it again, we won't see the markdown out, but because we're using, cashing or not regenerated it.<br>
But we are really requesting it over here.<br>
Perfect, right.<br>
Okay, well, it depends on what you're doing, whether or not this step is necessary or helpful to you.<br>
But if you're using a custom logging framework like logbook, which I recommend, look, it's super easy to add it here and just fold all these things together and just get a little more information about how your APs running.<br>
And that's got to be good to help you keep it running correctly and be able to diagnose stuff that goes wrong.
|
|
|
show
|
0:52 |
remember, if you want to control of the messages that come out of the logger just to the standard out just by via print is super easy to Dio.<br>
We can just go down to the markdown subsystem and get the logging and say, Give me the current longer, which is the standard out, print style logger.<br>
You have to do anything that said that of its there by default, and then you can set its level brought with do one of these log level enumeration type things.<br>
So would you say log dot log level equals this and that will only allow error and higher messages to come out?<br>
Remember, if you want to turn it all the way off, said it, the log level off.<br>
If you want to see everything, it's willing to show you say, log level dot race or verbose of her boast, I think, is the lowest eso that'll do it.<br>
You just turn it on and see what it's willing to tell you.<br>
And if you're not gonna integrate with other logging, you just want to sort of get it to chill out or give you more messages.<br>
Here's what you can
|
|
|
show
|
0:59 |
if you do have a proper logging system in your Web app, and I recommend that you do, because it's really important to know what's going on with your certain on your with your APP on your server, you probably should go ahead and take the time to integrate markdown subsystems, logging bits with what you're already doing.<br>
So with this one class, this is basically it.<br>
You just go through and say, I want to override a couple of methods one right over I trace for bows and bow and so on, And then you just check.<br>
Should I log at this given level yes or no?<br>
And then if you should just go ahead and log that message to your logging framework of choice.<br>
Here we've created a logbook lager and in the trace one we say logbook, logbook blogger dot trace in the info one.<br>
We say it logbook longer dot info, and that means it just passes those messages on to our underlying pre configured logging system.<br>
Whether that's going toe files, whether that's going to standard out or whether it's going nowhere, this will go ahead and take care of that for you.
|
|
|
|
19:47 |
|
|
show
|
1:35 |
we've come to the end of the course and you've made it to the finish line.<br>
You now have merged the abilities and the powers of these data driven Web applications with that of a CMS.<br>
You no longer need something like WordPress or Jumla or some other tooling.<br>
There's a separate thing to allow you to create this great content and then have this other app type of thing where your logic lives and people can log in and do stuff.<br>
No, these convey the same thing as you've seen.<br>
So let's take this last final section in review What you learned.<br>
We started out with Pipi.<br>
I not exactly pipi I but our clone of it, and it looked pretty similar and it had much of the core functionality and everything else we need to add to really make it.<br>
Pipi.<br>
I well, wouldn't have added a whole lot, right, so we started out with what was basically a rich, working, data driven Web application.<br>
That means there's a database with a bunch of entries, and the pages are structured very much around showing elements of those database entries like you can see the bottom.<br>
We have new releases, and it's showing the title and the sub subtitle where you call that little description summary of each one in this long, less down there.<br>
Right?<br>
So we took this idea, which is very common, and we added on this CMS functionality.<br>
Now we can go to the admin section in the top right log in, create new page and just start writing.<br>
We no longer have to write code.<br>
We can just use that aspect of our website toe add things where there's not too much functionality required.
|
|
|
show
|
3:34 |
we started out our exploration of adding the CMS functionality by talking about routing.<br>
And the reason was it's essential that we find a way to get access to every single request that didn't correctly get processed in our sight.<br>
If we slapped, asked for looking like slash packages slash seek welcome me.<br>
Well, the data driven side of that would go and grab it and process it.<br>
But what if they ask for some other things like slash help?<br>
If that wasn't already there, normally would just the Web framework pyramid would return a 44 and say, Too bad that didn't work.<br>
What we want to do is look at that and say, Hold on.<br>
Is there actually something in the database?<br>
Virtually we conceptually think of as a page, even though it's not technically in the site that we wanna return back to them.<br>
So that was routing.<br>
Let's just review writing really quick in general.<br>
So we're gonna process that http get requests.<br>
This is like clicking on a link to a euro or something.<br>
And this one is to slash project slash sequel Commie on the right.<br>
We've got four view methods broken into two different vials.<br>
We've got some euros or routes associate with them.<br>
So we said Slash home, that's going to go to our just slash.<br>
That's gonna goto home dot indexes going to call that function and do whatever that does.<br>
So the system asked us slash Project slash sequel could be matched that the answer is no slash about.<br>
That's another registered one.<br>
Also not a match slash project.<br>
Early bracket flash package.<br>
So the curly braces mean here's a very well, it could be anything and yes, in fact, that does match.<br>
So your meds going to set up this match dicked?<br>
It's going to say it's got different things that matched in the Ural in particular, where we have the variable package, its value is now seek.<br>
Welcome me and then it's going to call the details function.<br>
Passing this requested we can process it and tell them about this page that they requested.<br>
Now setting up one of these special CMS routes, as I described, is a little bit different in our previous example where he had curly bracket package, it couldn't be slash sequel alchemy slash help or slash anything.<br>
The flash can't appear there right It's not a general thing.<br>
It's like, Well, there's slash project slash a single value What we need with our CMS world to say, give us everything.<br>
And the trick to do that in Pyramid is to put this star that star sub path.<br>
The star says match everything after this, not just a single value between the slashes.<br>
And once we set this up, we can define a page method that's going to capture every request and then try to render a page here.<br>
So we're going to say, first, get the request stop Mastic, and we're gonna get this sub path here.<br>
The thing is that some path actually comes back as a list of things.<br>
Strings separated by those Ford slash it.<br>
So if it was slash project slash sick welcome me, it would be a list of two things.<br>
One being project next string being sequel.<br>
Capi.<br>
Did it work with that in our database?<br>
We're gonna turn that back into something separated by slashes, and then we use our little seem a service to go talk to the database and get the page back, and then we just return that back to the page.<br>
You were not really checking that case.<br>
The patient might not exist, but this gives you the general idea of how it works.<br>
Remember this route.<br>
Appear this config dot Add route.<br>
It matches everything.<br>
The system will stop looking for other matches.<br>
Sooners that find something that is a match.<br>
So it's very important that this line this config dot add routes.<br>
He mess that this goes at the very end of all the routing set up.<br>
Because if you put it somewhere before then gonna be in trouble, that's not gonna work with anything below that, right?<br>
So do keep that in mind.
|
|
|
show
|
1:01 |
one of the first meaningful features we added to our pipi i app plus CMS was this ability to come up with little girls that were redirects.<br>
Think of the bit dot li service or some mural shorten her service out there.<br>
We'd rather have the ability to say a very short name that then could redirect some other site somewhere else in our website.<br>
That's much more, much longer, much more complex and so on.<br>
So we added this ability to get a redirect as part of our seem s requests and notice we could get the page, but imagine that that part doesn't match a page.<br>
So we're gonna come in and say, Let's go and see if there's a redirect at this euro and we get the response and get the euro from there, we make sure we a pen, the query string if it exists, and then we just return.<br>
And http found to that location because this one CMS method Seamus request method captures every single request that's not already built into the website.<br>
It's the perfect place to plug in both these redirects and page responses.
|
|
|
show
|
1:37 |
in our Web app, and especially in the admin section where we're editing redirects and editing pages.<br>
We use this view model pattern now.<br>
This came to us from the website.<br>
It was already using this pattern, but we kept working with it, and I highly recommend you adopt this.<br>
So that idea is we have a request.<br>
Come in here, I said.<br>
It's a post to register.<br>
That means they're submitting the register form.<br>
And it's really in these forms scenarios where view model their most powerful but not the only place use him what a lot of people do A lot of coded bought examples tutorials on the Internet and other sites I've seen is they just have these huge, massive, you methods where there's all the code that's going to process this request.<br>
That is not the way we want to write our programs.<br>
It's gonna be hard to maintain.<br>
Gonna be hard to know where to look, to find what we're working on, right?<br>
If you have bugs Mike, it go duplication, and none of those things are fun.<br>
So what we decided to do instead is use this view model pattern, which takes a lot of what makes the view method, big data exchange, data conversion and data validation.<br>
We move that to its own thing, its own class called a view model.<br>
So instead we have, ah, small little method.<br>
And it works with this other class, this other bit of code called the View model to get some data into it, validate it and then get the converted data back.<br>
That means it's much easier to do unit tasked against these view models.<br>
It's much cleaner.<br>
It's obvious what the entirety of the data being exchanged with the page, all of those things.<br>
So you model pattern definitely recommended for your Web APS, and we made good use of it here.
|
|
|
show
|
2:18 |
At first, you might wonder what is really the difference between a data driven page and a CMS page.<br>
After all, we're kind of storing them both in the database, right?<br>
The CMS data is in the database and other things like packages and releases and users.<br>
Those were also in the database.<br>
When you talk about this, don't have a clear idea of what it is you're talking about, a comparing and the advantages of them.<br>
Most Web APS when you go learn about them, are what I'm calling data driven Web maps like this one here on the left.<br>
This is viewing the eight of us seal I package and every single page that you look at.<br>
That is one of these the AWS Eli sequel, Commie Pyramid.<br>
We'll ask whatever it is that you're pulling up, it's gonna have exactly this look.<br>
But the little places where data goes, we're going to vary.<br>
And that's the data driven stuff in the database.<br>
We have ah, project name.<br>
We have a version we have releases.<br>
We have a description and links and all those things.<br>
On the other hand, maybe we've got help.<br>
Page the help page doesn't have nearly that much structure.<br>
It's not like, Well, this help page has all these things and that HelpAge as all that No, it just use the title.<br>
And here's some text that tells you what you might need to do to be helped with working my pi p I.<br>
So the difference is we look in the left here we've got.<br>
Here's the title.<br>
The name of the project.<br>
The version years, details about installing it, whether or not so the latest version of when that one was released.<br>
Little summary for it.<br>
Things that are links about it, like the project description, the files, the home page and the description right there.<br>
We just got the text.<br>
Remember, this is just mark down that we've rendered here, but it's not pure text.<br>
There's still some logic.<br>
There's still some stuff going on.<br>
We still wanna have our overall Web application know about it because we might want to have an account section here.<br>
Or maybe there's some part of this page that we wanna have still interact with our site and not just be some static file on the Internet to the advantage of bringing these two together as we still get the stuff in the upper right here on that help page, we can still interact with our site.<br>
Nike still have logic, terming who has access to things and so on.<br>
And yet we don't have to go write code and redeploy our website every time we wanna have a help page or a donate page or anything like that.<br>
This is data driven pages on the left, Seamus pages on the right.
|
|
|
show
|
1:33 |
for all the cool functionality and effort and polish we put into this application, rendering the page is not where that appears or where we had to use that skill.<br>
So once we've gone to that CMS request and we've determined there is a page, we're going to use this chameleon template to render it and all.<br>
We have to dio it's set the title on.<br>
We passed through the View model, a page object which has the titles we say Dollar curly bracket page, not title, And then we want to put the HTML in the middle.<br>
I remember the trick is that we just say dollar early bracket HTML it encodes it.<br>
So it's like viewing the source of the HTML, not the actual display that we're hoping for.<br>
So in Pyramid and in chameleon, the way we do this is we say structure, colon, some string, and it says we're not gonna protect you from this.<br>
We're gonna drop it in exactly as it is.<br>
It's part of the page, its structure of the page.<br>
So this is what we had to do these two things, I think in a real example we also actually set the title as well.<br>
On the top of the tab, Do beware.<br>
This structure thing means you cannot take user input and then return it or render it this way, just asking for them.<br>
Toe hack.<br>
You are more likely hack your users to put some kind of JavaScript or scripting vulnerability into that conduct and then try to get you to show it to the other users of the site.<br>
So this is for you and your trusted people on the back end.<br>
Edit the CMS and render the data.<br>
Be careful if you try to use the same technique for users who might enter the value of HTML there.
|
|
|
show
|
0:56 |
we decided to use sequel alchemy to store our data in the database.<br>
And I definitely love sequel alchemy.<br>
If I'm working with relational databases, that's what I would use.<br>
The way seek welcoming works is it has this unit of work create the thing you make a bunch of database changes and then you all at once in a transaction, save those changes back.<br>
So that looks like this in code.<br>
We create this session saying, db session not create.<br>
We create a page object set values like the title bureau on the contents and here were normalizing or economical izing them like, for example, Ural, that stripped out lower.<br>
So just in case somebody has a little space on the end, it won't be some weird thing that looks like it should match in the database, but doesn't.<br>
Do you want to set this all up?<br>
Then go the session.<br>
I want to add the object that we created.<br>
Then we just say session not commit boom, because sequel alchemy is awesome.<br>
This is now saved and inserted into the
|
|
|
show
|
1:34 |
we started out thinking, Well, we have a CMS for a website.<br>
So what we want to do is type HTML into it and then have it show it back to the users and that was all well and good.<br>
But we saw each team.<br>
L is a little brittle and harden mostly annoying to work with.<br>
So here's the page that we hope we're going to create in our CMS After we typed it in.<br>
This is the page we actually agree with our CMS.<br>
What's the problem?<br>
Well, there's this subtle when you don't highlight it.<br>
Subtle unclos h to remember what we were typing into.<br>
It's not like an editor that would find the problems with HTML.<br>
No, it's just a text area in a Web page.<br>
This was hard to find, and that causes big problems that follow on for everything that comes after it in the site, Not just what we right, but even the content that was part of the outer shell of our general look and feel.<br>
So what we decided to do was go with mark down and we use the simple mde markdown editor and all you gotta do is take a text area include a little CSS and JavaScript and point this thing at it.<br>
It becomes in awesome little editor.<br>
Remember, we're gonna go and add the CSS at the top.<br>
We're going to add the JavaScript at the bottom in this additional Js thing.<br>
And we have a script section.<br>
We just create this simple MD And we say the element element is document dog get element bidi.<br>
Our text area had the i d contents.<br>
So we just say contents.<br>
That's it.<br>
One other thing I would do is I would say spellchecker false.<br>
Turn that off.<br>
The spell checker is not great.<br>
Yeah, I just like to turn it off cause you already got a spellchecker in here.<br>
What browser, anyway?<br>
Just use that.
|
|
|
show
|
2:33 |
are moved to markdown had some benefits, but it also has some drawbacks.<br>
One It dramatically slowed down the website we saw for a large page, maybe 20 Web browser pages worth of content.<br>
It took 6 700 milliseconds to render that that is way, way too long.<br>
And on a busy site, it's going really slow.<br>
And on a site, even if it's not super busy is not ideal.<br>
You want it much, much quicker or like 10 milliseconds, not six 100 2 800 milliseconds.<br>
We also saw that we can't in general take some part of mark down and imported and reuse it across different parts of our site.<br>
Also could do that with HTML, right?<br>
Just it's just not built into it.<br>
So that was another one.<br>
we wanted basically better performance reusability.<br>
We could leverage this libraries idea to get variable replacements, but we didn't use it, So not really a big benefit to us here.<br>
The idea, though, was to use this markdown sub temple climber.<br>
It automatically does the cashing to make things extremely fast.<br>
It does the mark down conversion.<br>
It allows you to create content and then share it and reuse it through other parts of your site.<br>
All the things we're hoping for right here.<br>
And this open source project is super easy for us to use when we integrated into our site, Really all we had to do with two things.<br>
One for the HTML.<br>
We just say markdown sub template dot engine, not get Paige and give it the URL at all we gotta do there.<br>
The other one is we have to configure this thing to work with the database and with logging and things like that.<br>
So, for example, we had to create a little class that drive from sub template storage, had to implement, get markdown text and get shared markdown and a couple of other very simple things.<br>
It might sound like a lot of work, but we already wrote all that logic with our CMS service, So we just need to kind of put it together, give it over to the markdown September library so it can say they have this URL what content belongs with it.<br>
Use this class here to go ask our database.<br>
What page content?<br>
If there is any, do we have for that euro and it gives it back right here.<br>
Then we have to make sure that we set this up in the web site in the library.<br>
It doesn't just magically know about it cause we created this class.<br>
So we have to go in our app, start up in the dunder netapp I with Diogo and say, create one of these markdown sub template stores and then just go from the markdown Septima library.<br>
Say storage thought, set storage.<br>
Give it this.<br>
That's it.<br>
Everything you see on the screen here is pretty much all we had to do to integrate it.
|
|
|
show
|
1:54 |
your Web app probably already has some kind of logging and if it doesn't, you should add it.<br>
The logging that we reason in our pipi I app and that we kept using in our CMS is logbook and low book is really, really nice.<br>
It's super easy use it does the rotating bile output with the date lost the file name and creates a new one every day.<br>
All the kind of stuff you would hope that it would easily dio.<br>
So we started out working with this and we brought us in to add additional logging to our CMS admin side so we could see what was happening there and it was really easy.<br>
But we also saw that the markdown sub temple library has logging and log reporting and diagnostic information coming out of it.<br>
So we also want to take the final step to go in.<br>
Integrate are logging system in this case, the logbook with markdown sub template.<br>
So it's all together in one place, and that was incredibly easy.<br>
We just wanted to change the level right just going toe, print it out somewhere.<br>
We want to do that.<br>
We just go to logging from the library.<br>
We can say long enough.<br>
Get log and then log, not log.<br>
Level equals.<br>
We have this new Marais shin log level, so we say error, trace and bo warnings and so on.<br>
This will just let you control how much comes out of it, but not where it goes.<br>
If you want to control where it goes, just like the database we create this class that drive from sub template logger in this case and implement a few methods trace, invoke and so on and was gonna integrate with logbook.<br>
We're gonna create a logbook here and whatever the system asked us to do a trace, long as we check that we should do that.<br>
Trace right.<br>
Gonna check the level there, see what level it's that were to come in and just do the logbook, Walker, trace or log book blogger dot info and just pass it through.<br>
So this allows us to adapt whatever logging system we're using and capture the output from markdown sub template and wrap it in
|
|
|
show
|
1:12 |
That's when our close things out by saying thank you.<br>
Thank you.<br>
Thank you.<br>
Thank you for taking this course with me.<br>
Thank you.<br>
Supporting all the work that I'm doing around creating educational material.<br>
And by taking this class, you're absolutely doing that.<br>
So follow me on Twitter, where I'm at M.<br>
Kennedy.<br>
Listen to the talk by thunder Me podcast if you don't already.<br>
And I hope that you can take this concept of adding a CMS to a data driven Web app and bring those two together to create the best of both worlds and whatever you're building, we definitely have done that or us over talked by phone training.<br>
So a training dot talk by fund out of em when you go visit the public details about a course page or are pricing policy or environmental policy all many many of the non data driven parts of that website are powered not by something similar, but almost exactly the same thing that you see going on over here in this course.<br>
And it has been working beautifully, and I can definitely recommend it, put it into your application because it adds that capability that many people need to go and edit the website without changing the code without being a developer, and I think you'll find it super, super useful.<br>
Thanks for taking the course.<br>
See a line by.
|
|
|
|
49:47 |
|
|
show
|
4:07 |
One of the absolute pillars of web applications are their data access and database systems.<br>
So we're going to talk about something called SQLAlchemy and in many many relational based web applications this is your programming layer to talk to your database.<br>
SQLAlchemy allows you to simply change the connection string and it will adapt itself into entirely different databases.<br>
When you use a local file in SQLite for development maybe MySQL for testing and Postgres for production.<br>
Not really sure why you would mix those last two but if you wanted to you could with SQLAlchemy and not change your code at all.<br>
Just simply change the connection string.<br>
So SQLAlchemy is one of the most well known most popular and most powerful data access layers in Python.<br>
SQLAlchemy of course is open source.<br>
You'll find it over at sqlalchemy.org.<br>
It was created by Mike Bayer.<br>
And his site is really good.<br>
It has tutorials and walk throughs for the various ways in which you can work with SQLAlchemy.<br>
One for the Object Relational Mapper one for more direct data access, things like that.<br>
So why might you want to use SQLAlchemy?<br>
Well, there's a bunch of reasons.<br>
First of all it does provide an ORM or object relational mapper but it's not required.<br>
Sometimes you want a program and classes and model your data that way but other times you want to just do more set based operations in direct SQL.<br>
So SQLAlchemy lets you work in a lower level programming data language that is not truly raw SQL.<br>
So it can still adapt to the various different types of databases.<br>
It's mature and it's very fast.<br>
It's been around for over 10 years.<br>
Some of the really hot spots are written in C.<br>
So it's not some brand new thing.<br>
It's been truly tested and is highly tuned.<br>
It's DBA approved.<br>
Who wouldn't want that?<br>
What they mean is by default SQLAlchemy will generate SQL statements based on the way you interact with the classes.<br>
But you can actually swap out those with hand optimized statements.<br>
And so if the DBA says, whoa there's no way we're going to run this all the time you can actually change how some of the SQL is generated and run.<br>
While the ORM is not required I'd recommend it for about 80%, 90% of the cases.<br>
It makes programming much simpler, more straightforward and it much better matches the way you think about data in your Python application rather than how it's normalized in the database.<br>
So it has a really really nice ORM with lots of features and this is what we're going to be focusing on in this course.<br>
It also uses the unit of work design pattern.<br>
So that concept is I create a unit of work I make, insert updates, deletes, etc.<br>
All of those within a transaction, basically.<br>
And then at the end I can either commit or not commit all of those changes at once.<br>
This is in opposition to the other style which is called active record where you work with every individual piece of data separately and it doesn't commit all at once.<br>
There's a lot of different databases supported.<br>
So SQLite, Postgres, MySQL, Microsoft SQL Server, etc.<br>
There's lots of different database support.<br>
And finally, one of the problems that we can hit with ORMs is through relationships.<br>
Maybe I have a package and the package has releases.<br>
So I do one query to get a list of packages and I also want to know about the releases.<br>
So every one of those package when I touch their releases relationship it will actually go back to the database and do another query.<br>
So if I get 20 packages back I might do 21 overall database operations separately.<br>
That's super bad for performance.<br>
So you can do eager loading and have SQLAlchemy do just one single operation in the database that is effectively a join or something like that that brings all that data back.<br>
So if you know that you're going to work with the relationships ahead of time, you can tell SQLAlchemy I'm going to be going back to get these.<br>
So also load that relationship.<br>
And these are just some of the reasons you want to use SQLAlchemy.
|
|
|
show
|
1:35 |
When you choose a framework whether that's for a database or web framework it's good to know that you're in good company that other companies and products have already tested this and looked around and decided yeah, SQLAlchemy is a great choice.<br>
So let's look at some of the popular deployments.<br>
Dropbox is a user of SQLAlchemy and Dropbox is one of the most significant Python shops out there.<br>
Guido van Rossum and some of the other core developers work there and almost everything they do is in Python so the fact that they use SQLAlchemy that's a very high vote of confidence.<br>
Uber, Uber uses SQLAlchemy.<br>
Reddit, Reddit's interesting in that they don't use the ORM, but in fact they use only the core at least a while ago they were using only the core aspect of SQLAlchemy, that's pretty cool.<br>
Firefox, Mozilla, more properly, is using SQLAlchemy.<br>
OpenStack makes heavy use of SQLAlchemy.<br>
FreshBooks, the accounting software based on, you guessed it, SQLAlchemy.<br>
We've got Hulu, Yelp, TriMet that's the Public Transit Authority for all of Portland, Oregon the trains, the buses and things like that so they use that as well.<br>
So here are just a couple of the companies and products that use SQLAlchemy.<br>
There's some really high pressure, some of these are under you know if it's working for them it's going to work well for you, especially Reddit Reddit gets a crazy amount of traffic.<br>
So pretty interesting that they're all using it and we'll see why in a little bit.
|
|
|
show
|
2:14 |
Before we actually start writing code for SQLAlchemy let's get a quick, 50,000 foot view by looking at the overall architecture.<br>
So when we think of SQLAlchemy there's really three layers.<br>
First of all, it's built upon Python's DB-API.<br>
So this a standard API, actually it's DB-API2 these days but we don't have the version here.<br>
This is defined by PEP 249 and it defines a way that Python can talk to different types of databases using the same API.<br>
So SQLAlchemy doesn't try to reinvent that they just build upon this.<br>
But there's two layers of SQLAlchemy.<br>
There's a SQLAlchemy core which defines schemas and types a SQL expression language that is a generic query language that can be transformed into a dialect that the different databases speak.<br>
There's an engine which manages things like the connection and connection pooling and actually which dialect to use.<br>
You may not be aware, but the SQL query language that used to talk to Microsoft SQL Server is not the same that used to talk to Oracle.<br>
It's not the same that used to talk to Postgres.<br>
They all have slight little variations that make them different.<br>
And that can make it hard to change between database engines.<br>
But SQLAlchemy does that adaptation for us using its core layer.<br>
So if you want to do SQL-like programming and work mainly in set operations, well here you go you can just use the core and that's a little bit faster and a little bit closer to the metal.<br>
You'll find most people, though when they're working with SQLAlchemy will be using what's called an Object Relational Mapper.<br>
Object being classes, relational, database and going between them.<br>
So what you do is you define classes and you define fields and properties on them.<br>
And those are mapped, transformed into the database using SQLAlchemy and its mapper here.<br>
So what we're going to do is we're going to define a bunch of classes that model our database.<br>
Things like packages, releases, users, maintainers and so on in SQLAlchemy and then SQLAlchemy will actually create the database, the database schema everything and we're just going to talk to SQLAlchemy.<br>
It'll be a thing of beauty.
|
|
|
show
|
3:10 |
When you're trying to model something like PyPI a website with a database the clearer of a picture you have the better you're going to be.<br>
So let's look around this running, finished version.<br>
Remember this is not, even though it looks very much like what we built.<br>
This one is actually the finished one that we going to sort of be aiming for.<br>
Alright, and we're not going to look at the code but we'll poke around what the web looks like.<br>
And we could just as well look at the real one but lets look at this.<br>
So on any given package this is pulling up the package AMQP.<br>
And apparently that's a low level AMQP client for Python.<br>
OK, great I actually have never used this.<br>
We have a couple of things going on here.<br>
We have the name of the package the version, bunch of different versions actually a description, right here.<br>
We actually have a release history.<br>
So each package has potentially multiple releases.<br>
You can see this one had many different releases and we can pull up the details about different ones, and jump back there.<br>
We have downloads, we have information like the homepage, so right over here we go to GitHub, apparently that has to do with Celery.<br>
You could pull up some statistics about it.<br>
It has a license, has an author.<br>
So, remember up here we have a login and register so we could actually go login to the site or create an account just as a regular user and then we could decide as Barry Peterson apparently did, to just publish a package and then there's a relationship between that user and this package as a maintainer and is probably a normalization table.<br>
Also have a license, BSD in this case.<br>
And we want to model this situation in a relational database.<br>
Let's see how we do that.<br>
PyCharm has some pretty sweet tooling around visualizing database structure.<br>
So here we're going to have a package and it's going to have things like a summary and a description and a home page, a license, key words.<br>
Things like that.<br>
It has an author but it also potentially has other maintainers so we have our users name, email, password, things like that and then I don't have the relationship drawn in this diagram but there'd be a relationship between the user ID and the user ID and the package ID and the package ID there.<br>
So this is what's often referred to as a normalization table for many to many relationships.<br>
So that's one part and then the package, remember it has releases so here each release has an ID.<br>
It has major and minor build version a date, comments, ways to download that.<br>
Different sizes as it changes over time.<br>
We also have licenses that relate back there.<br>
And we have languages.<br>
So here, this is going to relate back to that ID right there.<br>
Finally we're not going to track any of this but there actually are download statistics about this.<br>
About downloading all these packages and the different releases and so on so we went ahead and threw that in there.<br>
This is what we're going to try to build but we're not going to build it in the database.<br>
We're going to build it in SQLAlchemy and SQLAlchemy will maintain the database for us.<br>
I think the place to get started is packages so let's go on and do that.
|
|
|
show
|
6:50 |
It's time to bring SQLAlchemy into our application and start modeling things in the database, and actually using a database.<br>
How cool would that be?<br>
The place to start, I think, is modeling the tables with classes in SQLAlchemy.<br>
That's not actually the order, the first thing that happens in order when you execute the program.<br>
We have to do things like create the connection connect to the database, make sure the tables are configured and match the stuff that we're modeling things like that.<br>
But conceptually, the primary thing we're doing is modeling the database with these classes, so let's start there.<br>
Now, I personally like to have a separate dedicated section for the various classes.<br>
So we're going to create a sub-package.<br>
So here we have our data and let's start by modeling package, we'll call it packages, something like that.<br>
So here's how it works in SQLAlchemy.<br>
We have a class, we give it a name.<br>
Typically its name should be singular but, you know, however you want.<br>
It represents a single entity in the database anyway.<br>
It's going to derive from something here which we have to define, do that in a moment.<br>
And then into it, we're going to put a bunch of columns so it's going to be like an int.<br>
And then we'll have, say this be a name this is going to be a string, and so on.<br>
The things that we put on the right here are special SQLAlchemy values and they serve two purposes.<br>
At design time, they tell SQLAlchemy how to actually create the tables.<br>
At run time, they're effectively this integers, strings, and so on.<br>
So lets start by importing SQLAlchemy.<br>
Sometimes you'll see this as sa to keep things short so maybe we'll do that.<br>
Now notice it says this is not defined so let's install this.<br>
Cause, it's actually not defined.<br>
While we're doing that, we can go over here and also put it in the setup.<br>
Alright, now let's try it again.<br>
Oh perfect, so that's great.<br>
So we want a column, and in this column we would like.<br>
Actually, we were going to hijack the name thing and just make that the primary key.<br>
Remember the name of the package has to be unique on PyPI anyways.<br>
So let's just make this an sa.string and let's say primary key is true.<br>
Okay, starts to feel database-y right?<br>
The next thing, this is just something I like in databases is always knowing when a record was created.<br>
It lets you look at things that were recently created or see them in order, things like that.<br>
So let's add a created date.<br>
A datetime.<br>
And we're going to expand on these columns and make them a little bit nicer.<br>
But let's just get the basic structure in place first.<br>
A summary, now let me try to tie these back.<br>
So if we go over to SQLAlchemy here's going to be the name or the ID.<br>
This is the summary, right there that little tiny short thing.<br>
So we'll come over here this is the sa.column.<br>
And then, this part down here that is a big fat long description.<br>
So we'll have a description as well.<br>
We're also going to come over here and we'll have this little home page.<br>
We're going to be able to click on that so we need to model the home page.<br>
Also a string, and a docs URL some of them have the ability to say here are the documentation.<br>
and a package URL.<br>
Also you'll see that these have authors and maintainers and then, here they have an author.<br>
So the author's Mike Bayer and Mike Bayers's one of the maintainers as well but so is this person, okay?<br>
So we need to model it having a dedicated author but then also maintainers.<br>
Now we could do this to a relationship or we could put it directly on there.<br>
Maybe we want to keep it even in case they delete their account.<br>
So I'm going to put the author information here and we'll use a join to get to the maintainers.<br>
Then finally, these all have a license.<br>
Now we're going to use, oh let's see if we find the license here.<br>
Here we go.<br>
It's MIT.<br>
We're going to use a similar trick as we did here we would like to show just this simple information just the name of the license and maybe a link to it as well.<br>
Which is just the same as the title basically.<br>
So what we'd like to do is we could set this up in a way where we have to do a join on a license table because we're going to have a set of licenses.<br>
But, if we make the ID also be the name and be unique why would you have two licenses with exactly the same name?<br>
We won't.<br>
So, because the name would be unique we could use this and then this could actually both be just the string but also the relationship.<br>
So that'll avoid one join and make our table a little bit faster.<br>
That'll be sweet.<br>
So one more thing down here we're going to have releases and we're going to have maintainers.<br>
But the releases and the maintainers requires relationships.<br>
So we're going to come back to that in just a little bit but right now, things are looking pretty good for our table.<br>
If I go and start working with SQLAlchemy and saying here's my package table well one it needs a base class for this to work.<br>
But on the other, it's going to create a table called Package as a singular.<br>
I personally don't like that I'd prefer to have plural names and maybe lowercase.<br>
So we can control how this maps, so the database by putting a __tablename__ here.<br>
And we'll say lowercase packages so on the table it's going to show up as lowercase packages.<br>
But when we have one of them it's going to show up as a Package like a class would normally in Python.<br>
The other thing is sometimes nice when we're debugging this you would like to see in PyCharm without actually expanding all the bits what package you got back, and so on.<br>
So we're going to add a __repr__.<br>
And we'll just return something really simple here we'll just return.<br>
Just the ID, so it'll be package request package SQLAlchemy and so on if we're looking at a debugger output or printing a list of these things.<br>
Something like that.<br>
So that'll be a little bit helpful along the way.<br>
Alright so here's the basic concept of what we want to build.
|
|
|
show
|
1:56 |
Now for SQLAlchemy to work right we need to put a base class here.<br>
It needs to be a special one.<br>
Every class that maps to the same database needs to use the same base class.<br>
You can have different ones, like if you have an analytics database, and you have a core data database those might be different classes but all the ones that go into one database they should be the same.<br>
Okay, so how do we do that?<br>
Well, we're going to define a class and it's really quite simple.<br>
You sort of create one and only one of them from SQLAlchemy.<br>
So I'm going to put that into its own separate file, now.<br>
I think this one totally justifies its own file.<br>
What I'm going to do here is pushing the limit of maybe this is a little too fine grained but there's only one and it's supposed to be shared.<br>
So I think what I'm going to do is, do this.<br>
Create a model base class and then we have to import SQLAlchemy.extensions.declarative I'll just say, shorts we don't have to say too much there just, as dict then I'm going to create a class called SQLAlchemyBase.<br>
This class is the class that's going to be the base class but instead of defining it this way we use a factory method out of this place here so we say, declarative_base like that.<br>
And that's it.<br>
This is now our base type.<br>
It gets created at runtime by SQLAlchemy and then, by virtue of deriving from it, it basically means we're telling SQLAlchemy, "Here's another class that you're managing." So for example, put that here and let PyCharm import it.<br>
So for the top, we have from model base, import this and those two lines are going to pretty much be the same for all of our types.<br>
And that's it, this class can now be loaded and saved from the database once we connect to it.
|
|
|
show
|
4:20 |
We define our class that maps the database we have our SQLAlchemy base class.<br>
Next thing to do is actually create that connection and configure the database.<br>
So again, a new file to organize that code.<br>
Call it DBSession.<br>
So this is going to serve two purposes it's going to initialize the access to the database and it's also going to manage this overall session this unit of work design pattern so hence the name.<br>
We're going to come down here and define a class called DBSession and we're going to give it two pieces of information.<br>
We're going to have a factory and we're going to have a engine.<br>
The engine is going to manage the type of database we're talking to and the connection and the connection pooling.<br>
The factory is going to be the thing that creates sessions on demand, okay and the rule about these is there should be one and only one of them per connection okay so that's basically a singleton unless you're having multiple connections to multiple databases, in which case you got to manage that slightly differently than I'm showing you here.<br>
You want to have a static method called global_init and then we'll just make sure we call this once and only once, so we'll say if DBSession.factory and it's already been called no problem So we're also going to need to take a DB file to the string.<br>
What we're going to do is we're going to use SQLLite for this.<br>
That means when you set up this code and you run it you have no database to configure install, manage, etc.<br>
In production you probably if you're using SQLAlchemy you'll want to use some like Postgres or something along those lines that's just changing the connection string should be no problem but for here we're going to let them pass in a file and that file is going to represent just the actual SQLAlchemy file on disc.<br>
That's all you need for a SQLAlchemy connection.<br>
So it's probably prudent to do a little test here.<br>
Alright, now we know we have at least something that could be a file.<br>
Now let's define the connection string.<br>
SQLite always looks like this.<br>
sqlite:///<DB file> and I always like to print this out like here's my connection string.<br>
If this had a username password in it maybe I wouldn't exactly print that I'd print you know maybe not the password for sure but let's just go ahead and print.<br>
Connecting then like this connecting to DB at the connection string and then what we're going to do is we're going to create the engine.<br>
So we'll say engine equals SQLAlchemy.create_engine.<br>
Now it takes *args **kwargs which means thanks for the help, nothing sadly but what we can do is we'll pass the connection string here and then echo equals What do we put here, let's put false for now.<br>
If you would like to see every operation every bit of SQL that is sent to the database as it happens, print it out, change that to True it's a really nice debugging technique to see what's happening.<br>
Alright so because we want one and only one of those we're going to store that here and we also need while we're at it let's go ahead and create this factory and it'll just round out this thing here so we'll say DBSession.factory say SQLAlchemy.session.orm Better import that at the top too .sessionmaker say bind equals engine I think we're in good shape.<br>
Okay so this will allow us to initialize the connection and create this factory and then later when we want to actually create the factories we'll see there's a couple of evolutions or steps of improvement that will apply to this factory thing here as well but for now this is the sort of standard starting place so what we do is we come up with a connection string we create the engine based on that and we hold onto it, one and only one of them same thing, we create the factory based on the engine and this is going to manage both the connection string as well as the dialect, the type of database we're talking to because of that right there.
|
|
|
show
|
7:09 |
With our connection and engine set up it's time to create the tables.<br>
One way the wrong way would be to go to the database and actually start using the database design and modeling tools to just go and model the stuff.<br>
Because we've already got that right here.<br>
In fact, we need those to match exactly.<br>
So it's better if we just let SQLAlchemy do it.<br>
So, it's actually super easy here.<br>
Let's go down after we've done this bit and if we can import our SQLAlchemyBase which we can, it has metadata right there.<br>
And on the metadata there's no help from PyCharm here but it does exist when we say, create_all and pass the engine.<br>
So, if the database doesn't exist whatever connection string info we gave it here it will create it and then it's going to create the tables and the primary keys and the relationships and all that stuff based on all of the various types that derive from this.<br>
There's one really big caveat that's easy to miss here.<br>
By the time line 27 is run every single class that derives from it must have already been imported, so SQLAlchemy has seen it.<br>
If you import those afterwards, too late those tables are not getting created.<br>
So I'm pretty sure right now, the way this is working is it's going to be failing So we need to do something kind of like this.<br>
We need to go over here and say from pypi.data.packages import package, release and user, and whatever.<br>
Alright, so we got to do this for all of 'em.<br>
So we got to do it like this.<br>
Now that, expanding out of all the ones you need turns out to be super error prone so let's add one little trick here.<br>
And add one more file.<br>
Now let's call this all_models kay, and over here I'll say, well exactly that.<br>
So we're just going to list everyone here from packages, import package and we define release and we're going to import that and we define languages, we're going to import that and let's tell PyCharm "Hold on, no this, I know it looks like this does nothing," "but for the moment, we need to have this here." "It actually has an effect that you don't realize." "So thanks for the help, but not this time." And then over here, we can just make this a little simpler.<br>
We can just import it like that, and we'll put that little, you know "PyCharm, please ignore this." So that way, we can just model it right here and it doesn't matter where where we do this import but that's a really not obvious thing but you have to basically, before you run this import every single model or it's not going to work.<br>
However, with this in place and if we call this function, it should work.<br>
So let's go to our __init__ down here we're going to include the net routing let's have a init DB config.<br>
And we'll come down here and we'll just put that at the end.<br>
And this should be pretty simple so we'll say, "DB session," import that and we'll just say, "global_init," and we'll have to give it a file.<br>
What file do we give it?<br>
Well, let's make a little folder 'cause this is SQLite, we'll just make a little folder called DB and we'll put it in here, okay?<br>
If we were using, say PostCraft, like I said that we'd just give it a regular connection string like here's the server.<br>
But we're going to need this, so how do we do that?<br>
Let's say, "DB folder." We'll use the os module, yeah?<br>
So come over here and say, "path.absolutepath" "of some stuff, we're going to say, os.path.join" And what are we going to put in it?<br>
We'll say, "os.path.dirname of wherever we are." So, we're going to be in the PyPI folder just __init__.<br>
So we want to be in the PyPI directory and then down here, we're going to say "The next thing we want is DB." And then the next thing we want is pypi.bin or let's call SQLite, how's that?<br>
Want that right there.<br>
And we'll just pass DB let's call that file.<br>
'Cause it's not just the folder, but it's the file.<br>
Great, now if we run it we're not using the config for now so let's put an underscore probably need it later if we say "Store different DB settings in production" "and development" here.<br>
But now we don't need it.<br>
Alright, so when we run this we should see it print out a path that's located here and actually create the database files.<br>
You'll notice there's no little expando chevron thing here.<br>
There's no files in there.<br>
Let's run it.<br>
Well it didn't crash, that's a good start.<br>
It's creating this, you can see way down there.<br>
Now, if I go over here say "Synchronize." Oh look, look look look what we got!<br>
How cool is that?<br>
Okay, so, it's really nice that this is here how do we know what's in it?<br>
Did it actually create that packages table or did it not?<br>
Well, in PyCharm that's easy to answer.<br>
So we come over here and we can drag and drop this and it'll open up if, if if if it's a big if.<br>
So you got to go here once on your machine and go "datasource SQLite serial" and then notice here it has driver.<br>
It looks like it can update the driver files but sometimes it'll say you have to download the driver files 'cause there's no file.<br>
So we can download 'em again just to show you what that looks like.<br>
Alright, apparently that's updated.<br>
That's cool.<br>
We can come down here and expand this out in the schema and main and look!<br>
There's our packages.<br>
Primary key with an index ID.<br>
Right, there's that.<br>
We got a create date, which is a datetime.<br>
Our summary which is varchar.<br>
Our license which is varchar.<br>
There's a lot of varchar happenin' around here.<br>
But there is our database with our one table and notice it's named packages plural not upper case P package singular.<br>
You go over here, say "Select," "star from Packages where author email" look at that, beautiful.<br>
Beautiful beautiful.<br>
If for some reason you don't have the pro version of PyCharm you can use this app DB Browser for SQLite.<br>
Come over here and find the file.<br>
And you get the same thing, right?<br>
So here you go, it's not.<br>
I dunno, maybe it's nicer or maybe it's not quite as nice.<br>
I haven't used it that much but this is also another thing you can get for free.<br>
Just google DB Browser for SQLite.<br>
Either way, our database is all up and running.<br>
Now this is only the beginning of course but we've created our database and we've got a lot of stuff in place.<br>
Really all we have left to do is just to expand out all the other various tables we're going to work with.
|
|
|
show
|
4:01 |
So our package table came out pretty well.<br>
But notice, there's a few things that you might want in a database that are missing here.<br>
For example, we always have to set the created date explicitly, and if we forget it's going to be null, which is not great.<br>
Maybe this is a required field and we don't want to allow it to be null.<br>
I think by default they're actually not nullable everything but you can control those types of things.<br>
Default values.<br>
One of the really important things that people often overlook are indexes.<br>
Indexes are incredibly important for fast and high performing databases.<br>
The difference between a large set of data with an index and without can be a thousand times the query speed.<br>
So, it's pretty important to think about it.<br>
And in turns out to be really easy to do.<br>
The primary key one already has an index by default and a uniqueness constraint.<br>
Let's just start knocking out those additional requirements.<br>
Like, I want a default value here so we can just put a default.<br>
Now, you got to be really careful with this.<br>
It can go wrong if you just make a minor, simple misstep.<br>
So what we're going to do is we're going to use datetime.<br>
So we'll import at the top.<br>
We're going to use datetime.<br>
And we want to use now, okay?<br>
It's so easy to type that.<br>
If you type that, it is going to be very bad.<br>
What that means is, the default value for when everything's created is going to be basically, app start time.<br>
But if we omit this, and we pass the function not the return value of it, then the default will be execute that function, and get the time when it's inserted.<br>
That's what we want.<br>
Maybe we want the summary to be nullable so we'll say nullable as True.<br>
That means that it's not required.<br>
Something I want to leave for the description.<br>
Same with the homepage, the doc, and the package.<br>
Maybe we don't necessarily have an author name.<br>
Well, we might not have one actually for the e-mail but if we do, we would like to be able to search and say really quickly, show me all the packages that this author has published.<br>
So we come down here and say index equals True, which is really nice.<br>
And similarly, maybe we want to know show me all the packages with MIT license.<br>
That'd be kind of crazy, but if we want to ask that question having an index here is really important.<br>
Of course, these are going to be foreign key relationships when we get them in place, but there.<br>
Now this is the table that we really wanted to build at the beginning, just didn't want to overwhelm you with all the pieces.<br>
So watch this, if I run it again I'm sure its going to be amazing.<br>
It's now, we've done that create table.<br>
Let me refresh it, and hmm.<br>
Where are my relationships?<br>
Here's something you got to learn about SQLAlchemy.<br>
It will create the tables, it will not upgrade them it will not change them, it will not modify them.<br>
Once they're created, done.<br>
No changes.<br>
What do you do?<br>
Well, in this situation, you just go over here and you just delete the database.<br>
You just delete it, and it's gone and that works really well when you're just like really quickly prototyping, getting stuff in place.<br>
But if there's data there, if it's in production, that's not going to fly.<br>
So later we're going to talk about something called Alembic which will let you do migrations to take the database from one step to the next step, to the next step to the next step, and that works really well.<br>
But for now, in this step, we're just going to delete the data, and put it back.<br>
So you can go over to here and drop the table.<br>
It's gone.<br>
Rerun our code.<br>
And if we re-sync it, package is back, but this time notice that there's a little indexy right there and there.<br>
And if we go and actually open it you can see we have an index on author email, and index on the ID of course, and so on.<br>
I don't think, I guess the SQLite doesn't store the nullability.<br>
Doesn't have the concept of non-nullability versus nullability maybe here.<br>
That's fine, we connect something like Postgres it'll convert that over, and definitely store those.
|
|
|
show
|
3:35 |
With our package class mostly in place I've already created the other various tables that we're going to need.<br>
So we went through creating packages in great detail and we're not quite done we still have to put some relationships on it.<br>
But, let's just quickly look at the rest because they're exactly the same and it's not really worth taking tons of time to work it out.<br>
So downloads.<br>
We're going to have a download thing.<br>
Again, it derives from SQLAlchemyBase when I altered the name here.<br>
This is interesting.<br>
We have an integer, a bigint, primary key here and we're actually telling it to auto-increment.<br>
So that way, we don't even have to set it.<br>
It's just going to set itself right?<br>
That's great.<br>
Similarly for created date.<br>
So when we insert a new record we don't have to set those two values.<br>
But, for the download we got to store the release and the package and the IP address and the user agent.<br>
And we might want to do queries by these showing me all the downloads for this release.<br>
Count the number of downloads for that package.<br>
So we have an index on those.<br>
Languages, this is like programing languages like Python 227 or something like that.<br>
So we have a little bit of info here.<br>
Pretty straightforward.<br>
Again, we're using the ID to be both the name and the ID since it has to be unique.<br>
So, that will avoid one more join.<br>
Same thing for licenses basically here.<br>
Want to have a little simple basic information.<br>
Here we have the maintainer table.<br>
And this represents the many to many relationship between the user table and the packages.<br>
So we have one user can maintain many packages and one package can be maintained by more than one user.<br>
So here we have that information.<br>
Real simple.<br>
These we already did.<br>
Releases.<br>
This is going to be a release of a package.<br>
So the release is going to have an ID.<br>
More importantly its going to have a major minor build version and a date.<br>
It also has a URL to download that version and maybe a comment on what's changed as well as the size of that download.<br>
I'm going to put a package relationship in here but, that's not in place yet.<br>
We'll get to package relationships shortly.<br>
And then finally, the user table.<br>
So we have the ID which is auto-incrementing.<br>
And we have their name, their email.<br>
Hashed password, we will never store plain text passwords.<br>
Never!<br>
So, we don't want to just put password.<br>
We want to make it super clear that this is a hashed password.<br>
Again, when do they create their account?<br>
What's their profile image?<br>
And we'll keep a record of when they last logged in.<br>
Maybe we have a table, maybe an audit table but, for now, when did we last see these people?<br>
Have they logged in recently or has it been like five years?<br>
And that's it.<br>
That's all the data that we need.<br>
Over here in our database we just have the one.<br>
But if we re-run it.<br>
We go refresh.<br>
There are all of our tables.<br>
Perfect, right?<br>
So SQLAlchemy will make the new tables but if we had made a change to packages that change wouldn't be applied.<br>
Remember, that's migrations.<br>
We'll get to that later.<br>
Alright so here we are.<br>
We pretty much have this up and running and we've got all our data modeling done.<br>
The only thing we don't have in place currently are the relationships.<br>
That's an important part of relational databases, right?<br>
So we're going to put that in place and then I think we will have our models more or less than.<br>
Oh, one more thing I didn't point out but I did kind of infer before.<br>
Now that we define these new models we have to put them all in here.<br>
I actually try and keep them in alphabetical order so I can quickly look, oh have I added licenses?<br>
Let's see.<br>
Oh yeah there it is.<br>
You can end up with many of these.<br>
So this alphabetical order thing can definitely help.<br>
But every time we add a new class, it has to go here so the SQLAlchemyBase sees it that's why that create worked.
|
|
|
show
|
6:35 |
One of the core relationships in this model is that we have a package and packages have releases.<br>
A release has a package and a package has many releases.<br>
Okay.<br>
So let's model that right here.<br>
Now, SQLAlchemy has a way to build in these relationships which ultimately create foreign key constraints and relationships in the database itself.<br>
So we come over here and we can just say releases is equal to and we need to go import up here...<br>
some more stuff.<br>
We need to import the orm to explicit use that.<br>
I'll just say as orm...<br>
and down here we'll say orm.relationship.<br>
The first, again it's *arg, **kwarg which I don't know, it's a pet peeve of mine.<br>
There's just a bunch of keyword arguments.<br>
Let's just explicitly set them with default values but anyway, here we have, sum value the first thing we have to pass, the first positional argument is the name of the class that we're relating to.<br>
There.<br>
I'm going to put release.<br>
What we probably want is to have a certain order here.<br>
The way it's going to work is we're going to get a package back and it's going to have a property or a field which is a list that we can just iterate over so for, r in p.releases, things like that.<br>
Having some form of order on that is going to be really important.<br>
Either descending or ascending, of course we could sort it every time we get it back but it's much better to let the database do the default sorting.<br>
If we need to change that, we can.<br>
The thing that we're going to put here is we're going to say order by, equals.<br>
Now we could put two things here.<br>
One thing is I could say release and we got to import that, and we could say major version like that and that would be ascending or I could even say descending like this.<br>
That's going to show three, two, one but then there's other parts as well right?<br>
There's the minor version, if the major version matches we want to sort by that.<br>
This is pretty common to write like this but in this case what we actually want to do is we want to put this into a list.<br>
So we're going to do major and then minor, and then build.<br>
We'll leave the comma.<br>
So that's going to do the ordering.<br>
If we go over here and look, these all have indexes so the ordering should be nice and fast.<br>
There's not that many anyway but still, good.<br>
Over on the other side, we would, if we do a query for a package, we're going to get its releases but then on each individual release we'd like to be able to navigate this relationship in code in reverse, without actually going back to the database.<br>
We can say backpopulates equals package.<br>
That means over on the release, somewhere down here we're going to have a package property which we'll do more details on that in a second.<br>
But when we get one of these packages and we interact with its releases each one of the ones that comes back is going to have that set to the package that we got from the database.<br>
Makes sense?<br>
Okay.<br>
This lets us navigate bidirectionally which is really really important.<br>
This side of things, I think is done.<br>
The releases is a little more interesting.<br>
Let's go, how do we know that a release is related to a package in the database.<br>
Well, it's going to have a package ID is equal to some SQLAlchemy thing.<br>
Right, some SQLAlchemy column here.<br>
Now, this is going to be set by the relationship but this is a field or column in the database that has to be set, and it's going to be SQLAlchemy not string.<br>
That's the way that IDs are packaged right, if we go up here and look.<br>
This is a string, so that has to be a string there, right, those match.<br>
But in addition to being just a regular string it's going to also be, a foreign key relationship.<br>
We'll say SQLAlchemy.ForeignKey.<br>
When we did our relationship back here we spoke in terms of classes, the release class.<br>
When we talk about the foreign key we talk in terms of databases so we'll say packages, not capital p package, dot ID.<br>
That is going to store the relationship in the database but we also would like to be able to navigate it in memory and code, so here we're going to do orm again we got to import that.<br>
Come down here, and this will be a relationship...<br>
To the class package and it's going to back populate releases.<br>
Let's look at that over here, and it's going to back populate this so if we get a singular release it's going to go and we interact with its package then it's going to automatically do this right so this bidirectional nature and then we're talking about this class here.<br>
It can be confusing when you're working with these relationships when you speak in database terms when you speak in Python type terms but here's how we're going to do it.<br>
Now in order for this to have any effect of course we need to go over here and drop these two tables.<br>
If we rerun it we'll see if we got it right.<br>
Encouraging, let's look again.<br>
Now over here, actually if we look at releases...<br>
if we look at releases, you can see we've got package ID...<br>
is a relationship over to over to package.ID.<br>
Alright, we have that relationship modeled there which is pretty awesome.<br>
We have our foreign key constraint right there.<br>
From package, back, did it put it on the other one as well?<br>
No, just on the releases table but that's all we need.<br>
Now that's pretty interesting to see it show up in the database but what we'll see is if we can come over here and we obviously this is not going to work, alright.<br>
This is not really a thing but let me just type it out.<br>
So if we have p as a package that we somehow got from the database then we can say p.releases say for r in releases print r dot and then off it goes right, major version or whatever.<br>
This relationship will mean that we can do a single query to get the package and then we can just navigate this relationship.<br>
Similarly if we have this we can go .package, .ID if we wanted to print out the name right?<br>
And that would navigate these two tables in the database using our classes here and that's what we've built with our ORM relationship on both sides of the story.
|
|
|
show
|
4:15 |
Before we actually start using SQLAlchemy to insert data and query data and so on, Let's talk about some of the core concepts we've seen and some of the fundamental building blocks for modeling with SQLAlchemy.<br>
So we started with the SQLAlchemyBase.<br>
Remember, the idea was every class we're going to store in the database derive from this dynamically defined SQLAlchemyBase class.<br>
You can call it whatever you want.<br>
I like SQLAlchemyBase, but there's other you know, it's just a variable name it as you like.<br>
So we want to create this singleton base class to register the classes and types that go in the database.<br>
Remember, there's one and only one instance of this SQLAlchemyBase shared across all of the types per database.<br>
So for example, we're going to have a package, a release, and user they all derive from this one, and only one SQLAlchemyBase type here.<br>
To model data in our classes, we put a bunch of class level fields here: ID, summary, size, homepage, and so on.<br>
And each one of them is a column.<br>
SQLAlchemy.column and they have different types like integer, string, and so on.<br>
We can see some of them are primary keys and even if it's an integer they can even be auto-incrementing primary keys which is really really nice.<br>
And we can also have relationships like we do between package and releases.<br>
One really nice feature of databases is they have default values.<br>
We saw with our auto-incrementing ID our primary key we don't have to set it the database does that for us.<br>
So here we can pass datetime.now the function not the value, the function and then it's going to call that function, now whenever a row is created and set that value to be, well, right now.<br>
That's super nice.<br>
We can also do that up here with more complex expressions.<br>
So in the bottom one we've literally passed an existing function, datetime.now but above we wanted to define this default behavior in a more rich way.<br>
So we're passing our very own Lambda expression that takes the uuid for identifier converts it to a string and then drops the dashes that normally separate it into just one giant scrambled alphanumeric soup thing.<br>
You can create these default values by passing any function a built in one or one of your own making.<br>
You also want to model keys and indexes.<br>
So primary keys automatically have indexes we don't have to do anything there.<br>
That's got a uniqueness constraint as well as a indexes.<br>
This created one maybe we want to sort by the newest users for example.<br>
Well if we're going to do that we very much want to put an index on that.<br>
As I pointed out, indexes can have tremendous performance benefits.<br>
It's totally reasonable to have a thousand times difference performance in a query if you have tons of data on whether you have an index or not.<br>
Indexes do slow write time but certainly, in this case the rate of user creation versus querying and interacting with them is you know, it's no comparison, right?<br>
We're creating far fewer users probably than we are querying or interacting with them.<br>
We could also specify uniqueness.<br>
We didn't do that in our example.<br>
We can say this email we can't have two users with the same email.<br>
You know, emails are very often used to like reset your password.<br>
And if you have two users who's going to get their password reset?<br>
All of 'em?<br>
One of 'em?<br>
Who knows, none of 'em?<br>
So you might want to say there's a uniqueness constraint on the email to say "Only one user gets to use particular email" and that's super easy to do by just saying unique equals True.<br>
Finally, once all of the modeling is done we have to actually create the tables and it turns out that that's super easy.<br>
We import all the packages.<br>
Get the connection string and we create an engine based on the connection string and then we just go to SQLAlchemyBase to it's metadata and say create_all and pass the engine.<br>
Boom, everything is done.<br>
Remember though, this only creates new tables it does not modify existing ones.<br>
So if you need to modify it wait till we get to the Alembic chapter the migrations chapter or do it yourself.<br>
Or, you know, if you're just in development mode maybe deleting it and just letting it recreate itself.<br>
That might be the easiest thing that's what we did.
|
|
|
|
50:34 |
|
|
show
|
8:18 |
You can see we've defined our schema and modeled those in our data classes here and everything seemed to be working just fine.<br>
However let's see what kind of data we are having over here and we can jump to the console, do a little query okay get all the packages, 0 packages.<br>
Not so interesting is it.<br>
Well I guess we're going to have to insert some data.<br>
Now the reality of inserting data is we're going to need some web forms.<br>
We're going to need people posting data to the service and things like that.<br>
We're going to do that when we get to say the user section.<br>
But for the moment we need to bootstrap this whole project and get some data in here so we can show it, things like that.<br>
Along those lines, we're going to do two things.<br>
First of all we're going to write a little bit of basic code.<br>
And notice I've made a bin folder over here.<br>
Create a new little Python file called basic_inserts.<br>
Now in this basic_inserts what we're going to do is just insert a couple of packages and maybe some releases just to see how it works and then we'll go and actually use this little data to load up all the real PyPI data using exactly the structure that we have here.<br>
Great, so let's get started.<br>
Now notice we have two new requirements Python dateutil and progressbar2.<br>
I'll go ahead and install those.<br>
PyCharm is noticing that I've updated down here but I've updated the setup so we're going to need that for this load data thing but we're not using it yet.<br>
One thing we will need is we're going to need to initialize the database.<br>
So what we're going to do is we're going to come first import os and our DBSession.<br>
And we need to import pypi as well.<br>
So we're just going to go figure out the path to that file right there.<br>
Then we're going to call DBSession.global_init.<br>
We did that previously nothing new here but you have to do this at the beginning of every process is going to talk to the database.<br>
Great, so let's define the main method that we're actually going to use.<br>
I'll do the sort of main convention that Python uses for its processes.<br>
So that's going to initialize the database.<br>
And then let's just go over here and do a method I will call it insert_some_data.<br>
So we'll just say insert a package.<br>
So what do we want to do here?<br>
Well let's figure out what we have to set in order to insert a package.<br>
So what we going to do is we're going to insert a package and we're going to give it a one or two releases.<br>
So we'll just come over here and grab some of this stuff so we can see what we need.<br>
And let's just get started.<br>
So we're going to say p = Package().<br>
We're going to allocate one of those like that.<br>
That's the one we defined we don't need to set the ID.<br>
Actually, sorry we do is not auto-incrementing like the others.<br>
So let's say id is going to be input package name and then the created_date.<br>
We don't need to set the summary.<br>
Summary is input.<br>
Package summary.<br>
We won't set the description or the home page of the docs for now.<br>
We'll leave that alone.<br>
Say p.author and also set the email here.<br>
Okay that's going to cover that that sequence set the license that's easy.<br>
Now we're going to create two releases.<br>
So what do we need for a release.<br>
Let's drop that stuff right there.<br>
In the release, the id is going to be set automatically.<br>
We need those.<br>
We have a created_date they'll be set automatically and I will just copy this over.<br>
So let's say r1 = Release().<br>
So here let's set the version and the created_date will be automatic.<br>
comment, url, size I guess we'll leave those all alone for now.<br>
We'll set the size to a 100k.<br>
How's that.<br>
And we can do the same for release two.<br>
Technically don't need to call it release.<br>
Just keep the same variable name but just so it all crazy.<br>
Got a little bit bigger.<br>
Okay so we've created these in memory but that doesn't put them in the database.<br>
How do we put them in the database?<br>
What we have to use is what's called a session.<br>
So here's this unit of work design pattern as opposed to active record that SQLAlchemy uses.<br>
So we come over here and we say DBSession go to that factory and that creates our session.<br>
And then later we're going to say session.commit().<br>
Assuming we want to save it.<br>
And it's somewhere in between we'll say session.add(p) for the package.<br>
We could also go over here and say okay r.package_id = p.id.<br>
And that would associate them in the database.<br>
But we could do something more interesting now we could say p.releases.append([r1, r2]) And just put them together in memory the way we would in code.<br>
And then this will navigate that relationship.<br>
All right.<br>
Well let's give that a shot.<br>
I'll insert a couple of these.<br>
Let's go and run our basic inserts let's see if we got things working right.<br>
So far let's go with a request.<br>
requests HTTP for humans, connect, writes oops misspelled it but that's alright MIT I don't know, we'll just guess to be 1, 0, 5, 6, whatever, 2, 0, 0.<br>
Now let's do one more of these.<br>
Let's go with SQLAlchemy the ORM for Python, Mike Bayer.<br>
I'll go with BSD.<br>
I've no idea of that's what it is but I'm just going to make this up.<br>
1, 1, 1 and 2, 2, 5.<br>
Then lets just bail out go back over to our database.<br>
I want to run a select of packages.<br>
I think I got it open again.<br>
Look at that, here we have it.<br>
It's all inserted we have requests and SQLAlchemy both inserted today.<br>
We didn't set a lot of the details but we did set many of them.<br>
Got our licenses and those now the other interesting question is what about this?<br>
What if we go over here to over here and say releases and run the same query Look at that.<br>
We have the various releases and most importantly the package ID was already set.<br>
So that's really beautiful.<br>
Let us fully leverage the object oriented nature of this.<br>
We create the package packages contain releases.<br>
So we went to the releases and we put the various releases in there release 1 and 2 and we just called add for the package and it followed the entire object graph to create these relationships for us.<br>
So you get to skip out a little bit on thinking of all the ways your data is split up in SQLAlchemy and just think of how you wanted to focus and work in memory.<br>
Now these relationships can have performance issues and we'll talk about that when I get to querying on how to fix it because SQLAlchemy does have ways around the inherent performance problems you might get here.<br>
but it's a really really nice way of working and this is how we do inserts for data.<br>
Over here we create a session.<br>
We've allocated the objects.<br>
We just add one or more of them and then call commit.<br>
All happens successfully or with a failure right there.<br>
If we wanted to make an update we could do a query.<br>
Get one of these back from one of the sessions.<br>
Talk about query, do a query make a change to it and then call commit and that'd push the changes back.<br>
Okay so this is basically how we work inserting data.<br>
And this is the real simple one and that's how it works.<br>
Inserts in SQLAlchemy, create the objects add them to the session, called commit.<br>
Boom, Inserted.
|
|
|
show
|
3:52 |
You saw how to insert data, now let's go through the nitty gritty details of actually inserting all the data from real sources.<br>
So there is an API for PyPI I've used that API to get most of the top 100 packages.<br>
So for example, here's click.<br>
Let's look at that real quick.<br>
And I've downloaded this and it's from Armin Ronacher, creator of Flask.<br>
Here you can see the licenses and the languages in this funky format.<br>
The author info embedded in there.<br>
You see the license, it's not set here but it's set up here, so it's kind of a kind of confusing and tricky to make this work, but that's fine.<br>
So here's a home page The maintainers right now, there's no other maintainers set.<br>
The full summary and then here are a bunch of releases for it, right?<br>
Each release has comments and so on.<br>
Now, this data is not super useful to us in this format.<br>
There's not much description but the other ones...<br>
Let me just throw one in here so you can see.<br>
It's sterling, park, parse or an alternative there.<br>
Here you can see the description has a lot more a lot more detail, it goes over to column 1,614 so that's pretty long.<br>
Right, so what we're going to do is we're going to import this data so you have actual packages, releases, users, etc.<br>
to work with, how are you're going to do that?<br>
Well, I'm not going to leave that up to you 'cause that's pretty messy but what I am going to do is I'm giving you these PyPI top 100 JSON files right here.<br>
They're going to be just at the top of your repository right there.<br>
Now, over here we're writing basically the same code.<br>
Initialize the data base, get a session and what it's going to do is it's going to go through and check if and only if there are no users, it's going to load those files and it goes through and parses out all the users and then it actually saves them to the data base and then it goes through and finds all the packages, saves them to the data base, along with their releases and languages and licenses and so on.<br>
And it prints out a little summary.<br>
So right now there's no data and I actually deleted those other two releases I put in there.<br>
So let's run this and I'm actually going to run it outside 'Cause it has a cool little progress bar.<br>
So, let's go over here and say I'm going to activate our virtual environment 'cause we need the same packages and everything there.<br>
And then we're going to say "Python," copy that path and we're going to run that right here.<br>
Let's see how we do.<br>
Beautiful!<br>
It's got some extra junk that it printed out apparently but you could take that out.<br>
Here's the final numbers it found 84 users, 96 packages- from those packages we have 5,400 releases, 10 maintainers, 25 languages and 30 licenses.<br>
Cool, now let's just go over here and do a quick query to make sure that's in there.<br>
So if we run that again, now you can see there's tons of releases.<br>
This is all AMPQ, they go in order basically AsyncIO view packages there's all the packages.<br>
Right, here's Tornado and so on.<br>
These are the popular ones.<br>
Really nice, so now we have actual data to work with.<br>
You're welcome to look through this load data.<br>
It's pretty interesting, how to take these actual real world data sets and import them using SQLAlchemy.<br>
So, we've got all this JSON data now we're putting it in our data base, it's a lot of yucky details about making it work so I'm not going to go through it.<br>
But, if it's useful for you feel free to grab it we now have data in our database.<br>
And all the inserts and everything was done just the way you saw in the previous video.
|
|
|
show
|
2:26 |
One of the core concepts of SQLAlchemy is this Unit of Work.<br>
Let's dig into that.<br>
The unit of work is a design pattern that allows ORMs and other data access frameworks to put a bunch of work together and then at the very end decide to go and interact with the database.<br>
Decide, now, we're going to actually save this data within a single transaction.<br>
So here we have a bunch of different tables customers, suppliers, and orders.<br>
They're all providing entities into this operation this unit of work.<br>
So maybe we have a couple customers one supplier, and one order.<br>
We've also maybe allocated some new one like we did with package and we're inserting that into the database.<br>
And maybe we've changed things about the supplier.<br>
We're updating those in the database.<br>
And the order is canceled, so we're calling delete on that.<br>
All that gets kind of queued up in this unit of work and then we get, so I'll call commit in SQLAlchemy syntax and that pushes all those changes which are tracked by the unit of work the so-called dirty records, right?<br>
The things that need to be inserted the things that need to be deleted the things that need to be updated, and so on.<br>
So we can use these unit of works like that.<br>
And the way we create them are with these sessions.<br>
So we've seen that we create these engines and the engine gives us this session factoring.<br>
That was all encapsulated within our DBSession class.<br>
We do this once, right?<br>
And then, every time we want to interact with the database we create one of these sessions.<br>
So we come over here and we call that session factory it gives us a unit of work, which is often called a session kind of treat this like a transaction.<br>
A bunch of stuff happens in memory, then it's committed.<br>
Maybe we add something, maybe we do some more queries maybe that tells us what we've got to do to add some more we could make changes to the results of those queries either updates or delete.<br>
All of that work has not interacted with the database.<br>
In fact, other than the query there's not actually been any interaction with the database.<br>
This add doesn't actually add it to the database.<br>
It just queues it up to be added and when you call commit that commits the entire unit of work.<br>
Don't want to commit it?<br>
Don't, nothing will happen in the database.<br>
There will be no changes to your data.<br>
And that's how the unit of work pattern appears and is used in SQLAlchemy through this session factory, and then committing it.
|
|
|
show
|
5:02 |
Here we are back at our demo app and remember, this is all being driven with fake data but we're about to change that.<br>
Notice these 0 projects, 0 releases, 0 users.<br>
Not so amazing and here, these are just things that we've hacked in here.<br>
So our goal during this video, this lecture, is to actually fill out of those pieces right there.<br>
So first of all, where is it happening?<br>
Let's close some of this stuff off.<br>
Right here we're returning the test packages and in our template, we literally just have zero, zero, zero.<br>
So first of all, we need to pass that data along.<br>
So let's say package_count, release_count, user_count is zero and then we can use these over in our template.<br>
So we can put 'em like that.<br>
We could actually get a little better format if we do it like so.<br>
Like this, that way we'll get comma separators or digit grouping there.<br>
So do the same for releases and users.<br>
Let's rerun it and see how it works.<br>
Ooh, releases_count.<br>
Release, singular, count, it didn't like that.<br>
Amazing, it's still zero but now it's coming from that place.<br>
We can see if we were to put something here like 10,000, remember you've got to rerun it for the Python code to change.<br>
There we are.<br>
Now we have 10,000 projects, awesome.<br>
So it is being driven with that data.<br>
Now our goal, of course, is not to type zeros here but to go and get the data from the database.<br>
There's two ways we can do this.<br>
Well, there's probably infinitely many ways to do this but there's two obvious ways in which we can do this.<br>
One obvious way would just literally be to start writing queries inside this home index.<br>
That is not the way we want to do things.<br>
It makes it hard to test our code.<br>
It makes detangling the controller logic from the data access logic problematic and so on.<br>
So a pattern that I've settled in on is putting what I call data access services and sort of grouping them by their roles.<br>
So what we're going to do is we're going to come over here.<br>
We're going to define I guess a Python package.<br>
We'll call this services and these are not external services these are the data services I'm talking about and let's go and add Python file called package service.<br>
In here we can have some functions, def.<br>
Do a release count and let's take something similar and we'll put that in and do a user services well they're going to do many more things than count of course, but this will get us started.<br>
All right, so up here we're going to save from pypi.data, import, oh not data, sorry.<br>
services, ah, it looks like I made that in the wrong place, oops.<br>
Okay so we'll import this and then we can come down here and we can just say, .package_count and release_count and we'll do the same for users.<br>
User service, okay?<br>
Now, I think it returns None, which is probably going to crash, so let's go and actually implement these.<br>
All right, so they're all going to be basically the same.<br>
In order to interact with the database, we need session right, so we'll say session = DBSession.factory like that and later, we're going to just call close on the session.<br>
We don't actually have to do anything and we can just skip it.<br>
I think it'll get garbage collected straightaway.<br>
So we want to do a query so I'll return session.query and what do we want to do a query on?<br>
Well that's on packages, so we import that and we could do a filter.<br>
We could do an orderby but really all we care about is a super simple count.<br>
That's pretty easy, right?<br>
See the release and let's go do the user.<br>
All right, run it again.<br>
This thing should work.<br>
Let's go refresh and look at that.<br>
How many packages did we import, 96.<br>
How many releases do we have, 5,400 with 84 users, awesome.<br>
So everything is in place and now we can start doing things like get our new releases by just simply adding one more function over here.<br>
So we'll do that later but everything's coming together and our little data access piece, well it's working really nicely.
|
|
|
show
|
6:12 |
Now it's time to write another query.<br>
Actually we're going to write a couple queries to do something interesting and this actually might be the most complicated thing we do in the entire website.<br>
But, yeah you'll get to see a lot of stuff in action.<br>
So let's look over here real quick, here's our homepage.<br>
We're now driving that little slice out of the database.<br>
But remember this, this is just our fake data.<br>
So we want to actually go get the latest releases and then correlate those back to the latest packages and then show them here.<br>
Okay, how do we do that?<br>
Well, we're going to write a function.<br>
We want to say how many releases we want.<br>
So, we'll have a limit by default that limit is going to be 10.<br>
And it's going to return a list of package.<br>
List comes out of the typing model and the package that we already have.<br>
As always, everything starts like this and then we're going to return something down here at the end.<br>
So what happens at the middle?<br>
Well, the data model that I have chosen which was the most sort of naive and straightforward one maybe isn't the best for this site.<br>
Maybe it would have been better to have a little information on the package itself about when it was last modified but, it doesn't matter.<br>
What we're going to do is we're going to go get the latest releases find out the package IDs those correlate to and then we're going to go and get those packages out of the database.<br>
Great, so how do we do that?<br>
First we say releases is going to be and we're going to do a query.<br>
And the way that queries work is you to your session and you say I'd like to create a query based on a particular thing.<br>
Here we're querying Release.<br>
Now we can do where clauses like this, filter.<br>
We can do orderby.<br>
So we actually don't want to do a filter.<br>
We just want to say show us the newest ones.<br>
And whenever you put some sort of qualifier here like a filter or a something that you're sorting by you use the type name.<br>
Release.<br>
and then what are you going to order by?<br>
Created date descending.<br>
Now PyCharm gives a warning that says descending doesn't exist.<br>
Nevermind it definitely does.<br>
That is going to give us back the releases.<br>
And we probably want to limit those by something.<br>
We don't want to get every release that's going to be a lot.<br>
So we'll say limit, we don't know for sure if maybe there's some kind of release done really quickly on the same package.<br>
So if we want to be sure that we give them say 10 or however many they're asking for we should probably double this or something.<br>
So I'll say the limit times two.<br>
And that's because we could have a really quick release of requests and then another one of requests.<br>
And then, you know we'd have two more than just the 10 releases.<br>
Actually get the 10 distinct packages.<br>
So we've got that.<br>
Now, what I want to do is come up with just the package IDs as a list of strings.<br>
I'm going to do that with a simple list comprehension.<br>
So say r.package_id for r in releases.<br>
In fact, if we wanted to do it I could even do it as a set comprehension.<br>
and that would give us distinct packages so we don't have to check for them existing twice.<br>
Beautiful.<br>
So, we've got the latest releases and now we've converted those to the distinct set of the latest package IDs.<br>
Now all you got to do is actually get the packages.<br>
I just realized my little trick here is going to be great but we're going to need packages in order as well.<br>
So let's do this.<br>
So now we need to do a query so we go back to the session.<br>
Go to query and this time on package.<br>
And how do we say I would like all the packages that are in this set of package IDs.<br>
Turns out that's super easy.<br>
Say filter package.id.in_ Because in_ is a keyword they say in underscore you give it package IDs.<br>
That's it.<br>
That's going to give us all the matching packages.<br>
Now, we need to preserve the order.<br>
So, if all we wanted was the packages we could just kick those back.<br>
But remember, we asked for more than one so we don't get duplication, things like that.<br>
So, let's go and actually turn this into a quick dictionary.<br>
p.<br>
based on the ID.<br>
Do a little dictionary comprehension on that result and then finally we'll get these back.<br>
so we're just going to put stuff into this little results array right here and we're going to do it in order.<br>
There's probably a cool join way if I was better at data bases I could do that here but we're doing it this sort of convoluted way and it's going to work fine.<br>
Maybe not the most efficient, but not too bad.<br>
Alright, so we've got our results going through the releases in order and adding the packages in order and then we're adding them back.<br>
So this should work, but we're not calling it yet.<br>
Lets go over here, remember our get_test_packages?<br>
So we'll say, package service, not latest releases.<br>
Now, this is also not going to work because if we go over to our template it was using that fake data which had names.<br>
We don't have names, we have IDs.<br>
We actually do now have a description so let's put that in there.<br>
p.summary in here.<br>
Alright, let's give it a shot, see how we're doing.<br>
Here's where the stuff goes, we run it, Boom!<br>
Sweet, look at that.<br>
We've got 1, 2, 3, 4, 5 6, 7, 8, 9, 10.<br>
Exactly like we asked for.<br>
Awesome!<br>
So now we've got our packages right here.<br>
It looks like awscli was the most recent release out of the ones that we have.<br>
And now if we click on it, well it doesn't take us anywhere.<br>
Let's do one more thing.<br>
We have this ID here, and lets fix r href.<br>
This is project/{id}, refresh Boom.<br>
That page needs some help.<br>
But this page, this page is done.<br>
This is awesome.
|
|
|
show
|
2:10 |
So far we've seen our homepage is looking really sweet.<br>
We don't have that much data yet but it is data driven and this is coming out of the database.<br>
However, when we pull up the details for one of the packages under project/{package_id} well the details are not so much.<br>
So that's what we're going to focus on in this video on how to fix this.<br>
Now, the actual design for this page remember, remind you what this looks like it looks like this.<br>
It's got this little install instruction whether or not it's the latest version the ability to see all the releases the details, the homepage, the maintainers and so on, and so on.<br>
All of this stuff.<br>
It turns out the actual web design to do all that would take quite a while and we already spent a ton of time back in the adding design after the bootstrap chapter that we already did on the homepage and this is really pretty similar.<br>
So what I'm going to do is just quickly talk you through what we got here.<br>
So here is some more HTML.<br>
We're using the same, sort of, hero concept.<br>
This time we've got that little install bit.<br>
Whether or not it's the latest release and how to switch from that.<br>
Same little stats.<br>
Here instead of having the numbers though, we have the summary.<br>
And the maintainers and we have the side bar navigation thing.<br>
And then somewhere down here we have the project details.<br>
And we're using structured output HTML like stuff.<br>
Now if this was just marked down to be real easy to convert it to HTML and actually show it properly formatted but because most of it's restructured text and I haven't found a good library for that I just threw it into a pre so we can just read it, all right.<br>
So it's not going to be perfect but it's close enough.<br>
So with this in place, you think we could load it up but in fact, if I rerun it here it's going to run into some problems.<br>
'Cause we don't have the data.<br>
Right so wait hold up, we need the actual package object from the database.<br>
You just gave us a fake name.<br>
This is not really the package object.<br>
Our goal will be to implement the data access layer and pass the right amount data over make this view happy, right.<br>
So working our package service and our controller.
|
|
|
show
|
6:43 |
We have our design in place but we don't really have the data being passed.<br>
Let's go fix that, so if we go over to our controller here we're just passing package name.<br>
But we actually have to pass a whole bunch of other stuff.<br>
So let's start by treating this for real and let's go over here and say package.<br>
It's going to be package_service, and find_package_by_name.<br>
Alright well that doesn't exist, does it?<br>
So PyCharm can write it for us, thank you.<br>
And this is going to be a str and it's actually going to return an optional package.<br>
Optional comes from the typing library.<br>
Okay so, what are we going to do?<br>
What we always do when talk the database.<br>
And then go here.<br>
And we're create a session, and then we'll be able to return some result of a query.<br>
Turns out this is super easy, remember the package name is also actually the ID and maybe want to strip off anything like spaces, or make this lowercase but we're just going to just do the query with it.<br>
Assuming everything comes together, so we'll just say give us a query of package, and then we're going to filter on the package.id == to package_name.<br>
What do we get if we do this?<br>
Well we get one or zero packages of course but what we actually get is a cursor into the database.<br>
Cause, it has no way of knowing that that means just one so if we want to make sure we get just the one we'll say first.<br>
So first, or None if it doesn't exist.<br>
Instead of returning like a query set thing we're going to get actually either the first package or nothing if the name doesn't match, hence the optional.<br>
Okay so now instead of checking for this package name we'll check to make sure the package is actually found.<br>
So there's a few things we're going to have to put here and it's going to be a little complicated it's going to get more complicated before it gets better.<br>
Okay, so go over here and pass the package that's not needed anymore.<br>
Now in order for this to actually work we're going to have to, let me point at some pieces here we're going to have to come and indicate whether it's the latest version, and if it's not which version it is here is the numerical value of the latest version and whether or not that numerical value is the latest, okay?<br>
And by the way, if it turns out to not be the latest we'll get a different install statement right there, okay?<br>
So, for that we got to return the latest version.<br>
Now this is the part where it gets messier before it gets better.<br>
I'm going to show you a way to vastly improve this but it adds another layer on top of things.<br>
So first of all let's just come up with the details here and then we'll clean it up in another section under validation.<br>
So we'll save the latest version we're going to default this to zero and we'll say if package.releases, remember this?<br>
Our releases' navigating that relationship.<br>
Now, right now this is going back and doing another database interaction which is not terrible but it's not awesome.<br>
We'll fix that in a minute.<br>
So we'll say r equals, let's call this latest release we need the latest version to be set to nothing.<br>
An empty sort of nothing value or the real version but we're also going to need, if that exists there is a latest release we'll actually need that object.<br>
So I'm going to say this is None.<br>
I'm going to pass that in a second.<br>
Alright so the package has releases the latest release is going to be the first one, why?<br>
We go over to the package class, notice we're sorting descending by the highest version number.<br>
Okay so it means the zeroth one is the latest release.<br>
Have the latest version text is going to be alright pass these along, it's kind of big.<br>
So let's wrap it, and we're getting close.<br>
We're also going to need to pass the maintainers we haven't dealt with that yet.<br>
So, I'm just going to pass that as an empty list so it doesn't crash.<br>
And the other thing we need to discuss is is this the latest release?<br>
And I'm just going to say it is for now remember the ability to navigate to different versions.<br>
We're just going to say is latest is true, for the moment.<br>
We don't actually take the versions here under these details exactly but down here when we look at the released version.<br>
Pull up the details, here we're passing that.<br>
So we'll come back to that.<br>
I think this might be enough, so what are we going to do?<br>
Going to go to our super simple query make sure we got something back.<br>
If we didn't, must not be found.<br>
Come up with the various data here's a little default.<br>
If we actually do have releases we'll put those here.<br>
I'm going to return these values.<br>
So one more thing we'll need when we get the more complicated bit but we're just going to say that our current version we have out there is this, is the latest version.<br>
Oh, look at that.<br>
Alright let's do quick comparison.<br>
Real, fake, real, fake.<br>
Looks like our, oh our fonts maybe are not the most amazing here we might not be bringing those in.<br>
But nonetheless, it's close enough for what we're doing.<br>
And notice here's our description right, if we could transform this restructured text that would be better, but it's not.<br>
Here's our project description, our release history.<br>
I think we might need to put a wrap there.<br>
Got the home page.<br>
Here's the awscli, here's information on the status here's the license, here's the license again.<br>
Here's all the extra metadata.<br>
So it's looking pretty good, and here our latest version.<br>
Well, it's good, it is the latest version.<br>
We're also missing a little CSS, hold on I'll fix that.<br>
There we go, now we got that wrapping and everything.<br>
Looks a little bit better I just forgot to move a little CSS over.<br>
Like I said, we're skipping over the design.<br>
It's very very similar to before but just needed a few more styles.<br>
Alright what do you think?<br>
Pretty close, again it's not exact like we don't actually have the copy feature but I think it's close enough for our little demo app that we're building.<br>
Here's the summary that was entered in the database.<br>
Here's the package ID, here's the latest release.<br>
Here's the date of the latest release that's those kind of are why we actually needed the object.<br>
And yeah, everything looks really good.<br>
So I think that's pretty much working.<br>
Let's just review it real quick here.<br>
In order to do this, all we had to throw in a filter and say package.field or column ==.<br>
I know Django and Mongoengine have equals here but in SQLAlchemy, you put the equality statement here.<br>
So you can do greater than and stuff as well.<br>
So ID equal equal the value and then to get just one of them first.<br>
And the rest was just passing the data off to the template.
|
|
|
show
|
7:07 |
Now, to see what I'd like to show you in this one.<br>
It's time to finally look at this echo.<br>
So far it's been false, but let's set it to be true.<br>
And rerun our code and we see a whole bunch of stuff shoot out.<br>
Look at all that.<br>
So, what we're doing is actually, SQLAlchemy is checking for the existence of various tables like downloads, languages, releases and so on.<br>
And then our app finally starts.<br>
Alright so this is when we initialize our database stuff.<br>
Now, let's go over here and load up this page.<br>
Works great.<br>
But notice all the different statements.<br>
We have over here a begin, select package stuff from packages, where package ID is some sort of limit and offset.<br>
Okay so this is getting you can see it's doing the query for the first awscli, right.<br>
So, offset is 1, sorry, offset is 0.<br>
Limit is one.<br>
Okay the thing, that's first.<br>
Great.<br>
Then, we go back to the database again and we select release stuff from releases where package ID equals some parameter.<br>
That parameter being the one we passed.<br>
And we order by these three things in that order.<br>
Two operations.<br>
Not hugely bad here.<br>
But imagine, you got a list of these packages and you looped over those packages and interacted with their releases.<br>
If you got 20 packages you're doing one query to get the 20 packages and then you're doing this query separately, 20 times.<br>
So 21 operations.<br>
That's the so-called n+1 problem which is a common anti-pattern in terms of performance for ORMs This lazy loader's nice, but if you know you're going to interact with releases, there's something we can do better.<br>
So let's turn this into a single query that would solve the n+1 problem.<br>
Great, now we're getting one package so it's not terrible like I said, but the same technique applies regards of how many you're getting back.<br>
Alright, let's have a look.<br>
So we go over here, and we have this nice, clean bit of code on line 42.<br>
Give me a query, filter it like this, first boom.<br>
However, for what we're about to do we need a little more space.<br>
So let's put some wrap in here and here and we're going to come over and say we would like to go options, and we want to call this thing subqueryload.<br>
We're going to import that from the ORM.<br>
And what we do here is we're going to put the relationship to be loaded.<br>
So package.releases.<br>
So what are we doing?<br>
We're telling SQLAlchemy, go do this query and anything you return also go ahead and use a subquery to pull out all the related releases of this one.<br>
You could also do a joinedload.<br>
I think subqueryload's a little newer and fancier but they both would accomplish more or less the same thing.<br>
We have our filter again and first.<br>
So now, if we run the same thing again we should see one, more complicated but only one contact to the database.<br>
There it is.<br>
And let's try it with joinedload.<br>
I think actually joinedload might be better here.<br>
Try again.<br>
Clean that up.<br>
There we go now we're down to one interaction with the database.<br>
That's what I wanted after all.<br>
So, we come over here and we say select the package stuff here from and then we're doing another, sort of left outer joined on releases, to give us that.<br>
So one interaction with the database.<br>
It echos out to I think a standard error.<br>
And then, just standard out.<br>
But now we've got it down to one database interaction and that's better.<br>
So you can either use subqueryload or joinedload and either will work.<br>
Okay, so, let's look at performance.<br>
I guess we haven't really talked about performance.<br>
I'm going to go back and turn off echo.<br>
'Cause we don't want to trace out a bunch of stuff.<br>
So let me do this query a bunch of times.<br>
Now, just to be fair, over here.<br>
There's not a tremendous amount of data.<br>
I mean, there are 5000 releases but only 96 projects.<br>
It turns out, that even with tons of data we can get really good performance.<br>
But let's pull this back up.<br>
Have a look.<br>
So all that stuff happening is 62 milliseconds.<br>
Pretty decent.<br>
Let's see if I hit it a few times if I can get it better.<br>
Eh, 68, it looks like that's pretty much it.<br>
Check this out, we have our render.<br>
And we actually have SQLAlchemy.<br>
Here's that query, holy moly.<br>
That is quite the query.<br>
I guess it would be interesting to try the joinedload as well and see if we get any performance difference.<br>
Another thing, just while we have this pulled up here.<br>
If we go turn on performance and go back to history.<br>
And then we refresh this a few more times you can actually pull up performance if I click on the right part here.<br>
Pull up performance is slower because we're asking it to do more work, but look at this.<br>
Built-in profiling, so.<br>
It turns out, where does it start to get slow.<br>
Find package by name.<br>
Takes about that long, okay.<br>
Apparently to do that query, it takes a little while.<br>
Let's go back and just, you know since now we can measure let's go change a few things here.<br>
Let's try this subqueryload first of all.<br>
Do that a few times, pull up the latest.<br>
Now, this number's slower than the original but it actually, that's only because the profiling was on let's turn that off.<br>
And notice, over here we now have two SQLAlchemy interactions one for releases and one from packages.<br>
Let's try again.<br>
20 milliseconds, how 'about that?<br>
Subquery join is actually, subqueryload is actually faster by quite a bit, that's three times faster.<br>
I guess the final thing to check would just be what if it weren't there?<br>
Let's try it one more time, and just do the relationship.<br>
And look at that.<br>
16 milliseconds.<br>
It's a little bit of a interesting case, right?<br>
That we put that performance speed up in there and it actually made it slower.<br>
It just reminds you, always, always measure.<br>
So, I'll put a little comment here so you have that, like so.<br>
Let's put it actually over here, above.<br>
The reason I think this is faster is we're not suffering at all from the latency of talking to the database.<br>
In a real database, that probably would be slower because you've got a few milliseconds between the interactions.<br>
And this whole n+1 problem, if you have a hundred well obviously the join is going to be faster.<br>
But I guess just two independent queries is faster in this case.<br>
So, you know, measure, measure, measure.<br>
See what's up.
|
|
|
show
|
4:03 |
We've written a few interesting queries and before we're done with this application we'll write a couple more.<br>
But let's talk about some of the core concepts around querying data.<br>
So here's a simple function that says find an account by login.<br>
We haven't written this one yet but you know, we're going to when we get to the user side of things.<br>
It starts like all interaction with SQLAlchemy.<br>
We create a unit of work by creating a session.<br>
Here in the slides we have a slightly different factory method that we've written, but same idea we get a session back, we're call calling it s.<br>
We go to our session or we say s.query of the type we're trying to query from, account and then we can have one or more filter statements.<br>
Here we're doing two filter statements.<br>
Find where the account has this e-mail and the hashed password is the one that we've created for them by rehashing it.<br>
And now we're calling one, which gives us one and exactly one or none items back and we're going to return that account.<br>
So, if you actually look at what goes over to the database it's something like this.<br>
Select * from account where account.email is some parameter and account.passwordhashed is some other parameter and the parameters are Mysie Kennedy and ABC.<br>
You'll see that you can layer on these filter statements even conditionally, like you can create the query and then say if some other value is there then also append or apply another filter operation so you can kind of build these up.<br>
They don't actually execute until you do like a one operation or you loop over them or you do a first or anything like that.<br>
So here's returning a single record.<br>
Also, it's worth noting that the select * here is a simplification, everything is explicitly called out in SQLAlchemy.<br>
The concept is just give me all the records or give me all the columns.<br>
If we want to get a set of items back, like show me all of the packages that a particular person with their email has authored.<br>
We would go and again get our session.<br>
We would go and create a query based on package.<br>
We'd say filter, package.authoremail equals this email ==, remember double equal and then we can just say All and that'll give us all of the packages that match that query.<br>
This one's not going against a primary key so there'll be potentially more than one.<br>
Of course this maps down to select * from packages where package.authoremail equals when you know the email that you passed.<br>
Super simple and exactly like you would expect.<br>
So the double equal filter, pretty straightforward.<br>
There's actually some that are not so straightforward so equals obviously ==, user.name == Ed, simple.<br>
If you want not equals, just use the not equals operator.<br>
That's pretty simple.<br>
You could also use like, so one of the things it takes some getting used to is these SQLAlchemy descriptor column field value type multi-purpose things here is they actually have operations that you can do on them when you're treating the static type interacting with a static definition rather than a record from the database.<br>
So here we say the usertype.name.like_ or in_ or things like that.<br>
So, we saw the descending sort operation on there as well.<br>
So, if we want to do the Like query, this is like find the substring ed in the name, then you can do .like_ and then pass the % operators as you would in a normal SQL query.<br>
IF you want to say I want to find the user whose name is contained in the set, Ed, Wendy or Jack then you can do this .in_, remember the underscore is because in is a key word in Python, so in_.<br>
If you want to do not, not in, this is kind of not obvious but you do the ~ operator at the beginning to negate it.<br>
If you want to check for null, == None, the and you just apply multiple queries, the or doesn't work that way.<br>
If you want to do an or, you've got to apply a special or operator to a tuple of things.<br>
So, here are most of the SQL operators in terms of SQLAlchemy.<br>
You can do a lot of stuff with this.<br>
It's not all of them, but many of them.
|
|
|
show
|
0:44 |
Databases are really good at filtering and ordering.<br>
Here's a function, find_all_packages and the idea is I would like really a list of all the packages in the database showing the newest ones first and the oldest ones last.<br>
So we're going to do a query on package and we don't do any filtering 'cause you know, we said in the name, we want them all but we are going to do an order by.<br>
So we say query a package.orderby and then we always express these operations in terms of the type, so package.created.<br>
And if we just said package, dot, created it would order ascending by the created date but we want descending, so we go to that descriptor created and we say, .desc, we call the function to reverse the sort and then we just say give us all the packages, here they come.
|
|
|
show
|
0:49 |
In order to update existing data, we start like we always do, we get a session, and then we retrieve one or more records from the database.<br>
Here we're just getting one package.<br>
We're going to get this package back, and if we make changes to it, so we set the author value to a new name and we set the author email to a new email SQLAlchemy will track within the session that that record is dirty and it needs to be updated because we've changed some fields.<br>
And then, when we're ready to actually save it, push all the changes back.<br>
I could apply this to as many entities as we'd like it doesn't have to just be one, then we're going to commit the unit to work, and it's going to look at the changes, do all the changes in a single transaction, back to the database.<br>
We use the unit of work to do our updates just like we do the inserts.
|
|
|
show
|
1:59 |
We saw relationships are extremely powerful and let us imagine as if our code and data were just connected almost hierarchically the way we would in a regular Python program connect it not split apart like we do in a database.<br>
The way we define these we had an orm.relationship field to the class.<br>
So here we have our releases say the relationship is against the release type that we're speaking in terms of SQLAlchemy entities not database and then we're going to do an orderby.<br>
This could be a single thing or a list.<br>
Probably an integer actually and so we're going to pass that in.<br>
And then we're going to say it back-populates package.<br>
What does that mean?<br>
If we want this relationship to work in both directions.<br>
So we have a package we can see the releases and if we have an individual release we can see the single package that it corresponds to.<br>
So over in the release we're going to do the package ID value to actually store the relationship like we would store any value that's a string or an integer whatever it corresponds to in the other field.<br>
And then we're going to say this is a foreign key and in the foreign key part we speak in terms of database packages.id But then we also would like to establish that relationship so we say there's orm relationship for the package type form released back to the package.<br>
And it back populates releases and it's called package.<br>
So you can see the symmetry here.<br>
Not too hard to set this up, once you have an example.<br>
Put them side by side, you go okay here's where I fit all the pieces for my particular data set and then you saw that when we load a package it doesn't actually load the releases unless we interact with it.<br>
So if we touch it, it would go back to the database and do the query.<br>
We also saw that if we create new releases and put them into the release package.releases what becomes a list and commit those changes that will actually insert the releases.<br>
We work on the same but in reverse as well if we had said a package on a release.<br>
So it's sort of bi-directional in that sense.
|
|
|
show
|
0:37 |
We started off this chapter by demoing how to insert data.<br>
Let's actually summarize now here at the end.<br>
So again, we're going to create a session which is the corresponding unit of work bit of syntax in SQLAlchemy.<br>
Then we're just going to allocate some objects so here we're going to create a package and set its ID and its author maybe create some releases, set the release not package value, other properties similarly release two, set its package.<br>
We're going to add the package, call commit whoosh, all three of those things because of the relationships get inserted into the database.<br>
Super easy.
|
|
|
show
|
0:32 |
I did mention this at the very beginning of the course but if you want to dig deeper into SQLAlchemy hear the backstories of the design patterns that whole concept of the unit of work and why Mike thought that was great and brought it in you can check out talkpython.fm/5 that will take you over one of the very first Talk Python episodes I did with Mike Bayer.<br>
And you can listen to the whole story about how he created it, how it's evolved over time things like that.<br>
So if you want to dig deeper, here's a quick and easy way to do it while you're driving or doing chores.
|